Indholdsfortegnelse
Hvad er Oracle index clustering factor(CF)?
Klyngefaktoren er et tal, der repræsenterer i hvilken grad data er tilfældigt fordelt i en tabel sammenlignet med den indekserede kolonne. Enkelt sagt er det antallet af "blokafbrydere", mens du læser en tabel ved hjælp af et indeks.
Det er en vigtig statistik, der spiller en vigtig rolle i optimeringsberegning. Det bruges til at vægte beregningen for indeksområdets scanninger. Når klyngefaktoren er højere, er omkostningerne ved indeksområdescanning højere
En god klyngefaktor er lig (eller tæt på) værdierne for antallet af blokke i tabellen.
En dårlig klyngefaktor er lig (eller tæt på) antallet af rækker i tabellen.
Hvordan beregnes CF?
Oracle beregner klyngefaktoren ved at lave en fuld scanning af indekset, der går bladblokkene fra ende til anden. For hver indtastning i hvert blad kontrollerer Oracle det absolutte filnummer og blok-id'et som hentet fra den indekserede værdis ROWID. Det holder en løbende optælling af, hvor mange "forskellige" blokke, der indeholder datarækker, der peges på af indekset. Blokeringsadressen fra den første post sammenlignes med blokadressen fra den anden post. Hvis det er den samme tabelblok, øger Oracle ikke tælleren. Hvis tabelblokkene er forskellige, føjer Oracle én til optællingen. Denne optællingsproces fortsætter fra indgang til indgang, mens du altid sammenligner den tidligere indgang med den nuværende.
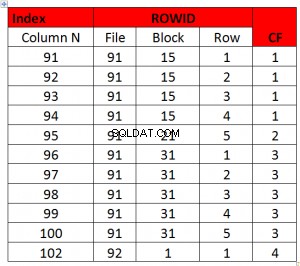
Ovenstående er et godt CF-eksempel, da CF er lig med antallet af blokke
Eksempel på dårlig klyngefaktor
Her er klyngefaktoren lig med antal rækker
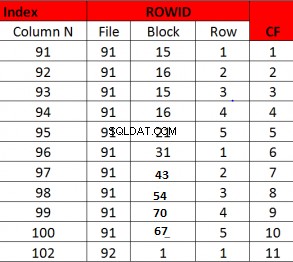
Denne optællingsmetode har sit eget uventede resultat. Lad os antage, at dataene tilfældigvis er udfyldt over et lille sæt blokke, men ikke i rækkefølge i forhold til indeksnøglen, så kan et sæt rækker se ud til at være over et stort sæt blokke, når der måske kun er nogle få ægte distinkte blokke . Så CF ville være højere, men faktisk rører den meget få blokke. Dette problem kan afhjælpes i 12c ved at bruge tabelpræferencer og angive den tabellagrede cacheblok.
hvordan man forbedrer klyngefaktor i oracle
En indeksombygning ville ikke have nogen effekt på klyngefaktoren. Tabellen skal sorteres og genopbygges for at sænke klyngefaktoren.
Forespørgsel for at bestemme klyngefaktoren
CF lagres i dataordbogen og kan ses fra dba_indexes (eller user_indexes).
Faktisk kan alle indeksstatistikker findes der
SELECT index_name, index_type, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,
avg_data_blocks_per_key, clustering_factor, num_rows, sample_size, last_analyzed, partitioned
FROM dba_indexes
WHERE table_name = 'ORDERS' ;
Hvordan påvirker Oracle-indeksklyngefaktoren optimeringsplanen?
Klyngefaktoren er den primære statistik, som optimeringsværktøjet bruger til at vægte indeksadgangsstier. Det er et estimat af antallet af LIO'er til tabelblokke, der kræves for at hente alle de rækker, der opfylder forespørgslen i rækkefølge. Jo højere klyngefaktoren er, jo flere LIO'er vil optimeringsværktøjet estimere være påkrævet. Jo flere LIO'er, der kræves, jo mindre attraktiv og dermed dyrere vil brugen af indekset være.
Relateret artikel
Oracle partitionsindeks :Forstå Oracle partitionsindeks, Hvad er globale ikke-partitionerede indekser?, Hvad er lokale præfiksindekser, lokalt indeks uden præfiks
find indekser på en tabel i Oracle:tjek denne artikel for at finde forespørgsler om, hvordan for at finde indekser på en tabel i oracle, skal du liste alle indekser i skemaet, indeksstatus, indekskolonne
typer af indekser i oracle :Denne side består af oracle-indeksoplysninger, forskellige typer indekser i oracle med et eksempel, hvordan at oprette/drop/ændre indekset i Oracle
Virtuelt indeks i Oracle:Hvad er virtuelt indeks i Oracle? Anvendelser, begrænsninger, fordele og hvordan man bruger til at kontrollere forklaringsplanen i Oracle-databasen, skjult parameter _USE_NOSEGMENT_INDEXES