Når du skal arbejde med en database, som du ikke er 100 % bekendt med, kan du blive overvældet af de hundredvis af tilgængelige metrics. Hvilke er de vigtigste? Hvad skal jeg overvåge, og hvorfor? Hvilke mønstre i metrikker bør ringe nogle alarmklokker? I dette blogindlæg vil vi forsøge at introducere dig til nogle af de vigtigste metrics at holde øje med, mens du kører MySQL eller MariaDB i produktion.
Com_* Statustællere
Vi starter med Com_*-tællere - de definerer antallet og typer af forespørgsler, som MySQL udfører. Vi taler her om forespørgselstyper som SELECT, INSERT, UPDATE og mange flere. Det er ret vigtigt at holde øje med dem, da pludselige stigninger eller uventede fald kan tyde på, at noget gik galt i systemet.
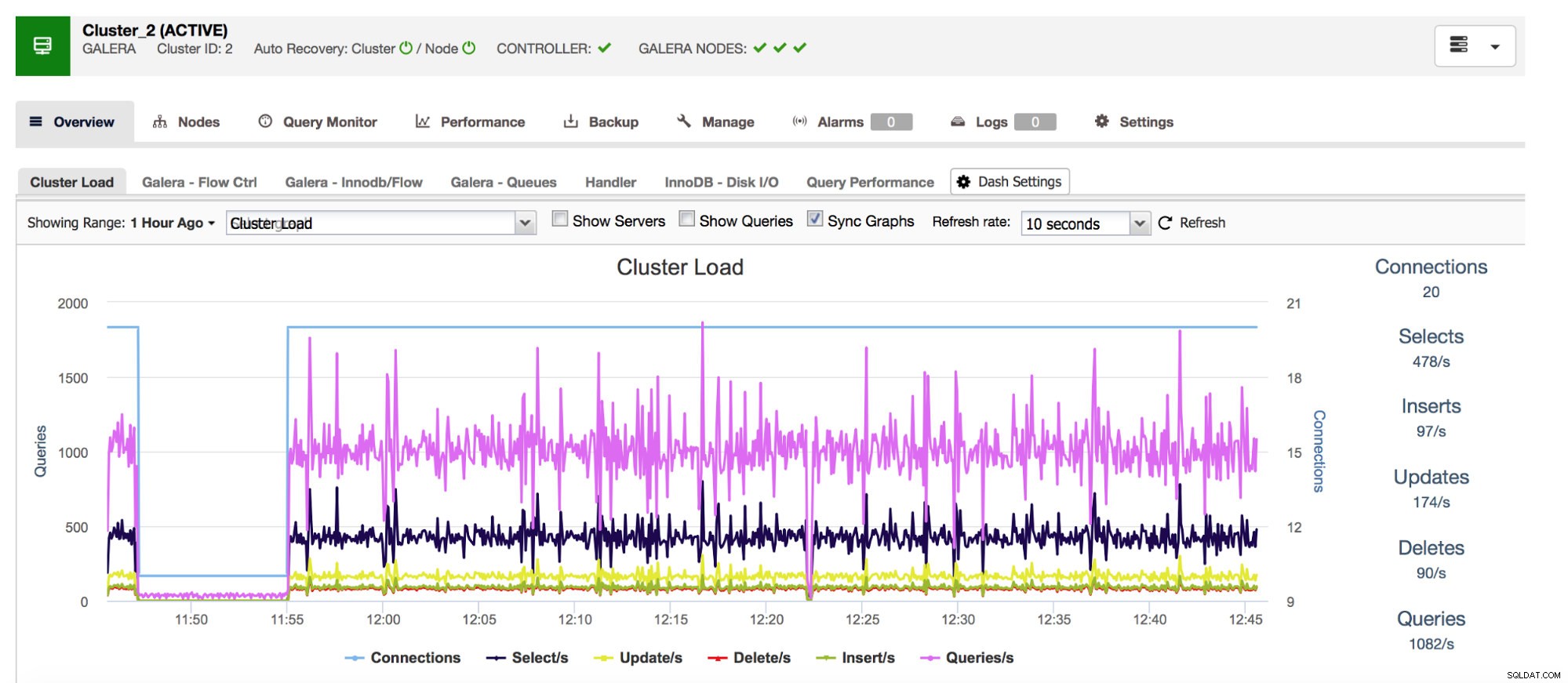
Vores altomfattende databasestyringssystem ClusterControl viser dig disse data relateret til de mest almindelige forespørgselstyper i afsnittet "Oversigt".
Handler_* Statustællere
En kategori af metrics, du bør holde øje med, er Handler_*-tællere i MySQL. Com_*-tællere fortæller dig, hvilken slags forespørgsler din MySQL-instans udfører, men én SELECT kan være helt anderledes end en anden - SELECT kunne være et primærnøgleopslag, det kan også være en tabelscanning, hvis et indeks ikke kan bruges. Handlere fortæller dig, hvordan MySQL får adgang til lagrede data - dette er meget nyttigt til at undersøge ydeevneproblemer og vurdere, om der er en mulig gevinst i forespørgselsgennemgang og yderligere indeksering.
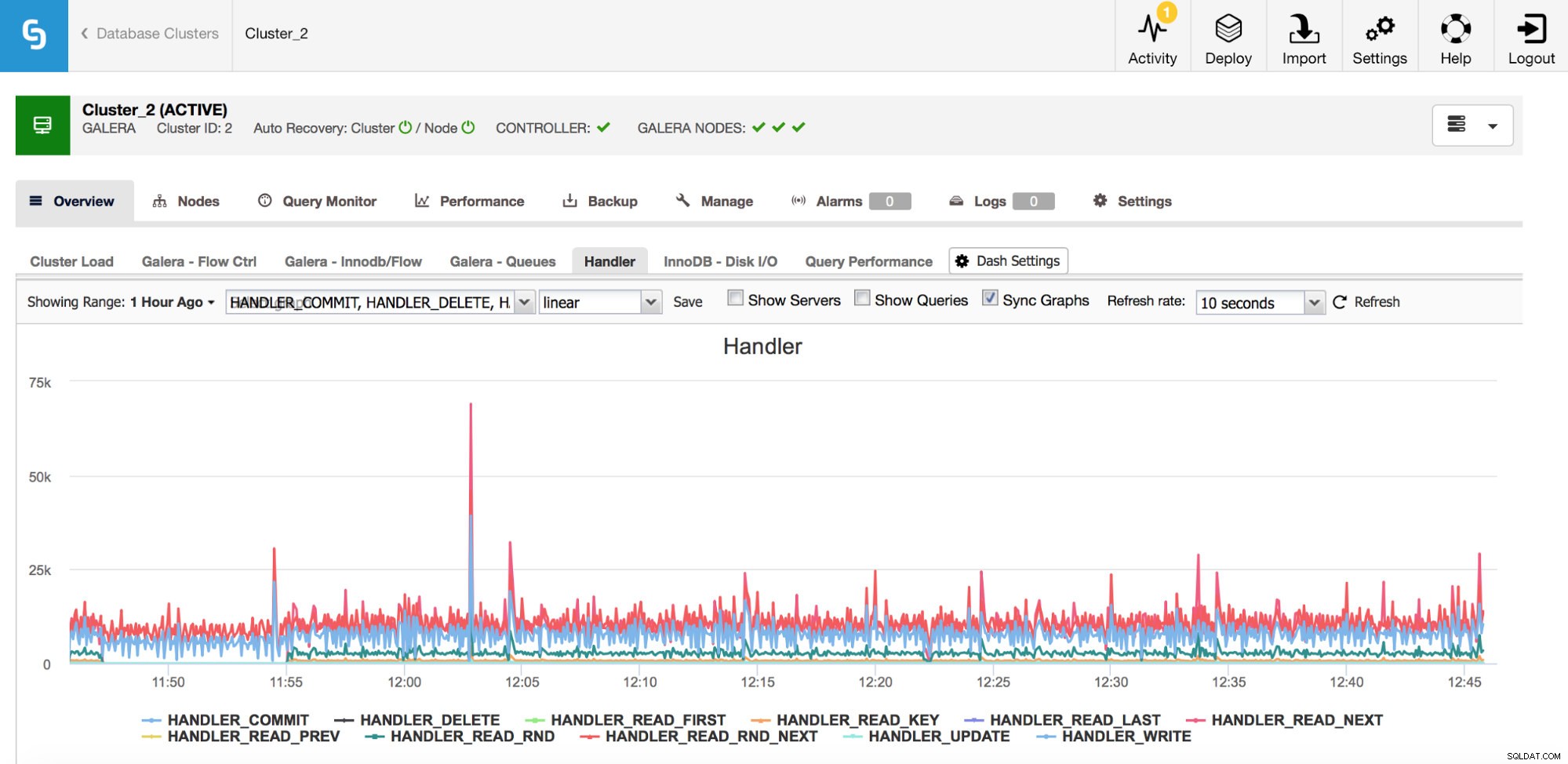
Som du kan se fra grafen ovenfor, er der mange metrics at spore (og ClusterControl-grafer de vigtigste) - vi vil ikke dække dem alle her (du kan finde beskrivelser i MySQL-dokumentation), men vi vil gerne fremhæve de vigtigste.
Handler_read_rnd_next - hver gang MySQL tilgår en række uden et indeksopslag, i sekventiel rækkefølge, vil denne tæller blive øget. Hvis i din workload handler_read_rnd_next er ansvarlig for en høj procentdel af hele trafikken, betyder det, at dine tabeller højst sandsynligt kan bruge nogle ekstra indekser, fordi MySQL laver masser af tabelscanninger.
Handler_read_next og handler_read_prev - disse to tællere opdateres, når MySQL laver en indeksscanning - frem eller tilbage. Handler_read_first og handler_read_last kan kaste lidt mere lys over, hvilken slags indeksscanninger det er - hvis vi taler om fuld indeksscanning (fremad eller tilbage), vil disse to tællere blive opdateret.
Handler_read_key - denne tæller, på den anden side, hvis dens værdi er høj, fortæller dig, at dine tabeller er godt indekseret, da mange af rækkerne blev tilgået gennem et indeksopslag.
Replikeringsforsinkelse
Hvis du arbejder med MySQL-replikering, er replikeringsforsinkelse en metrik, du helt sikkert vil overvåge. Replikationsforsinkelse er uundgåelig, og du bliver nødt til at håndtere det, men for at håndtere det skal du forstå, hvorfor det sker. For at det første skridt vil være at vide, _hvornår_ det dukkede op.
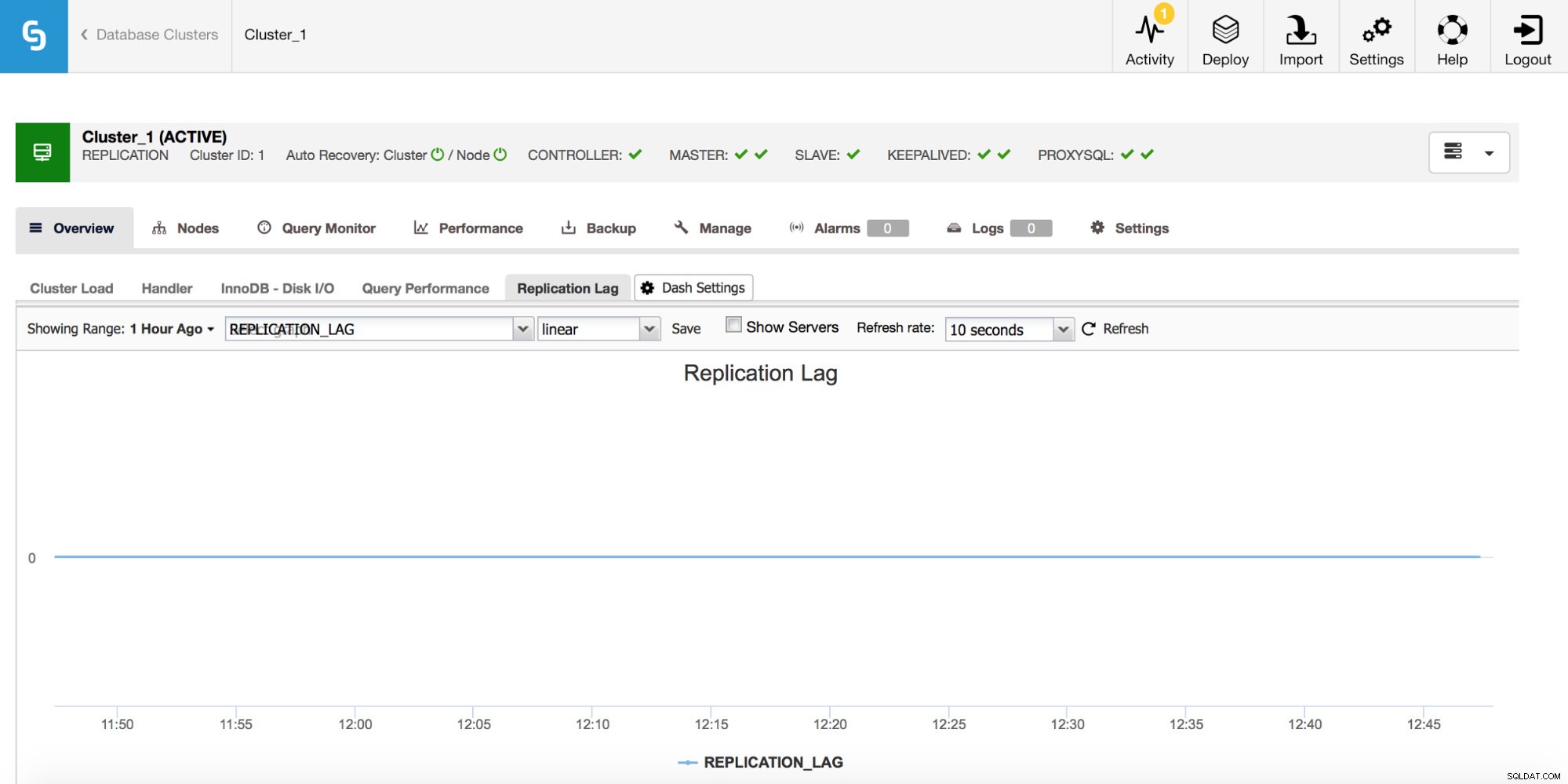
Når du ser en stigning i replikationsforsinkelsen, vil du gerne tjekke andre grafer for at få flere spor - hvorfor er det sket? Hvad kan have forårsaget det? Årsagerne kan være forskellige - lange, tunge DML'er, betydelig stigning i antallet af DML'er, der udføres på kort tid, CPU- eller I/O-begrænsninger.
InnoDB I/O
Der er en række vigtige metrics til at overvåge, der er relateret til I/O.
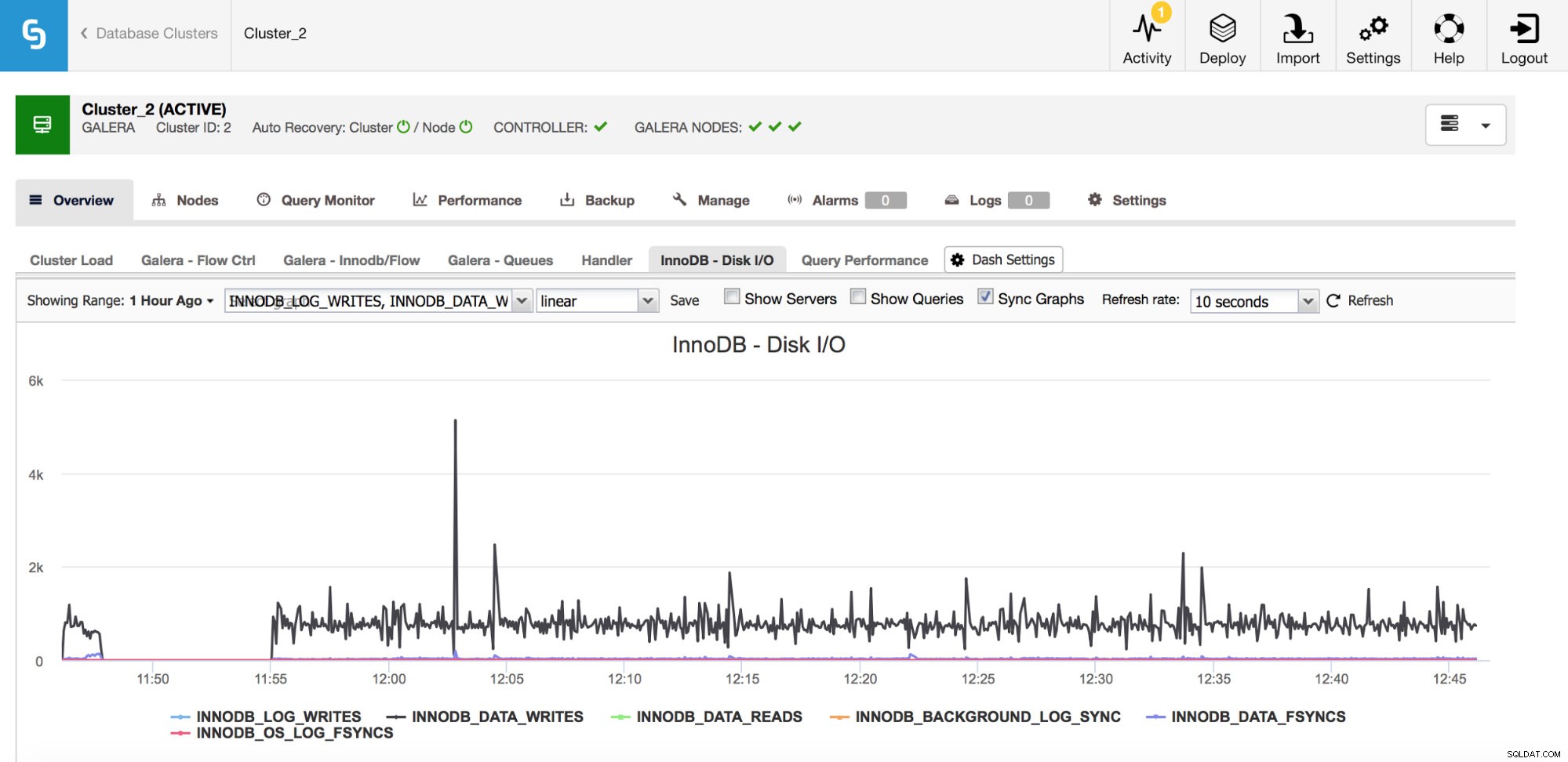
I grafen ovenfor kan du se et par målinger, der fortæller dig, hvilken slags I/O InnoDB gør - data skriver og læser, skriver om log, fsyncs. Disse målinger hjælper dig med at afgøre, for eksempel, om replikationsforsinkelsen var forårsaget af en stigning i I/O eller måske på grund af en anden årsag. Det er også vigtigt at holde styr på disse målinger og sammenligne dem med dine hardwarebegrænsninger - hvis du nærmer dig hardwaregrænserne for dine diske, er det måske på tide at undersøge dette, før det får mere alvorlige konsekvenser for din databaseydeevne.
Severalnines DevOps Guide til Database Management Lær om, hvad du skal vide for at automatisere og administrere dine open source-databaser. Download gratisGalera-målinger - Flowkontrol og køer
Hvis du tilfældigvis bruger Galera Cluster (uanset hvilken smag du bruger), er der et par flere målinger, du gerne vil overvåge nøje, disse er noget bundet sammen. Først af dem er målinger relateret til flowkontrol.
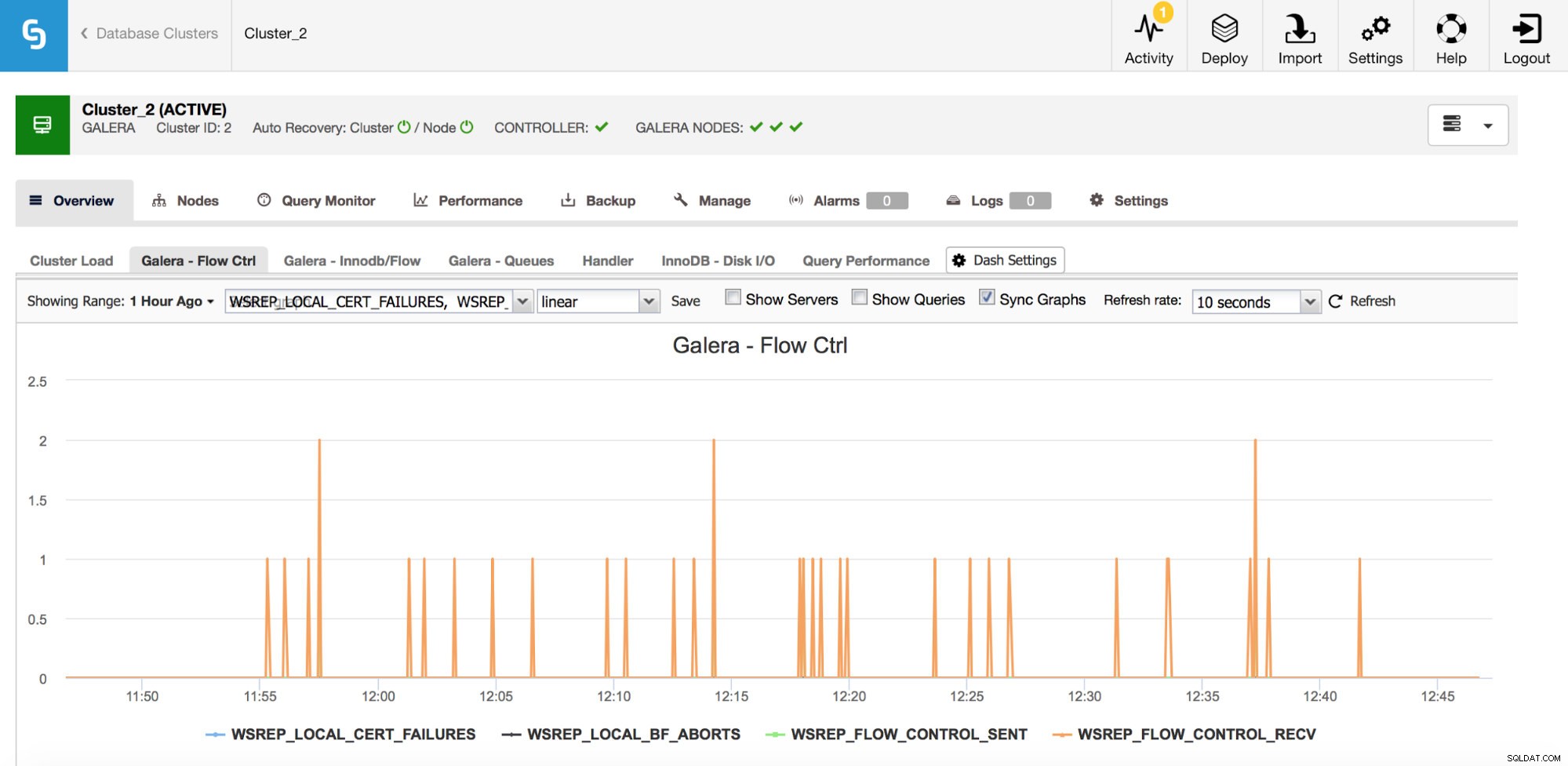
Flowkontrol i Galera er et middel til at holde klyngen synkroniseret. Når en node går i stå og ikke kan følge med resten af klyngen, begynder den at sende flowkontrolmeddelelser, der beder de resterende klyngeknuder om at sænke farten. Dette gør det muligt at indhente det. Dette reducerer klyngens ydeevne, så det er vigtigt at kunne fortælle hvilken node og hvornår den begyndte at sende flowkontrolmeddelelser. Dette kan forklare nogle af de opbremsninger, som brugerne oplever, eller begrænse tidsvinduet og værten, der skal bruges til yderligere undersøgelser.
Andet sæt metrics, der skal overvåges, er dem, der er relateret til sende- og modtagekøer i Galera.
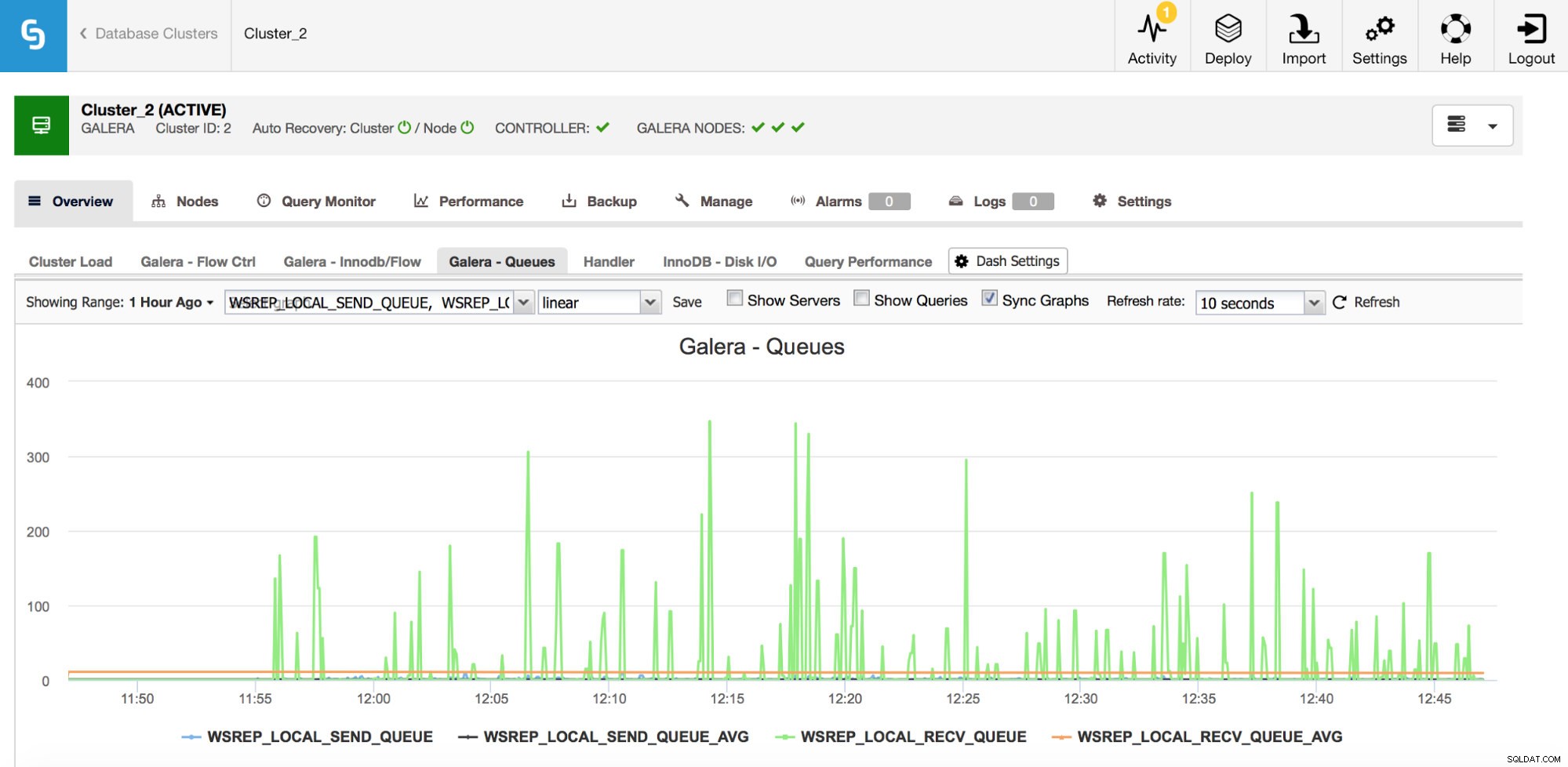
Galera-noder kan cache skrivesæt (transaktioner), hvis de ikke kan anvende dem alle med det samme. Om nødvendigt kan de også cache skrivesæt, som er ved at blive sendt til andre noder (hvis en given node modtager skrivninger fra applikationen). Begge tilfælde er symptomer på en opbremsning, som højst sandsynligt vil resultere i, at der sendes flowkontrolmeddelelser og kræver en vis undersøgelse - hvorfor det skete, på hvilken node, på hvilket tidspunkt?
Dette er selvfølgelig kun toppen af isbjerget, når vi overvejer alle de metrics, MySQL stiller til rådighed - stadig kan du ikke gå galt, hvis du begynder at se dem, vi dækkede her, ud over almindelige OS/hardware-metrics som CPU , hukommelse, diskudnyttelse og tjenesternes tilstand.