Du har måske hørt om udtrykket "failover" i forbindelse med MySQL-replikering. Måske undrede du dig over, hvad det er, når du starter dit eventyr med databaser. Måske ved du, hvad det er, men du er ikke sikker på potentielle problemer relateret til det, og hvordan de kan løses?
I dette blogindlæg vil vi forsøge at give dig en introduktion til failover-håndtering i MySQL &MariaDB.
Vi vil diskutere, hvad failover er, hvorfor det er uundgåeligt, hvad forskellen er mellem failover og switchover. Vi vil diskutere failover-processen i den mest generiske form. Vi vil også komme lidt ind på forskellige problemstillinger, som du skal forholde dig til i forhold til failover-processen.
Hvad betyder "failover"?
MySQL-replikering er et kollektiv af noder, hver af dem kan tjene en rolle ad gangen. Det kan blive en mester eller en replika. Der er kun én masterknude på et givet tidspunkt. Denne node modtager skrivetrafik, og den replikerer skrivninger til dens replikaer.
Som du kan forestille dig, er masterknuden ret vigtig, da den er et enkelt indgangspunkt for data i replikeringsklyngen. Hvad ville der ske, hvis det mislykkedes og var blevet utilgængeligt?
Dette er en ganske alvorlig tilstand for en replikationsklynge. Den kan ikke acceptere nogen skrivninger på et givet tidspunkt. Som du måske forventer, bliver en af replikaerne nødt til at overtage mesterens opgaver og begynde at acceptere skriverier. Resten af replikationstopologien skal muligvis også ændres - resterende replikaer bør ændre deres master fra den gamle, mislykkede node til den nyligt valgte. Denne proces med at "promovere" en replika til at blive en mester, efter at den gamle mester har fejlet, kaldes "failover".
På den anden side sker "switchover", når brugeren udløser promovering af replikaen. En ny master forfremmes fra en replika, som brugeren peger på, og den gamle master bliver typisk en replika til den nye master.
Den vigtigste forskel mellem "failover" og "switchover" er den gamle mesters tilstand. Når en failover udføres, er den gamle master på en eller anden måde ikke tilgængelig. Det kan være gået ned, det kan have lidt en netværkspartitionering. Det kan ikke bruges på et givet tidspunkt, og dets tilstand er typisk ukendt.
På den anden side, når en omstilling udføres, lever den gamle mester i bedste velgående. Dette har alvorlige konsekvenser. Hvis en master ikke kan nås, kan det betyde, at nogle af dataene endnu ikke er blevet sendt til slaverne (medmindre der blev brugt semi-synkron replikering). Nogle af dataene kan være blevet beskadiget eller sendt delvist.
Der er mekanismer på plads for at undgå at udbrede sådanne korruptioner på slaver, men pointen er, at nogle af dataene kan gå tabt under processen. På den anden side, mens du udfører en omstilling, er den gamle master tilgængelig, og datakonsistensen bibeholdes.
Failover-proces
Lad os bruge lidt tid på at diskutere, hvordan failover-processen præcist ser ud.
Master Crash er registreret
For det første skal en master gå ned, før failoveren udføres. Når den ikke er tilgængelig, udløses en failover. Indtil videre virker det simpelt, men sandheden er, at vi allerede er på glat underlag.
Først og fremmest, hvordan testes master sundhed? Er det testet fra ét sted, eller distribueres tests? Forsøger failover-styringssoftwaren bare at oprette forbindelse til masteren, eller implementerer den mere avancerede verifikationer, før masterfejl erklæres?
Lad os forestille os følgende topologi:
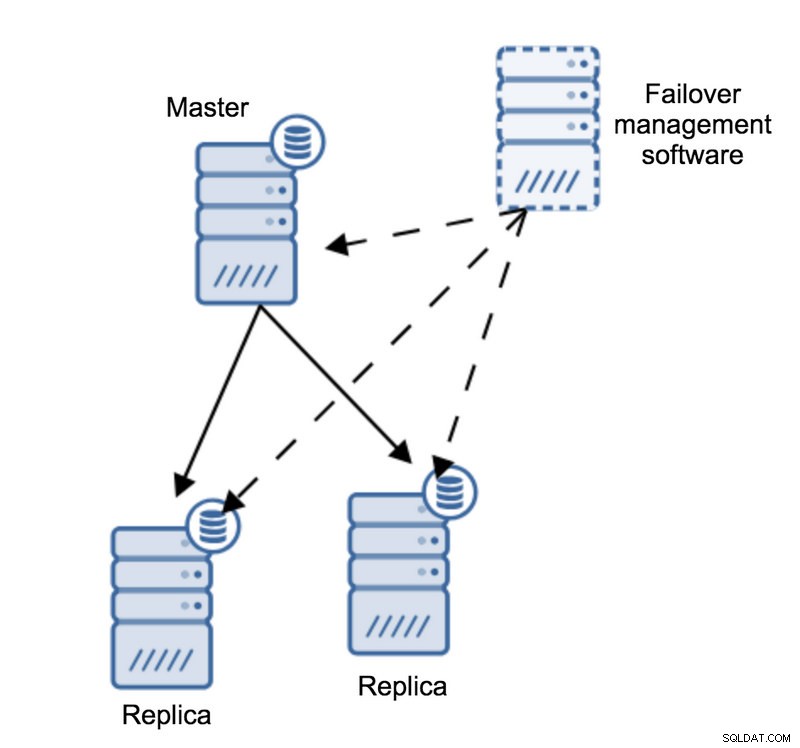
Vi har en mester og to replikaer. Vi har også en failover-styringssoftware placeret på en ekstern vært. Hvad ville der ske, hvis en netværksforbindelse mellem værten med failover-software og masteren mislykkedes?
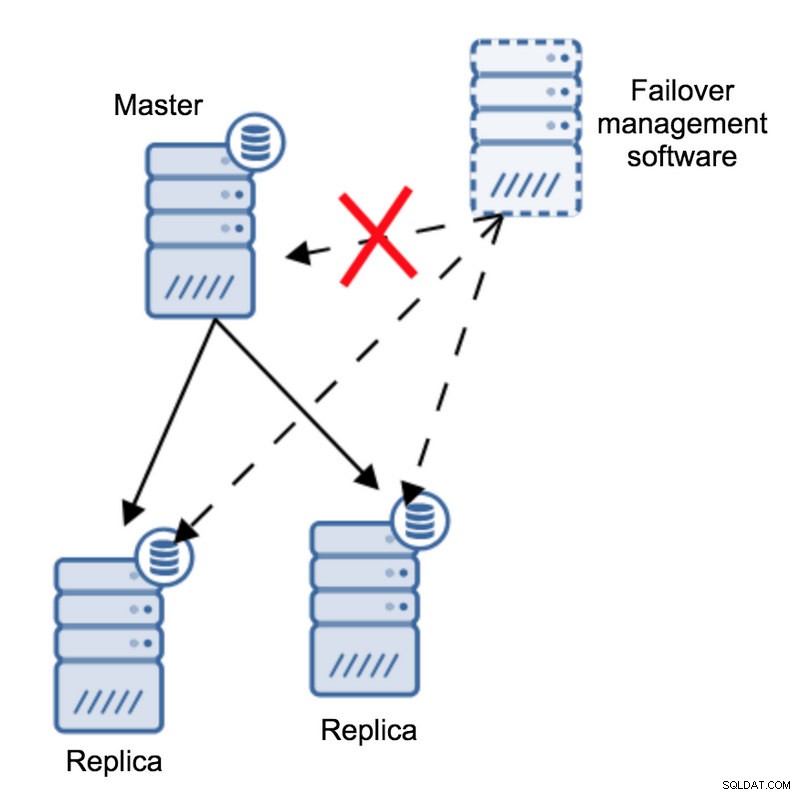
Ifølge failover-styringssoftwaren er masteren gået ned - der er ingen forbindelse til den. Alligevel fungerer selve replikationen fint. Det, der skulle ske her, er, at failover-styringssoftwaren ville forsøge at oprette forbindelse til replikaer og se, hvad deres synspunkt er.
Klager de over en ødelagt replikation, eller replikerer de med glæde?
Tingene kan blive endnu mere komplekse. Hvad hvis vi ville tilføje en proxy (eller et sæt fuldmagter)? Det vil blive brugt til at dirigere trafik - skriver til master og læser til replikaer. Hvad hvis en proxy ikke kan få adgang til masteren? Hvad hvis ingen af proxyerne kan få adgang til masteren?
Det betyder, at applikationen ikke kan fungere under disse forhold. Skal failover (faktisk ville det være mere en overgang, da masteren teknisk set er i live) udløses?
Teknisk set er masteren i live, men den kan ikke bruges af applikationen. Her skal forretningslogikken ind, og der skal tages en beslutning.
Forhindrer den gamle mester i at løbe
Uanset hvordan og hvorfor, hvis der er en beslutning om at promovere en af replikaerne til at blive en ny mester, skal den gamle mester stoppes, og ideelt set burde den ikke kunne starte igen.
Hvordan dette kan opnås afhænger af detaljerne i det særlige miljø; derfor er denne del af failover-processen almindeligvis forstærket af eksterne scripts integreret i failover-processen gennem forskellige hooks.
Disse scripts kan designes til at bruge værktøjer, der er tilgængelige i det bestemte miljø, til at stoppe den gamle master. Det kan være et CLI- eller API-kald, der stopper en VM; det kan være shell-kode, der kører kommandoer gennem en slags "lys ud-styring"-enhed; det kan være et script, der sender SNMP-fælder til Power Distribution Unit, som deaktiverer de strømudtag, den gamle master bruger (uden elektrisk strøm kan vi være sikre på, at den ikke starter igen).
Hvis en failover-styringssoftware er en del af et mere komplekst produkt, som også håndterer gendannelse af noder (som det er tilfældet for ClusterControl), kan den gamle master blive markeret som udelukket fra gendannelsesrutinerne.
Du undrer dig måske over, hvorfor det er så vigtigt at forhindre, at den gamle mester bliver tilgængelig igen?
Hovedproblemet er, at i replikeringsopsætninger kan kun én node bruges til at skrive. Det sikrer du typisk ved at aktivere en read_only (og super_read_only, hvis relevant) variabel på alle replikaer og kun holde den deaktiveret på masteren.
Når en ny master først er blevet forfremmet, vil den være skrivebeskyttet deaktiveret. Problemet er, at hvis den gamle master ikke er tilgængelig, kan vi ikke skifte den tilbage til read_only=1. Hvis MySQL eller en vært gik ned, er dette ikke et stort problem, da god praksis er at have my.cnf konfigureret med denne indstilling, så når MySQL starter, starter den altid i skrivebeskyttet tilstand.
Problemet viser, når det ikke er et nedbrud, men et netværksproblem. Den gamle master kører stadig med read_only deaktiveret, den er bare ikke tilgængelig. Når netværk konvergerer, vil du ende med to skrivbare noder. Dette kan være et problem eller ikke. Nogle af proxyerne bruger read_only-indstillingen som en indikator for, om en node er en master eller en replika. To mastere, der dukker op på det givne tidspunkt, kan resultere i et stort problem, da data skrives til begge værter, men replikaer får kun halvdelen af skrivetrafikken (den del, der ramte den nye master).
Nogle gange handler det om hårdkodede indstillinger i nogle af scripts, som er konfigureret til kun at oprette forbindelse til en given vært. Normalt ville de fejle, og nogen ville bemærke, at masteren har ændret sig.
Når den gamle master er tilgængelig, vil de med glæde oprette forbindelse til den, og der vil opstå datauoverensstemmelser. Som du kan se, er det ret højt prioriteret at sikre, at den gamle master ikke starter.
Beslut dig for en masterkandidat
Den gamle mester er nede, og den vender ikke tilbage fra sin grav, nu er det tid til at beslutte, hvilken vært vi skal bruge som ny mester. Normalt er der mere end én kopi at vælge imellem, så en beslutning skal tages. Der er mange grunde til, at en replika kan vælges frem for en anden, derfor skal der udføres kontrol.
Hvidlister og sortlister
For det første kan et team, der administrerer databaser, have sine grunde til at vælge en replika frem for en anden, når de beslutter sig for en masterkandidat. Måske bruger den svagere hardware eller har et bestemt job tildelt den (denne replika kører backup, analytiske forespørgsler, udviklere har adgang til den og kører brugerdefinerede, håndlavede forespørgsler). Måske er det en testreplika, hvor en ny version gennemgår accepttest, før den fortsætter med opgraderingen. De fleste failover-styringssoftware understøtter hvide og sorte lister, som kan bruges til præcist at definere, hvilke replikaer der skal eller ikke kan bruges som masterkandidater.
Semi-synkron replikering
En replikeringsopsætning kan være en blanding af asynkrone og semi-synkrone replikaer. Der er en enorm forskel mellem dem - semi-synkron replika vil med garanti indeholde alle hændelser fra mesteren. En asynkron replika har muligvis ikke modtaget alle data, og hvis du ikke kommer over til den, kan det resultere i tab af data. Vi vil hellere se semi-synkrone replikaer blive promoveret.
Replikeringsforsinkelse
Selvom en semi-synkron replika vil indeholde alle hændelser, kan disse hændelser stadig kun findes i relælogfiler. Med tæt trafik kan alle replikaer, uanset om de er semi-synkroniserede eller asynkrone, halte.
Problemet med replikeringsforsinkelse er, at når du promoverer en replika, skal du nulstille replikeringsindstillingerne, så den ikke forsøger at oprette forbindelse til den gamle master. Dette vil også fjerne alle relælogfiler, selvom de endnu ikke er anvendt - hvilket fører til datatab.
Selvom du ikke vil nulstille replikeringsindstillingerne, kan du stadig ikke åbne en ny master til forbindelser, hvis den ikke har anvendt alle hændelser fra sin relælog. Ellers risikerer du, at de nye forespørgsler vil påvirke transaktioner fra relæloggen, hvilket udløser alle slags problemer (for eksempel kan en applikation fjerne nogle rækker, som tilgås af transaktioner fra relæloggen).
Tager man alt dette i betragtning, er den eneste sikre mulighed at vente på, at relæloggen bliver anvendt. Alligevel kan det tage et stykke tid, hvis replikaen haltede meget. Der skal træffes beslutninger om, hvilken replika der ville være en bedre master - asynkron, men med lille forsinkelse eller semi-synkron, men med forsinkelse, der ville kræve en betydelig mængde tid at anvende.
Fejlagtige transaktioner
Selvom replikaer ikke bør skrives til, kan det stadig ske, at nogen (eller noget) har skrevet til det.
Det kan have været kun en enkelt transaktionsmåde tidligere, men det kan stadig have en alvorlig effekt på evnen til at udføre en failover. Problemet er strengt relateret til Global Transaction ID (GTID), en funktion, som tildeler et særskilt ID til hver transaktion, der udføres på en given MySQL-node.
I dag er det et ret populært setup, da det giver store niveauer af fleksibilitet, og det giver mulighed for bedre ydeevne (med flertrådede replikaer).
Problemet er, at mens der genslaves til en ny master, kræver GTID-replikering, at alle hændelser fra denne master (som ikke er blevet udført på replika) replikeres til replikaen.
Lad os overveje følgende scenarie:på et tidspunkt i fortiden skete der en skrivning på en replika. Det er lang tid siden, og denne begivenhed er blevet fjernet fra replikaens binære logfiler. På et tidspunkt har en mester fejlet, og replikaen blev udpeget som en ny mester. Alle resterende replikaer vil blive slave af den nye mester. De vil spørge om transaktioner udført på den nye master. Det vil svare med en liste over GTID'er, som kom fra den gamle master og det enkelte GTID relateret til den gamle skrivning. GTID'er fra den gamle master er ikke et problem, da alle resterende replikaer indeholder i det mindste størstedelen af dem (hvis ikke alle), og alle manglende hændelser bør være nye nok til at være tilgængelige i den nye masters binære logfiler.
I værste fald vil nogle manglende hændelser blive læst fra de binære logfiler og overført til replikaer. Problemet er med den gamle skrivning - det skete kun på en ny master, mens det stadig var en replika, så det eksisterer ikke på resterende værter. Det er en gammel begivenhed, derfor er der ingen måde at hente den fra binære logfiler. Som et resultat vil ingen af replikaerne være i stand til at slave af den nye master. Den eneste løsning her er at foretage en manuel handling og injicere en tom begivenhed med det problematiske GTID på alle replikaer. Det betyder også, at replikaerne muligvis ikke er synkroniserede med den nye master, afhængigt af hvad der skete.
Som du kan se, er det ret vigtigt at spore fejlagtige transaktioner og afgøre, om det er sikkert at promovere en given replika til at blive en ny mester. Hvis det indeholder fejlagtige transaktioner, er det muligvis ikke den bedste løsning.
Failover-håndtering for applikationen
Det er afgørende at huske på, at hovedafbryderen, tvunget eller ej, har en effekt på hele topologien. Skrivninger skal omdirigeres til en ny node. Dette kan gøres på flere måder, og det er afgørende at sikre, at denne ændring er så gennemsigtig for applikationen som muligt. I dette afsnit vil vi tage et kig på nogle af eksemplerne på, hvordan failover kan gøres transparent for applikationen.
DNS
En af måderne, hvorpå en applikation kan peges på en master, er ved at bruge DNS-poster. Med lav TTL er det muligt at ændre den IP-adresse, som en DNS-indgang som 'master.dc1.example.com' peger på. En sådan ændring kan udføres gennem eksterne scripts, der udføres under failover-processen.
Serviceopdagelse
Værktøjer som Consul eller etc.d kan også bruges til at dirigere trafik til et korrekt sted. Sådanne værktøjer kan indeholde oplysninger om, at den aktuelle masters IP er sat til en eller anden værdi. Nogle af dem giver også mulighed for at bruge værtsnavnsopslag til at pege på en korrekt IP. Igen skal indgange i serviceopdagelsesværktøjer vedligeholdes, og en af måderne at gøre det på er at foretage disse ændringer under failover-processen ved at bruge hooks, der udføres på forskellige stadier af failover.
Proxy
Proxyer kan også bruges som en kilde til sandhed om topologi. Generelt set, uanset hvordan de opdager topologien (det kan enten være en automatisk proces, eller proxyen skal omkonfigureres, når topologien ændres), bør de indeholde den aktuelle tilstand af replikeringskæden, da de ellers ikke ville være i stand til at rute forespørgsler korrekt.
Tilgangen til at bruge en proxy som en kilde til sandhed kan være ret almindelig i forbindelse med tilgangen til at samle proxyer på applikationsværter. Der er adskillige fordele ved at samle proxy- og webservere:hurtig og sikker kommunikation ved hjælp af Unix-socket, holde et caching-lag (da nogle af proxyerne, som ProxySQL også kan cache) tæt på applikationen. I et sådant tilfælde giver det mening for applikationen blot at oprette forbindelse til proxyen og antage, at den vil dirigere forespørgsler korrekt.
Failover i ClusterControl
ClusterControl anvender industriens bedste praksis for at sikre, at failover-processen udføres korrekt. Det sikrer også, at processen vil være sikker - standardindstillingerne er beregnet til at afbryde failover, hvis der opdages mulige problemer. Disse indstillinger kan tilsidesættes af brugeren, hvis de ønsker at prioritere failover frem for datasikkerhed.
Når en masterfejl er blevet opdaget af ClusterControl, startes en failover-proces, og en første failover-hook udføres straks:

Dernæst testes mastertilgængelighed.

ClusterControl udfører omfattende test for at sikre, at masteren faktisk ikke er tilgængelig. Denne adfærd er aktiveret som standard, og den administreres af følgende variabel:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled. Som et følgende trin sikrer ClusterControl, at den gamle master er nede, og hvis ikke, vil ClusterControl ikke forsøge at genoprette den:

Næste trin er at bestemme, hvilken vært der kan bruges som masterkandidat. ClusterControl kontrollerer, om der er defineret en hvidliste eller en sortliste.
Du kan gøre det ved at bruge følgende variabler i cmon-konfigurationsfilen:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set. replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set. Det er også muligt at konfigurere ClusterControl til at se efter forskelle i binære logfiltre på tværs af alle replikaer. Det kan gøres ved hjælp af variabelen replication_check_binlog_filtration_bf_failover. Som standard er disse kontroller deaktiveret. ClusterControl verificerer også, at der ikke er nogen fejlagtige transaktioner på plads, hvilket kan forårsage problemer.

Du kan også bede ClusterControl om automatisk at genopbygge replikaer, som ikke kan replikere fra den nye master ved at bruge følgende indstilling i cmon-konfigurationsfilen:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default). 
Bagefter udføres et andet script:det defineres i indstillingen replication_pre_failover_script. Dernæst gennemgår en kandidat en forberedelsesproces.


ClusterControl venter på, at gentag-logfiler bliver anvendt (sikker på, at datatab er minimalt). Den kontrollerer også, om der er andre tilgængelige transaktioner på resterende replikaer, som ikke er blevet anvendt på masterkandidat. Begge adfærd kan kontrolleres af brugeren ved at bruge følgende indstillinger i cmon-konfigurationsfilen:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled. replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately. Som du kan se, kan du gennemtvinge en failover, selvom ikke alle redo-loghændelser er blevet anvendt - det giver brugeren mulighed for at bestemme, hvad der har den højeste prioritet - datakonsistens eller failover-hastighed.


Til sidst vælges masteren, og det sidste script udføres (et script, der kan defineres som replication_post_failover_script.
Hvis du ikke har prøvet ClusterControl endnu, opfordrer jeg dig til at downloade det (det er gratis) og prøve det.
Master Detection i ClusterControl
ClusterControl giver dig mulighed for at implementere fuld High Availability-stak inklusive database- og proxy-lag. Mesteropdagelse er altid et af de problemer, man skal forholde sig til.
Hvordan fungerer det i ClusterControl?
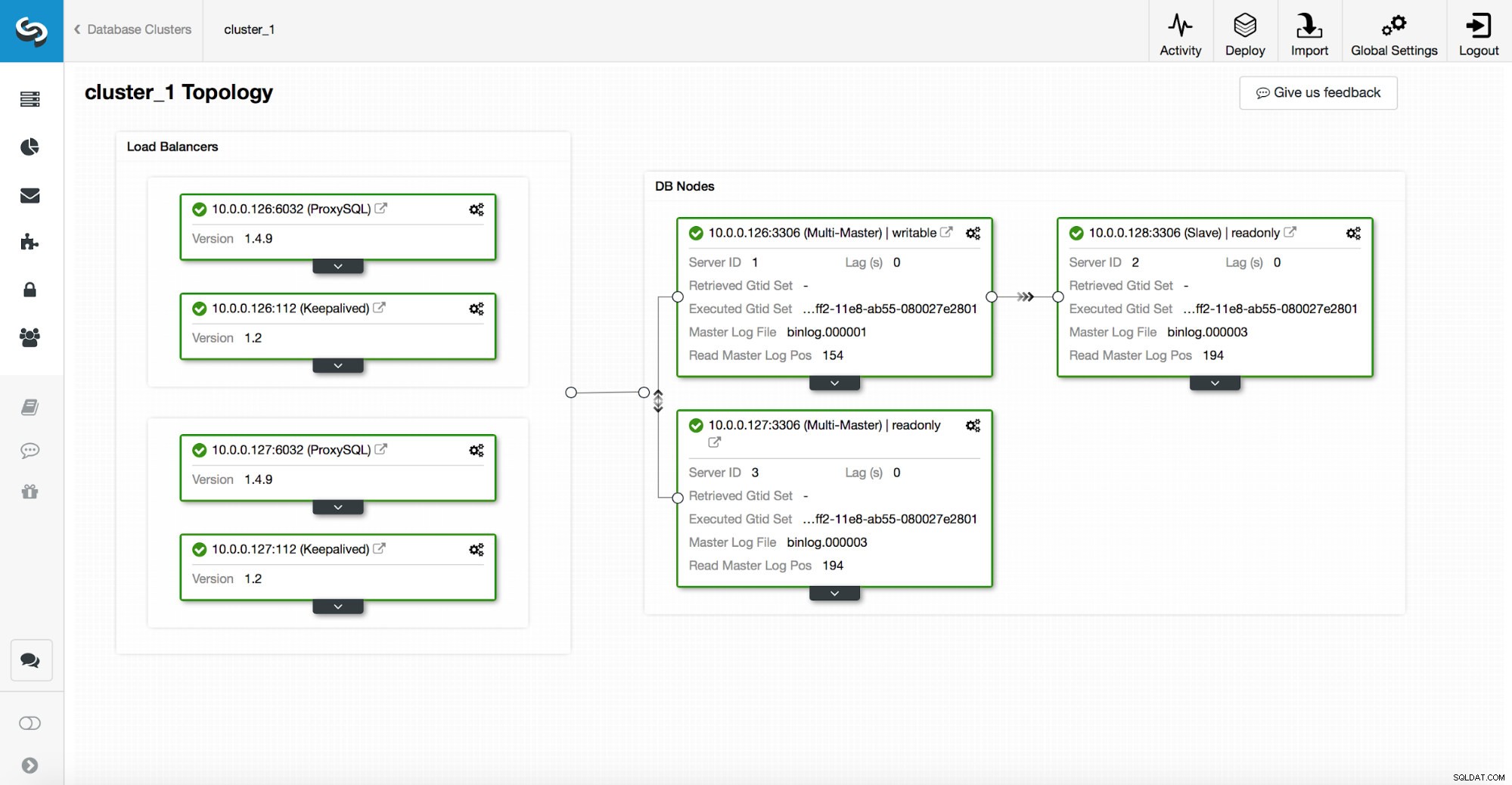
En høj tilgængelig stak, implementeret gennem ClusterControl, består af tre dele:
- databaselag
- proxylag, som kan være HAProxy eller ProxySQL
- bevaret lag, som ved brug af Virtual IP sikrer høj tilgængelighed af proxylaget
Proxyer er afhængige af read_only variabler på noderne.
Som du kan se på skærmbilledet ovenfor, er kun én node i topologien markeret som "skrivbar". Dette er masteren, og dette er den eneste node, som vil modtage skrivninger.
En proxy (i dette eksempel ProxySQL) vil overvåge denne variabel, og den omkonfigurerer sig selv automatisk.
På den anden side af den ligning tager ClusterControl sig af topologiændringer:failovers og switchovers. Den vil foretage nødvendige ændringer i read_only værdi for at afspejle topologiens tilstand efter ændringen. Hvis en ny master forfremmes, bliver den den eneste skrivbare node. Hvis en master vælges efter failover, vil den være skrivebeskyttet deaktiveret.
Oven på proxy-laget er keepalive implementeret. Den implementerer en VIP, og den overvåger tilstanden af underliggende proxyknuder. VIP peger på én proxy node på et givet tidspunkt. Hvis denne node går ned, omdirigeres virtuel IP til en anden node, hvilket sikrer, at trafikken dirigeret til VIP når en sund proxyknude.
For at opsummere det, opretter et program forbindelse til databasen ved hjælp af en virtuel IP-adresse. Denne IP peger på en af proxyerne. Proxyer omdirigerer trafik i overensstemmelse med topologistrukturen. Information om topologi er afledt af read_only-tilstand. Denne variabel administreres af ClusterControl, og den indstilles baseret på de topologiændringer, brugeren har anmodet om, eller ClusterControl, der udføres automatisk.