Opbyg høj tilgængelighed, et trin ad gangen
Når det kommer til databaseinfrastruktur, vil vi alle have det. Vi stræber alle efter at bygge et højt tilgængeligt setup. Redundans er nøglen. Vi begynder at implementere redundans på det laveste niveau og fortsætter op i stakken. Det starter med hardware - redundante strømforsyninger, redundant køling, hot-swap-diske. Netværkslag - flere NIC'er bundet sammen og forbundet til forskellige switches, som bruger redundante routere. Til opbevaring bruger vi diske sat i RAID, hvilket giver bedre ydeevne men også redundans. Derefter bruger vi på softwareniveau klyngeteknologier:flere databasenoder, der arbejder sammen om at implementere redundans:MySQL Cluster, Galera Cluster.
Alt dette er ikke godt, hvis du har alt i et enkelt datacenter:Når et datacenter går ned, eller en del af tjenesterne (men vigtige) går offline, eller selv hvis du mister forbindelsen til datacentret, vil din tjeneste gå ned - uanset mængden af redundans i de lavere niveauer. Og ja, de ting sker.
- Afbrydelse af S3-tjenesten skabte kaos i USA-Øst-1-regionen i februar 2017
- EC2- og RDS-tjenesteafbrydelse i USA-Øst-regionen i april 2011
- EC2, EBS og RDS blev afbrudt i EU-West-regionen i august 2011
- Strømsvigt fik Rackspace Texas DC til at falde i juni 2009
- UPS-fejl fik hundredvis af servere til at gå offline i Rackspace London DC i januar 2010
Dette er på ingen måde en komplet liste over fejl, det er kun resultatet af en hurtig Google-søgning. Disse tjener som eksempler på, at tingene kan og vil gå galt, hvis du lægger alle dine æg i den samme kurv. Et andet eksempel ville være orkanen Sandy, som forårsagede en enorm udvandring af data fra USA-Øst til US-Vest DC'er - på det tidspunkt kunne man næppe opdrive tilfælde i US-Vest, da alle skyndte sig at flytte deres infrastruktur til den anden kyst i forventning. at North Virginia DC vil blive alvorligt påvirket af vejret.
Så opsætning af multidatacenter er et must, hvis du vil bygge et miljø med høj tilgængelighed. I dette blogindlæg vil vi diskutere, hvordan man bygger en sådan infrastruktur ved hjælp af Galera Cluster til MySQL/MariaDB.
Galera-koncepter
Inden vi ser nærmere på bestemte løsninger, lad os bruge lidt tid på at forklare to koncepter, som er meget vigtige i højt tilgængelige multi-DC Galera-opsætninger.
Kvorum
Høj tilgængelighed kræver ressourcer – man har nemlig brug for et antal noder i klyngen for at gøre den yderst tilgængelig. En klynge kan tolerere tab af nogle af dens medlemmer, men kun i et vist omfang. Ud over en vis fejlrate ser du måske på et scenarie med split-hjerne.
Lad os tage et eksempel med en 2 node opsætning. Hvis en af noderne går ned, hvordan kan den anden så vide, at dens peer styrtede ned, og det ikke er en netværksfejl? I så fald kan den anden node lige så godt være oppe at køre og betjene trafik. Der er ingen god måde at håndtere sådanne sager på... Det er grunden til, at fejltolerance normalt starter fra tre noder. Galera bruger en kvorumberegning til at bestemme, om det er sikkert for klyngen at håndtere trafik, eller om det skal indstille driften. Efter en fejl forsøger alle resterende noder at oprette forbindelse til hinanden og bestemme, hvor mange af dem der er oppe. Det sammenlignes derefter med klyngens tidligere tilstand, og så længe mere end 50 % af noderne er oppe, kan klyngen fortsætte med at fungere.
Dette resulterer i følgende:
2 node klynge - ingen fejltolerance
3 node klynge - op til 1 nedbrud
4 node klynge - op til 1 nedbrud (hvis to noder ville gå ned, kun 50 % af klyngen ville være tilgængelig, du har brug for mere end 50 % noder for at overleve)
5 node klynge - op til 2 nedbrud
6 node klynge - op til 2 nedbrud
Du ser sikkert mønsteret - du vil have, at din klynge skal have et ulige antal noder - med hensyn til høj tilgængelighed er der ingen mening i at flytte fra 5 til 6 noder i klyngen. Hvis du vil have bedre fejltolerance, bør du gå efter 7 noder.
Segmenter
Typisk i en Galera-klynge følger al kommunikation alt til alle-mønsteret. Hver node taler med alle de andre noder i klyngen.
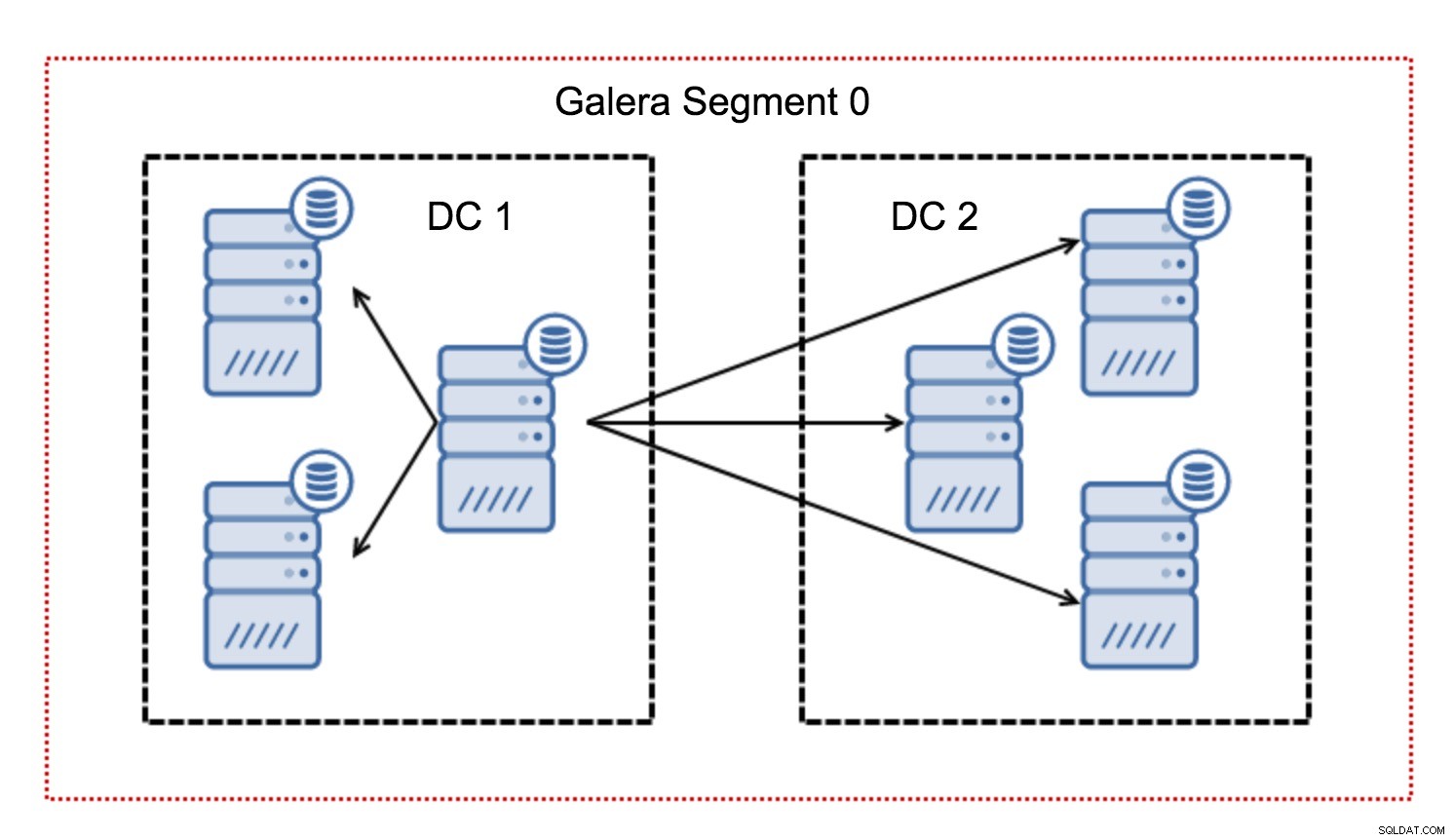
Som du måske ved, skal hvert skrivesæt i Galera være certificeret af alle noderne i klyngen - derfor skal hver skrivning, der er sket på en node, overføres til alle noderne i klyngen. Dette fungerer ok i et miljø med lav latency. Men hvis vi taler om multi-DC opsætninger, skal vi overveje meget højere latency end i et lokalt netværk. For at gøre det mere udholdeligt i klynger, der spænder over Wide Area Networks, introducerede Galera segmenter.
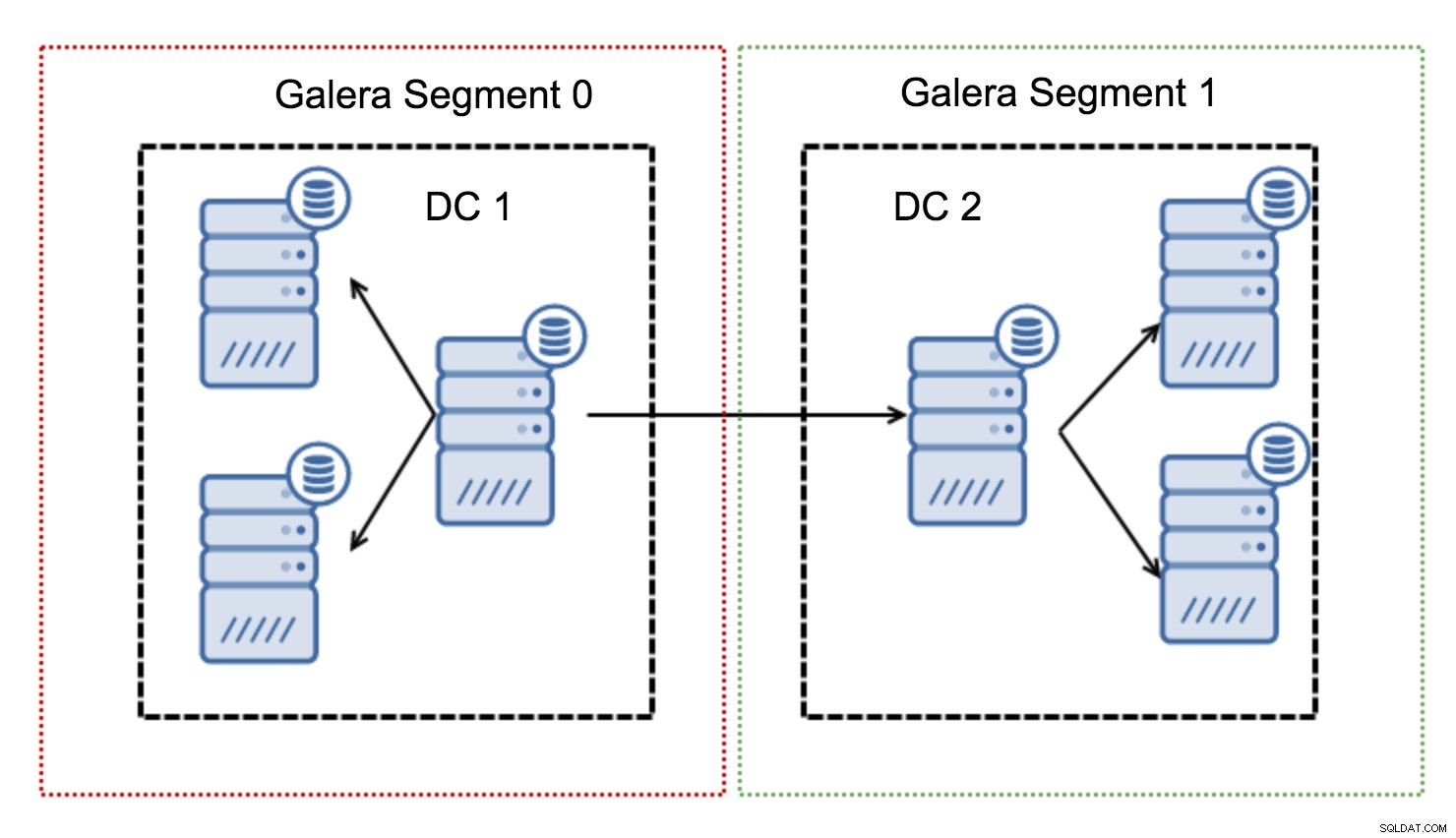
De fungerer ved at indeholde Galera-trafikken i en gruppe af noder (segment). Alle noder inden for et enkelt segment fungerer, som om de var i et lokalt netværk - de antager en til alle kommunikation. For krydssegmenttrafik er tingene anderledes - i hvert af segmenterne vælges én "relæ"-knude, al trafik på tværs af segmenter går gennem disse knudepunkter. Når en relæknude går ned, vælges en anden knude. Dette reducerer ikke latensen meget - trods alt vil WAN-latenstiden forblive den samme, uanset om du opretter forbindelse til en fjernvært eller til flere fjernværter, men i betragtning af at WAN-links har en tendens til at være begrænset i båndbredde, og der kan være en gebyr for mængden af overførte data, en sådan tilgang giver dig mulighed for at begrænse mængden af data, der udveksles mellem segmenter. En anden tids- og omkostningsbesparende mulighed er det faktum, at noder i samme segment prioriteres, når der er behov for en donor - igen, dette begrænser mængden af data, der overføres via WAN og højst sandsynligt fremskynder SST som et lokalt netværk næsten altid vil være hurtigere end et WAN-link.
Nu hvor vi har fået nogle af disse koncepter af vejen, lad os se på nogle andre vigtige aspekter af multi-DC-opsætninger til Galera-klyngen.
Problem, du er ved at tage stilling til
Når du arbejder i miljøer på tværs af WAN, er der et par problemer, du skal tage i betragtning, når du designer dit miljø.
Kvorumsberegning
I det foregående afsnit beskrev vi, hvordan en kvorumsberegning ser ud i Galera-klyngen - kort sagt, du vil have et ulige antal noder for at maksimere overlevelsesevnen. Alt dette er stadig sandt i multi-DC-opsætninger, men nogle flere elementer er tilføjet til blandingen. Først og fremmest skal du beslutte, om du vil have Galera til automatisk at håndtere en datacenterfejl. Dette vil afgøre, hvor mange datacentre du vil bruge. Lad os forestille os to DC'er - hvis du deler dine noder 50% - 50%, hvis det ene datacenter går ned, har det andet ikke 50%+1 noder til at opretholde sin "primære" tilstand. Hvis du opdeler dine noder på en ujævn måde, ved at bruge størstedelen af dem i "hoved" datacenteret, når det datacenter går ned, vil "backup" DC ikke have 50% + 1 noder til at danne et kvorum. Du kan tildele forskellige vægte til noder, men resultatet vil være nøjagtigt det samme - der er ingen måde at automatisk failover mellem to DC'er uden manuel indgriben. For at implementere automatiseret failover har du brug for mere end to DC'er. Igen, ideelt set et ulige tal - tre datacentre er en perfekt opsætning. Dernæst er spørgsmålet - hvor mange noder skal du have? Du vil gerne have dem jævnt fordelt på tværs af datacentrene. Resten er kun et spørgsmål om, hvor mange mislykkede noder din opsætning skal håndtere.
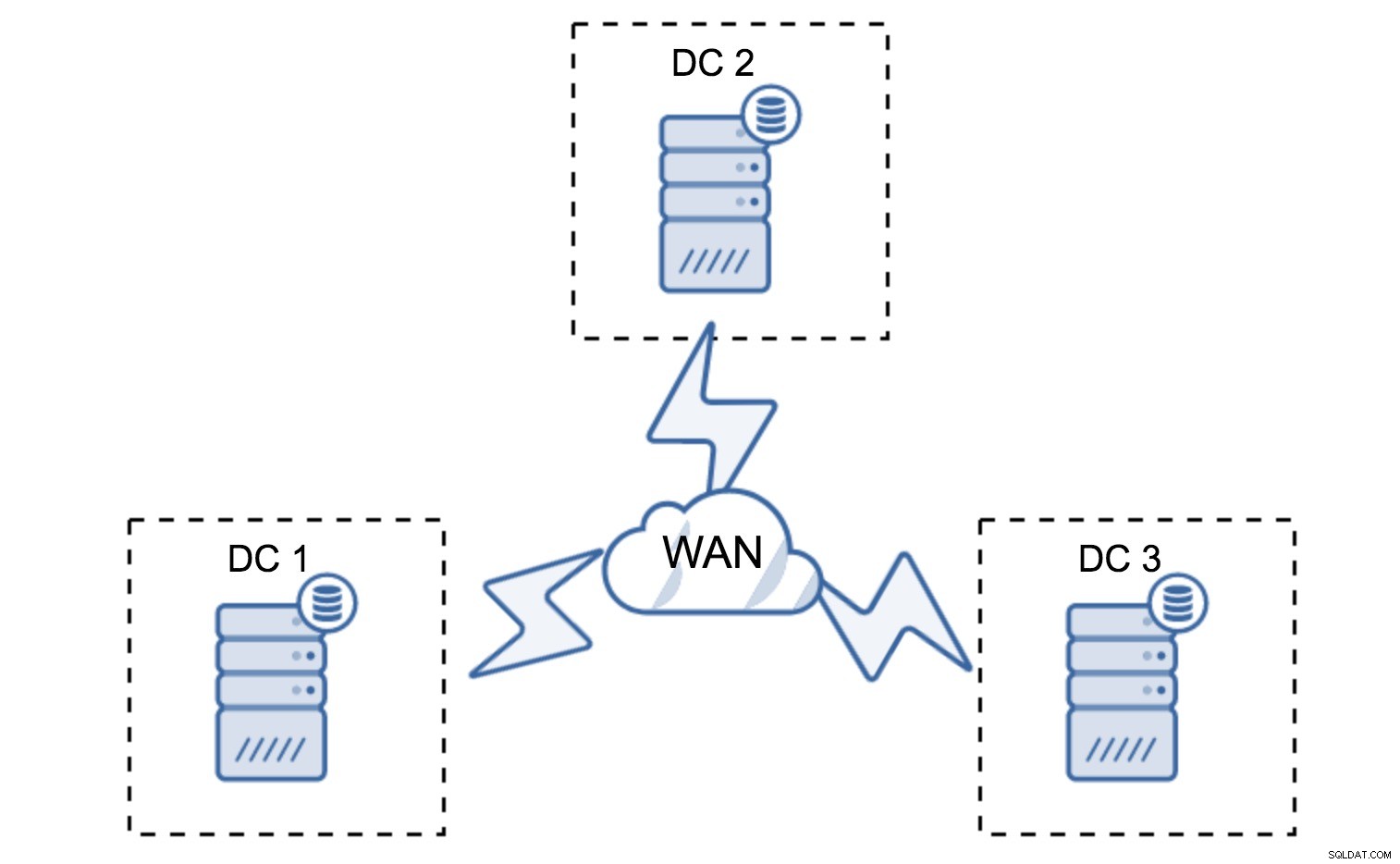
Minimal opsætning vil bruge én node pr. datacenter - det har dog alvorlige ulemper. Enhver tilstandsoverførsel kræver flytning af data på tværs af WAN, og dette resulterer i enten længere tid, der er nødvendig for at gennemføre SST, eller højere omkostninger.
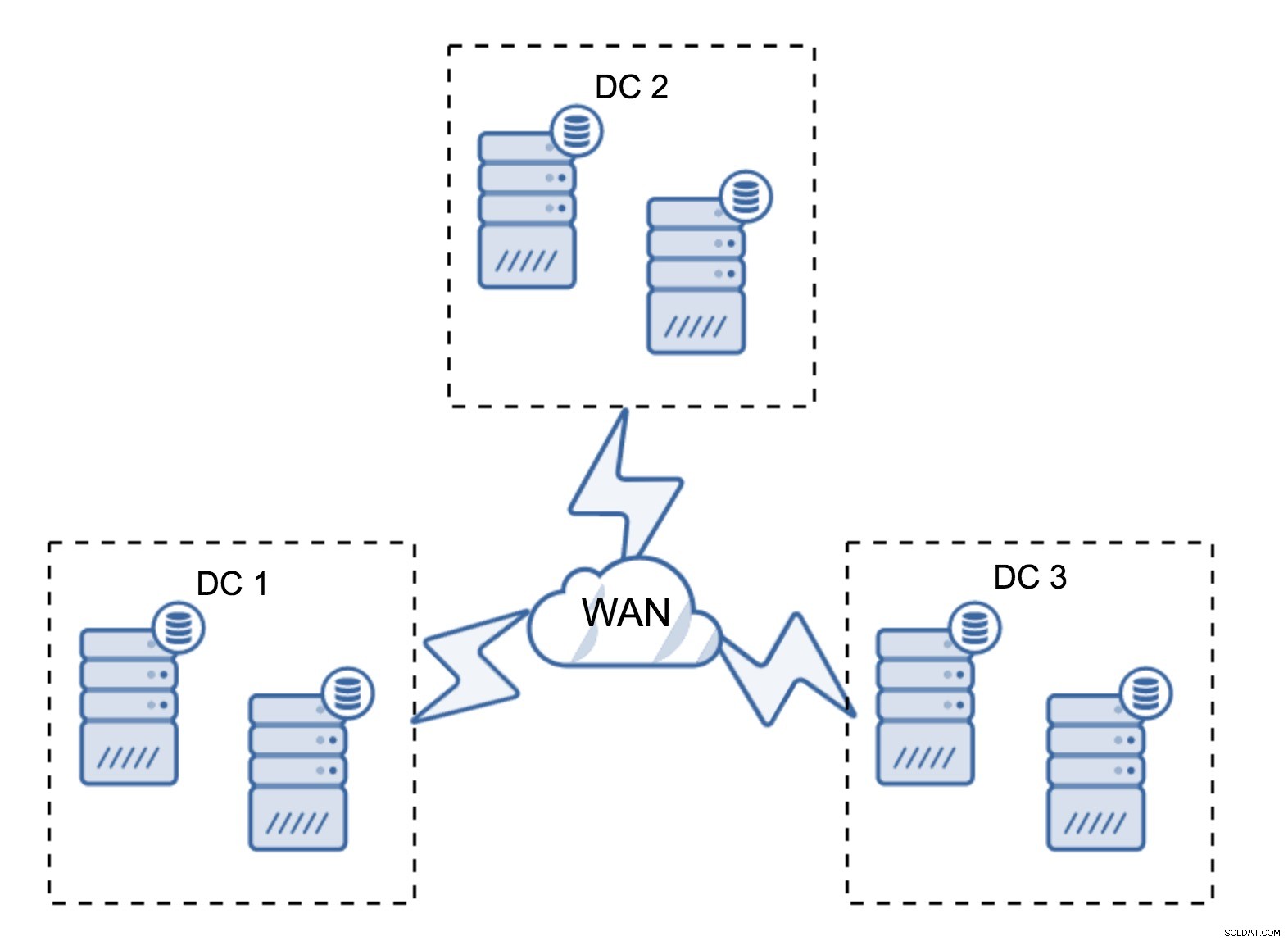
Helt typisk opsætning er at have seks noder, to pr. datacenter. Denne opsætning virker uventet, da den har et lige antal noder. Men når du tænker over det, er det måske ikke så stort et problem:det er ret usandsynligt, at tre noder vil gå ned på én gang, og sådan en opsætning vil overleve et nedbrud på op til to noder. Et helt datacenter kan gå offline, og to resterende DC'er vil fortsætte driften. Det har også en stor fordel i forhold til den minimale opsætning - når en node går offline, er der altid en anden node i datacentret, som kan tjene som donor. Det meste af tiden vil WAN ikke blive brugt til SST.
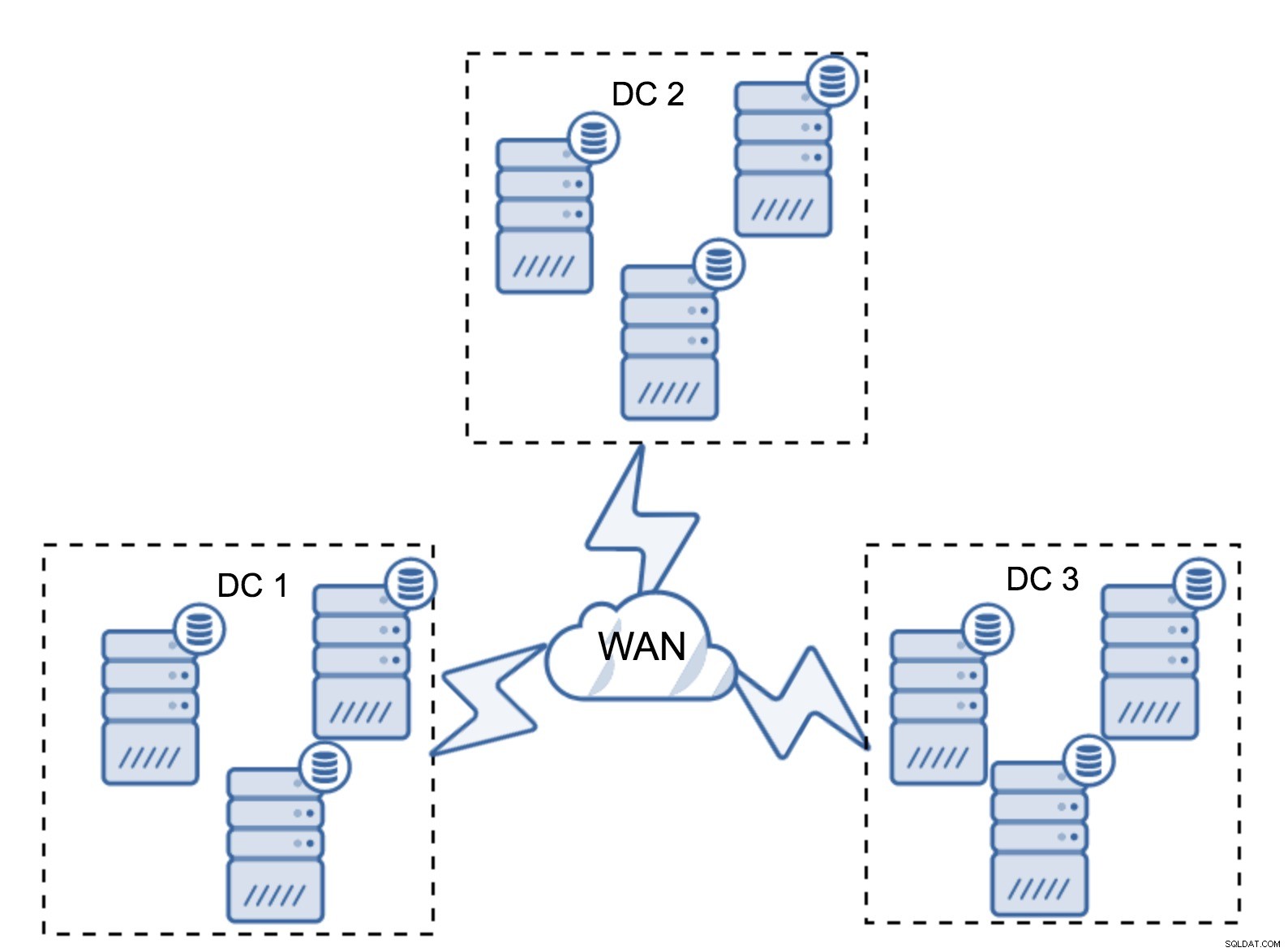
Selvfølgelig kan du øge antallet af noder til tre pr. klynge, ni i alt. Dette giver dig endnu bedre overlevelsesevne:op til fire noder kan gå ned, og klyngen vil stadig overleve. På den anden side skal du huske på, at selv med brug af segmenter betyder flere noder højere driftsomkostninger, og du kan kun udskalere Galera-klyngen til en vis grad.
Det kan ske, at der ikke er behov for et tredje datacenter, for lad os sige, at din applikation kun er placeret i to af dem. Selvfølgelig er kravet om tre datacentre stadig gyldigt, så du vil ikke gå uden om det, men det er helt fint at bruge en Galera Arbitrator (garbd) i stedet for fuldt indlæste databaseservere.
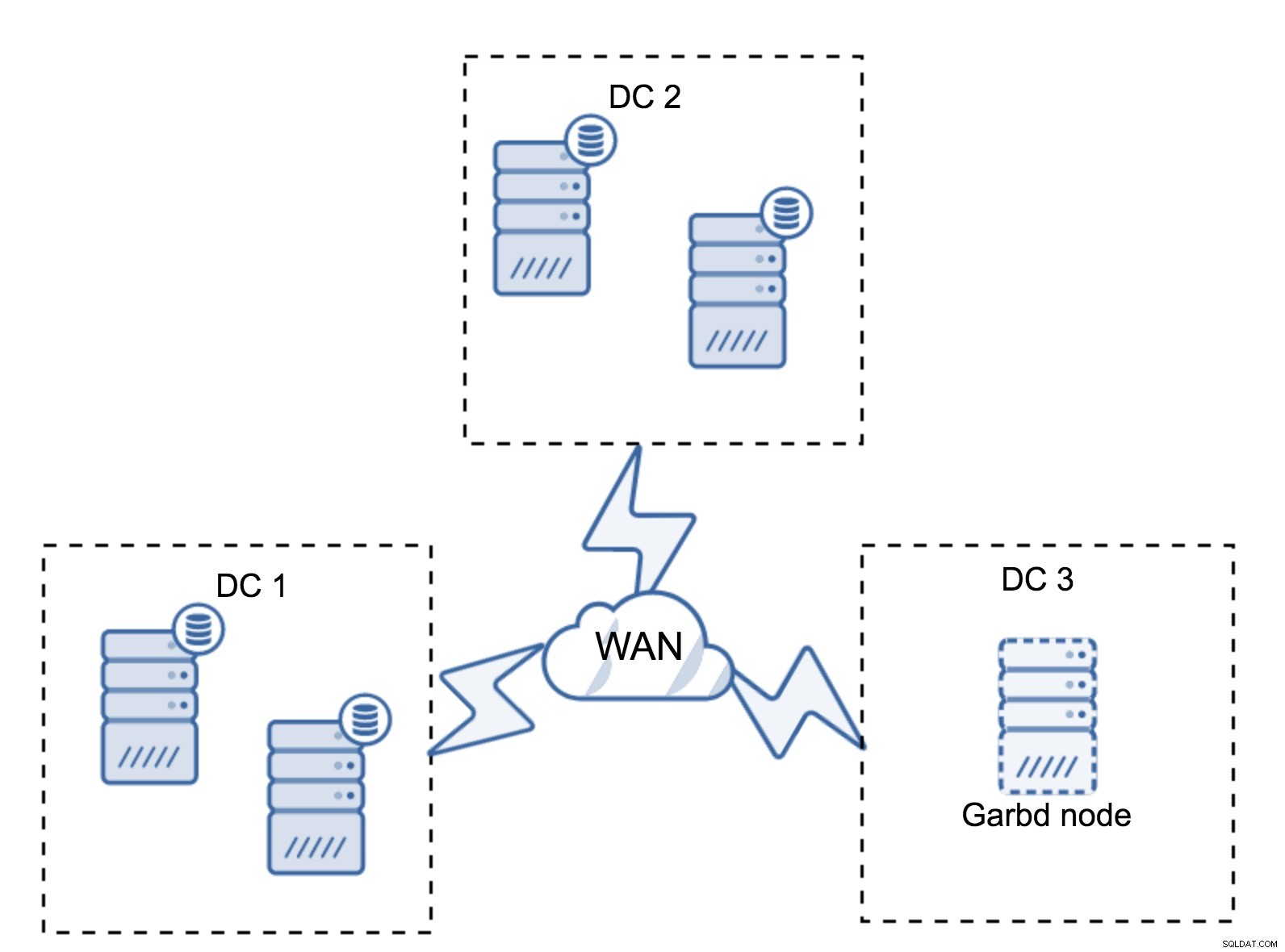
Garbd kan installeres på mindre noder, endda virtuelle servere. Det kræver ikke kraftig hardware, det gemmer ingen data eller anvender nogen af skrivesættene. Men det ser al replikeringstrafikken og deltager i kvorumberegningen. Takket være det kan du implementere opsætninger som fire noder, to pr. DC + garbd i den tredje - du har fem noder i alt, og en sådan klynge kan acceptere op til to fejl. Så det betyder, at den kan acceptere en fuldstændig lukning af et af datacentrene.
Hvilken mulighed er bedre for dig? Der er ingen bedste løsning for alle tilfælde, det hele afhænger af dine infrastrukturkrav. Heldigvis er der forskellige muligheder at vælge imellem:flere eller færre noder, fuld 3 DC eller 2 DC og garbd i den tredje - det er ret sandsynligt, at du finder noget, der passer til dig.
Netværksforsinkelse
Når du arbejder med multi-DC-opsætninger, skal du huske på, at netværksforsinkelsen vil være betydeligt højere end hvad du ville forvente fra et lokalt netværksmiljø. Dette kan alvorligt reducere ydeevnen af Galera-klyngen, når du sammenligner den med en selvstændig MySQL-instans eller en MySQL-replikeringsopsætning. Kravet om, at alle noderne skal certificere et skrivesæt betyder, at alle noderne skal modtage det, uanset hvor langt væk de er. Med asynkron replikering er der ingen grund til at vente før en commit. Selvfølgelig har replikering andre problemer og ulemper, men latency er ikke den største. Problemet er især synligt, når din database har hot spots - rækker, som jævnligt opdateres (tællere, køer osv.). Disse rækker kan ikke opdateres oftere end én gang pr. netværksrejse. For klynger, der spænder over hele kloden, kan dette nemt betyde, at du ikke vil være i stand til at opdatere en enkelt række oftere end 2 - 3 gange i sekundet. Hvis dette bliver en begrænsning for dig, kan det betyde, at Galera-klyngen ikke passer godt til netop din arbejdsbyrde.
Proxylag i Multi-DC Galera Cluster
Det er ikke nok at have Galera-klynge, der spænder over flere datacentre, du har stadig brug for din applikation for at få adgang til dem. En af de populære metoder til at skjule kompleksiteten af databaselaget fra en applikation er at bruge en proxy. Proxyer bruges som et indgangspunkt til databaserne, de sporer databasenodernes tilstand og skal altid lede trafik til kun de noder, der er tilgængelige. I dette afsnit vil vi forsøge at foreslå et proxy-lagdesign, som kan bruges til en multi-DC Galera-klynge. Vi bruger ProxySQL, som giver dig en del fleksibilitet i håndteringen af databasenoder, men du kan bruge en anden proxy, så længe den kan spore Galera-knudernes tilstand.
Hvor finder man proxyerne?
Kort sagt er der to almindelige mønstre her:du kan enten implementere ProxySQL på separate noder, eller du kan implementere dem på applikationsværterne. Lad os tage et kig på fordele og ulemper ved hver af disse opsætninger.
Proxylag som et separat sæt værter
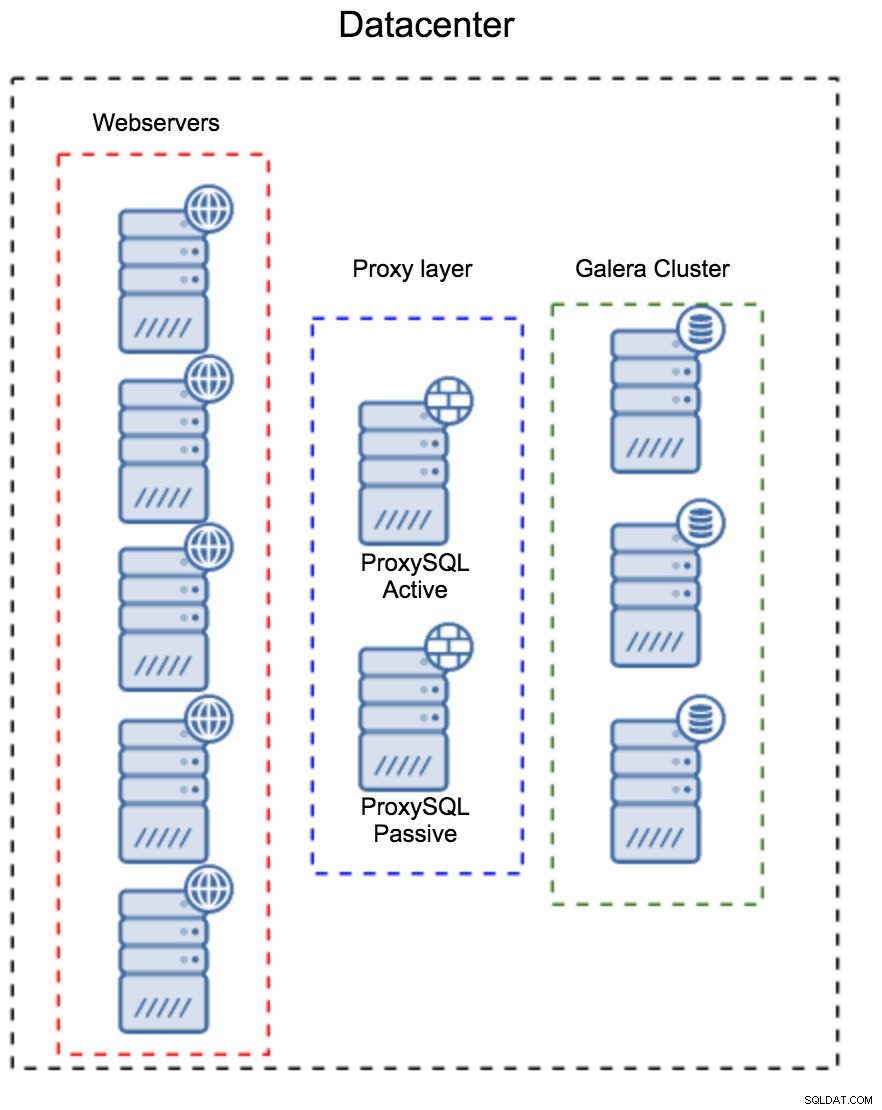
Det første mønster er at bygge et proxy-lag ved hjælp af separate, dedikerede værter. Du kan implementere ProxySQL på et par værter og bruge Virtual IP og keepalive for at opretholde høj tilgængelighed. En applikation vil bruge VIP'en til at oprette forbindelse til databasen, og VIP'en vil sikre, at anmodninger altid vil blive dirigeret til en tilgængelig ProxySQL. Hovedproblemet med denne opsætning er, at du højst bruger en af ProxySQL-instanserne - alle standby-noder bruges ikke til at dirigere trafikken. Dette kan tvinge dig til at bruge mere kraftfuld hardware, end du normalt ville bruge. På den anden side er det nemmere at vedligeholde opsætningen - du bliver nødt til at anvende konfigurationsændringer på alle ProxySQL-noder, men der vil kun være en håndfuld af dem. Du kan også bruge ClusterControls mulighed for at synkronisere noderne. En sådan opsætning skal duplikeres på hvert datacenter, du bruger.
Proxy installeret på applikationsforekomster
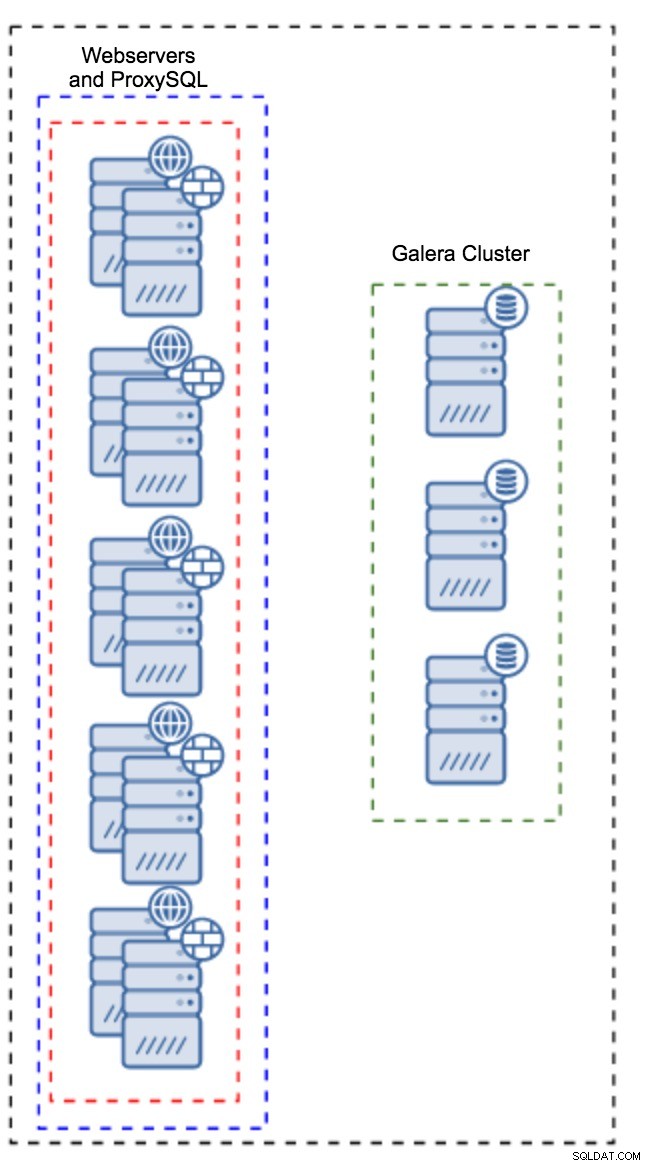
I stedet for at have et separat sæt værter, kan ProxySQL også installeres på applikationsværterne. Applikationen vil oprette forbindelse direkte til ProxySQL på localhost, den kunne endda bruge unix-socket for at minimere overhead af TCP-forbindelsen. Den største fordel ved sådan en opsætning er, at du har et stort antal ProxySQL-instanser, og belastningen er jævnt fordelt på tværs af dem. Hvis en går ned, vil kun den applikationsvært blive påvirket. De resterende noder vil fortsætte med at arbejde. Det mest alvorlige problem at stå over for er konfigurationsstyring. Med et stort antal ProxySQL-noder er det afgørende at komme med en automatiseret metode til at holde deres konfigurationer synkroniseret. Du kan bruge ClusterControl eller et konfigurationsstyringsværktøj som Puppet.
Justering af Galera i et WAN-miljø
Galera-standarderne er designet til lokalt netværk, og hvis du vil bruge det i et WAN-miljø, kræves der en vis justering. Lad os diskutere nogle af de grundlæggende tweaks, du kan lave. Husk på, at den præcise tuning kræver produktionsdata og trafik - du kan ikke bare foretage nogle ændringer og antage, at de er gode, du bør lave ordentlig benchmarking.
Opsætning af operativsystem
Lad os starte med operativsystemets konfiguration. Ikke alle de ændringer, der foreslås her, er WAN-relaterede, men det er altid godt at minde os selv om, hvad der er et godt udgangspunkt for enhver MySQL-installation.
vm.swappiness = 1Swappiness styrer, hvor aggressivt operativsystemet vil bruge swap. Det bør ikke indstilles til nul, fordi det i nyere kerner forhindrer operativsystemet i overhovedet at bruge swap, og det kan forårsage alvorlige ydeevneproblemer.
/sys/block/*/queue/scheduler = deadline/noopPlanlæggeren for blokenheden, som MySQL bruger, skal indstilles til enten deadline eller noop. Det nøjagtige valg afhænger af benchmarks, men begge indstillinger bør levere lignende ydeevne, bedre end standardplanlæggeren, CFQ.
For MySQL bør du overveje at bruge EXT4 eller XFS, afhængigt af kernen (ydeevnen af disse filsystemer ændres fra en kerneversion til en anden). Udfør nogle benchmarks for at finde den bedre løsning for dig.
Ud over dette vil du måske se på sysctl netværksindstillinger. Vi vil ikke diskutere dem i detaljer (du kan finde dokumentation her), men den generelle idé er at øge buffere, efterslæb og timeouts for at gøre det lettere at imødekomme boder og ustabile WAN-links.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Ud over OS tuning bør du overveje at justere Galera netværksrelaterede indstillinger.
evs.suspect_timeout
evs.inactive_timeoutDu vil måske overveje at ændre standardværdierne for disse variabler. Begge timeouts styrer, hvordan klyngen fordriver mislykkede noder. Mistænkt timeout finder sted, når alle noderne ikke kan nå det inaktive medlem. Inaktiv timeout definerer en hård grænse for, hvor længe en node kan forblive i klyngen, hvis den ikke reagerer. Normalt vil du opdage, at standardværdierne fungerer godt. Men i nogle tilfælde, især hvis du kører din Galera-klynge over WAN (for eksempel mellem AWS-regioner), kan forøgelse af disse variabler resultere i mere stabil ydeevne. Vi vil foreslå at indstille dem begge til PT1M for at gøre det mindre sandsynligt, at WAN-link-ustabilitet vil kaste en node ud af klyngen.
evs.send_window
evs.user_send_windowDisse variabler, evs.send_window og evs.user_send_window , definere hvor mange pakker der kan sendes via replikering på samme tid (evs.send_window ) og hvor mange af dem der kan indeholde data (evs.user_send_window ). For forbindelser med høj latenstid kan det være værd at øge disse værdier betydeligt (f.eks. 512 eller 1024).
evs.inactive_check_periodOvenstående variabel kan også ændres. evs.inactive_check_period , som standard er indstillet til et sekund, hvilket kan være for ofte til en WAN-opsætning. Vi vil foreslå at indstille den til PT30S.
gcs.fc_factor
gcs.fc_limitHer ønsker vi at minimere chancerne for, at flowkontrol sætter ind, derfor vil vi foreslå at indstille gcs.fc_factor til 1 og øg gcs.fc_limit til for eksempel 260.
gcs.max_packet_sizeDa vi arbejder med WAN-linket, hvor latency er væsentligt højere, ønsker vi at øge pakkernes størrelse. Et godt udgangspunkt ville være 2097152.
Som vi nævnte tidligere, er det praktisk talt umuligt at give en simpel opskrift på, hvordan man indstiller disse parametre, da det afhænger af for mange faktorer - du bliver nødt til at lave dine egne benchmarks, bruge data så tæt på dine produktionsdata som muligt, før du kan sige, at dit system er tunet. Når det er sagt, skulle disse indstillinger give dig et udgangspunkt for den mere præcise tuning.
Det er det for nu. Galera fungerer ret godt i WAN-miljøer, så prøv det og lad os vide, hvordan du kommer videre.