Introduktion
Lagring af data er én ting; lagring af meningsfuld, nyttig, korrekt data er noget helt andet. Mens mening og nytte i sig selv er subjektive kvaliteter, kan korrekthed i det mindste defineres logisk og håndhæves. Typer sikrer allerede, at tal er tal, og datoer er datoer, men kan ikke garantere, at vægt eller afstand er positive tal eller forhindrer datointervaller i at overlappe. Tuple-, tabel- og databasebegrænsninger anvender regler for data, der lagres, og afviser værdier eller kombinationer af værdier, som ikke består.
Begrænsninger gør på ingen måde andre inputvalideringsteknikker ubrugelige, selv når de tester de samme påstande. Tid brugt på at prøve og undlade at gemme ugyldige data er spildtid. Overtrædelsesmeddelelser, såsom assert i systemer og applikationsprogrammeringssprog, afslører kun det første problem med den første kandidatpost mere detaljeret end nogen, der ikke umiddelbart er involveret i databasens behov. Men hvad angår korrektheden af data, er begrænsninger lov, på godt og ondt; alt andet er råd.
På Tuples:Not Null, Default og Check
Ikke-nul begrænsninger er den enkleste kategori. En tuple skal have en værdi for den begrænsede attribut, eller sagt på en anden måde, sættet af tilladte værdier for kolonnen inkluderer ikke længere det tomme sæt. Ingen værdi betyder ingen tupel:indsættelsen eller opdateringen er afvist.
Beskyttelse mod nulværdier er lige så let som at erklære column_name COLUMN_TYPE NOT NULL i CREATE TABLE eller ADD COLUMN . Null-værdier forårsager hele kategorier af problemer mellem databasen og slutbrugere, så refleksivt at definere ikke-null-begrænsninger på en kolonne uden en god grund til at tillade nuller er en god vane at komme ind på.
Tilvejebringelsen af en standardværdi, hvis intet er angivet (ved udeladelse eller en eksplicit NULL). ) i en indsættelse eller opdatering betragtes ikke altid som en begrænsning, da kandidatposter ændres og gemmes i stedet for at blive afvist. I mange DBMS'er kan standardværdier genereres af en funktion, selvom MySQL ikke tillader brugerdefinerede funktioner til dette formål.
Enhver anden valideringsregel, som kun afhænger af værdierne i en enkelt tupel, kan implementeres som en CHECK begrænsning. På en måde NOT NULL i sig selv er en forkortelse for CHECK (column_name IS NOT NULL); fejlmeddelelsen modtaget i strid gør det meste af forskellen. CHECK , kan dog anvende og håndhæve sandheden af ethvert boolsk prædikat over en enkelt tupel. For eksempel skal en tabel, der gemmer geografiske placeringer, CHECK (latitude >= -90 AND latitude < 90) , og tilsvarende for længdegrad mellem -180 og 180 -- eller, hvis tilgængeligt, brug og valider en GEOGRAPHY datatype.
På borde:Unik og ekskludering
Tabel-niveau begrænsninger test tuples mod hinanden. I en unik begrænsning må kun én post have et givet sæt værdier for de begrænsede kolonner. Nullabilitet kan give problemer her, da NULL er aldrig lig med noget andet, op til og inklusive NULL sig selv. En unik begrænsning på (batman, robin) giver derfor mulighed for uendelige kopier af enhver Robinless Batman.
Ekskluderingsbegrænsninger understøttes kun i PostgreSQL og DB2, men udfylder en meget nyttig niche:de kan forhindre overlapninger. Angiv de begrænsede felter og de operationer, hvormed hver vil blive evalueret, og en ny post vil kun blive accepteret, hvis ingen eksisterende post kan sammenlignes med hvert felt og hver operation. For eksempel en schedules tabel kan konfigureres til at afvise konflikter:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Ophæv operationer såsom PostgreSQL's ON CONFLICT klausul eller MySQL's ON DUPLICATE KEY UPDATE bruge en begrænsning på tabelniveau til at opdage konflikter. Og ligesom ikke-nul begrænsninger kan udtrykkes som CHECK begrænsninger, kan en unik begrænsning udtrykkes som en udelukkelsesbegrænsning på lighed.
Den primære nøgle
Unikke begrænsninger har et særligt nyttigt specialtilfælde. Med en ekstra begrænsning, der ikke er nul på den eller de unikke kolonner, kan hver post i tabellen identificeres enkeltvis ved dens værdier for de begrænsede kolonner, som under ét kaldes en nøgle . Flere kandidatnøgler kan eksistere side om side i en tabel, såsom users stadig nogle gange med distinkt unik og ikke-null email s og username s; men at erklære en primær nøgle etablerer et enkelt kriterium, efter hvilket optegnelser er offentligt og udelukkende kendt. Nogle RDBMS'er organiserer endda rækker på sider efter den primære nøgle, kaldet til dette formål et klynget indeks , for at gøre søgning efter primærnøgleværdier så hurtig som muligt.
Der er to typer primærnøgler. En naturlig nøgle er defineret på en eller flere kolonner "naturligt" inkluderet i tabellens data, mens en surrogat eller syntetisk nøgle er opfundet udelukkende med det formål at blive nøglen. Naturlige nøgler kræver omhu - flere ting kan ændre sig, end databasedesignere ofte tilskriver, fra navne til nummereringsskemaer. En opslagstabel, der indeholder lande- og regionsnavne, kan bruge deres respektive ISO 3166-koder som en sikker naturlig primærnøgle, men en users tabel med en naturlig nøgle baseret på mutable værdier som navne eller e-mailadresser inviterer til problemer. Hvis du er i tvivl, skal du oprette en surrogatnøgle.
Hvis en naturlig nøgle spænder over flere kolonner, bør en surrogatnøgle altid i det mindste overvejes, da nøgler med flere kolonner kræver en større indsats at administrere. Hvis de naturlige nøgler passer til, bør kolonner dog ordnes i stigende specificitet, ligesom de er i indekser:landekode så regionskode i stedet for omvendt.
Surrogatnøglen har historisk set været en enkelt heltalskolonne eller BIGINT hvor milliarder i sidste ende vil blive tildelt. Relationelle databaser kan automatisk fylde surrogatnøgler med det næste heltal i en serie, en funktion, der normalt kaldes SERIAL eller IDENTITY .
En autoinkrementerende numerisk tæller er ikke uden ulemper:Tilføjelse af poster med prægenererede nøgler kan forårsage konflikter, og hvis sekventielle værdier udsættes for brugere, er det nemt for dem at gætte, hvad andre gyldige nøgler kan være. Universelt unikke identifikatorer eller UUID'er undgår disse svagheder og er blevet et almindeligt valg for surrogatnøgler, selvom de også er meget større på siden end et simpelt tal. V1 (MAC-adressebaseret) og v4 (pseudotilfældig) UUID-typer bruges oftest.
På databasen:Fremmednøgler
Relationelle databaser implementerer kun én klasse af multi-table begrænsninger,
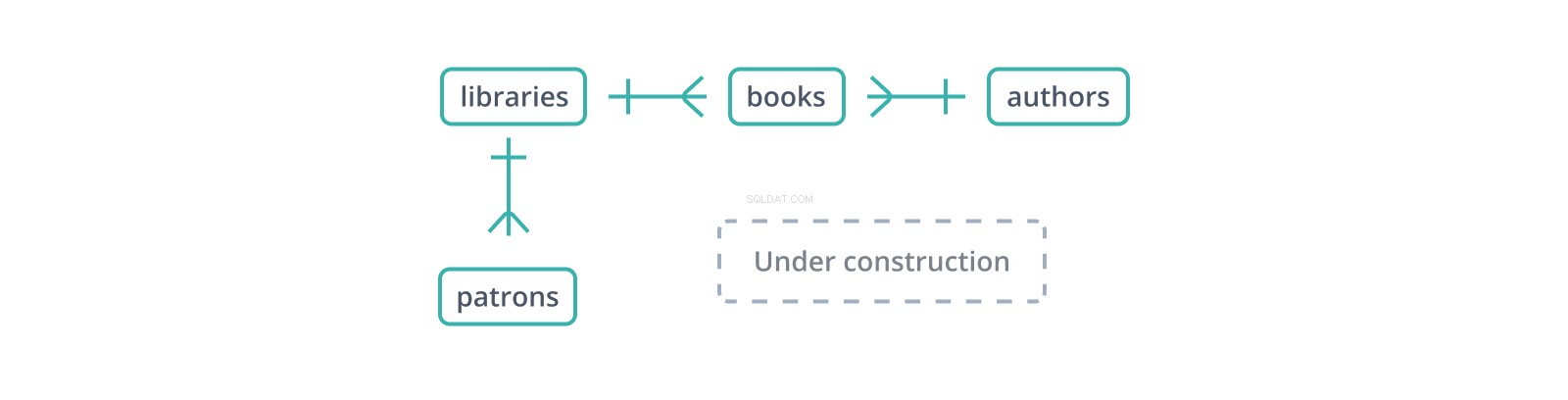
Dette uformelle "entity-relationship diagram" eller ERD viser begyndelsen af et skema for en database over biblioteker og deres samlinger og lånere. Hver kant repræsenterer et forhold mellem de tabeller, den forbinder. Den | glyf angiver en enkelt post på siden, mens "kragefod"-glyfen repræsenterer flere:et bibliotek rummer mange bøger og har mange lånere.
En fremmednøgle er en kopi af en anden tabels primære nøgle, kolonne for kolonne (et punkt til fordel for surrogatnøgler:kun én kolonne at kopiere og henvise til), med værdier, der forbinder poster i denne tabel med "overordnede" poster i den. I skemaet ovenfor er books tabel vedligeholder en library_id fremmednøgle til libraries , som indeholder bøger og et author_id til authors , der skriver dem. Men hvad sker der, hvis en bog indsættes med et author_id der ikke findes i authors ?
Hvis fremmednøglen ikke er begrænset -- dvs. det er bare en anden kolonne eller kolonner -- kan en bog have en forfatter, der ikke eksisterer. Dette er et problem:hvis nogen forsøger at følge linket mellem books og authors , de ender ingen steder. Hvis authors.author_id er et seriel heltal, er der også mulighed for, at ingen lægger mærke til det, før det falske author_id bliver til sidst tildelt, og du ender med en bestemt kopi af Don Quixote først tilskrevet ingen kendte og derefter til Pierre Menard, med Miguel Cervantes ingen steder at finde.
Begrænsning af fremmednøglen kan ikke forhindre, at en bog tilskrives forkert, hvis den fejlagtige author_id pege på en eksisterende post i authors , så andre kontroller og test er fortsat vigtige. Men sættet af eksisterende fremmednøgleværdier er næsten altid en lille delmængde af den mulige fremmednøgleværdier, så fremmednøglebegrænsninger vil fange og forhindre de fleste forkerte værdier. Med en fremmednøgle-begrænsning, Quixote med en ikke-eksisterende forfatter vil blive afvist i stedet for at blive optaget.
Er det her "Relationelle" i "Relationel database" kommer fra?
Fremmednøgler skaber relationer mellem tabeller, men tabeller, som vi kender dem, er matematisk relationer blandt sættene af mulige værdier for hver egenskab. En enkelt tupel relaterer en værdi for kolonne A til en værdi for kolonne B og frem. E.F. Codds originale papir bruger "relationel" i denne forstand.
Dette har ikke forårsaget nogen ende på forvirring og vil sandsynligvis fortsætte med at gøre det for evigt.
For visse værdier af korrekte
Der er mange flere måder, hvorpå data kan være forkerte, end der er behandlet her. Begrænsninger hjælper, men selv de er kun så fleksible; mange almindelige intra-tabel-specifikationer, såsom en grænse på to eller højere for antallet af gange, en værdi må vises i en kolonne, kan kun håndhæves med triggere.
Men der er også måder, hvorpå selve strukturen af en tabel kan føre til uoverensstemmelser. For at forhindre disse, bliver vi nødt til at samle både primære og fremmede nøgler, ikke bare for at definere og validere, men for at normalisere relationerne mellem tabeller. Først har vi dog knap ridset overfladen af, hvordan relationerne mellem tabeller definerer strukturen af selve databasen.