IRI leverer nu også fuzzy søgefunktioner, både i dets gratis database- og flad-fil profileringsværktøjer og som tilgængelige feltfunktionsbiblioteker i IRI CoSort, FieldShield og Voracity for at øge datakvalitet, sikkerhed og MDM-kapacitet. Dette er den første i en serie af artikler om IRI fuzzy søgeløsninger, der dækker deres anvendelse til forbedring af datakvalitet.
Introduktion
Sandheden eller pålideligheden af data for et af de store "V"-ord (sammen med volumen, variation, hastighed og værdi), som IRI et al taler om i forbindelse med data- og virksomhedsinformationsstyring. Generelt definerer IRI data i tvivl som havende en eller flere af disse attributter:
- Lav kvalitet, fordi den er inkonsekvent, unøjagtig eller ufuldstændig
- Tvetydig (tænk MDM), upræcist (ustruktureret) eller vildledende (sociale medier)
- Forspændt (undersøgelsesspørgsmål), støjende (overflødigt eller forurenet) eller unormalt (outliers)
- Ugyldig af enhver anden grund (er dataene korrekte og nøjagtige i forhold til dets tilsigtede brug?)
- Usikkert – indeholder det PII eller hemmeligheder, og er det korrekt maskeret, reversibelt osv.?
Denne artikel fokuserer kun på nye fuzzy søgeløsninger til det første problem, datakvalitet. Andre artikler i denne blog diskuterer, hvordan IRI-software løser de andre fire sandhedsproblemer; bede om hjælp til at finde dem, hvis du ikke kan.
Om fuzzy søgning
Fuzzy søgninger finder ord eller sætninger (værdier), der ligner, men ikke nødvendigvis er identiske, med andre ord eller sætninger (værdier). Denne type søgning har mange anvendelsesmuligheder, såsom at finde sekvensfejl, stavefejl, transponerede tegn og andre, vi vil dække senere.
At udføre en uklar søgning efter omtrentlige ord eller sætninger kan hjælpe med at finde data, der kan være en duplikat af tidligere lagrede data. Brugerinput eller automatisk korrektion kan dog have ændret dataene på en eller anden måde for at få registreringerne til at virke uafhængige.
Resten af artiklen vil dække fire uklare søgefunktioner, som IRI nu understøtter, hvordan man bruger dem til at gennemsøge dine data og returnere disse registreringer, der tilnærmer søgeværdien.
1. Levenshtein
Levenshtein-algoritmen fungerer ved at tage to ord eller sætninger og tælle, hvor mange redigeringstrin det vil tage for at omdanne et ord eller en sætning til den anden. Jo færre skridt det vil tage, jo mere sandsynligt er ordet eller sætningen et match. De trin, Levenshtein-funktionen kan tage, er:
- Indsættelse af et tegn i ordet eller sætningen
- Sletning af et tegn fra ordet eller sætningen
- Erstatning af et tegn i et ord eller en sætning med et andet
Følgende er et CoSort SortCL-program (jobscript), der demonstrerer, hvordan man bruger Levenshteins fuzzy søgefunktion:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Der er to dele, der skal bruges til at producere det ønskede output.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Denne linje kalder funktionen fs_levenshtein og gemmer resultatet i feltet FS_RESULT. Funktionen tager to inputparametre:
- Feltet til at køre den uklare søgning på (NAVN i vores eksempel)
- Den streng, som inputfeltet vil blive sammenlignet med ("Barney Oakley" i vores eksempel).
/INCLUDE WHERE FS_RESULT GT 50
Denne linje sammenligner feltet FS_RESULT og kontrollerer, om det er større end 50, så udlæses kun poster med et FS_RESULT på mere end 50. Det følgende viser output fra vores eksempel.

Som output viser, er denne type søgning nyttig til at finde:
- Sammenkædede navne
- Støj
- Stavefejl
- Transponerede tegn
- Transskriptionsfejl
- Skrivefejl
Levenshtein-funktionen er derfor også nyttig til at identificere almindelige dataindtastningsfejl. Det tager dog længst tid at udføre ud af de fire algoritmer, da det sammenligner hvert tegn i en streng med hvert tegn i den anden.
2. Terningskoefficient
Terningskoefficienten eller terningealgoritmen opdeler ord eller sætninger i tegnpar, sammenligner disse par og tæller kampene. Jo flere overensstemmelser ordene har, jo mere sandsynligt er selve ordet et match.
Følgende SortCL-script demonstrerer den fuzzy søgefunktion for terningskoefficienten.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Der er to dele, der skal bruges for at give os det ønskede output.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Denne linje kalder funktionen fs_dice og gemmer resultatet i feltet FS_RESULT. Funktionen tager to inputparametre:
- Feltet til at køre den uklare søgning på (NAVN i vores eksempel).
- Den streng, som inputfeltet vil blive sammenlignet med ("Robert Thomas Smith" i vores eksempel).
/INCLUDE WHERE FS_RESULT GT 50
Denne linje sammenligner feltet FS_RESULT og kontrollerer, om det er større end 50, så udlæses kun poster med et FS_RESULT på mere end 50. Det følgende viser output fra vores eksempel.
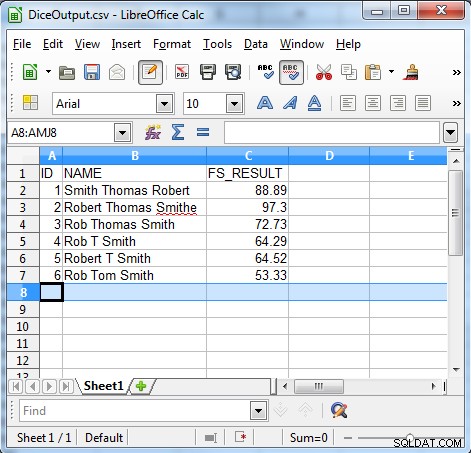
Som output viser er terningskoefficientalgoritmen nyttig til at finde inkonsistente data såsom:
- Sekvensfejl
- Ufrivillige rettelser
- Kælenavne
- Initialer og kaldenavne
- Uforudsigelig brug af initialer
- Lokalisering
Terningealgoritmen er hurtigere end Levenshtein, men kan blive mindre nøjagtig, når der er mange simple fejl som f.eks. stavefejl.
3. Metaphone og 4. Soundex
Metaphone- og Soundex-algoritmerne sammenligner ord eller sætninger baseret på deres fonetiske lyde. Soundex gør dette ved at læse ordet eller sætningen igennem og se på individuelle tegn, mens Metaphone ser på både individuelle karakterer og karaktergrupper. Så giver begge koder baseret på ordets stavemåde og udtale.
Følgende SortCL-script demonstrerer Soundex- og Metasphone-søgefunktionerne:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
I hvert tilfælde er der tre dele, der skal bruges for at give os det ønskede output.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Linjen kalder funktionen, og gemmer resultatet i feltet RESULTAT. Funktionerne tager begge to inputparametre:
- Feltet til at køre den uklare søgning på (NAVN i vores eksempel)
- Den xtring, som inputfeltet vil blive sammenlignet med ("John" i vores eksempel)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Denne linje sammenligner felterne SE_RESULT og MP_RESULT og kontrollerer og returnerer rækken, hvis enten er større end 0.
Soundex returnerer enten 100 for et match, eller 0, hvis det ikke er et match. Metaphone har mere specifikke resultater og returnerer 100 for en stærk kamp, 66 for en normal kamp og 33 for en mindre kamp.
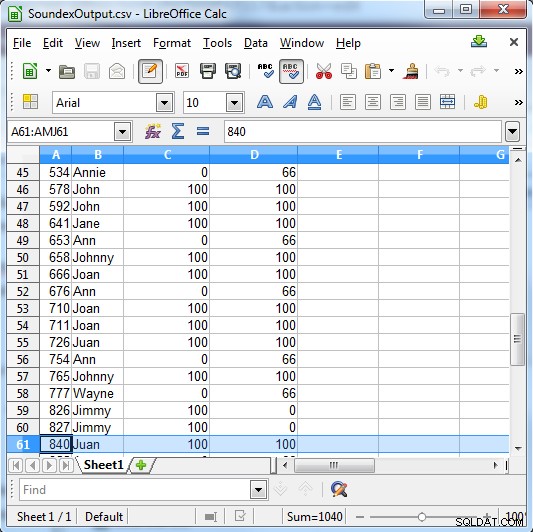
Kolonne C viser Soundex-resultaterne. Ckolonne D viser Metaphone-resultaterne
Som output viser, er denne type søgning nyttig til at finde:
- Fonetiske fejl
Send venligst feedback om denne artikel nedenfor, og hvis du er interesseret i at bruge disse funktioner bedes du kontakte din IRI-repræsentant. Se vores næste artikel om brug af disse algoritmer i IRI Workbench datakonsolideringsguiden (kvalitet).