Det er næsten to måneder siden, vi udgav SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM bruger Prometheus som den underliggende metode til at indsamle tidsseriedata fra eksportører, der kører på databaseforekomster og load balancere. Denne blog viser dig, hvordan du løser problemer, når Prometheus-eksportører ikke kører, eller hvis graferne ikke viser data eller viser "Ingen datapunkter".
Hvad er Prometheus?
Prometheus er et open source-overvågningssystem med en dimensionel datamodel, fleksibelt forespørgselssprog, effektiv tidsseriedatabase og moderne alarmeringstilgang. Det er en overvågningsplatform, der indsamler metrics fra overvågede mål ved at skrabe metrics HTTP-endepunkter på disse mål. Det giver dimensionelle data, kraftfulde forespørgsler, fantastisk visualisering, effektiv lagring, enkel betjening, præcis advarsel, mange klientbiblioteker og mange integrationer.
Prometheus i aktion til SCUMM Dashboards
Prometheus indsamler metriske data fra eksportører, hvor hver eksportør kører på en database eller load balancer-vært. Diagrammet nedenfor viser dig, hvordan disse eksportører er forbundet med serveren, der hoster Prometheus-processen. Det viser, at ClusterControl-noden har Prometheus kørende, hvor den også kører process_exporter og node_exporter.
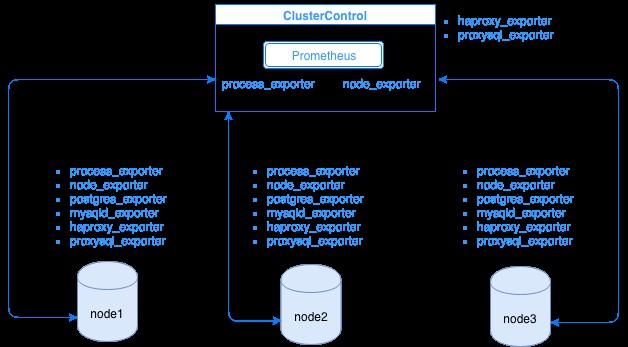
Diagrammet viser, at Prometheus kører på ClusterControl-værten og eksportørernes proces_exporter og node_exporter kører også for at indsamle metrics fra sin egen node. Du kan eventuelt også gøre din ClusterControl-vært til målet, hvor du kan konfigurere HAProxy eller ProxySQL.
For klyngen noder ovenfor (node1, node2 og node3), kan den have mysqld_exporter eller postgres_exporter kørende, som er de agenter, der skraber data internt i den node og sender dem til Prometheus-serveren og gemmer dem i sit eget datalager. Du kan finde dens fysiske data via /var/lib/prometheus/data inden for værten, hvor Prometheus er opsat.
Når du konfigurerer Prometheus, for eksempel i ClusterControl-værten, skal den have følgende porte åbnet. Se nedenfor:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusBaseret på outputtet har jeg også ProxySQL kørende på værtstestccnode, hvor ClusterControl er hostet.
Almindelige problemer med SCUMM Dashboards, der bruger Prometheus
Når Dashboards er aktiveret, vil ClusterControl installere og implementere binære filer og eksportører såsom node_exporter, process_exporter, mysqld_exporter, postgres_exporter og daemon. Disse er de fælles sæt af pakker til databasenoderne. Når disse er konfigureret og installeret, tændes og køres følgende dæmonkommandoer som vist nedenfor:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusFor en PostgreSQL-node,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterDet har de samme eksportører som for en MySQL-node, men adskiller sig kun på postgres_exporter, da dette er en PostgreSQL-databasenode.
Men når en node lider af en strømafbrydelse, et systemnedbrud eller en systemgenstart, stopper disse eksportører med at køre. Prometheus vil rapportere, at en eksportør er nede. ClusterControl prøver selve Prometheus og beder om eksportørstatusser. Så den reagerer på denne information og genstarter eksportøren, hvis den er nede.
Bemærk dog, at for eksportører, der ikke er blevet installeret via ClusterControl, vil de ikke blive genstartet efter et nedbrud. Årsagen er, at de ikke overvåges af systemd eller en dæmon, der fungerer som et sikkerhedsscript, der ville genstarte en proces ved nedbrud eller en unormal nedlukning. Derfor vil skærmbilledet nedenfor vise, hvordan det ser ud, når eksportørerne ikke kører. Se nedenfor:
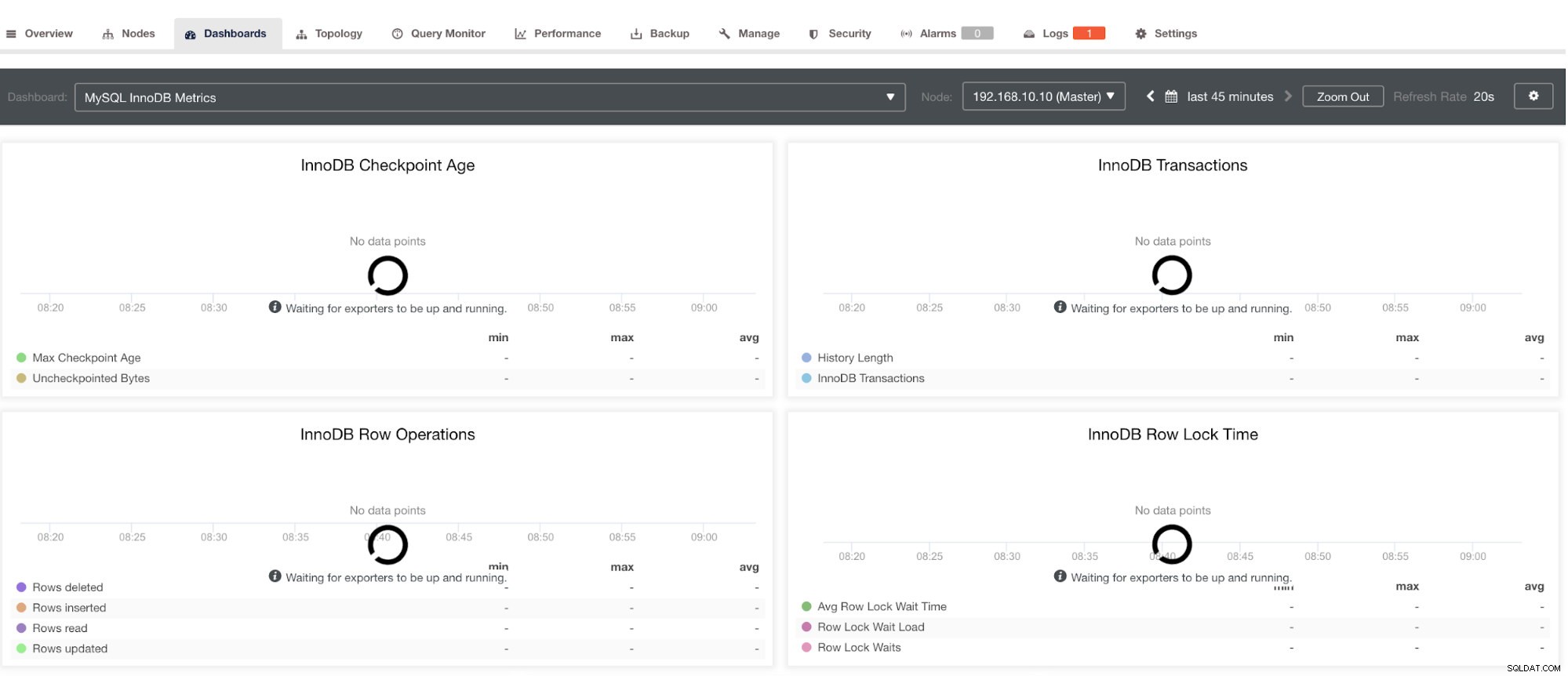
og i PostgreSQL Dashboard, vil have det samme indlæsningsikon med "Ingen datapunkter"-etiketten i grafen. Se nedenfor:
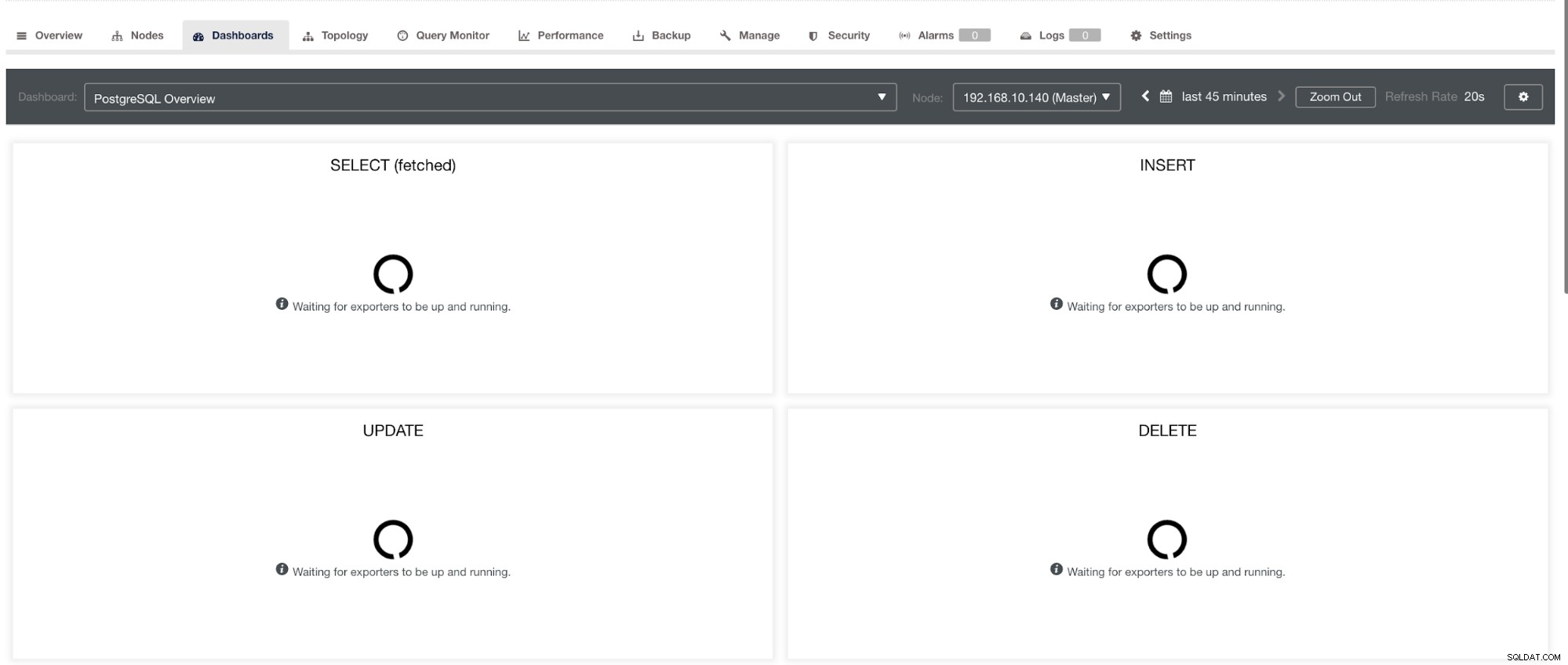
Derfor kan disse fejlfindes ved hjælp af forskellige teknikker, der følger i de følgende afsnit.
Fejlfinding af problemer med Prometheus
Prometheus-agenter, kendt som eksportørerne, bruger følgende porte:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter), og den helt egen promethe 909 ejes af en 09. behandle. Dette er portene til disse agenter, der bruges af ClusterControl.
For at starte fejlfinding af SCUMM Dashboard-problemerne, kan du starte med at kontrollere portene åbne fra databasenoden. Du kan følge listerne nedenfor:
-
Tjek om portene er åbne
f.eks.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporDer kan være en mulighed for, at portene ikke er åbne på grund af en firewall (såsom iptables eller firewalld), der blokerer den fra at åbne porten, eller selve procesdæmonen kører ikke.
-
Brug curl fra værtsmonitoren og kontroller, om porten er tilgængelig og åben.
f.eks.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Ideelt set fandt jeg praktisk talt denne tilgang mulig for mig, fordi jeg nemt kan grep og fejlfinde fra terminalen.
-
Hvorfor ikke bruge webbrugergrænsefladen?
-
Prometheus afslører port 9090, som bruges af ClusterControl i vores SCUMM Dashboards. Bortset fra dette kan de porte, som eksportørerne udsætter, også bruges til at fejlfinde og bestemme de tilgængelige metriske navne ved hjælp af PromQL. På serveren, hvor Prometheus kører, kan du besøge https://
:9090/targets . Skærmbilledet nedenfor viser det i aktion: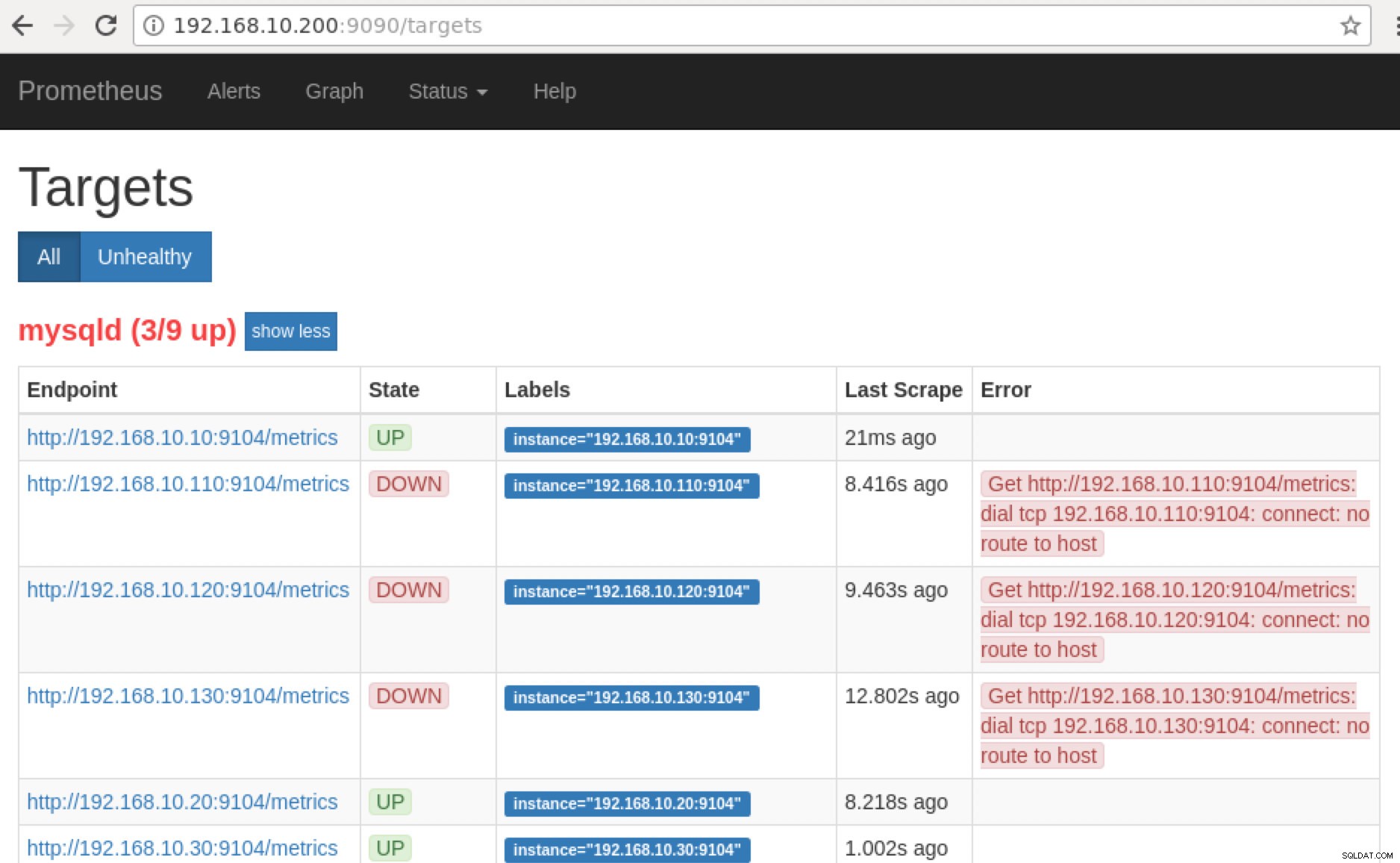
og ved at klikke på "Endpoints", kan du verificere metrics såvel som på skærmbilledet nedenfor:
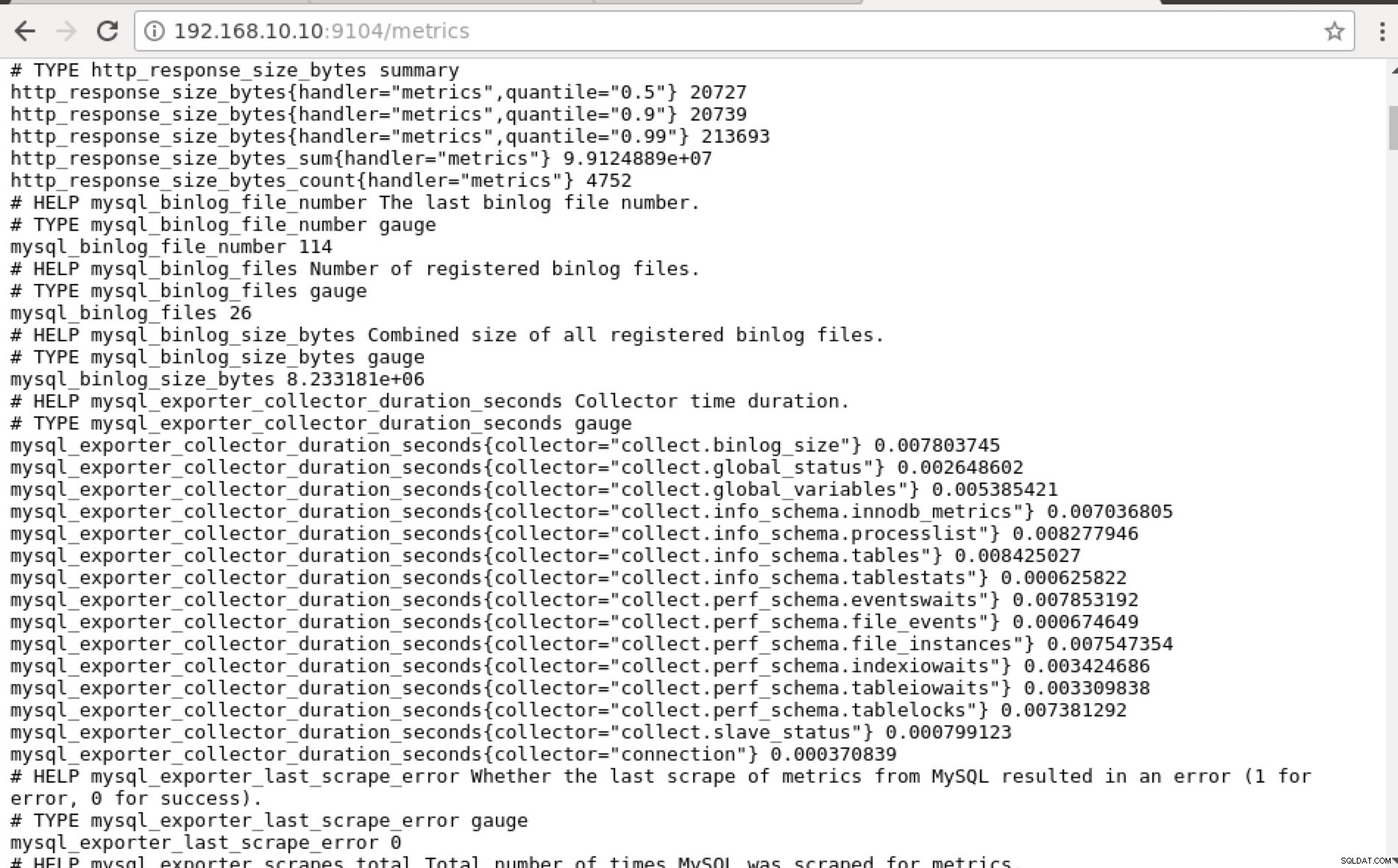
I stedet for at bruge IP-adressen kan du også tjekke dette lokalt via localhost på den specifikke node, såsom at besøge https://localhost:9104/metrics enten i en web-UI-grænseflade eller ved at bruge cURL.
Hvis vi nu går tilbage til "Mål ” side, kan du se listen over noder, hvor der kan være et problem med porten. Årsagerne, der kan forårsage dette, er anført nedenfor:
- Serveren er nede
- Netværket er ikke tilgængeligt, eller porte åbnes ikke på grund af en firewall, der kører
- Dæmonen kører ikke hvor
_exporter kører ikke. For eksempel kører mysqld_exporter ikke.
-
Når disse eksportører kører, kan du starte op og køre processen ved hjælp af daemon kommando. Du kan henvise til de tilgængelige kørende processer, som jeg havde brugt i eksemplet ovenfor eller nævnt i det forrige afsnit af denne blog.
Hvad med de "ingen datapunkter"-grafer i mit betjeningspanel?
SCUMM Dashboards kommer med et generelt brugsscenarie, som ofte bruges af MySQL. Der er dog nogle variabler, når en sådan metrik ikke er tilgængelig i en bestemt MySQL-version eller en MySQL-leverandør, såsom MariaDB eller Percona Server.
Lad mig vise et eksempel nedenfor:
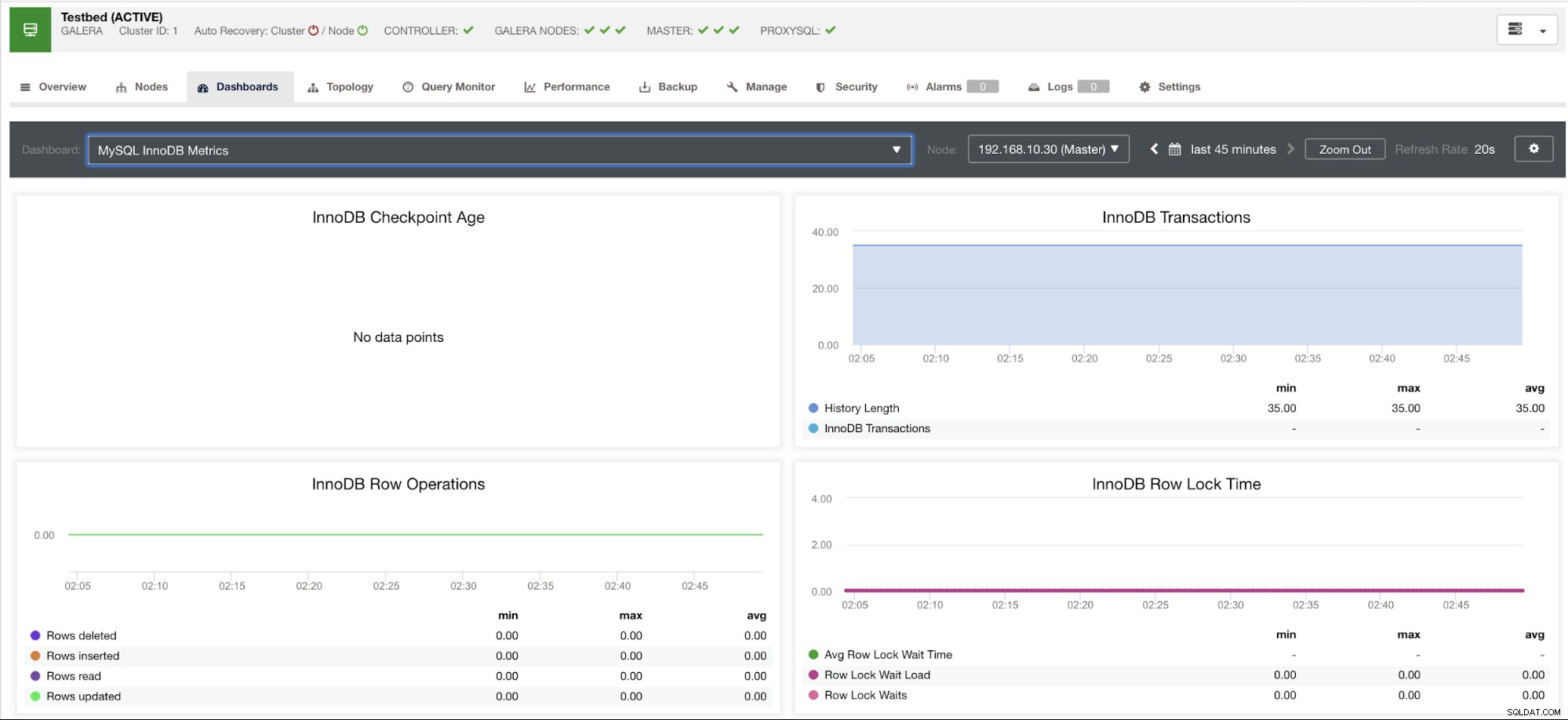
Denne graf blev taget på en databaseserver, der kører på en version 10.3.9-MariaDB-log MariaDB Server med wsrep_patch_version af wsrep_25.23-instansen. Nu er spørgsmålet, hvorfor indlæses der ingen datapunkter? Nå, da jeg spurgte noden om en checkpoint-aldersstatus, afslører den, at den er tom eller ingen variabel fundet. Se nedenfor:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Jeg aner ikke, hvorfor MariaDB ikke har denne variabel (fortæl os det i kommentarfeltet på denne blog, hvis du har svaret). Dette er i modsætning til en Percona XtraDB Cluster Server, hvor variablen Innodb_checkpoint_max_age eksisterer. Se nedenfor:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Hvad betyder dette dog er, at der kan være grafer, der ikke har datapunkter indsamlet, fordi der ikke er nogen data, der indsamles på den bestemte metrik, da en Prometheus-forespørgsel blev udført.
En graf, der ikke har datapunkter, betyder dog ikke, at din nuværende version af MySQL eller dens variant ikke understøtter den. For eksempel er der visse grafer, der kræver visse variabler, der skal konfigureres korrekt eller aktiveres.
Det følgende afsnit vil vise, hvad disse grafer er.
Index Condition Pushdown (ICP) graf

Denne graf er blevet nævnt i min tidligere blog. Den er afhængig af en MySQL global variabel ved navn innodb_monitor_enable. Denne variabel er dynamisk, så du kan indstille denne uden en hård genstart af din MySQL-database. Det kræver også innodb_monitor_enable =modul_icp, eller du kan indstille denne globale variabel til innodb_monitor_enable =all. For at undgå sådanne tilfælde og forvirring om, hvorfor en sådan graf ikke viser nogen datapunkter, skal du typisk bruge alt, men med forsigtighed. Der kan være visse overhead, når denne variabel er slået til og indstillet til alle.
MySQL Performance Schema Graphs
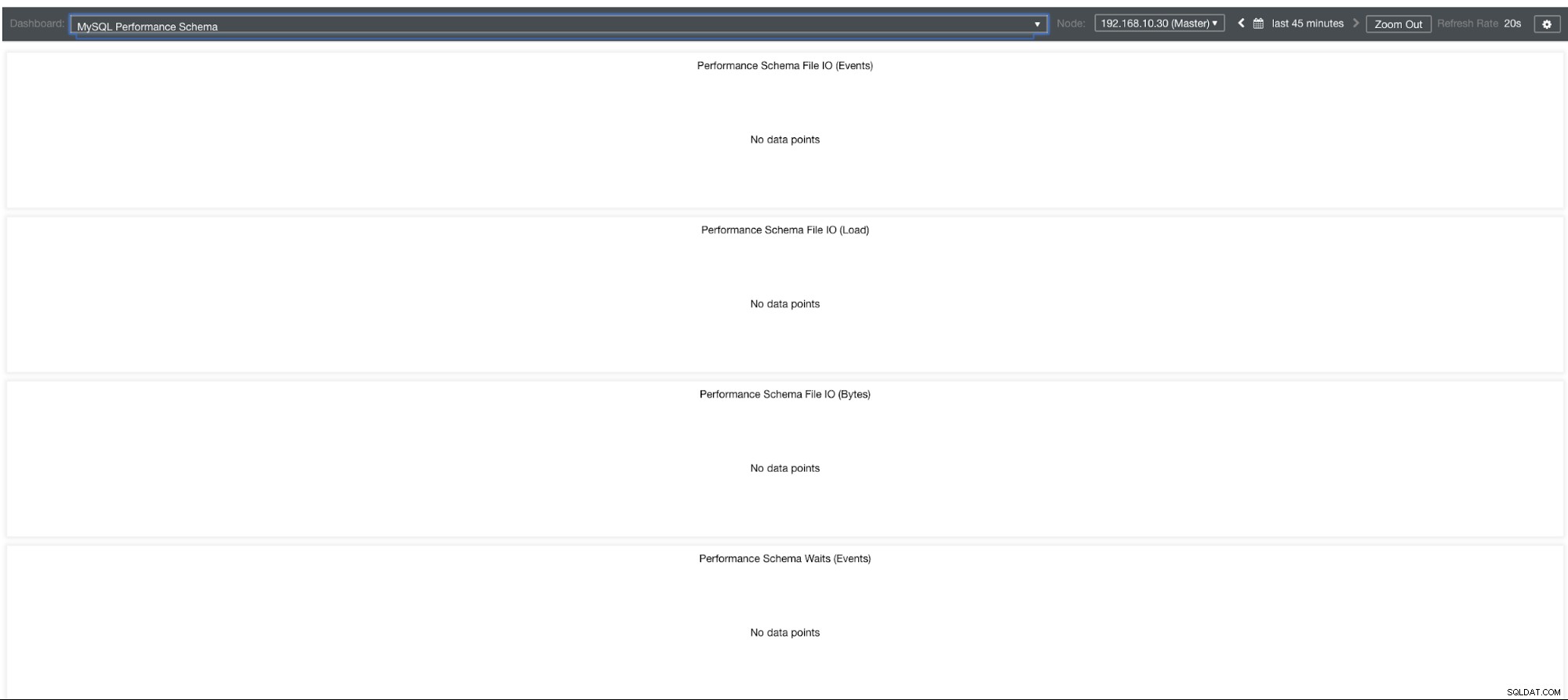
Så hvorfor viser disse grafer "Ingen datapunkter"? Når du opretter en klynge ved hjælp af ClusterControl ved hjælp af vores skabeloner, vil den som standard definere performance_schema-variabler. For eksempel er disse variabler nedenfor indstillet:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Men hvis performance_schema =FRA, så er det grunden til, at de relaterede grafer viser "Ingen datapunkter".
Men jeg har performance_schema aktiveret, hvorfor er andre grafer stadig et problem?
Nå, der er stadig grafer, der kræver, at flere variabler skal indstilles. Dette er allerede blevet dækket i vores tidligere blog. Derfor skal du indstille innodb_monitor_enable =all og userstat=1. Resultatet ville se sådan ud:
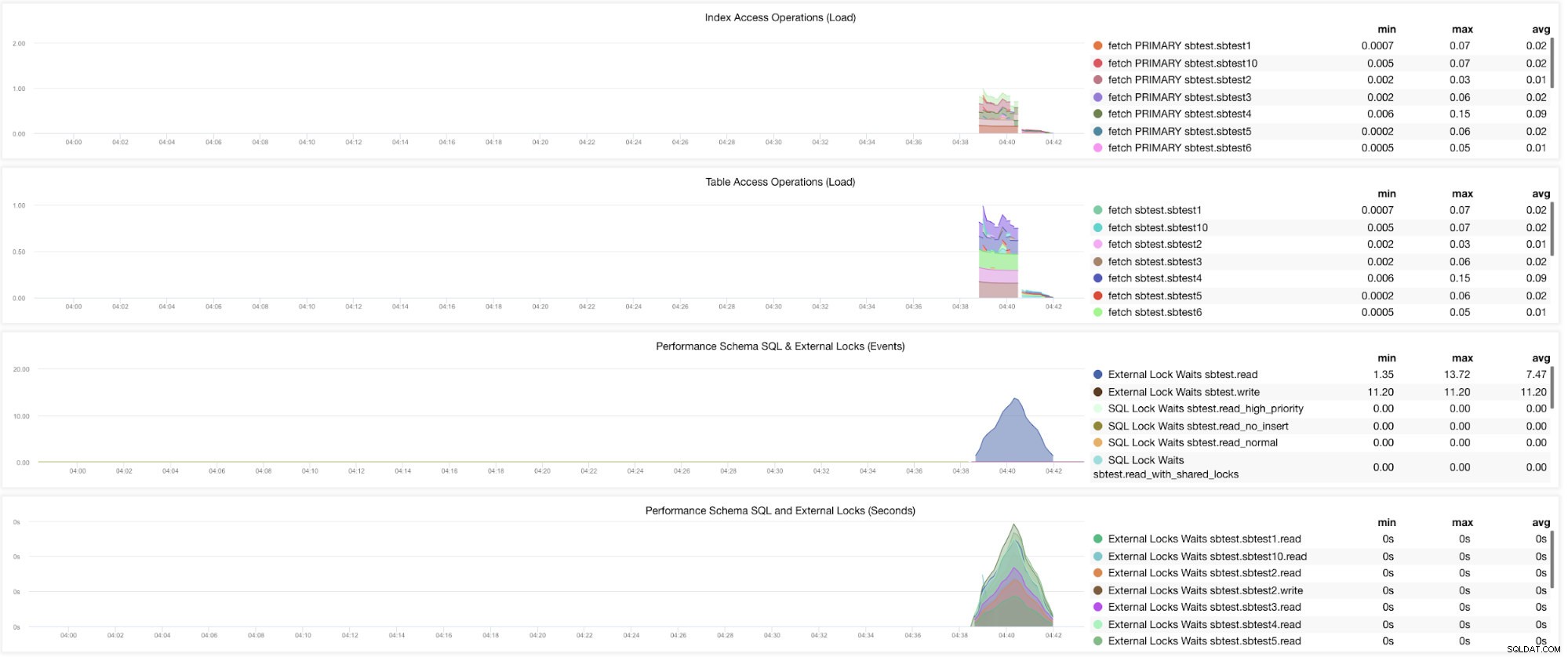
Jeg bemærker dog, at i versionen af MariaDB 10.3 (især 10.3.11) vil indstilling af performance_schema=ON udfylde de nødvendige metrics til MySQL Performance Schema Dashboard. Dette er en stor fordel, fordi det ikke behøver at indstille innodb_monitor_enable=ON, hvilket ville tilføje ekstra overhead på databaseserveren.
Avanceret fejlfinding
Er der nogen forudgående fejlfinding, jeg kan anbefale? Ja der er! Du har dog i det mindste brug for nogle JavaScript-færdigheder. Da SCUMM Dashboards, der bruger Prometheus, er afhængige af highcharts, kan den måde, de metrics, der bruges til PromQL-anmodninger, bestemmes gennem app.js script, som er vist nedenfor:
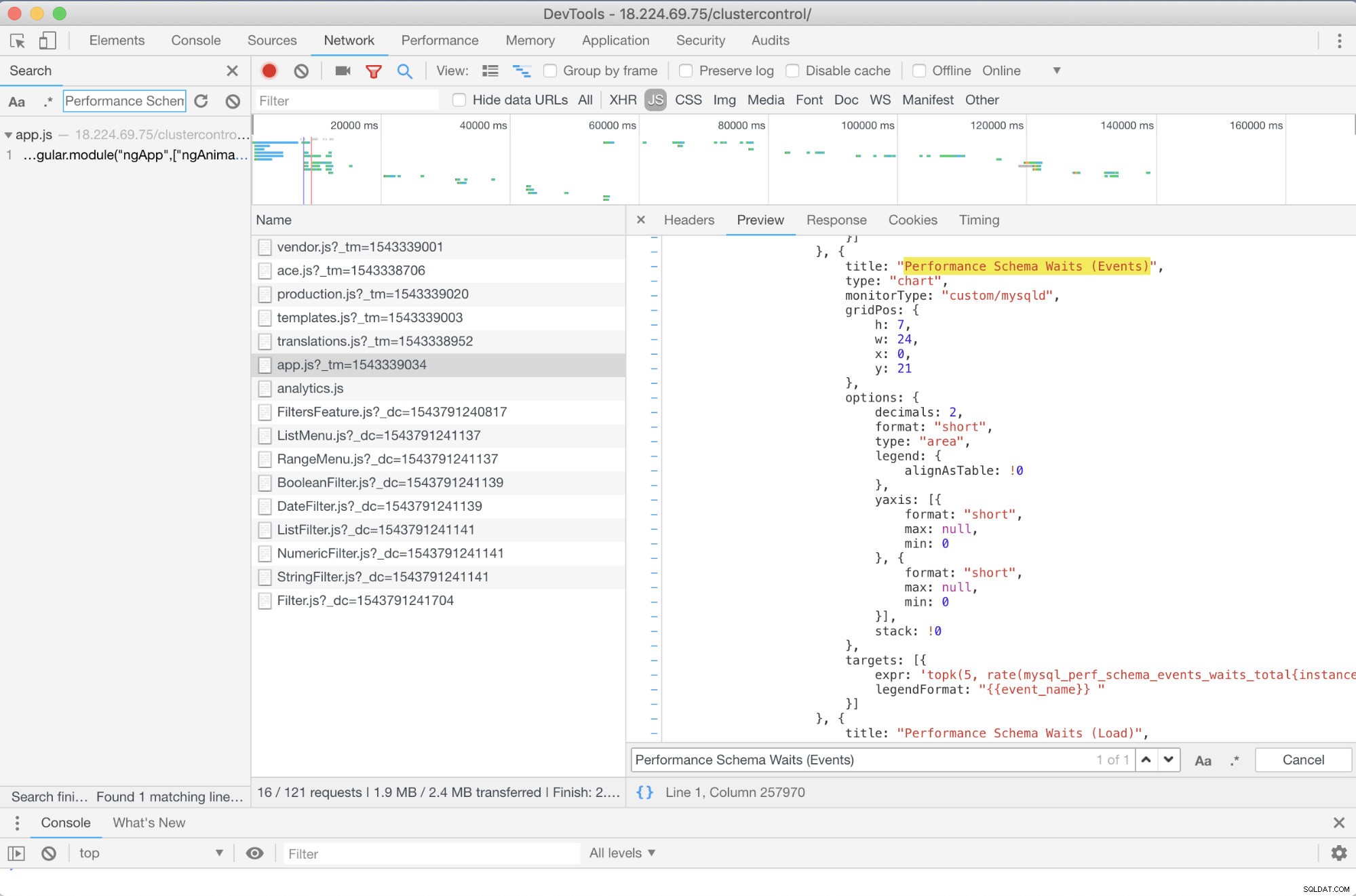
Så i dette tilfælde bruger jeg Google Chromes DevTools og forsøgte at lede efter Performance Schema Waits (Events) . Hvordan kan dette hjælpe? Nå, hvis du ser på målene, vil du se:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Nu kan du bruge de anmodede målinger, som er mysql_perf_schema_events_waits_total. Det kan du for eksempel tjekke ved at gå igennem https://
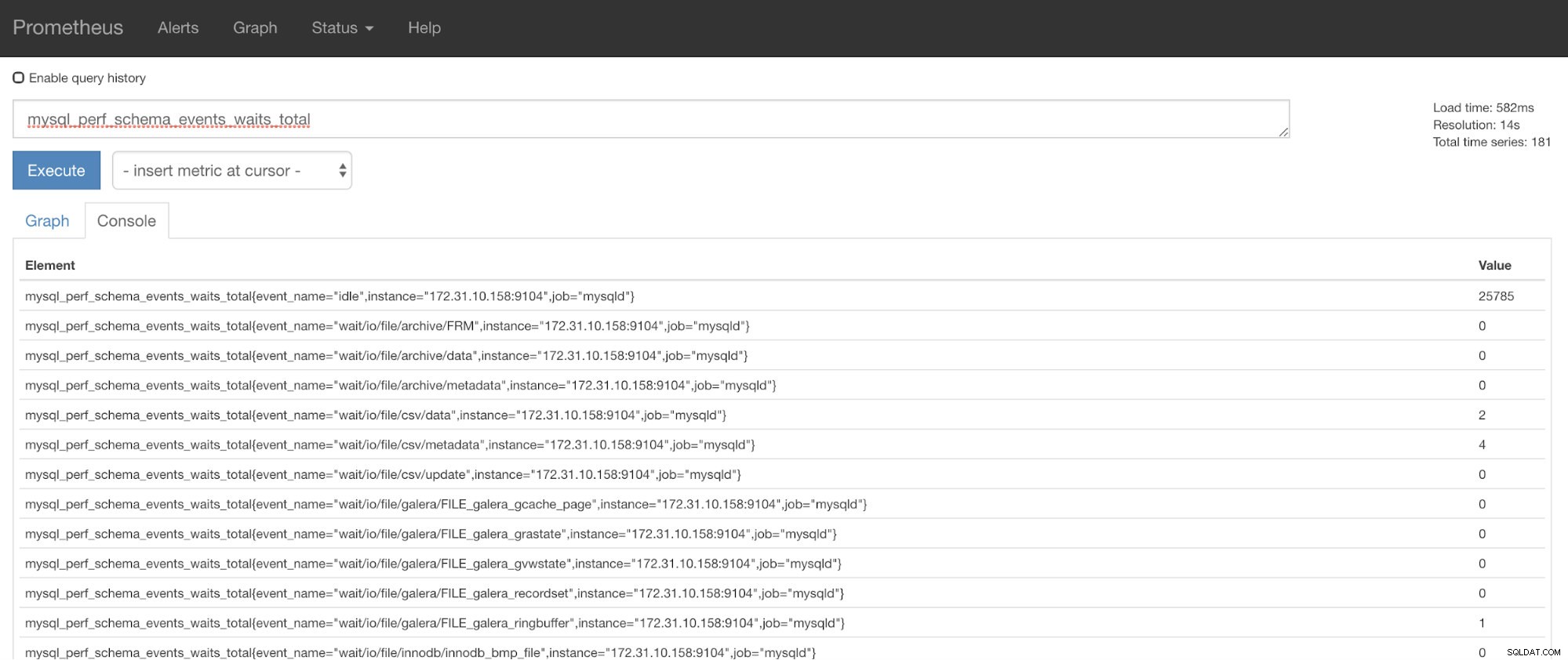
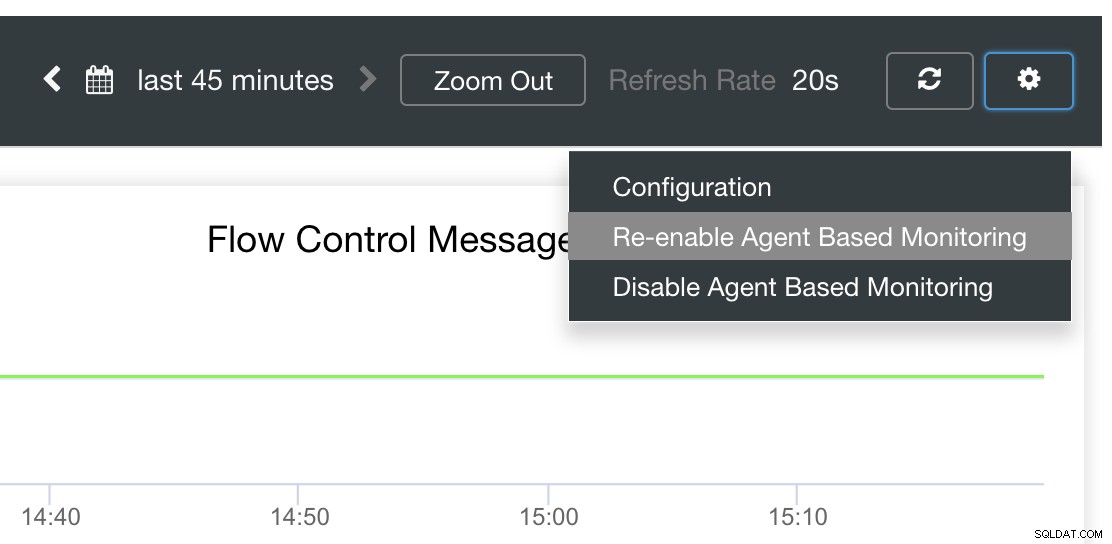
ClusterControl Auto-Recovery til undsætning!
Til sidst er hovedspørgsmålet, er der en nem måde at genstarte mislykkede eksportører på? Ja! Vi nævnte tidligere, at ClusterControl overvåger status for eksporten og genstarter dem, hvis det kræves. Hvis du bemærker, at SCUMM Dashboards ikke indlæser grafer normalt, skal du sikre dig, at du har aktiveret automatisk gendannelse. Se billedet nedenfor:

Når dette er aktiveret, vil dette sikre, at
Det er også muligt at geninstallere eller omkonfigurere eksportørerne.
Konklusion
I denne blog så vi, hvordan ClusterControl bruger Prometheus til at tilbyde SCUMM Dashboards. Det giver et kraftfuldt sæt funktioner, fra overvågningsdata i høj opløsning og fyldige grafer. Du har lært, at med PromQL kan du bestemme og fejlfinde vores SCUMM Dashboards, som giver dig mulighed for at aggregere tidsseriedata i realtid. Du kan også generere grafer eller se gennem konsollen for alle de metrics, der er blevet indsamlet.
Du har også lært, hvordan du fejlretter vores SCUMM Dashboards, især når der ikke indsamles datapunkter.
Hvis du har spørgsmål, bedes du tilføje dine kommentarer eller fortælle os det via vores fællesskabsfora.