SQLAlchemy hjælper dig med at arbejde med databaser i Python. I dette indlæg fortæller vi dig alt, hvad du behøver at vide for at komme i gang med dette modul.
I den forrige artikel talte vi om, hvordan man bruger Python i ETL-processen. Vi fokuserede på at få arbejdet gjort ved at udføre lagrede procedurer og SQL-forespørgsler. I denne artikel og den næste vil vi bruge en anden tilgang. I stedet for at skrive SQL-kode, bruger vi SQLAlchemy-værktøjssættet. Du kan også bruge denne artikel separat, som en hurtig introduktion til installation og brug af SQLAlchemy.
Parat? Lad os begynde.
Hvad er SQLAlchemy?
Python er kendt for sit antal og mange forskellige moduler. Disse moduler reducerer vores kodningstid betydeligt, fordi de implementerer rutiner, der er nødvendige for at opnå en specifik opgave. En række moduler, der arbejder med data, er tilgængelige, herunder SQLAlchemy.
For at beskrive SQLAlchemy bruger jeg et citat fra SQLAlchemy.org:
SQLAlchemy er Python SQL-værktøjssættet og Object Relational Mapper, der giver applikationsudviklere den fulde kraft og fleksibilitet af SQL.
Det giver en komplet suite af velkendt vedholdenhed på virksomhedsniveau mønstre, designet til effektiv og højtydende databaseadgang, tilpasset til et enkelt og pytonisk domænesprog.
Den vigtigste del her er lidt om ORM (objektrelationel mapper), som hjælper os med at behandle databaseobjekter som Python-objekter frem for lister.
Før vi går videre med SQLAlchemy, lad os holde pause og tale om ORM'er.
Fordele og ulemper ved at bruge ORM'er
Sammenlignet med rå SQL har ORM'er deres fordele og ulemper - og de fleste af disse gælder også for SQLAlchemy.
The Good Stuff:
- Kodeportabilitet. ORM tager sig af syntaktiske forskelle mellem databaser.
- Kun ét sprog er nødvendig for at håndtere din database. Selvom det for at være ærlig ikke burde være hovedmotivationen for at bruge en ORM.
- ORM'er forenkler din kode , for eksempel. de tager sig af forhold og behandler dem som genstande, hvilket er fantastisk, hvis du er vant til OOP.
- Du kan manipulere dine data inde i programmet .
Desværre kommer alt med en pris. The Not-So-Good Stuff om ORM'er:
- I nogle tilfælde kan en ORM være langsom .
- Skrivning af komplekse forespørgsler kan blive endnu mere kompliceret eller kan resultere i langsomme forespørgsler. Men dette er ikke tilfældet, når du bruger SQLAlchemy.
- Hvis du kender dit DBMS godt, så er det spild af tid at lære at skrive de samme ting i en ORM.
Nu hvor vi har håndteret dette emne, lad os vende tilbage til SQLAlchemy.
Før vi starter...
... lad os minde os selv om målet med denne artikel. Hvis du bare er interesseret i at installere SQLAlchemy og har brug for en hurtig tutorial om, hvordan du udfører enkle kommandoer, vil denne artikel gøre det. Kommandoerne præsenteret i denne artikel vil dog blive brugt i den næste artikel til at udføre ETL-processen og erstatte SQL (lagrede procedurer) og Python-kode, vi præsenterede i tidligere artikler.
Okay, lad os nu begynde lige fra begyndelsen:med at installere SQLAlchemy.
Installation af SQLAlchemy
1. Tjek, om modulet allerede er installeret
For at bruge et Python-modul skal du installere det (det vil sige, hvis det ikke tidligere var installeret). En måde at kontrollere, hvilke moduler der er installeret, er at bruge denne kommando i Python Shell:
help('modules')
For at kontrollere, om et specifikt modul er installeret, skal du blot prøve at importere det. Brug disse kommandoer:
import sqlalchemy sqlalchemy.__version__
Hvis SQLAlchemy allerede er installeret, vil den første linje blive udført. importer
Den anden kommando returnerer den aktuelle version af SQLAlchemy. Det returnerede resultat er afbilledet nedenfor:

Vi har også brug for et andet modul, og det er PyMySQL . Dette er et rent Python letvægts MySQL-klientbibliotek. Dette modul understøtter alt, hvad vi behøver for at arbejde med en MySQL-database, fra at køre simple forespørgsler til mere komplekse databasehandlinger. Vi kan kontrollere, om det eksisterer ved hjælp af help('modules') , som tidligere beskrevet, eller ved at bruge følgende to udsagn:
import pymysql pymysql.__version__
Selvfølgelig er det de samme kommandoer, som vi brugte til at teste, om SQLAlchemy var installeret.
Hvad hvis SQLAlchemy eller PyMySQL ikke allerede er installeret?
Det er ikke svært at importere tidligere installerede moduler. Men hvad hvis de moduler, du har brug for, ikke allerede er installeret?
Nogle moduler har en installationspakke, men for det meste bruger du pip-kommandoen til at installere dem. PIP er et Python-værktøj, der bruges til at installere og afinstallere moduler. Den nemmeste måde at installere et modul på (i Windows OS) er:
- Brug Kommandoprompt -> Kør -> cmd .
- Placering til Python-biblioteket cd C:\...\Python\Python37\Scripts .
- Kør kommandoen pip
install(i vores tilfælde kører vi pip install pyMySQLogpip installer sqlAlchemy.
PIP kan også bruges til at afinstallere det eksisterende modul. For at gøre det skal du bruge pip uninstall
2. Opretter forbindelse til databasen
Selvom det er vigtigt at installere alt det nødvendige for at bruge SQLAlchemy, er det ikke særlig interessant. Det er heller ikke rigtig en del af det, vi er interesserede i. Vi har ikke engang koblet os på de databaser, vi vil bruge. Det løser vi nu:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Ved at bruge scriptet ovenfor etablerer vi en forbindelse til databasen på vores lokale server, subscription_live database.
(Bemærk: Erstat
Lad os gennemgå scriptet, kommando for kommando.
import sqlalchemy from sqlalchemy.engine import create_engine
Disse to linjer importerer vores modul og create_engine funktion.
Dernæst etablerer vi en forbindelse til databasen på vores server.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Create_engine-funktionen opretter motoren og bruger .connect() , opretter forbindelse til databasen. create_engine funktion bruger disse parametre:
dialect+driver://username:password@host:port/database
I vores tilfælde er dialekten mysql , driveren er pymysql (tidligere installeret) og de resterende variabler er specifikke for den server og database(r), vi ønsker at oprette forbindelse til.
(Bemærk: Hvis du opretter forbindelse lokalt, skal du bruge localhost i stedet for din "lokale" IP-adresse, 127.0.0.1 og den relevante port :3306 .)

Resultatet af kommandoen print(engine_live.table_names()) er vist på billedet ovenfor. Som forventet fik vi listen over alle tabeller fra vores operationelle/live database.
3. Kørsel af SQL-kommandoer ved hjælp af SQLAlchemy
I dette afsnit vil vi analysere de vigtigste SQL-kommandoer, undersøge tabelstrukturen og udføre alle fire DML-kommandoer:SELECT, INSERT, UPDATE og DELETE.
Vi vil diskutere de udsagn, der bruges i dette script, separat. Bemærk venligst, at vi allerede har gennemgået forbindelsesdelen af dette script, og vi har allerede angivet tabelnavne. Der er mindre ændringer på denne linje:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Vi har lige importeret alt, hvad vi skal bruge fra SQLAlchemy.
Tabeller og struktur
Vi kører scriptet ved at skrive følgende kommando i Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Resultatet er det udførte script. Lad os nu analysere resten af scriptet.
SQLAlchemy importerer information relateret til tabeller, struktur og relationer. For at arbejde med disse oplysninger kan det være nyttigt at tjekke listen over tabeller (og deres kolonner) i databasen:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Dette returnerer simpelthen en liste over alle tabeller fra den tilsluttede database.
Bemærk: tabelnavne() metoden returnerer en liste over tabelnavne for den givne motor. Du kan udskrive hele listen eller gentage den ved hjælp af en løkke (som du kunne gøre med enhver anden liste).
Dernæst returnerer vi en liste over alle attributter fra den valgte tabel. Den relevante del af scriptet og resultatet er vist nedenfor:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
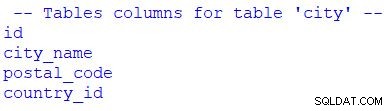
Du kan se, at jeg har brugt til at gå gennem resultatsættet. Vi kunne erstatte table_city.c med table_city.columns .
Bemærk: Processen med at indlæse databasebeskrivelsen og skabe metadata i SQLAlchemy kaldes refleksion.
Bemærk: MetaData er det objekt, der opbevarer information om objekter i databasen, så tabeller i databasen er også knyttet til dette objekt. Generelt gemmer dette objekt information om, hvordan databaseskemaet ser ud. Du vil bruge det som et enkelt kontaktpunkt, når du vil foretage ændringer i eller få fakta om DB-skemaet.
Bemærk: Attributterne autoload =True og autoload_with =engine_live skal bruges til at sikre, at tabelattributter vil blive uploadet (hvis de ikke allerede har været det).
VÆLG
Jeg tror ikke, jeg behøver at forklare, hvor vigtig SELECT-sætningen er :) Så lad os bare sige, at du kan bruge SQLAlchemy til at skrive SELECT-sætninger. Hvis du er vant til MySQL-syntaks, vil det tage lidt tid at tilpasse sig; stadig, alt er ret logisk. For at sige det så enkelt som muligt, vil jeg sige, at SELECT-sætningen er skåret op og nogle dele er udeladt, men alt er stadig i samme rækkefølge.
Lad os prøve et par SELECT-udsagn nu.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Den første er en simpel SELECT-sætning returnerer alle værdier fra den givne tabel. Syntaksen for denne sætning er meget enkel:Jeg har placeret navnet på tabellen i select() . Bemærk venligst, at jeg har:
- Forberedte sætningen -
stmt =select([table_city]. - Udskrev sætningen ved hjælp af
print(stmt), hvilket giver os en god idé om den erklæring, der netop er udført. Dette kan også bruges til fejlretning. - Udskrev resultatet med
print(connection_live.execute(stmt).fetchall()). - Slog gennem resultatet og udskrev hver enkelt post.
Bemærk: Fordi vi også indlæste primære og fremmede nøglebegrænsninger i SQLAlchemy, tager SELECT-sætningen en liste over tabelobjekter som argumenter og etablerer automatisk relationer, hvor det er nødvendigt.
Resultatet er vist på billedet nedenfor:

Python vil hente alle attributter fra tabellen og gemme dem i objektet. Som vist kan vi bruge dette objekt til at udføre yderligere operationer. Det endelige resultat af vores erklæring er en liste over alle byer fra byen tabel.
Nu er vi klar til en mere kompleks forespørgsel. Jeg har lige tilføjet en ORDER BY-klausul .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Bemærk: asc() metoden udfører stigende sortering mod det overordnede objekt ved at bruge definerede kolonner som parametre.
Den returnerede liste er den samme, men nu er den sorteret efter id-værdien i stigende rækkefølge. Det er vigtigt at bemærke, at vi blot har tilføjet .order_by( til den forrige SELECT-forespørgsel. .order_by(...) metode giver os mulighed for at ændre rækkefølgen af det returnerede resultatsæt på samme måde, som vi ville bruge i en SQL-forespørgsel. Derfor bør parametre følge SQL-logik ved at bruge kolonnenavne eller kolonnerækkefølge og ASC eller DESC.
Dernæst vil vi tilføje WHERE til vores SELECT-erklæring.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Bemærk: .where() metode bruges til at teste en betingelse, vi har brugt som argument. Vi kunne også bruge .filter() metode, som er bedre til at filtrere mere komplekse forhold.
Endnu en gang, .where del er simpelthen sammenkædet med vores SELECT-sætning. Bemærk, at vi har sat tilstanden inden for beslagene. Uanset hvilken tilstand der er i parentes, testes det på samme måde, som det ville blive testet i WHERE-delen af en SELECT-sætning. Ligestillingsbetingelsen testes med ==i stedet for =.
Det sidste, vi vil prøve med SELECT, er at forbinde to borde. Lad os tage et kig på koden og dens resultat først.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Der er to vigtige dele i ovenstående erklæring:
vælg([table_city.columns.city_name, table_country.columns.country_name])definerer, hvilke kolonner der returneres i vores resultat..select_from(table_city.join(table_country))definerer sammenføjningsbetingelsen/-tabellen. Bemærk, at vi ikke behøvede at skrive den fulde sammenføjningstilstand ned, inklusive nøglerne. Dette skyldes, at SQLAlchemy "ved", hvordan disse to tabeller er forbundet, da primære nøgler og fremmednøgler-regler importeres i baggrunden.
INDSÆT / OPDATERING / SLET
Dette er de tre resterende DML-kommandoer, vi vil dække i denne artikel. Selvom deres struktur kan blive meget kompleks, er disse kommandoer normalt meget enklere. Den anvendte kode er præsenteret nedenfor.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Det samme mønster bruges til alle tre sætninger:forberede sætningen, udskrive og udføre den og udskrive resultatet efter hver sætning, så vi kan se, hvad der rent faktisk skete i databasen. Bemærk endnu en gang, at dele af sætningen blev behandlet som objekter (.values(), .where()).

Vi vil bruge denne viden i den kommende artikel til at bygge et helt ETL-script ved hjælp af SQLAlchemy.
Næste:SQLAlchemy i ETL-processen
I dag har vi analyseret, hvordan man opsætter SQLAlchemy, og hvordan man udfører simple DML-kommandoer. I den næste artikel vil vi bruge denne viden til at skrive hele ETL-processen ved hjælp af SQLAlchemy.
Du kan downloade hele scriptet, der er brugt i denne artikel her.