Introduktion
Der er to tankegange om at udføre beregninger i din database:folk, der synes, det er fantastisk, og folk, der tager fejl. Dette betyder ikke, at verden af funktioner, lagrede procedurer, genererede eller beregnede kolonner og triggere udelukkende er solskin og roser! Disse værktøjer er langt fra idiotsikre, og ugennemtænkte implementeringer kan fungere dårligt, traumatisere deres vedligeholdere og mere, hvilket går et stykke vej i retning af at forklare eksistensen af kontroverser.
Men databaser er per definition meget gode til at behandle og manipulere information, og de fleste af dem gør den samme kontrol og magt tilgængelig for deres brugere (SQLite og MS Access i mindre grad). Eksterne databehandlingsprogrammer starter på bagfoden med at skulle trække information ud af databasen, ofte på tværs af et netværk, før de kan gøre noget. Og hvor databaseprogrammer kan drage fuld fordel af native sæt-operationer, indeksering, midlertidige tabeller og andre frugter af et halvt århundredes databaseudvikling, har eksterne programmer af enhver kompleksitet en tendens til at involvere en vis grad af genopfindelse af hjul. Så hvorfor ikke sætte databasen i gang?
Her er grunden til, at du måske ikke ønsker at programmere din database!
- Databasefunktionalitet har en tendens til at blive usynlig - udløser især. Denne svaghed skalerer omtrent med størrelsen af teams og/eller applikationer, der interagerer med databasen, da færre mennesker husker eller er opmærksomme på programmeringen i databasen. Dokumentation hjælper, men kun så meget.
- SQL er et sprog, der er specialbygget til at manipulere datasæt. Den er ikke særlig god til ting, der ikke manipulerer datasæt, og den er mindre god, jo mere kompliceret de andre ting bliver.
- RDBMS-funktioner og SQL-dialekter er forskellige. Simple genererede kolonner er bredt understøttet, men portering af mere kompleks databaselogik til andre butikker tager som minimum tid og kræfter.
- Opgraderinger af databaseskemaer er normalt mere belastende end applikationsopgraderinger. Hurtigt skiftende logik opretholdes bedst andre steder, selvom det kan være værd at kigge på igen, når tingene stabiliserer sig.
- Håndtering af databaseprogrammer er ikke så ligetil, som man kunne håbe. Mange skemamigreringsværktøjer gør lidt eller intet for organisationen, hvilket fører til vidtstrakte forskelle og besværlige kodegennemgange (sqitchs afhængighedsgrafer og omarbejdning af individuelle objekter gør det til en bemærkelsesværdig undtagelse, og migra søger at omgå problemet fuldstændigt). Ved testning forbedrer rammer som pgTAP og utPLSQL sig på black-box integrationstests, men repræsenterer også en ekstra support og vedligeholdelsesforpligtelse.
- Med en etableret ekstern kodebase har enhver strukturel ændring en tendens til at være både indsatskrævende og risikabel.
På den anden side, til de opgaver, som det er egnet til, tilbyder SQL hastighed, præcision, holdbarhed og mulighed for at "kanonisere" automatiserede arbejdsgange. Datamodellering er mere end at fastgøre enheder som insekter til pap, og det er vanskeligt at skelne mellem data i bevægelse og data i hvile. Hvile er virkelig langsommere bevægelse i finere grad; information flyder altid herfra til der, og databaseprogrammerbarhed er et effektivt værktøj til at styre og styre disse strømme.
Nogle databasemotorer deler forskellen mellem SQL og andre programmeringssprog ved også at rumme disse andre programmeringssprog. SQL Server understøtter funktioner skrevet i ethvert .NET Framework-sprog; Oracle har lagrede Java-procedurer; PostgreSQL tillader udvidelser med C og er brugerprogrammerbar i Python, Perl og Tcl, med plugins, der tilføjer shell-scripts, R, JavaScript og mere. Afrundet de sædvanlige mistænkte, det er SQL eller ingenting for MySQL og MariaDB, MS Access er kun programmerbar i VBA, og SQLite er slet ikke brugerprogrammerbar.
Brug af ikke-SQL-sprog er en mulighed, hvis SQL er utilstrækkelig til en opgave, eller hvis du vil genbruge anden kode, men det vil ikke få dig uden om de andre problemer, der gør databaseprogrammering til et mangekantet sværd. Hvis der er noget, komplicerer ty til disse implementering og interoperabilitet yderligere. Advarsel scriptor:Lad forfatteren passe på.
Funktioner vs. procedurer
Som med andre aspekter af implementering af SQL-standarden varierer de nøjagtige detaljer en smule fra RDBMS til RDBMS. Generelt:
- Funktioner kan ikke kontrollere transaktioner.
- Funktioner returnerer værdier; procedurer kan ændre parametre betegnet
OUTellerINOUTsom så kan læses i den kaldende kontekst, men aldrig returnere et resultat (SQL Server undtaget). - Funktioner påkaldes inde fra SQL-sætninger for at udføre noget arbejde på poster, der hentes eller gemmes, mens procedurer står alene.
Mere specifikt tillader MySQL også rekursion og nogle yderligere SQL-sætninger i funktioner. SQL Server forbyder funktioner i at ændre data, udføre dynamisk SQL og håndtere fejl. PostgreSQL adskilte slet ikke lagrede procedurer fra funktioner før 2017 med version 11, så Postgres-funktioner kan gøre næsten alt, hvad procedurer kan, undtagen transaktionskontrol.
Så hvad skal man bruge hvornår? Funktioner er bedst egnede til logik, der anvender post for post, efterhånden som data lagres og hentes. Mere komplekse arbejdsgange, som påberåbes af dem selv og flytter data rundt internt, er bedre som procedurer.
Standarder og generation
Selv simple beregninger kan skabe problemer, hvis de udføres ofte nok, eller hvis der findes flere konkurrerende implementeringer. Operationer på værdier i en enkelt række -- tænk at konvertere mellem metriske og imperiale enheder, gange en sats med arbejdstimer for fakturasubtotaler, beregne arealet af en geografisk polygon -- kan erklæres i en tabeldefinition for at løse det ene eller det andet problem :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
De fleste RDBMS'er tilbyder et valg mellem "lagrede" og "virtuelle" genererede kolonner. I førstnævnte tilfælde beregnes og gemmes værdien, når rækken indsættes eller opdateres. Dette er den eneste mulighed med PostgreSQL fra version 12 og MS Access. Virtuelt genererede kolonner beregnes, når der forespørges som i visninger, så de optager ikke plads, men vil blive genberegnet oftere. Begge typer er strengt begrænset:værdier kan ikke afhænge af information uden for rækken, de tilhører, de kan ikke opdateres, og individuelle RDBMS'er kan have endnu mere specifikke begrænsninger. PostgreSQL, for eksempel, forbyder partitionering af en tabel på en genereret kolonne.
Genererede kolonner er et specialiseret værktøj. Oftere er det eneste, der kræves, en standard, hvis en værdi ikke er angivet på indsatsen. Funktioner som now() vises ofte som kolonnestandarder, men de fleste databaser tillader tilpassede såvel som indbyggede funktioner (undtagen MySQL, hvor kun current_timestamp kan være en standardværdi).
Lad os tage det temmelig tørre, men enkle eksempel på et partinummer i formatet YYYYXXX, hvor de første fire cifre repræsenterer det aktuelle år og de sidste tre en stigende tæller:det første parti produceret i år er 2020001, det andet 2020002, og så videre . Der er ingen standardtype eller indbygget funktion, der genererer en værdi som denne, men en brugerdefineret funktion kan nummerere hvert parti
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Referencedata i funktioner
Sekvenstilgangen ovenfor har én vigtig svaghed (og lot_counter vil stadig have den samme værdi, som den havde den 31. december. Der er dog mere end én måde at spore, hvor mange partier, der er blevet oprettet på et år, og ved at forespørge lots selv next_lot_number funktion kan garantere en korrekt værdi, efter at året ruller over.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Arbejdsgange
Selv en enkelt-sætningsfunktion har en afgørende fordel i forhold til ekstern kode:eksekvering forlader aldrig sikkerheden for databasens ACID-garantier. Sammenlign next_lot_number ovenfor til mulighederne for en klientapplikation eller endda en manuel proces, der udfører
Programmer, der er lagret med flere sætninger, åbner op for et enormt rum af muligheder, da SQL indeholder alle de værktøjer, du har brug for til at skrive procedurekode, fra undtagelseshåndtering til savepoints (det er endda Turing komplet med vinduesfunktioner og almindelige tabeludtryk!). Hele databehandlingsarbejdsgange kan udføres i databasen, hvilket minimerer eksponeringen for andre områder af systemet og eliminerer tidskrævende rundrejser mellem databasen og andre domæner.
Så meget af softwarearkitektur i almindelighed handler om styring og isolering af kompleksitet og forhindrer den i at sprede sig over grænserne mellem undersystemer. Hvis en mere eller mindre kompliceret arbejdsgang involverer at trække data ind i en applikations-backend, et script eller et cron-job, fordøje og tilføje til det og gemme resultatet -- er det tid til at spørge, hvad der virkelig kræver at vove sig uden for databasen.
Som nævnt ovenfor er dette et område, hvor forskelle mellem RDBMS-varianter og SQL-dialekter kommer til syne. En funktion eller procedure udviklet til én database vil sandsynligvis ikke køre på en anden uden ændringer, uanset om det erstatter SQL Servers TOP for en standard LIMIT klausul eller fuldstændig omarbejdning af, hvordan midlertidig tilstand er gemt i en virksomheds Oracle til PostgreSQL-migrering. Kanonisering af dine arbejdsgange i SQL forpligter dig også til din nuværende platform og dialekt mere grundigt end næsten noget andet valg, du kan træffe.
Beregninger i forespørgsler
Indtil videre har vi set på at bruge funktioner til at gemme og ændre data, uanset om det er bundet til tabeldefinitioner eller styring af multi-table arbejdsgange. På en måde er det den mere kraftfulde brug, som de kan bruges til, men funktioner har også en plads i datahentning. Mange værktøjer, du måske allerede bruger i dine forespørgsler, er implementeret som funktioner, fra standard indbyggede funktioner som count til udvidelser såsom Postgres' jsonb_build_object , PostGIS' ST_SnapToGrid , og mere. Da de er tættere integreret med selve databasen, er de selvfølgelig for det meste skrevet på andre sprog end SQL (f.eks. C i tilfælde af PostgreSQL og PostGIS).
Hvis du ofte oplever, at du selv (eller tror, du måske finder dig selv) har brug for at hente data og derefter udføre en operation på hver post, før den virkelig er klar, overvej i stedet at transformere dem på vej ud af databasen! Forventer du et antal arbejdsdage ud fra en dato? Generering af en forskel mellem to JSONB felter? Praktisk talt enhver beregning, der kun afhænger af de oplysninger, du forespørger på, kan udføres i SQL. Og hvad der gøres i databasen -- så længe der er adgang til den konsekvent -- er kanonisk, hvad angår alt, der er bygget oven på databasen.
Det skal siges:Hvis du arbejder med en applikations-backend, kan dens dataadgangsværktøjssæt begrænse, hvor mange kilometer du får ud af at udvide forespørgselsresultaterne med funktioner. De fleste sådanne biblioteker kan udføre vilkårlig SQL, men dem, der genererer almindelige SQL-sætninger baseret på modelklasser, tillader muligvis ikke tilpasning af forespørgslen SELECT lister. Genererede kolonner eller visninger kan være et svar her.
Triggers og konsekvenser
Funktioner og procedurer er kontroversielle nok blandt databasedesignere og brugere, men ting virkelig tage afsted med triggere. En trigger definerer en automatisk handling, normalt en procedure (SQLite tillader kun en enkelt sætning), der skal udføres før, efter eller i stedet for en anden handling.
Den initierende handling er generelt en indsættelse, opdatering eller sletning af en tabel, og triggerproceduren kan normalt indstilles til at udføre enten for hver post eller for sætningen som helhed. SQL Server tillader også triggere på opdaterbare visninger, mest som en måde at håndhæve mere detaljerede sikkerhedsforanstaltninger; og det, PostgreSQL og Oracle tilbyder alle en form for begivenhed eller
En almindelig lavrisikobrug for triggere er som en ekstra kraftig begrænsning, der forhindrer ugyldige data i at blive lagret. I alle større relationsdatabaser, kun primære og fremmede nøgler og UNIQUE begrænsninger kan evaluere information uden for kandidatposten. Det er ikke muligt i en tabeldefinition at erklære, at der for eksempel kun må oprettes to partier på en måned -- og den enkleste database-og-kode-løsning er sårbar over for en lignende race-tilstand som tæl-så-sæt-tilgangen til lot_number over. For at håndhæve enhver anden begrænsning, der involverer hele tabellen eller andre tabeller, skal du bruge en
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Når du begynder at udføre lots i sig selv kan være den endelige operation af en trigger initieret af en indsættelse i orders , uden nogen menneskelig bruger eller applikations-backend bemyndiget til at skrive til lots direkte. Eller som items er føjet til en masse, kan en trigger der håndtere opdatering af current_quantity , og start en anden proces, når den når target_quantity .
Triggere og funktioner kan køre på adgangsniveauet for deres definerer (i PostgreSQL, en SECURITY DEFINER erklæring ved siden af en funktions LANGUAGE ), som giver ellers begrænsede brugere magten til at igangsætte bredere processer -- og gør validering og test af disse processer endnu vigtigere.
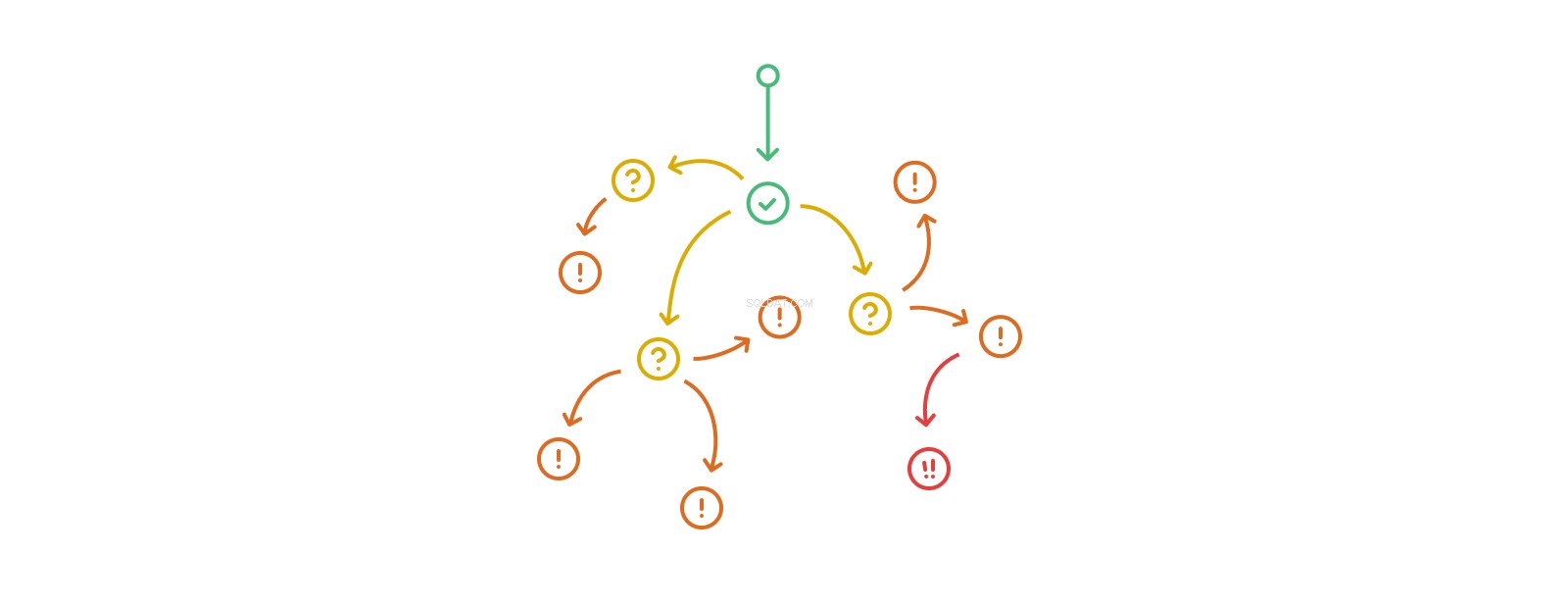
Trigger-action-trigger-action call-stakken kan blive vilkårligt lang, selvom ægte rekursion i form af ændring af de samme tabeller eller poster flere gange i et sådant flow er ulovligt på nogle platforme og mere generelt en dårlig idé under næsten alle omstændigheder. Triggernesting overgår hurtigt vores evne til at forstå dens omfang og virkninger. Databaser, der gør stor brug af indlejrede triggere, begynder at drive fra det kompliceredes til det komplekse, og bliver vanskelige eller umulige at analysere, fejlsøge og forudsige.
Praktisk programmerbarhed
Beregninger i databasen er ikke bare hurtigere og mere kortfattet udtrykt:de eliminerer tvetydighed og sætter standarder. Eksemplerne ovenfor frigør databasebrugere fra selv at skulle beregne lotnumre eller fra bekymringer om ved et uheld at skabe flere partier, end de kan håndtere. Især applikationsudviklere er ofte blevet trænet til at tænke på databaser som "dum lagring", der kun giver struktur og vedholdenhed, og kan således finde sig selv - eller endnu værre, ikke indse, at de - klodset artikulerer uden for databasen, hvad de kunne gøre mere effektivt i SQL.
Programmerbarhed er et uretmæssigt overset træk ved relationelle databaser. Der er grunde til at undgå det og mere til at begrænse dets brug, men funktioner, procedurer og triggere er alle kraftfulde værktøjer til at begrænse kompleksiteten, din datamodel pålægger de systemer, den er indlejret i.