For nylig var jeg involveret i udviklingen af den funktionalitet, der krævede en hurtig og hyppig overførsel af store mængder data til disk. Derudover skulle disse data fra tid til anden læses fra disken. Derfor var jeg bestemt til at finde ud af stedet, måden og midlerne til at opbevare disse data. I denne artikel vil jeg kort gennemgå opgaven, samt undersøge og sammenligne løsninger til udførelse af denne opgave.
Opgavens kontekst :Jeg arbejder i et team, der udvikler værktøjer til relativ databaseudvikling (SQL Server, MySQL, Oracle). Værktøjsudvalget omfatter både selvstændige værktøjer og tilføjelser til MS SSMS.
Opgave :Gendannelse af dokumenter, der blev åbnet i det øjeblik, IDE lukkede ved næste start af IDE.
Usecase :At lukke IDE hurtigt, før du forlader kontoret uden at tænke på, hvilke dokumenter der blev gemt, og hvilke der ikke blev. Ved næste start af IDE skal vi have det samme miljø, som var i lukningsøjeblikket og fortsætte arbejdet. Alle resultater af arbejdet skal gemmes i det øjeblik, hvor uordentligt lukkes ned, f.eks. under nedbrud af et program eller operativsystem eller under slukning.
Opgaveanalyse :Den lignende funktion er til stede i webbrowsere. Browsere gemmer dog kun URL'er, der består af cirka 100 symboler. I vores tilfælde skal vi gemme hele dokumentindholdet. Derfor har vi brug for et sted at gemme og opbevare brugerens dokumenter. Hvad mere er, nogle gange arbejder brugere med SQL på en anden måde end med andre sprog. For eksempel, hvis jeg skriver en C#-klasse på mere end 1000 rækker lang, vil det næppe være acceptabelt. Mens der i SQL-universet, sammen med 10-20-rækkers forespørgsler, eksisterer de monstrøse databasedumps. Sådanne dumps er næppe redigerbare, hvilket betyder, at brugere foretrækker at holde deres redigeringer sikre.
Krav til et lager:
- Det skal være en letvægts integreret løsning.
- Den skal have høj skrivehastighed.
- Den bør have mulighed for multibehandlingsadgang. Dette krav er ikke kritisk, da vi kan sikre adgangen ved hjælp af synkroniseringsobjekterne, men alligevel ville det være rart at have denne mulighed.
Kandidater
Den første kandidat er ret klodset, det vil sige at gemme alt i en mappe et eller andet sted i AppData.
Den anden kandidat er indlysende – SQLite, en standard af indlejrede databaser. Meget solid og populær kandidat.
Den tredje kandidat er LiteDB-databasen. Det er det første resultat for "indlejret database til .net"-forespørgsel i Google.
Første blik
Filsystem. Filer er filer, de kræver vedligeholdelse og korrekt navngivning. Udover filindholdet skal vi gemme et lille sæt egenskaber (oprindelig sti på disken, forbindelsesstreng, version af IDE, hvor den blev åbnet). Det betyder, at vi enten bliver nødt til at oprette to filer til et dokument, eller at opfinde et format, der adskiller egenskaber fra indhold.
SQLite er en klassisk relationsdatabase. Databasen er repræsenteret af én fil på disken. Denne fil bliver bundet med databaseskema, hvorefter vi skal interagere med den ved hjælp af SQL-midlerne. Vi vil være i stand til at oprette 2 tabeller, en for egenskaber og den anden for indhold – i tilfælde af at vi bliver nødt til at bruge egenskaber eller indhold separat.
LiteDB er en ikke-relationel database. I lighed med SQLite er databasen repræsenteret af en enkelt fil. Det er helt skrevet i С#. Det har fængslende enkelhed i brugen:vi skal bare give et objekt til biblioteket, mens serialisering vil blive udført af dets egne midler.
Performancetest
Før jeg leverer kode, vil jeg gerne forklare den generelle opfattelse og give sammenligningsresultater.
Den generelle opfattelse er at sammenligne hastigheden for at skrive store mængder af små filer til databasen, den gennemsnitlige mængde af gennemsnitlige filer og en lille mængde store filer. Sagen med gennemsnitsmapper er for det meste tæt på reel sag, mens sager med små og store sager er grænsesager, hvilket også skal tages i betragtning.
Jeg skrev indhold ind i en fil ved hjælp af FileStream med standardbufferstørrelsen.
Der var en nuance i SQLite, som jeg gerne vil nævne. Vi var ikke i stand til at lægge alt dokumentindhold (som jeg nævnte ovenfor, de kan være virkelig store) i én databasecelle. Sagen er, at vi af optimeringsøjemed gemmer dokumenttekst linje for linje. Det betyder, at for at sætte tekst i en enkelt celle, skal vi sætte alt dokument i en enkelt række, hvilket ville fordoble mængden af den brugte driftshukommelse. Den anden side af problemet ville afsløre sig selv under data læst fra databasen. Derfor var der en separat tabel i SQLite, hvor data blev lagret række for række, og data blev forbundet ved hjælp af fremmednøgle med tabellen, der kun indeholdt filegenskaber. Desuden formåede jeg at fremskynde databasen med batchdataindsættelse (flere tusinde rækker ad gangen) i OFF-synkroniseringstilstand uden logning og inden for én transaktion.
LiteDB modtog et objekt med List blandt sine egenskaber, og biblioteket gemte det på disk på egen hånd.
Under udviklingen af testapplikationen forstod jeg, at jeg foretrækker LiteDB. Sagen er, at testkoden til SQLite tager mere end 120 rækker, mens kode, der løser det samme problem i LiteDb, kun tager 20 rækker.
Test datagenerering
FileStrings.cs
intern klasse FileStrings { private static readonly Random random =new Random(); public List Strings { get; sæt; } =ny liste(); public int SomeInfo { get; sæt; } public FileStrings() { } public FileStrings(int id, int minLines, decimal lineIncrement) { SomeInfo =id; int linjer =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(List files) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; forbindelse.Åbn(); var kommando =forbindelse.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_numberings_uindexe ); PRAGMA synchronous =OFF;PRAGMA journal_mode =OFF"; kommando.ExecuteNonQuery(); var insertFilecommand =forbindelse.CreateCommand(); insertFilecommand.CommandText ="INDSÆT I filer(filnavn) VÆRDI(?); VÆLG last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =forbindelse.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var element i filer) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } privat statisk tomrum SaveToDb(FileStrings-element, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =filnavn; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var linje i item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(List item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); data.Indsæt(emne); } }
Følgende tabel viser gennemsnitlige resultater for flere kørsler af testkoden. Under modifikationer var den statistiske afvigelse ret umærkelig.
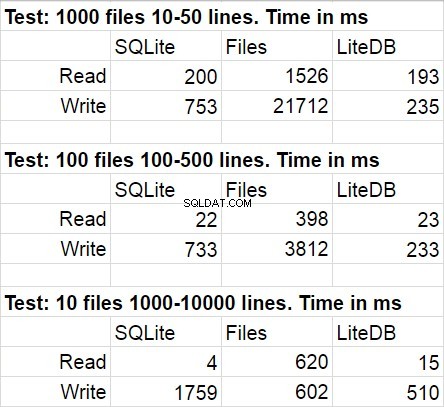
Jeg var ikke overrasket over, at LiteDB vandt i denne sammenligning. Jeg var dog chokeret over LiteDBs sejr over filer. Efter en kort undersøgelse af biblioteksarkivet fandt jeg ud af meget omhyggeligt implementeret paginal skrivning til disk, men jeg er sikker på, at dette kun er et af mange præstationstricks, der bruges der. En ting mere, jeg gerne vil påpege, er, at filsystemets adgang hurtigt falder, når mængden af filer i mappen bliver virkelig stor.
Vi valgte LiteDB til udviklingen af vores funktion, og vi fortrød næsten ikke dette valg. Sagen er, at biblioteket er skrevet i native for alle C#, og hvis noget ikke var helt klart, kunne vi altid henvise til kildekoden.
Idele
Udover de ovennævnte fordele ved LiteDB i sammenligning med dets konkurrenter, begyndte vi at bemærke ulemper under udviklingen. De fleste af disse ulemper kan forklares med 'ungdom' på biblioteket. Efter at have begyndt at bruge biblioteket lidt ud over grænserne for 'standard' scenariet, opdagede vi flere problemer (#419, #420, #483, #496). Bibliotekets forfatter svarede ret hurtigt på spørgsmål, og de fleste problemer blev hurtigt løst. Nu er der kun én opgave tilbage (bliv ikke forvekslet med dens lukkede status). Dette er et spørgsmål om konkurrenceadgang. Det ser ud til, at der gemmer sig en meget ubehagelig racetilstand et sted dybt inde i biblioteket. Vi gik forbi denne fejl på en ret original måde (jeg har tænkt mig at skrive en separat artikel om dette emne).
Jeg vil også gerne nævne fraværet af pæn redaktør og seer. Der er LiteDBShell, men er kun for ægte konsolfans.
Oversigt
Vi har bygget en stor og vigtig funktionalitet over LiteDB, og nu arbejder vi på endnu en stor funktion, hvor vi også vil bruge dette bibliotek. For dem, der leder efter en igangværende database, foreslår jeg, at de er opmærksomme på LiteDB og den måde, den vil vise sig i forbindelse med din opgave, da, som du ved, hvis noget havde fungeret for én opgave, ville det ikke nødvendigvis træne for en anden opgave.