I dag er databaser, der spænder over flere skyer, ret almindelige. De lover høj tilgængelighed og mulighed for nemt at implementere katastrofegendannelsesprocedurer. De er også en metode til at undgå leverandørlåsning:Hvis du designer dit databasemiljø, så det kan fungere på tværs af flere cloud-udbydere, er du højst sandsynligt ikke bundet til funktioner og implementeringer, der er specifikke for en bestemt udbyder. Dette gør det nemmere for dig at tilføje en anden infrastrukturudbyder til dit miljø, hvad enten det er en anden cloud- eller on-prem-opsætning. En sådan fleksibilitet er meget vigtig, da der er hård konkurrence mellem cloud-udbydere, og migrering fra den ene til den anden kan være ganske mulig, hvis det ville blive understøttet af reducerede omkostninger.
At spænde din infrastruktur på tværs af flere datacentre (fra samme udbyder eller ej, det er lige meget) bringer alvorlige problemer med at løse. Hvordan kan man designe hele infrastrukturen på en måde, så dataene er sikre? Hvordan håndterer du udfordringer, som du står over for, mens du arbejder i et multi-cloud-miljø? I denne blog vil vi tage et kig på et, men uden tvivl det mest seriøse potentiale i en split-hjerne. Hvad betyder det? Lad os grave lidt i, hvad split-brain er.
Hvad er "Split-Brain"?
Split-brain er en tilstand, hvor et miljø, der består af flere noder, lider af netværksopdeling og er blevet opdelt i flere segmenter, der ikke har kontakt med hinanden. Det enkleste tilfælde vil se sådan ud:
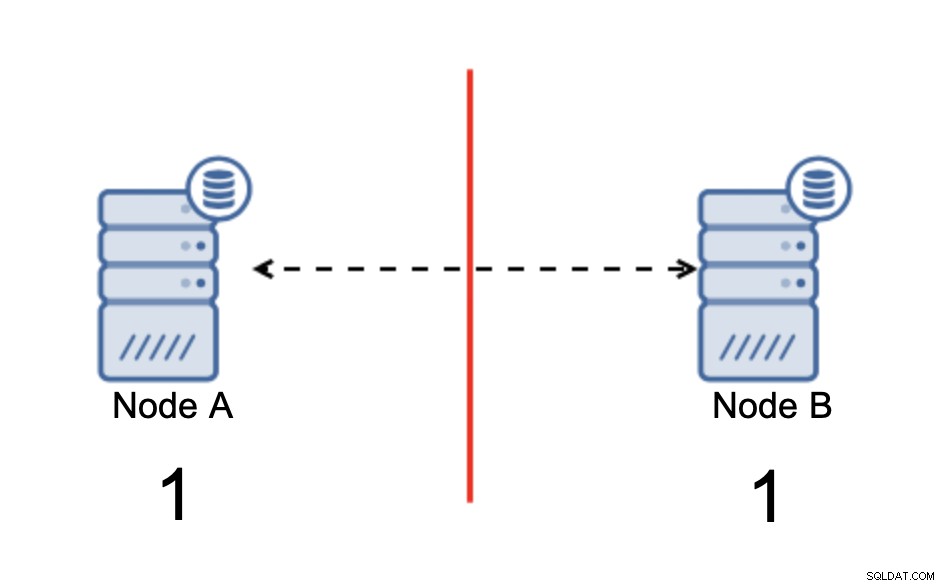
Vi har to noder, A og B, forbundet over et netværk ved hjælp af bi -retningsbestemt asynkron replikation. Derefter afbrydes netværksforbindelsen mellem disse noder. Som et resultat kan begge noder ikke forbindes til hinanden, og eventuelle ændringer, der udføres på node A, kan ikke overføres til node B og omvendt. Begge noder, A og B, er oppe og accepterer forbindelser, de kan bare ikke udveksle data. Dette kan føre til alvorlige problemer, da applikationen kan foretage ændringer på begge noder og forvente at se den fulde tilstand af databasen, mens den faktisk kun fungerer på en delvist kendt datatilstand. Som et resultat kan der foretages forkerte handlinger af applikationen, forkerte resultater kan blive præsenteret for brugeren og så videre. Vi synes, det er klart, at split-brain potentielt er en meget farlig tilstand, og en af prioriteterne ville være at håndtere det til en vis grad. Hvad kan man gøre ved det?
Sådan undgår du split-hjerne
Kort sagt, det afhænger af. Det vigtigste problem at håndtere er det faktum, at noder er oppe at køre, men ikke har forbindelse mellem dem, derfor er de uvidende om tilstanden af den anden node. Generelt har MySQL asynkron replikation ikke nogen form for mekanisme, der internt ville løse problemet med den splittede hjerne. Du kan prøve at implementere nogle løsninger, der hjælper dig med at undgå split-brain, men de kommer med begrænsninger, eller de løser stadig ikke problemet fuldt ud.
Når vi vover os væk fra den asynkrone replikering, ser tingene anderledes ud. MySQL Group Replication og MySQL Galera Cluster er teknologier, der drager fordel af build-it-klyngebevidsthed. Begge disse løsninger opretholder kommunikationen på tværs af noder og sikrer, at klyngen er opmærksom på nodernes tilstand. De implementerer en kvorumsmekanisme, der styrer, om klynger kan være operationelle eller ej.
Lad os diskutere disse to løsninger (asynkron replikering og kvorumbaserede klynger) mere detaljeret.
Kvorumsbaseret klyngedannelse
Vi vil ikke diskutere implementeringsforskellene mellem MySQL Galera Cluster og MySQL Group Replication, vi vil fokusere på den grundlæggende idé bag den kvorumsbaserede tilgang, og hvordan den er designet til at løse problemet med split-hjerne i din klynge.
Konklusionen er, at:klynge, for at fungere, kræver, at størstedelen af dens noder er tilgængelige. Med dette krav kan vi være sikre på, at mindretallet aldrig rigtig kan påvirke resten af klyngen, fordi mindretallet ikke burde være i stand til at udføre nogen handlinger. Dette betyder også, at en klynge skal have mindst tre knudepunkter for at kunne håndtere en fejl i en knude. Hvis du kun har to noder:
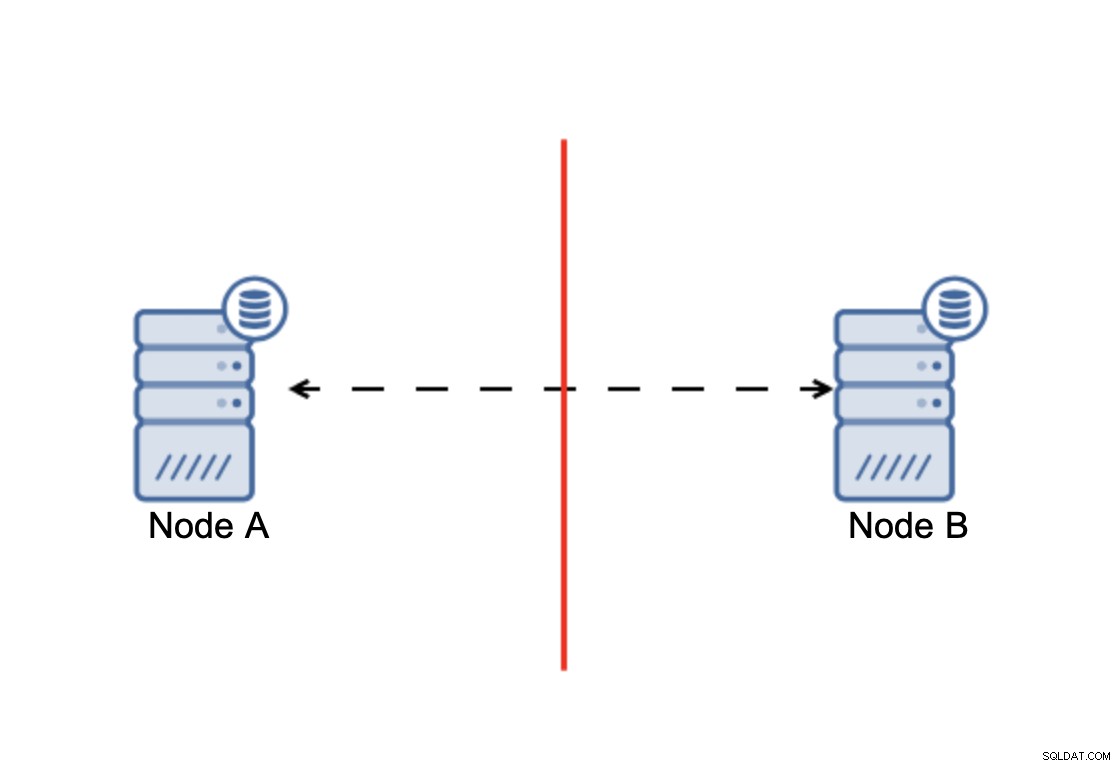
Når der er en netværksdeling, ender du med to dele af klynge, der hver især består af præcis 50% af de samlede noder i klyngen. Ingen af disse dele har flertal. Hvis du har tre noder, er tingene dog anderledes:
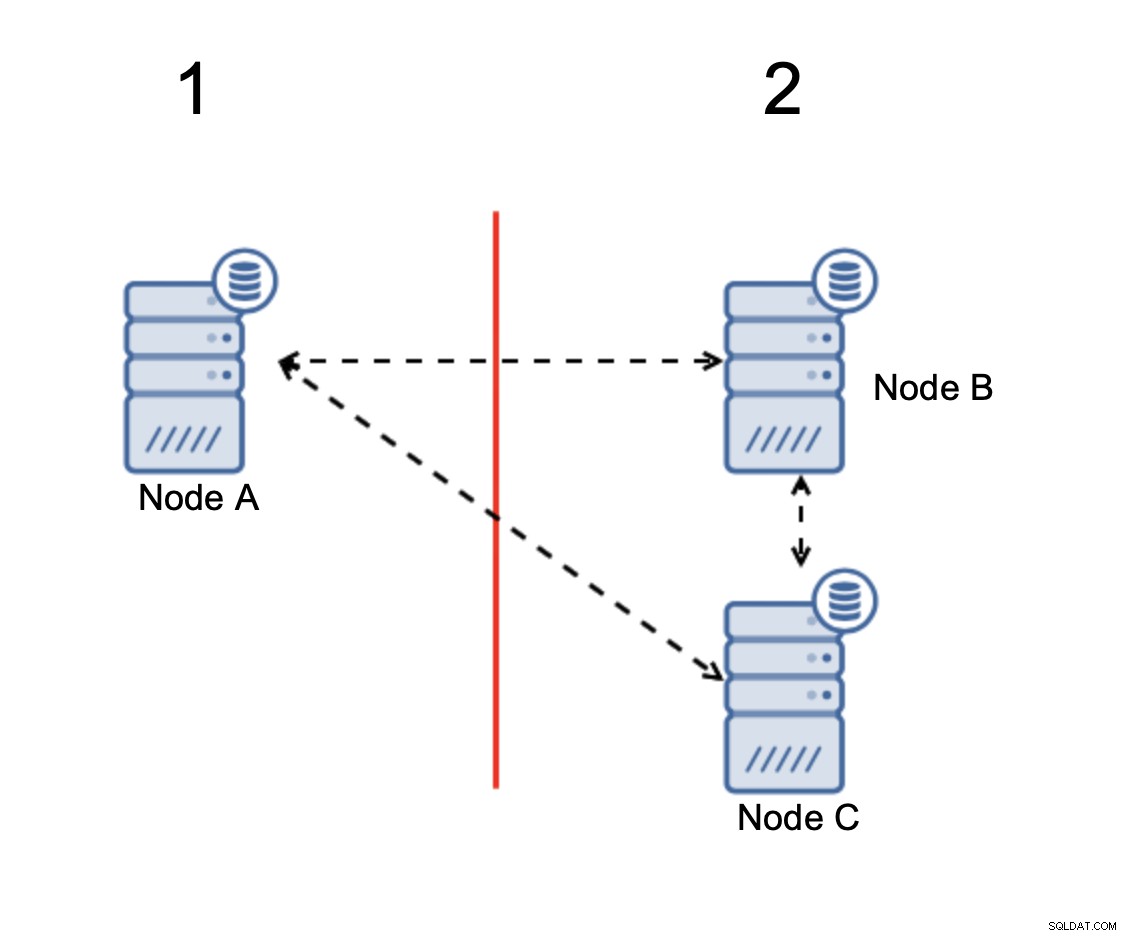
Knudepunkter B og C har flertallet:den del består af to noder ud af tre, således at den kan fortsætte med at fungere. På den anden side repræsenterer knude A kun de 33 % af knudepunkterne i klyngen, så den har ikke et flertal, og den vil ophøre med at håndtere trafik for at undgå den splittede hjerne.
Med en sådan implementering er det meget usandsynligt, at split-brain vil ske (det ville skulle introduceres gennem nogle mærkelige og uventede netværkstilstande, raceforhold eller almindelige fejl i klyngekoden. Selvom det ikke er umuligt at støde på sådanne forhold, at bruge en af de løsninger, der er quorum-baserede, er den bedste mulighed for at undgå den split-hjerne, der eksisterer i dette øjeblik.
Asynkron replikering
Selv om det ikke er det ideelle valg, når det kommer til at håndtere split-brain, er asynkron replikering stadig en levedygtig mulighed. Der er flere ting, du bør overveje, før du implementerer en multi-cloud-database med asynkron replikering.
Først failover. Asynkron replikering kommer med én forfatter - kun master skal være skrivbar, og andre noder skal kun betjene skrivebeskyttet trafik. Udfordringen er, hvordan man håndterer mesterfejlen?
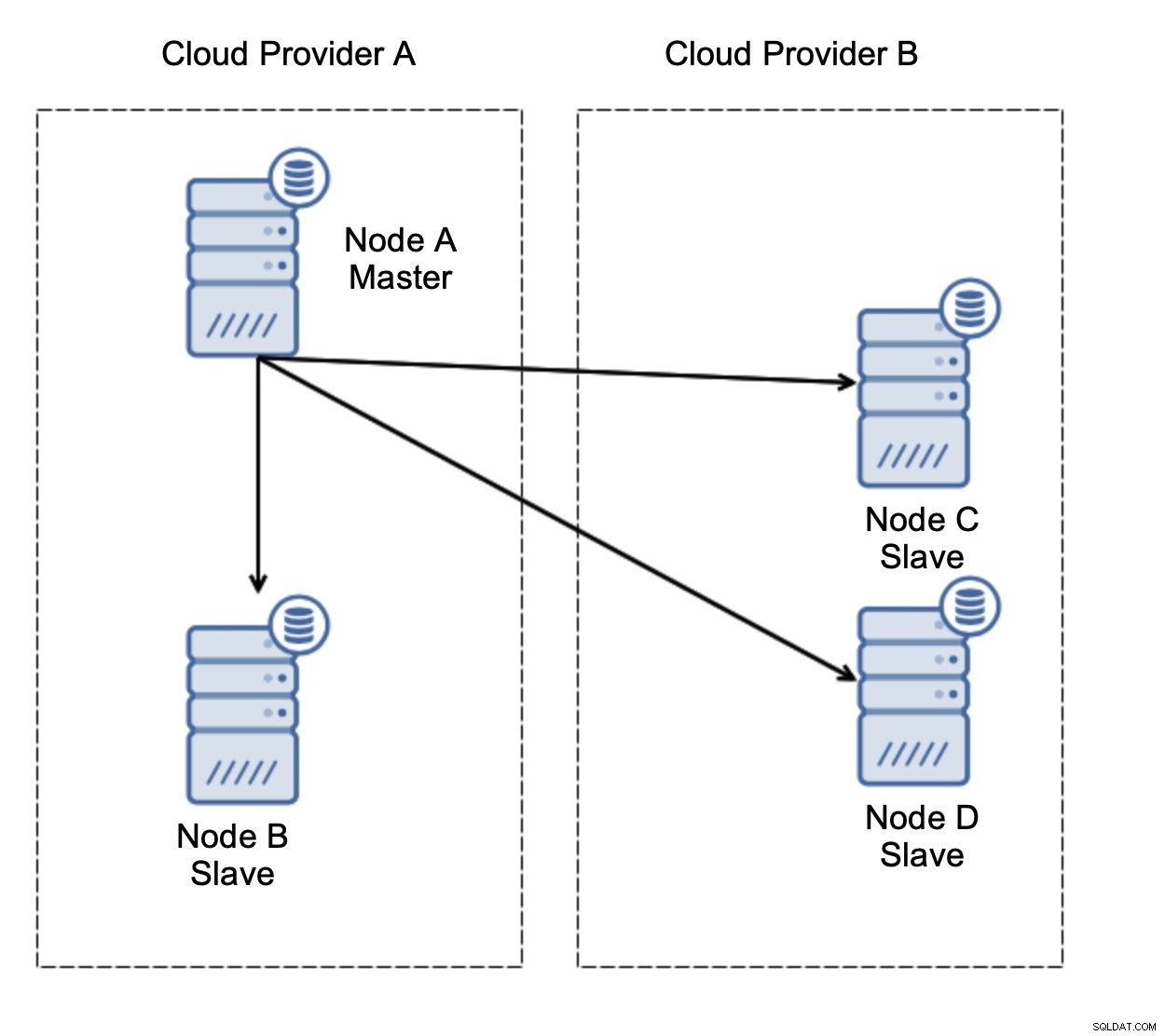
Lad os overveje opsætningen som på diagrammet ovenfor. Vi har to cloud-udbydere, to noder i hver. Udbyder A er også vært for masteren. Hvad skal der ske, hvis mesteren fejler? En af slaverne bør forfremmes for at sikre, at databasen vil fortsætte med at være operationel. Ideelt set bør det være en automatiseret proces for at reducere den tid, der er nødvendig for at bringe databasen til den operationelle tilstand. Hvad ville der dog ske, hvis der ville være en netværkspartitionering? Hvordan forventes vi at verificere klyngens tilstand?
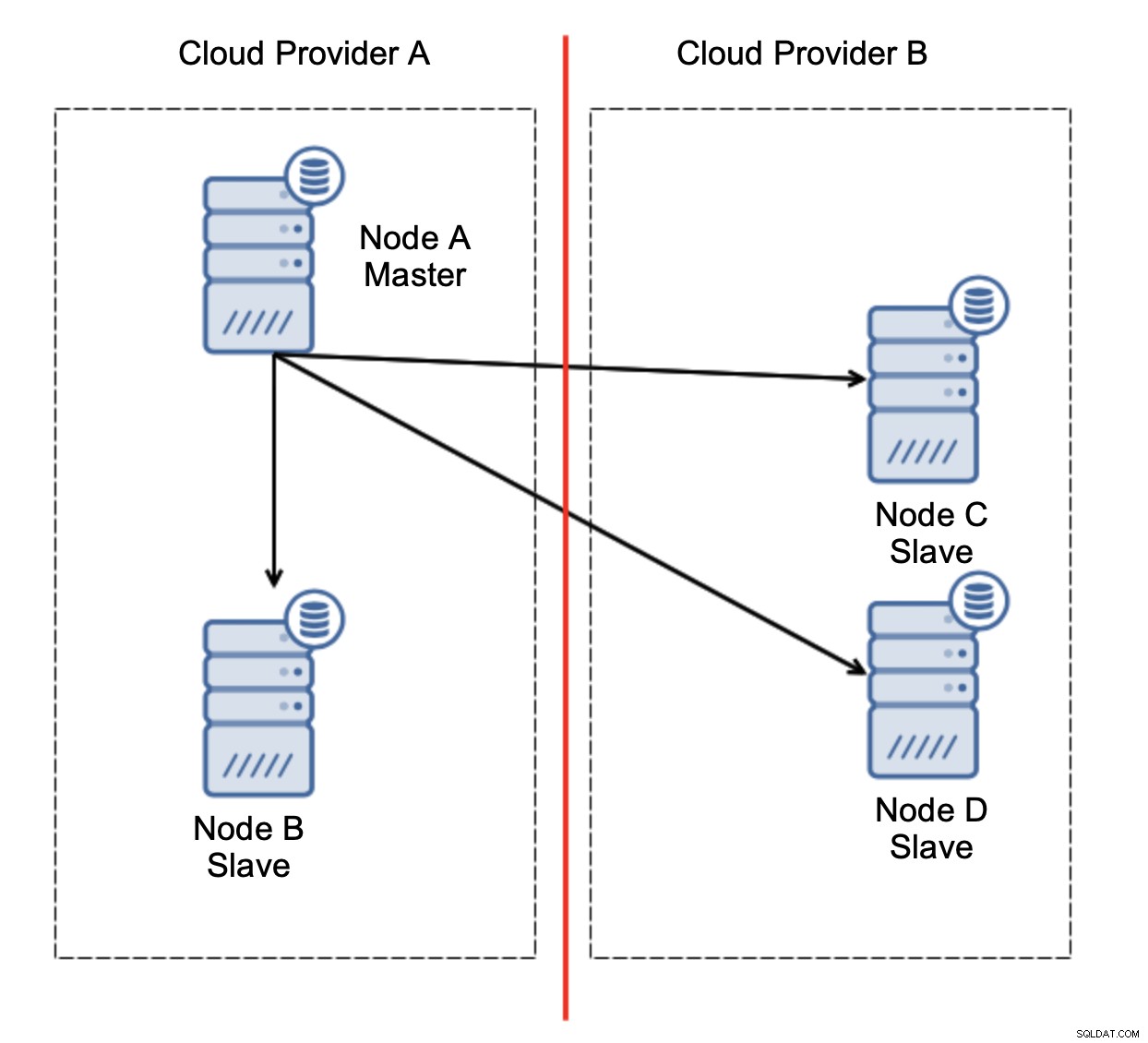
Her er udfordringen. Netværksforbindelsen går tabt mellem to cloud-udbydere. Fra nodernes C og Ds synspunkt er både node B og master node A offline. Skal node C eller D forfremmes til at blive en mester? Men den gamle mester er stadig oppe - den styrtede ikke ned, den er bare ikke tilgængelig over netværket. Hvis vi vil promovere en af noderne placeret hos udbyder B, ender vi med to skrivbare mastere, to datasæt og split hjerne:
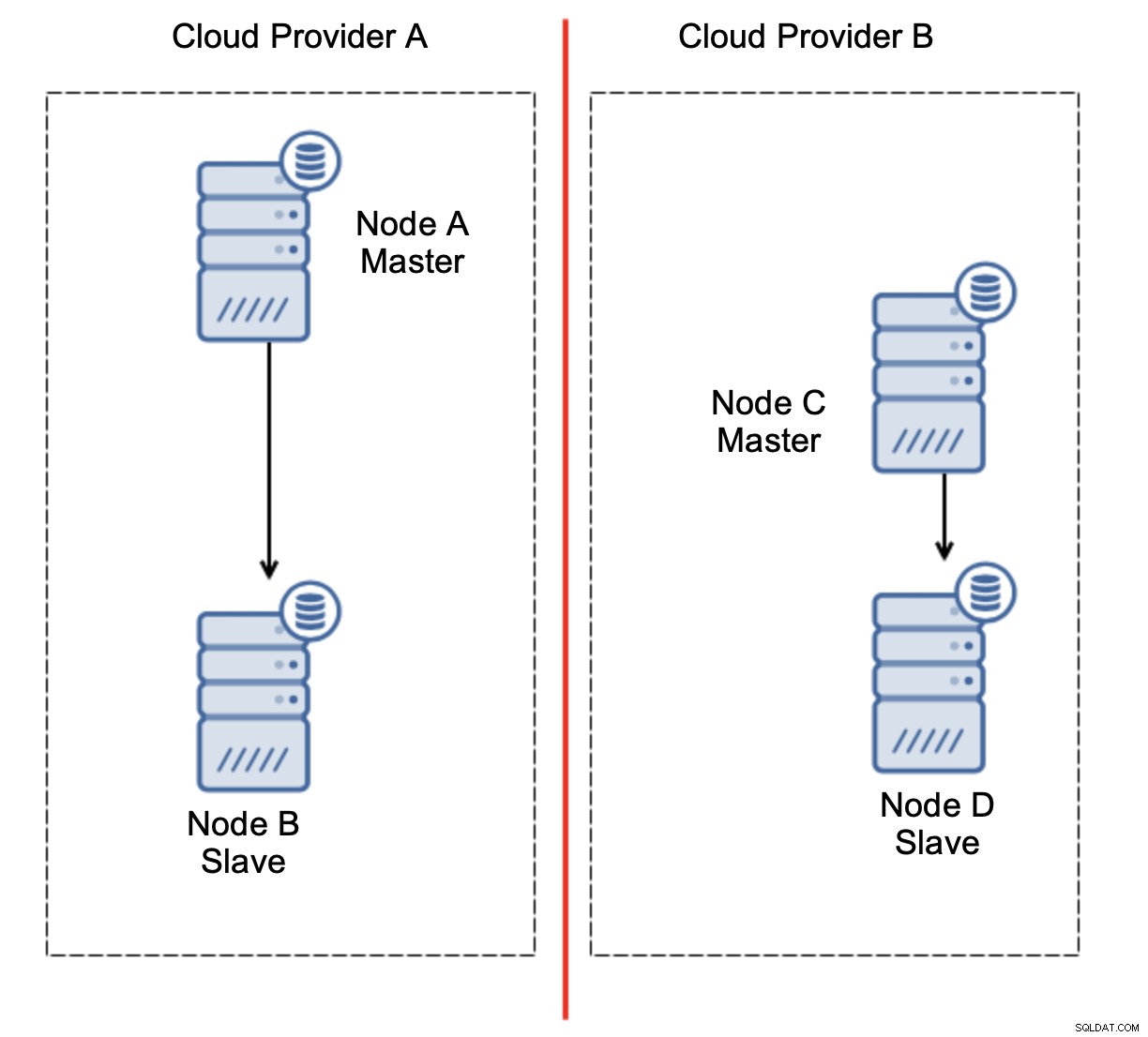
Dette er bestemt ikke noget, vi ønsker. Der er et par muligheder her. For det første kan vi definere failover-regler på en måde, så failover kun kan ske i et af netværkssegmenterne, hvor masteren er placeret. I vores tilfælde ville det betyde, at kun node B automatisk kunne forfremmes til at blive en master. På den måde kan vi sikre, at den automatiske failover vil ske, hvis node A er nede, men der vil ikke blive foretaget nogen handling, hvis der er en netværkspartitionering. Nogle af de værktøjer, der kan hjælpe dig med at håndtere automatiserede failovers (såsom ClusterControl) understøtter hvide og sorte lister, hvilket giver brugerne mulighed for at definere, hvilke noder der kan betragtes som kandidater til failover, og hvilke der aldrig bør bruges som mastere.
En anden mulighed ville være at implementere en slags "topologibevidsthed"-løsning. For eksempel kan man prøve at kontrollere mastertilstanden ved hjælp af eksterne tjenester som load balancers.
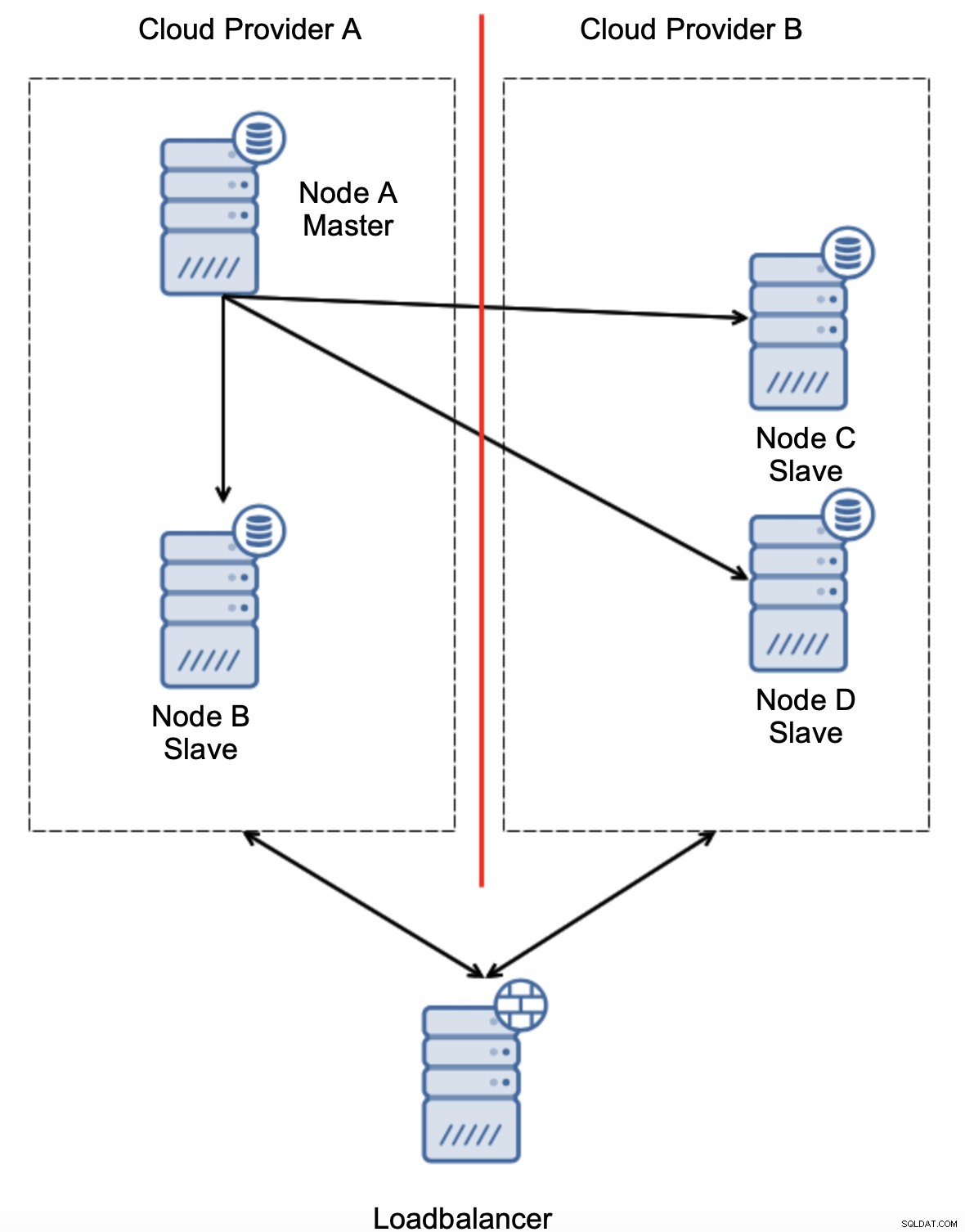
Hvis failover-automatiseringen kunne kontrollere topologiens tilstand som set af load balancer, kan det være, at load balanceren, der er placeret et tredje sted, faktisk kan nå til begge datacentre og gøre det klart, at noder i cloud-udbyder A ikke er nede, de kan bare ikke nås fra cloud-udbyder B. Sådanne et ekstra lag af kontroller er implementeret i ClusterControl.
Endelig, uanset hvilket værktøj du bruger til at implementere automatiseret failover, kan det også være designet, så det er kvorumsbevidst. Så kan du med tre noder på tværs af tre lokationer nemt se, hvilken del af infrastrukturen der skal holdes i live, og hvilken der ikke skal.
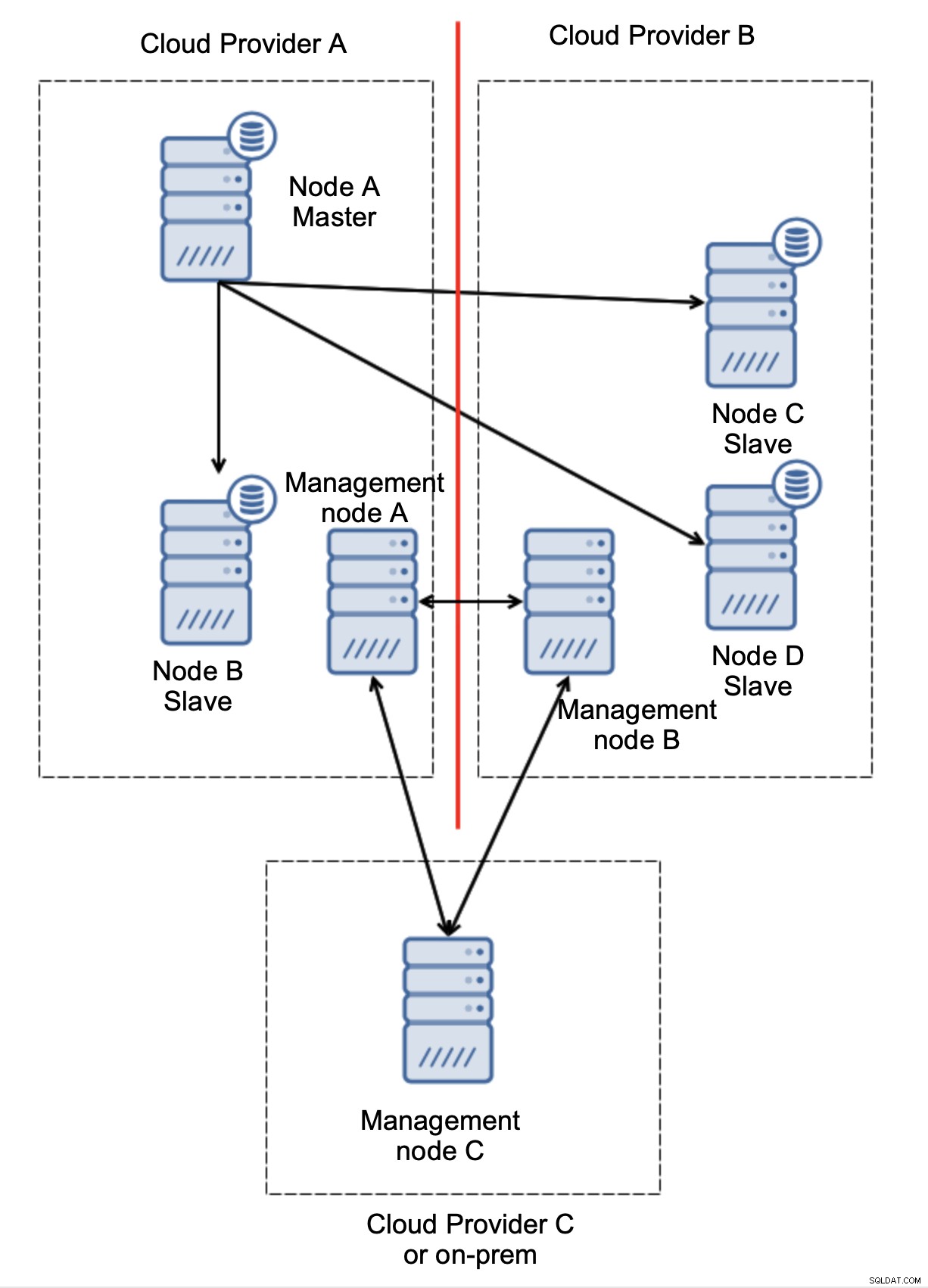
Her kan vi tydeligt se, at problemet kun er relateret til forbindelsen mellem udbyder A og B. Management node C vil fungere som et relæ, og som følge heraf bør der ikke startes failover. På den anden side, hvis ét datacenter er helt afbrudt:

Det er også ret tydeligt, hvad der skete. Ledelsesknudepunkt A vil rapportere, at det ikke kan nå ud til størstedelen af klyngen, mens ledelsesknudepunkt B og C vil udgøre flertallet. Det er muligt at bygge videre på dette og for eksempel skrive scripts, der vil styre topologien i overensstemmelse med tilstanden af styringsknuden. Det kan betyde, at de scripts, der udføres i cloud-udbyder A, vil opdage, at administrationsknude A ikke udgør flertallet, og de vil stoppe alle databasenoder for at sikre, at der ikke vil ske nogen skrivninger i den opdelte cloud-udbyder.
ClusterControl, når den implementeres i tilstanden High Availability, kan behandles som de administrationsknuder, vi brugte i vores eksempler. Tre ClusterControl-noder, oven i RAFT-protokollen, kan hjælpe dig med at bestemme, om et givet netværkssegment er opdelt eller ej.
Konklusion
Vi håber, at dette blogindlæg giver dig en idé om split-brain-scenarier, der kan ske for MySQL-implementeringer, der spænder over flere cloud-platforme.