Brug af Galera cluster er en fantastisk måde at bygge et meget tilgængeligt miljø til MySQL eller MariaDB på. Det er et delt-intet klyngemiljø, som kan skaleres selv ud over 12-15 noder. Galera har dog nogle begrænsninger. Det skinner i miljøer med lav latens, og selvom det kan bruges på tværs af WAN, er ydeevnen begrænset af netværksforsinkelse. Galera-ydeevnen kan også blive påvirket, hvis en af noderne begynder at opføre sig forkert. For eksempel kan overdreven belastning på en af noderne bremse den, hvilket resulterer i langsommere håndtering af skrivningerne, og det vil påvirke alle de andre noder i klyngen. På den anden side er det ganske umuligt at drive en virksomhed uden at analysere dine data. En sådan analyse kræver typisk at køre tunge forespørgsler, hvilket er helt anderledes end en OLTP-arbejdsbelastning. I dette blogindlæg vil vi diskutere en nem måde at køre analytiske forespørgsler på data gemt i Galera Cluster til MySQL eller MariaDB på en måde, så det ikke påvirker ydeevnen af kerneklyngen.
Hvordan kører man analytiske forespørgsler på Galera Cluster?
Som vi sagde, er det muligt at køre langvarige forespørgsler direkte på en Galera-klynge, men måske ikke så god idé. Hardwareafhængigt kan dette være en acceptabel løsning (hvis du bruger stærk hardware, og du ikke vil køre en multi-threaded analytisk arbejdsbyrde), men selvom CPU-udnyttelse ikke vil være et problem, vil det faktum, at en af noderne vil have blandet arbejdsbyrde ( OLTP og OLAP) vil alene udgøre nogle præstationsudfordringer. OLAP-forespørgsler fjerner data, der kræves til din OLTP-arbejdsbyrde, fra bufferpuljen, og dette vil sænke dine OLTP-forespørgsler. Heldigvis er der en enkel, men effektiv måde at adskille analytisk arbejdsbyrde fra almindelige forespørgsler - en asynkron replikeringsslave.
Replikeringsslave er en meget simpel løsning - alt hvad du behøver er blot endnu en vært, som kan klargøres, og asynkron replikering skal konfigureres fra Galera Cluster til den node. Med asynkron replikering vil slaven ikke påvirke resten af klyngen på nogen måde. Lige meget om den er tungt belastet, bruger anden (mindre kraftfuld) hardware, vil den bare fortsætte med at replikere fra kerneklyngen. Det værst tænkelige scenarie er, at replikeringsslaven begynder at halte bagud, men så er det op til dig at implementere flertrådsreplikering eller i sidste ende at opskalere replikeringsslaven.
Når replikeringsslaven er oppe at køre, bør du køre de tungere forespørgsler på den og aflæse Galera-klyngen. Dette kan gøres på flere måder, afhængigt af din opsætning og miljø. Hvis du bruger ProxySQL, kan du nemt rette forespørgsler til den analytiske slave baseret på kildeværten, brugeren, skemaet eller endda selve forespørgslen. Ellers er det op til din ansøgning at sende analytiske forespørgsler til den korrekte vært.
Opsætning af en replikeringsslave er ikke særlig kompleks, men det kan stadig være vanskeligt, hvis du ikke er dygtig til MySQL og værktøjer som xtrabackup. Hele processen ville bestå af opsætning af repository på en ny server og installation af MySQL-databasen. Så bliver du nødt til at klargøre den vært ved hjælp af data fra Galera-klyngen. Du kan bruge xtrabackup til det, men andre værktøjer som mydumper/myloader eller endda mysqldump vil også fungere (så længe du udfører dem korrekt). Når dataene er der, bliver du nødt til at konfigurere replikeringen mellem en master Galera-knude og replikeringsslaven. Endelig skal du omkonfigurere dit proxy-lag til at inkludere den nye slave og dirigere trafikken hen til den eller lave justeringer i, hvordan din applikation forbinder til databasen for at omdirigere noget af belastningen til replikeringsslaven.
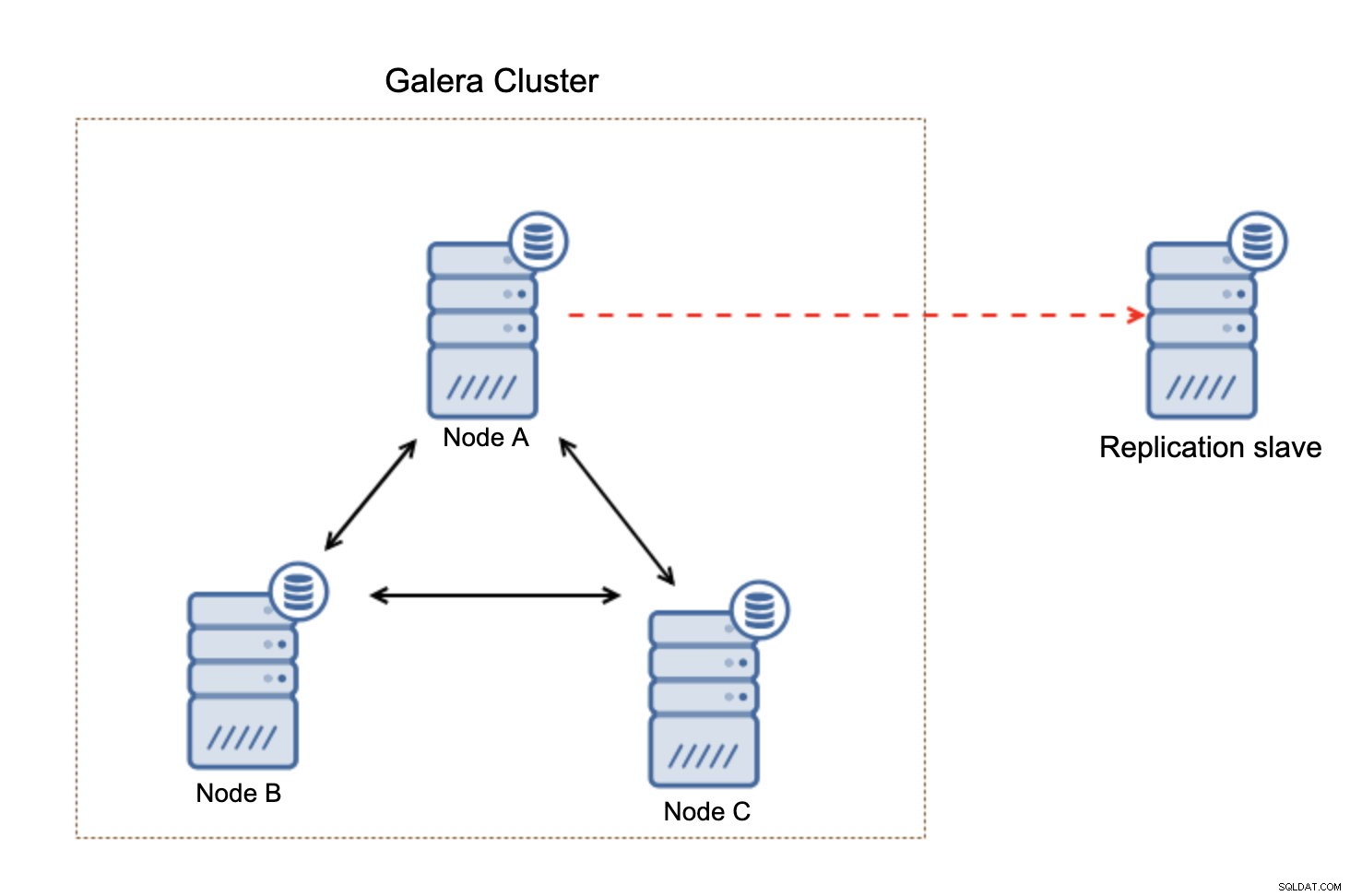
Hvad der er vigtigt at huske på, denne opsætning er ikke modstandsdygtig. Hvis "master" Galera-knuden ville gå ned, vil replikeringslinket blive brudt, og det vil tage en manuel handling for at slave replikaen fra en anden master-knude i Galera-klyngen.
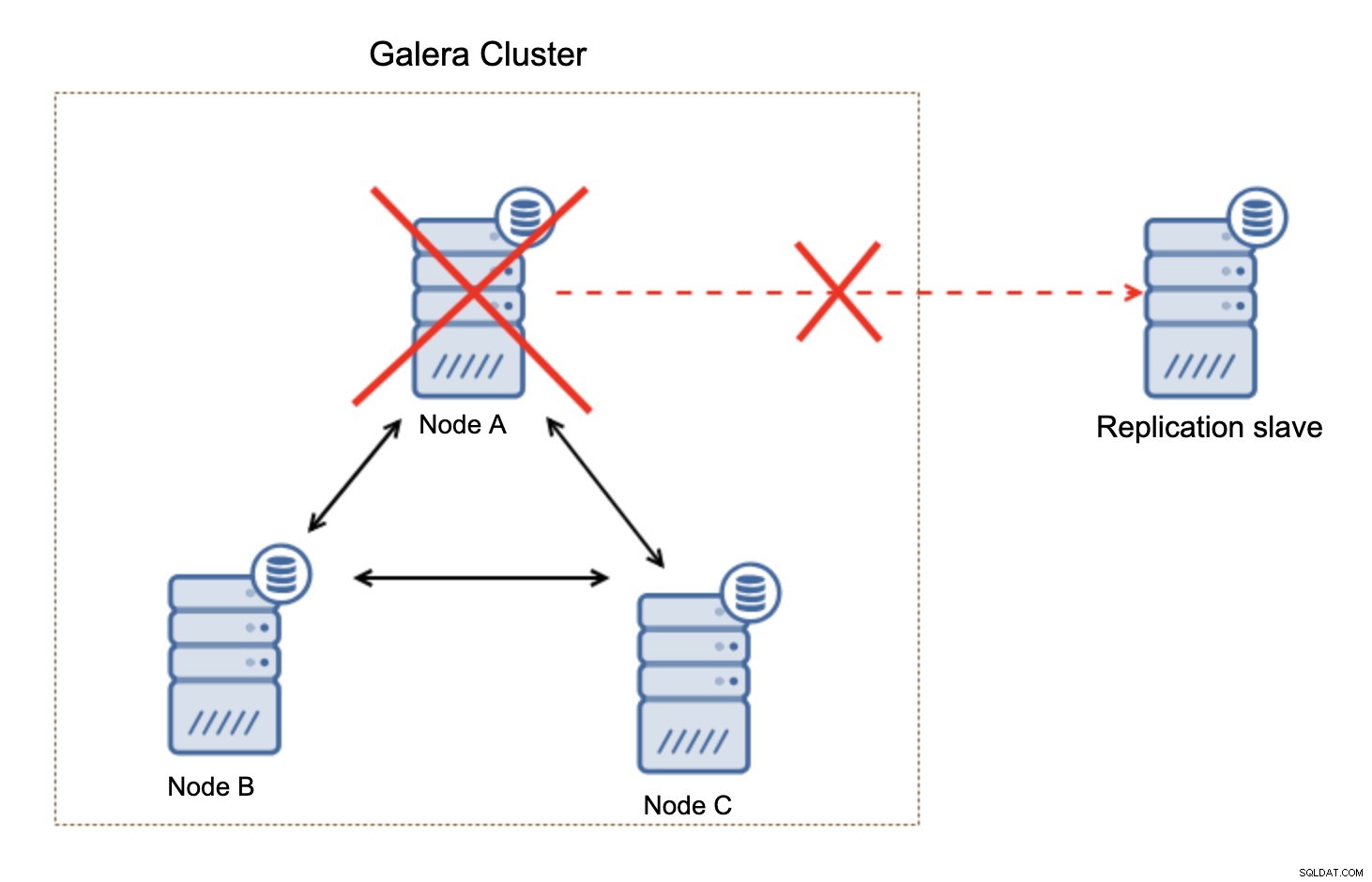
Dette er ikke en stor sag, især hvis du bruger replikering med GTID (Global Transaction ID), men du skal identificere, at replikationen er brudt og derefter foretage den manuelle handling.
Hvordan konfigurerer man den asynkrone slave til Galera Cluster ved hjælp af ClusterControl?
Heldigvis, hvis du bruger ClusterControl, kan hele processen automatiseres, og det kræver blot en håndfuld klik. Den oprindelige tilstand er allerede blevet konfigureret ved hjælp af ClusterControl - en Galera-klynge med 3 noder med 2 ProxySQL-noder og 2 Keepalive-knuder for høj tilgængelighed af både database og proxy-lag.
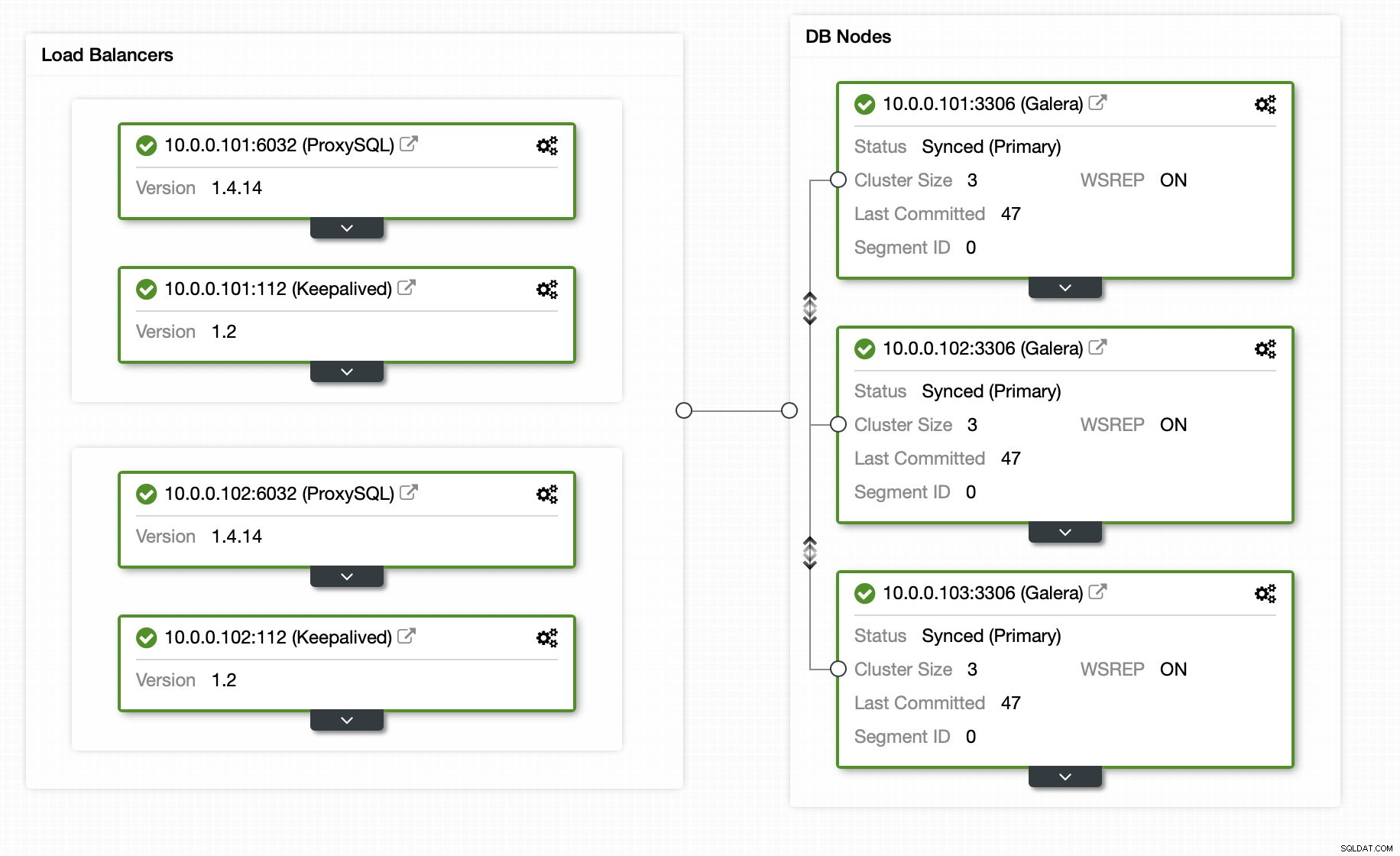
Tilføjelse af replikeringsslaven er kun et klik væk:
Replikering kræver naturligvis, at binære logfiler er aktiveret. Hvis du ikke har aktiveret binlogs på dine Galera-noder, kan du også gøre det fra ClusterControl. Husk, at aktivering af binære logfiler kræver en genstart af noden for at anvende konfigurationsændringerne.
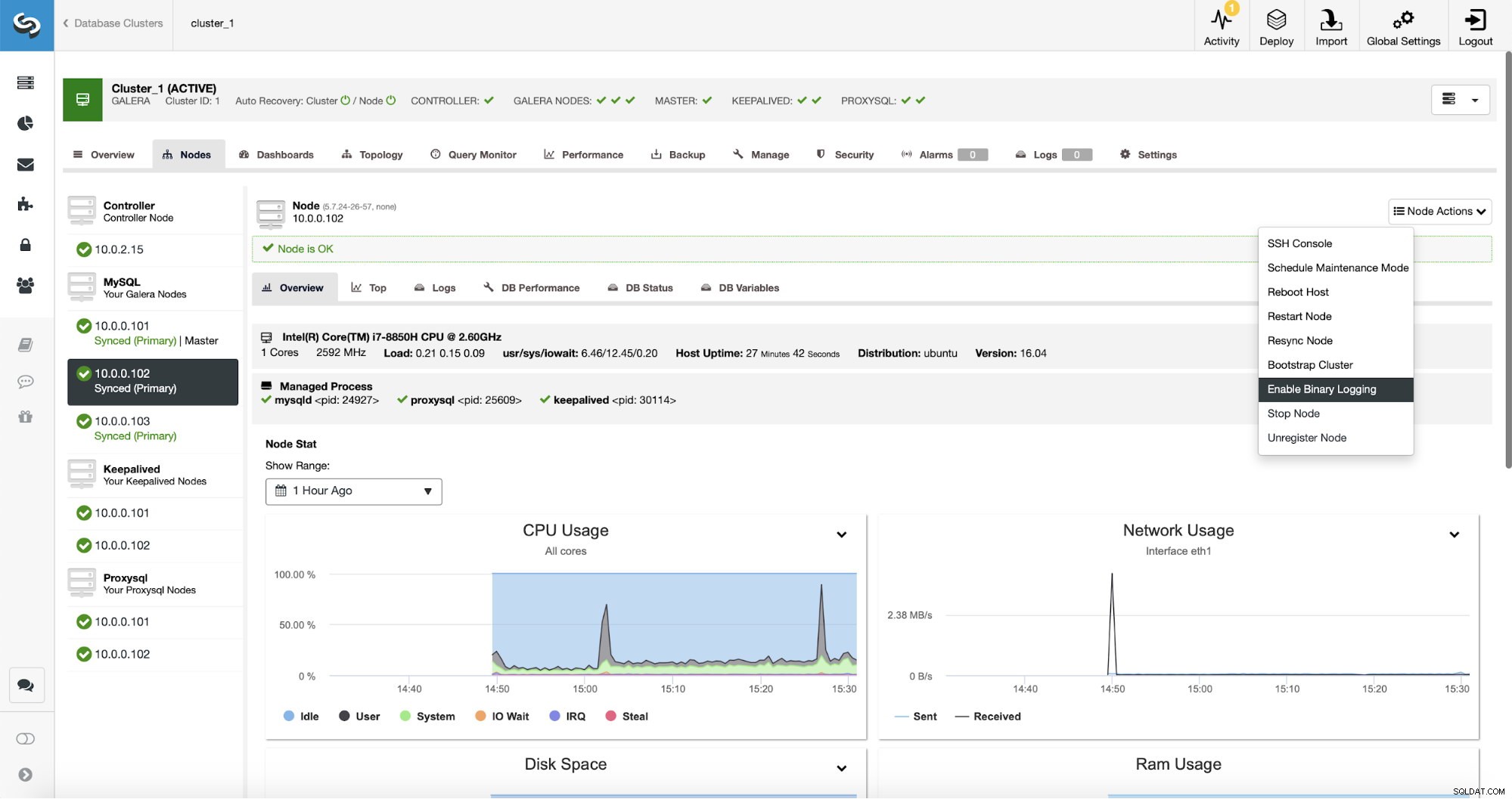
Selvom én node i klyngen har binære logfiler aktiveret (markeret som "Master" på skærmbilledet ovenfor), er det stadig godt at aktivere binær log på mindst én node mere. ClusterControl kan automatisk failover replikeringsslaven, efter at den har registreret, at master Galera-knuden styrtede ned, men til det kræves en anden masterknude med binære logfiler aktiveret, ellers vil den ikke have noget at fejle over til.
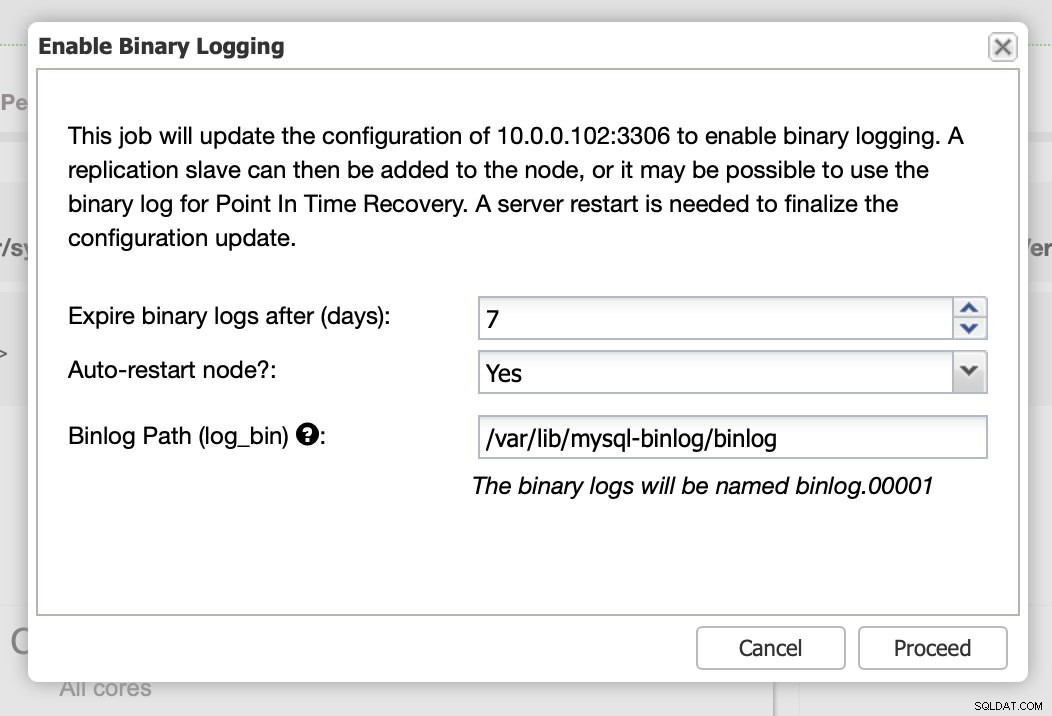
Som vi sagde, kræver aktivering af binære logfiler genstart. Du kan enten udføre det med det samme eller bare foretage konfigurationsændringerne og genstarte på et andet tidspunkt.
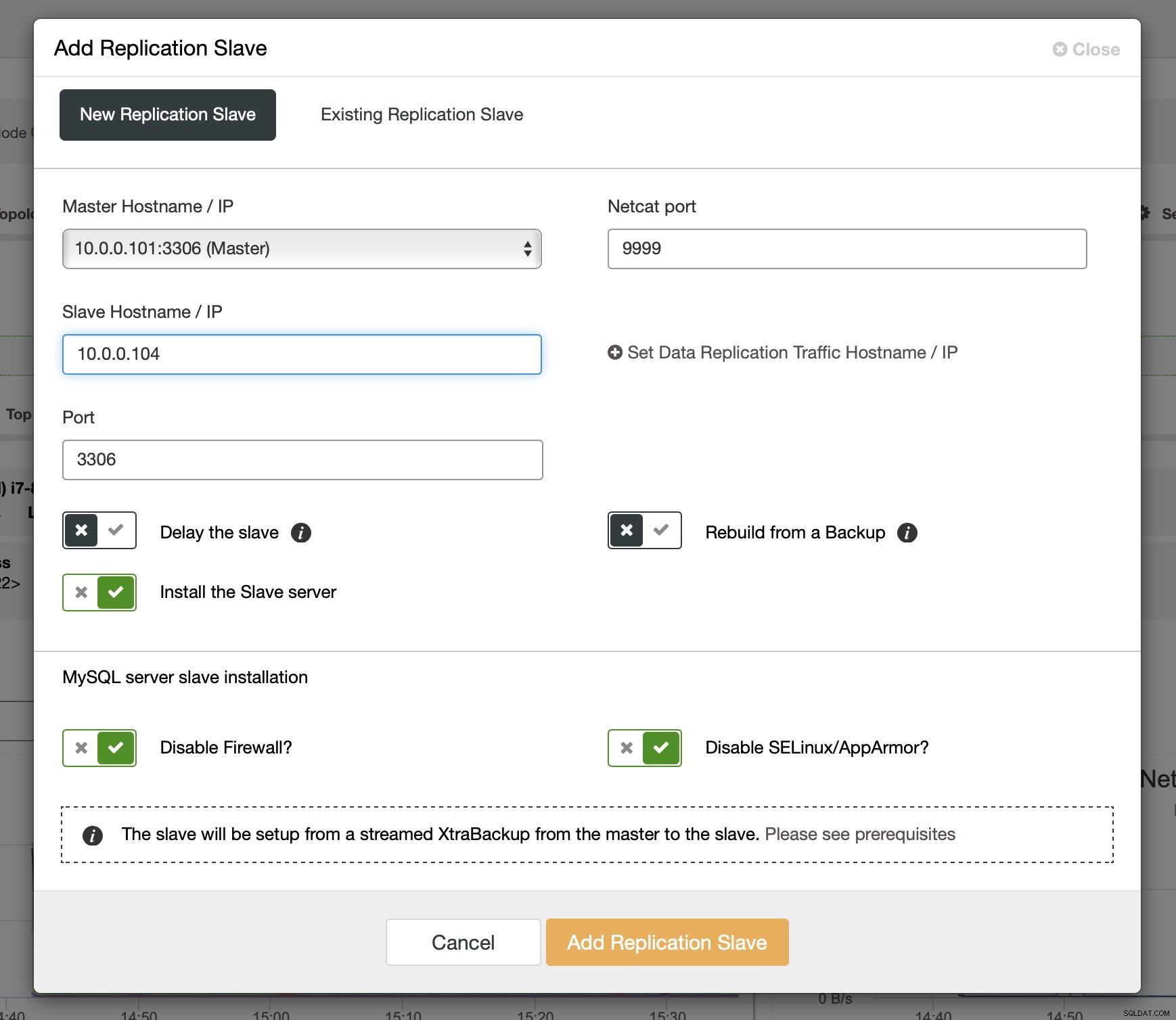
Efter at binlogs er blevet aktiveret på nogle af Galera-knuderne, kan du fortsætte med at tilføje replikeringsslaven. I dialogen skal du vælge master-værten, videregive værtsnavnet eller IP-adressen på slaven. Hvis du har nylige sikkerhedskopier ved hånden (hvilket du bør gøre), kan du bruge en til at klargøre slaven. Ellers vil ClusterControl klargøre det ved hjælp af xtrabackup - alle de seneste masterdata vil blive streamet til slaven, og derefter vil replikeringen blive konfigureret.
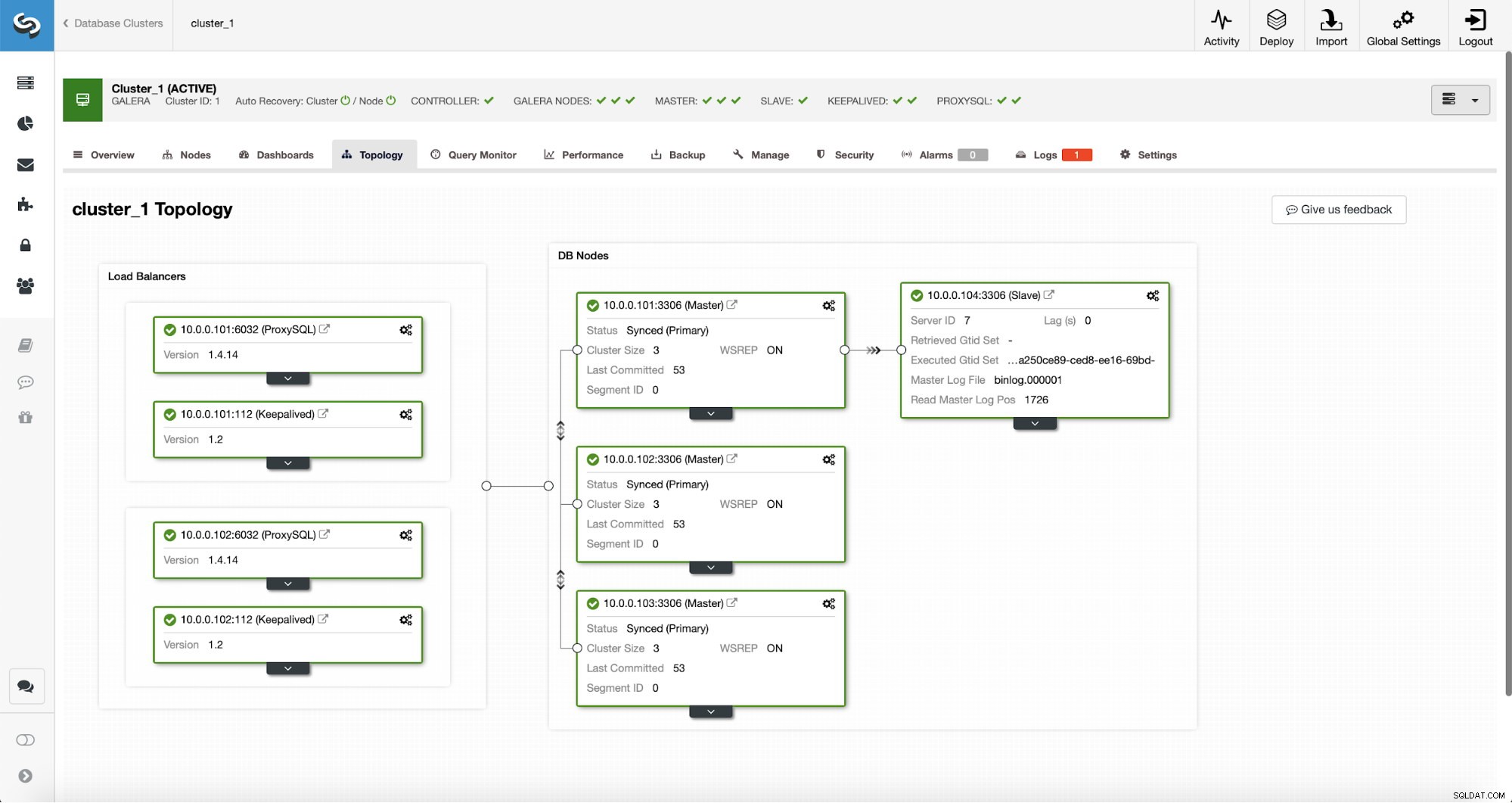
Efter jobbet er fuldført, er en replikeringsslave blevet tilføjet til klyngen. Som nævnt tidligere, hvis 10.0.0.101 dør, vil en anden vært i Galera-klyngen blive valgt som master, og ClusterControl vil automatisk slave 10.0.0.104 fra en anden node.
Da vi bruger ProxySQL, skal vi konfigurere det. Vi tilføjer en ny server til ProxySQL.
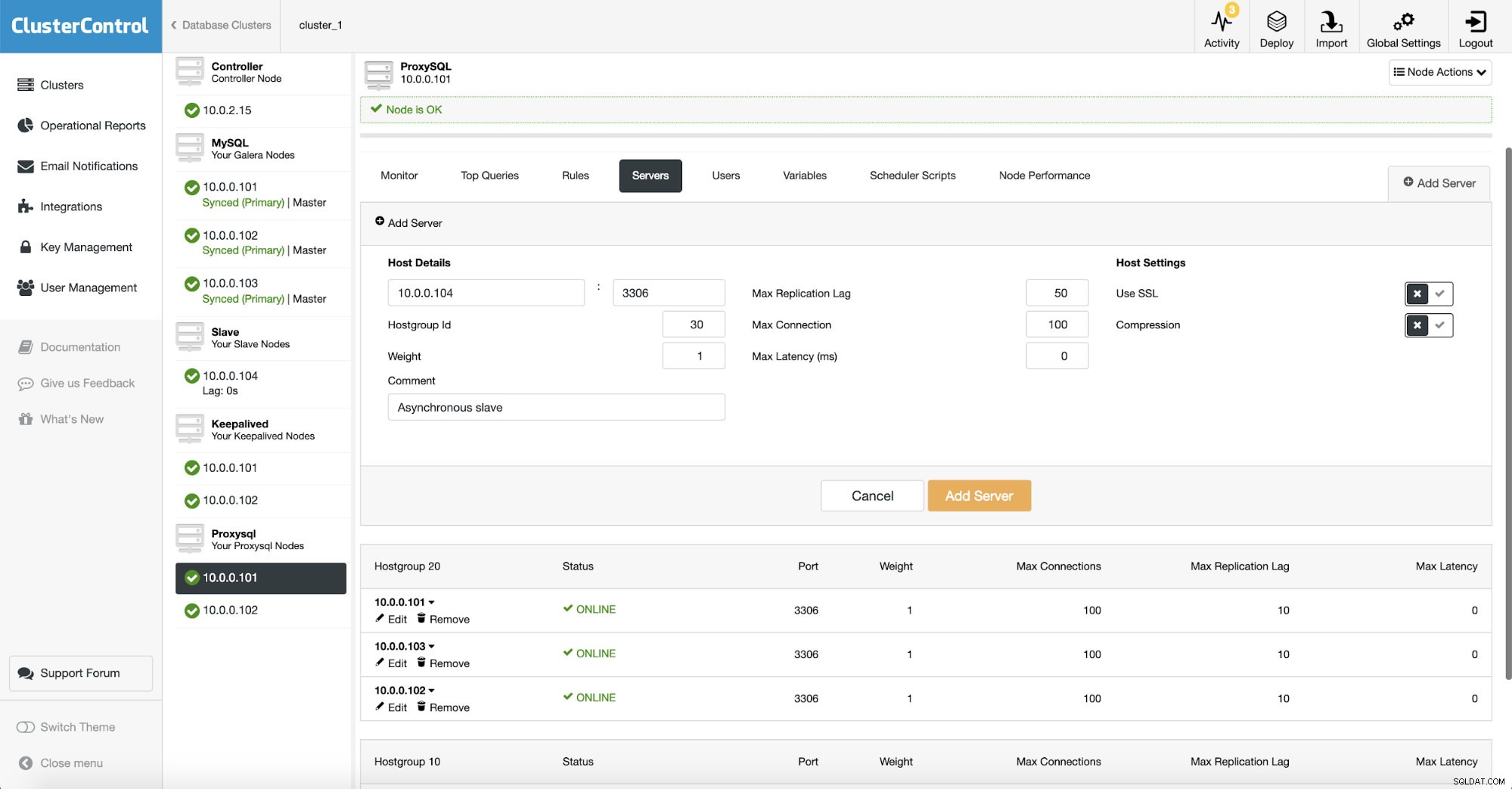
Vi oprettede en anden værtsgruppe (30), hvor vi satte vores asynkrone slave. Vi har også øget "Max Replication Lag" til 50 sekunder fra standard 10. Det er op til din virksomheds krav, hvor meget analytics-slaven kan halte, før det bliver et problem.
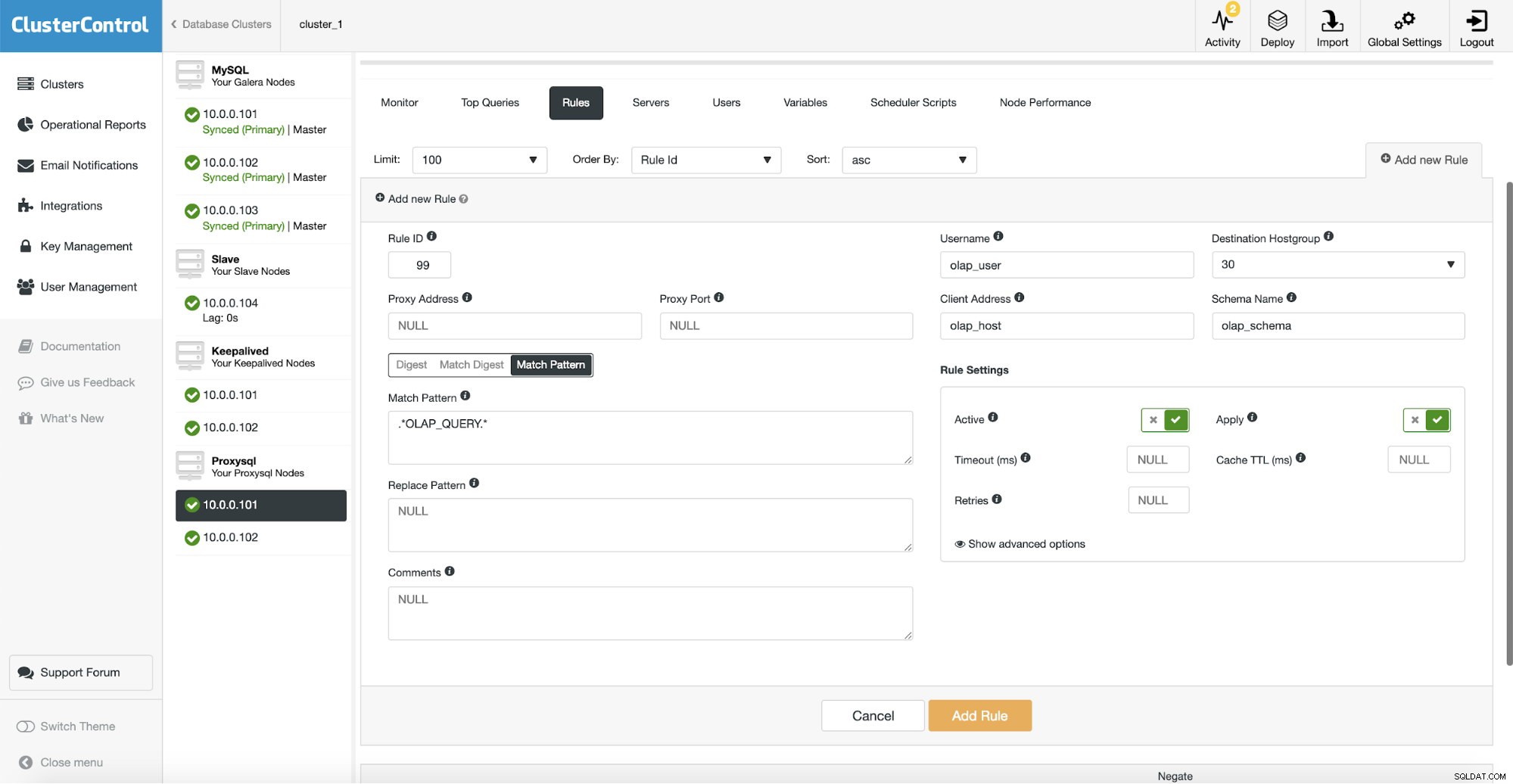
Derefter skal vi konfigurere en forespørgselsregel, der matcher vores OLAP-trafik og dirigerer den til OLAP-værtsgruppen (30). På skærmbilledet ovenfor udfyldte vi flere felter - dette er ikke obligatorisk. Typisk skal du bruge en, højst to af dem. Ovenstående skærmbillede tjener som et eksempel, så vi nemt kan se, at du kan matche forespørgsler ved hjælp af skema (hvis du har et separat skema med analytiske data), værtsnavn/IP (hvis OLAP-forespørgsler udføres fra en bestemt vært), bruger (hvis applikationen bruger bestemt bruger til analytiske forespørgsler. Du kan også matche forespørgsler direkte ved enten at sende en fuld forespørgsel eller ved at markere dem med SQL-kommentarer og lade ProxySQL dirigere alle forespørgsler med en "OLAP_QUERY"-streng til vores analytiske værtsgruppe.
Som du kan se, var vi takket være ClusterControl i stand til at implementere en replikeringsslave til Galera Cluster med blot et par klik. Nogle vil måske hævde, at MySQL ikke er den bedst egnede database til analytisk arbejdsbyrde, og vi er tilbøjelige til at være enige. Du kan nemt udvide denne opsætning ved hjælp af ClickHouse og ved at opsætte en replikering fra asynkron slave til ClickHouse søjledatalager for meget bedre ydelse af analytiske forespørgsler. Vi beskrev denne opsætning i et af de tidligere blogindlæg.