At flytte dine data til en offentlig cloud-tjeneste er en stor beslutning. Alle de store cloud-leverandører tilbyder cloud-databasetjenester, hvor Amazon RDS til MySQL nok er den mest populære.
I denne blog vil vi se nærmere på, hvad det er, hvordan det virker, og sammenligne dets fordele og ulemper.
RDS (Relational Database Service) er et Amazon Web Services-tilbud. Kort sagt er det en Database as a Service, hvor Amazon implementerer og driver din database. Det tager sig af opgaver som backup og patching af databasesoftwaren samt høj tilgængelighed. Nogle få databaser understøttes af RDS, her er vi dog primært interesserede i MySQL - Amazon understøtter MySQL og MariaDB. Der er også Aurora, som er Amazons klon af MySQL, forbedret, især inden for replikationsområdet og høj tilgængelighed.
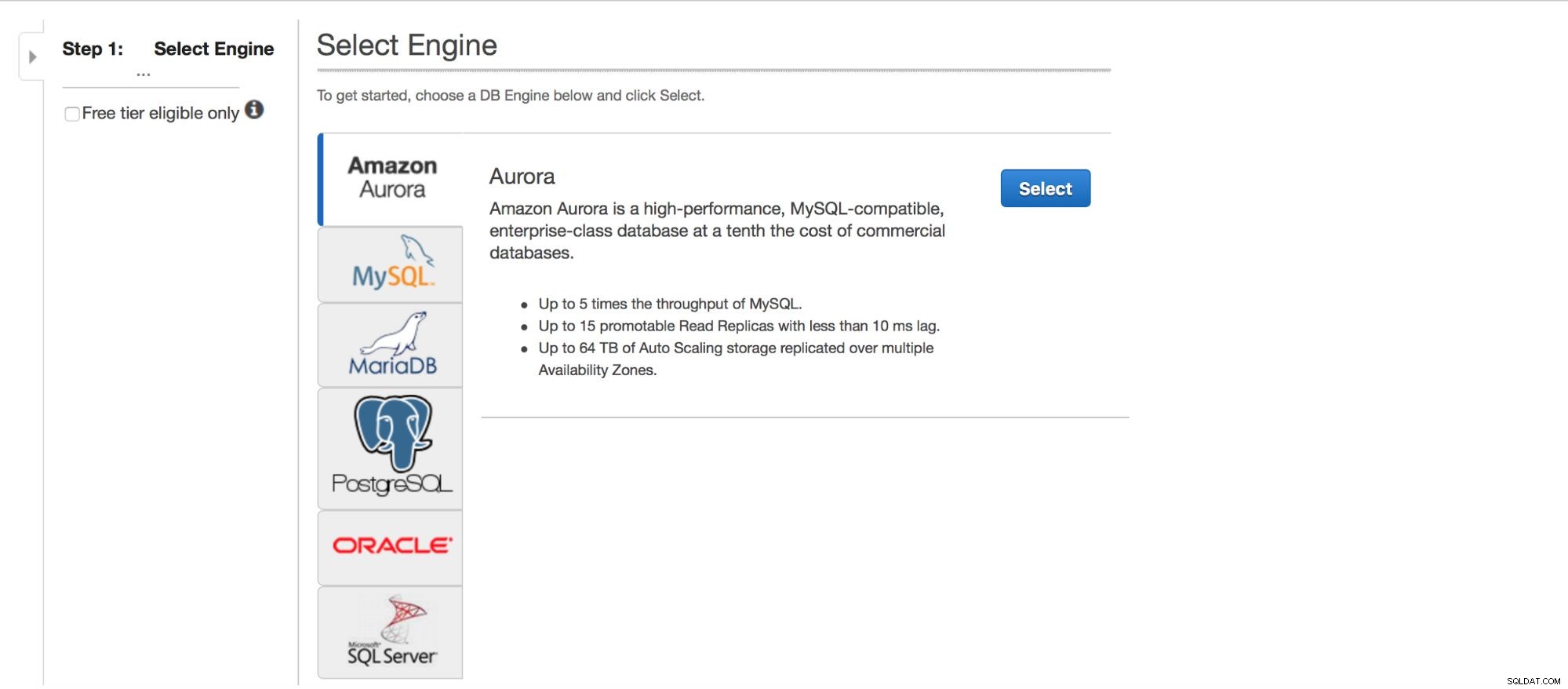
Implementering af MySQL via RDS
Lad os tage et kig på udrulningen af MySQL via RDS. Vi valgte MySQL, og så præsenteres vi for et par implementeringsmønstre at vælge imellem.
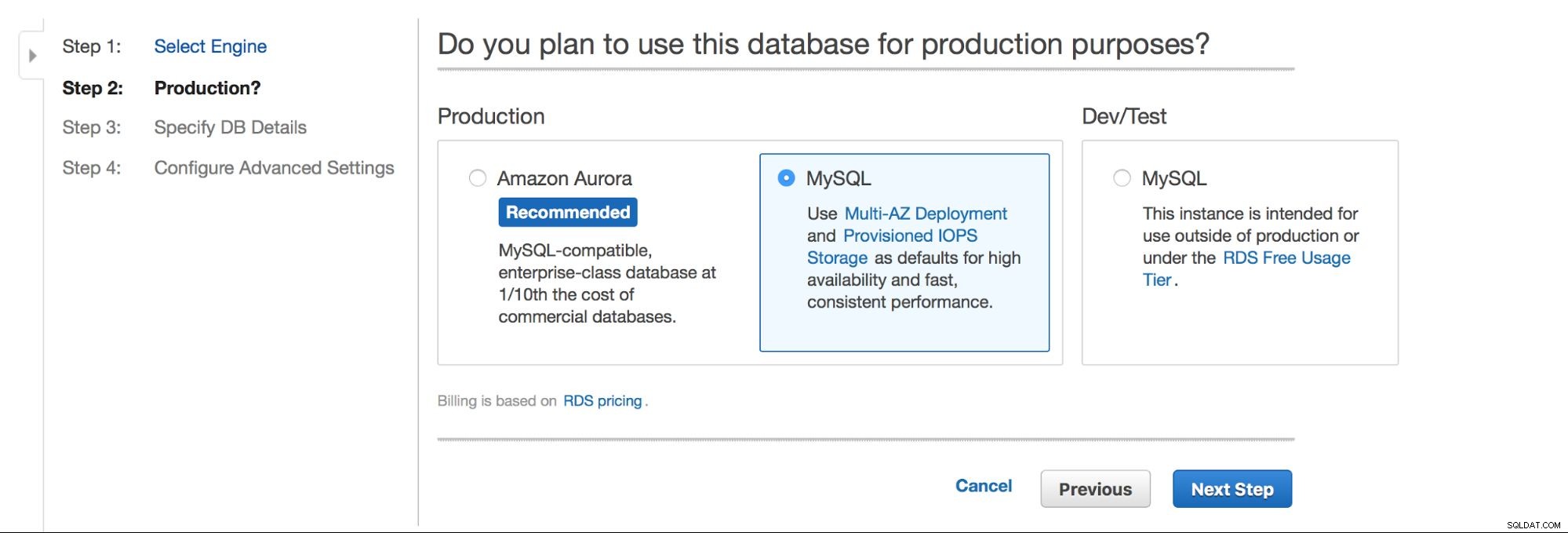
Hovedvalget er - vil vi have høj tilgængelighed eller ej? Aurora er også forfremmet.
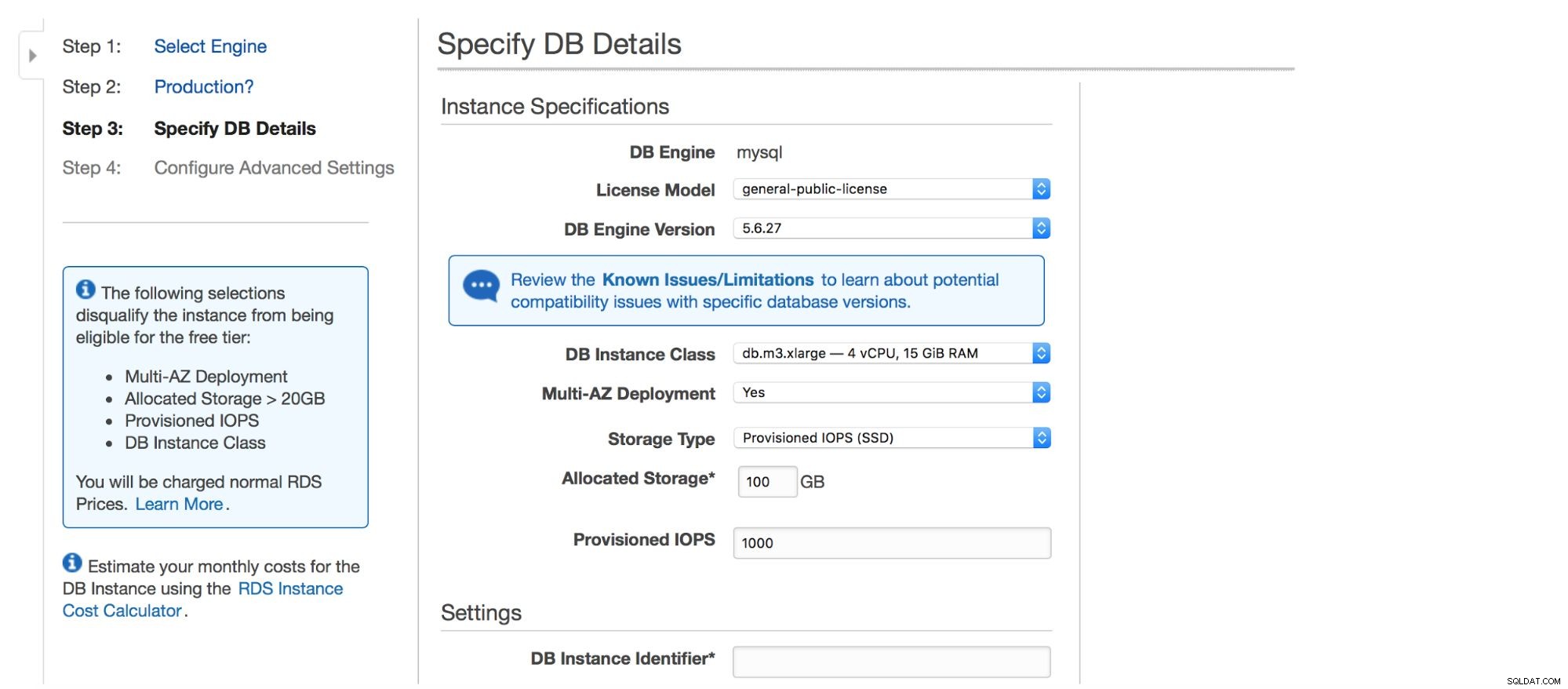
Næste dialogboks giver os nogle muligheder for at tilpasse. Du kan vælge en af mange MySQL-versioner - flere 5.5, 5.6 og 5.7 versioner er tilgængelige. Databaseforekomst - du kan vælge mellem typiske forekomststørrelser, der er tilgængelige i en given region.
Næste mulighed er et ret vigtigt valg - vil du bruge multi-AZ-implementering eller ej? Det hele handler om høj tilgængelighed. Hvis du ikke ønsker at bruge multi-AZ-implementering, vil en enkelt instans blive installeret. I tilfælde af fejl, vil en ny blive spundet op, og dens datavolumen vil blive genmonteret på den. Denne proces tager noget tid, hvor din database ikke vil være tilgængelig. Selvfølgelig kan du minimere denne påvirkning ved at bruge slaver og promovere en af dem, men det er ikke en automatiseret proces. Hvis du vil have automatiseret høj tilgængelighed, bør du bruge multi-AZ-implementering. Det, der vil ske, er, at der oprettes to databaseinstanser. Den ene er synlig for dig. En anden instans, i en separat tilgængelighedszone, er ikke synlig for brugeren. Det vil fungere som en skyggekopi, klar til at overtage trafikken, når den aktive node fejler. Det er stadig ikke en perfekt løsning, da trafikken skal skiftes fra den mislykkede instans til den skyggefulde instans. I vores test tog det ca. 45 sekunder at udføre en failover, men det kan naturligvis afhænge af instansstørrelse, I/O-ydeevne osv. Men det er meget bedre end ikke-automatiseret failover, hvor kun slaver er involveret.
Endelig har vi lagerindstillinger - type, størrelse, PIOPS (hvor relevant) og databaseindstillinger - identifikator, bruger og adgangskode.
I det næste trin venter et par flere muligheder på brugerinput.
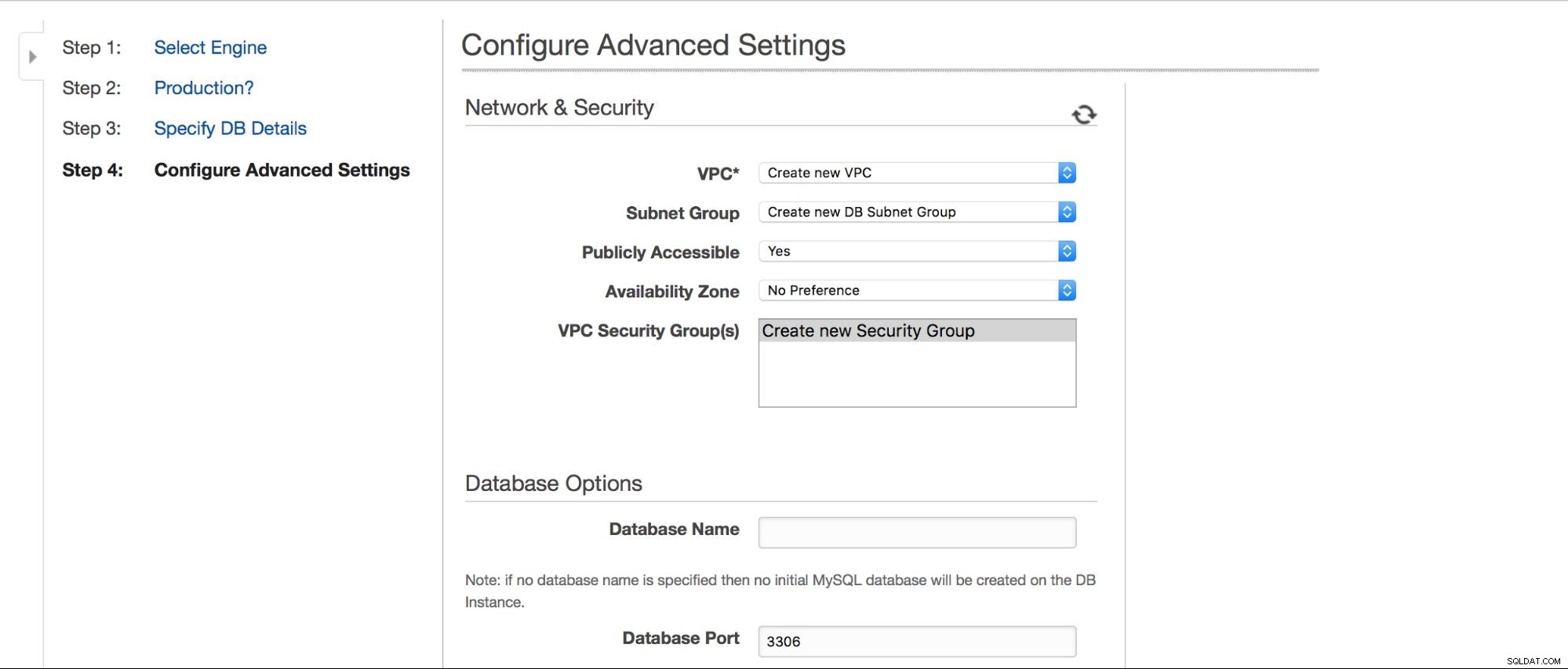
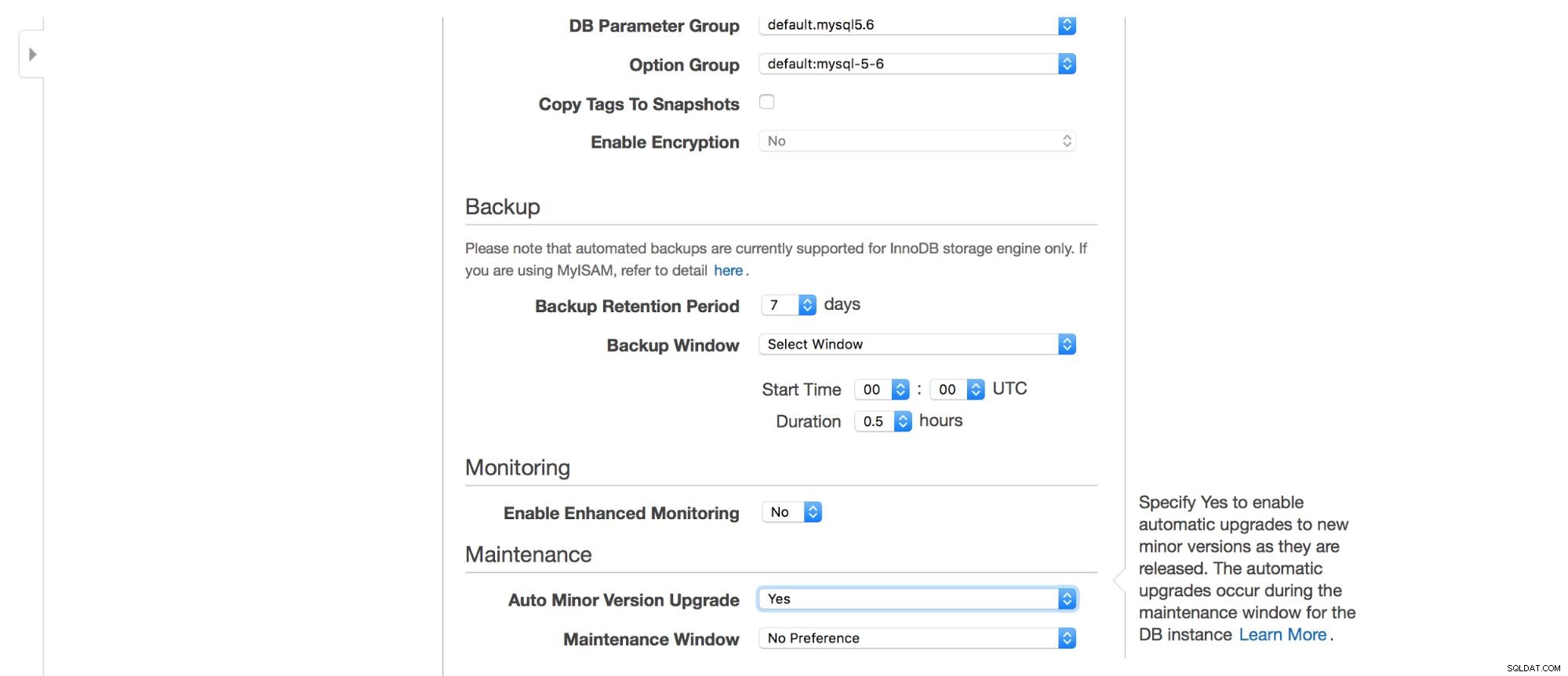
Vi kan vælge, hvor instansen skal oprettes:VPC, subnet, skal den være offentligt tilgængelig eller ej (som i - skal der tildeles en offentlig IP til RDS-instansen), tilgængelighedszone og VPC Security Group. Så har vi databasemuligheder:det første skema, der skal oprettes, port-, parameter- og indstillingsgrupper, om metadata-tags skal inkluderes i snapshots eller ej, krypteringsindstillinger.
Dernæst backup muligheder - hvor længe vil du beholde dine backups? Hvornår vil du have dem taget? Lignende opsætning er relateret til vedligeholdelse - nogle gange skal Amazon-administratorer udføre vedligeholdelse på din RDS-instans - det vil ske inden for et foruddefineret vindue, som du kan indstille her. Bemærk venligst, at der ikke er nogen mulighed for ikke at vælge mindst 30 minutter til vedligeholdelsesvinduet, derfor er det virkelig vigtigt at have multi-AZ-instanser på produktion. Vedligeholdelse kan resultere i genstart af node eller manglende tilgængelighed i nogen tid. Uden multi-AZ skal du acceptere den nedetid. Med multi-AZ-implementering sker failover.
Endelig har vi indstillinger relateret til yderligere overvågning - vil vi have det aktiveret eller ej?
Administration af RDS
I dette kapitel vil vi se nærmere på, hvordan man administrerer MySQL RDS. Vi vil ikke gennemgå alle tilgængelige muligheder derude, men vi vil gerne fremhæve nogle af de funktioner, Amazon har stillet til rådighed.
Snapshots
MySQL RDS bruger EBS-volumener som lager, så det kan bruge EBS-snapshots til forskellige formål. Sikkerhedskopier, slaver - alt sammen baseret på snapshots. Du kan oprette snapshots manuelt, eller de kan tages automatisk, når et sådant behov opstår. Det er vigtigt at huske på, at EBS-øjebliksbilleder generelt (ikke kun på RDS-instanser) tilføjer nogle overhead til I/O-operationer. Hvis du vil tage et øjebliksbillede, skal du forvente, at din I/O-ydelse falder. Medmindre du bruger multi-AZ-implementering, dvs. I sådanne tilfælde vil "skygge"-forekomsten blive brugt som en kilde til øjebliksbilleder, og ingen indvirkning vil være synlig på produktionsforekomsten.
Severalnines DevOps Guide til Database Management Lær om, hvad du skal vide for at automatisere og administrere dine open source-databaser. Download gratisSikkerhedskopier
Sikkerhedskopier er baseret på snapshots. Som nævnt ovenfor kan du definere din backup tidsplan og opbevaring, når du opretter en ny instans. Selvfølgelig kan du redigere disse indstillinger bagefter, gennem "modify instans" muligheden.
Du kan til enhver tid gendanne et øjebliksbillede - du skal gå til snapshot-sektionen, vælge det øjebliksbillede, du vil gendanne, og du vil blive præsenteret for en dialogboks, der ligner den, du har set, da du oprettede en ny instans. Dette er ikke en overraskelse, da du kun kan gendanne et øjebliksbillede i en ny instans - der er ingen måde at gendanne det på en af de eksisterende RDS-instanser. Det kan komme som en overraskelse, men selv i et cloudmiljø kan det give mening at genbruge hardware (og instanser, du allerede har). I et delt miljø kan ydeevnen af en enkelt virtuel instans variere - du foretrækker måske at holde dig til den præstationsprofil, som du allerede er bekendt med. Desværre er det ikke muligt i RDS.
En anden mulighed i RDS er point-in-time recovery - meget vigtig funktion, et krav for alle, der skal passe godt på sine data. Her er tingene mere komplekse og mindre lyse. Til at begynde med er det vigtigt at huske på, at MySQL RDS skjuler binære logfiler for brugeren. Du kan ændre et par indstillinger og liste oprettede binlogs, men du har ikke direkte adgang til dem - for at udføre nogen handling, inklusive brug af dem til gendannelse, kan du kun bruge UI eller CLI. Dette begrænser dine muligheder til, hvad Amazon giver dig mulighed for, og det giver dig mulighed for at gendanne din sikkerhedskopi op til den seneste "gendannelsestid", som tilfældigvis beregnes i 5 minutters interval. Så hvis dine data er blevet fjernet kl. 9:33a, kan du kun gendanne dem op til tilstanden kl. 9:30a. Point-in-time gendannelse fungerer på samme måde som gendannelse af snapshots - en ny instans oprettes.
Udskalering, replikering
MySQL RDS tillader udskalering ved at tilføje nye slaver. Når en slave oprettes, tages et snapshot af masteren, og det bruges til at oprette en ny vært. Denne del fungerer ret godt. Desværre kan du ikke skabe en mere kompleks replikeringstopologi som en, der involverer mellemliggende mastere. Du er ikke i stand til at oprette en master - master opsætning, som efterlader enhver HA i hænderne på Amazon (og multi-AZ-implementeringer). Efter hvad vi kan se, er der ingen måde at aktivere GTID på (ikke at du kunne drage fordel af det, da du ikke har nogen kontrol over replikationen, ingen CHANGE MASTER i RDS), kun almindelige, gammeldags binlog-positioner.
Mangel på GTID gør det ikke muligt at bruge multithreaded replikering - mens det er muligt at indstille et antal arbejdere ved hjælp af RDS parametergrupper, er dette ubrugeligt uden GTID. Hovedproblemet er, at der ikke er nogen måde at finde en enkelt binær logposition i tilfælde af et nedbrud - nogle arbejdere kunne have været bagud, nogle kunne være mere avancerede. Hvis du bruger den senest anvendte hændelse, mister du data, der endnu ikke er anvendt af disse "haltende" arbejdere. Hvis du vil bruge den ældste hændelse, vil du højst sandsynligt ende med "duplicate key"-fejl forårsaget af hændelser anvendt af de arbejdere, som er mere avancerede. Selvfølgelig er der en måde at løse dette problem på, men det er ikke trivielt, og det er tidskrævende - bestemt ikke noget, du nemt kan automatisere.
Brugere oprettet på MySQL RDS har ikke SUPER-privilegier, så operationer, som er enkle i selvstændig MySQL, er ikke trivielle i RDS. Amazon besluttede at bruge lagrede procedurer for at give brugeren mulighed for at udføre nogle af disse operationer. Fra hvad vi kan fortælle, er en række potentielle problemer dækket, selvom det ikke altid har været tilfældet - vi husker, da du ikke kunne rotere til den næste binære log på masteren. Et masternedbrud + binlog-korruption kunne gøre alle slaver ødelagte - nu er der en procedure for det:rds_next_master_log .
En slave kan manuelt forfremmes til en master. Dette ville tillade dig at skabe en slags HA oven på multi-AZ-mekanisme (eller omgå den), men det er blevet gjort meningsløst af det faktum, at du ikke kan genslave nogen af eksisterende slaver til den nye master. Husk, at du ikke har nogen kontrol over replikationen. Dette gør hele øvelsen forgæves - medmindre din mester kan rumme al din trafik. Efter at have promoveret en ny master, er du ikke i stand til at failover til den, fordi den ikke har nogen slaver til at håndtere din belastning. Oprettelse af nye slaver vil tage tid, da EBS-snapshots først skal oprettes, og dette kan tage timer. Derefter skal du varme infrastrukturen op, før du kan belaste den.
Mangel på SUPER Privilegium
Som vi sagde tidligere, giver RDS ikke brugere SUPER-privilegier, og dette bliver irriterende for nogen, der er vant til at have det på MySQL. Tag det for givet, at du i løbet af de første uger vil lære, hvor ofte det er påkrævet at gøre ting, som du gør ret ofte - såsom at dræbe forespørgsler eller betjene præstationsskemaet. I RDS bliver du nødt til at holde dig til en foruddefineret liste over lagrede procedurer og bruge dem i stedet for at gøre tingene direkte. Du kan liste dem alle ved hjælp af følgende forespørgsel:
SELECT specific_name FROM information_schema.routines;Som med replikering er en række opgaver dækket, men hvis du endte i en situation, som endnu ikke er dækket, er du uheldig.
Interoperabilitet og Hybrid Cloud-opsætning
Dette er et andet område, hvor RDS mangler fleksibilitet. Lad os sige, at du vil bygge en blandet cloud/on-premises-opsætning - du har en RDS-infrastruktur, og du vil gerne oprette et par slaver på stedet. Det største problem, du vil stå over for, er, at der ikke er nogen måde at flytte data ud af RDS på undtagen at tage et logisk dump. Du kan tage snapshots af RDS-data, men du har ikke adgang til dem, og du kan ikke flytte dem væk fra AWS. Du har heller ikke fysisk adgang til instansen for at bruge xtrabackup, rsync eller endda cp. Den eneste mulighed for dig er at bruge mysqldump, mydumper eller lignende værktøjer. Dette tilføjer kompleksitet (tegnsæt og sorteringsindstillinger kan forårsage problemer) og er tidskrævende (det tager lang tid at dumpe og indlæse data ved hjælp af logiske sikkerhedskopieringsværktøjer).
Det er muligt at opsætte replikering mellem RDS og en ekstern instans (på begge måder, så det er også muligt at migrere data til RDS), men det kan være en meget tidskrævende proces.
På den anden side, hvis du vil forblive i et RDS-miljø og spænde over din infrastruktur på tværs af Atlanterhavet eller fra øst til vestkyst i USA, giver RDS dig mulighed for det - du kan nemt vælge en region, når du opretter en ny slave.
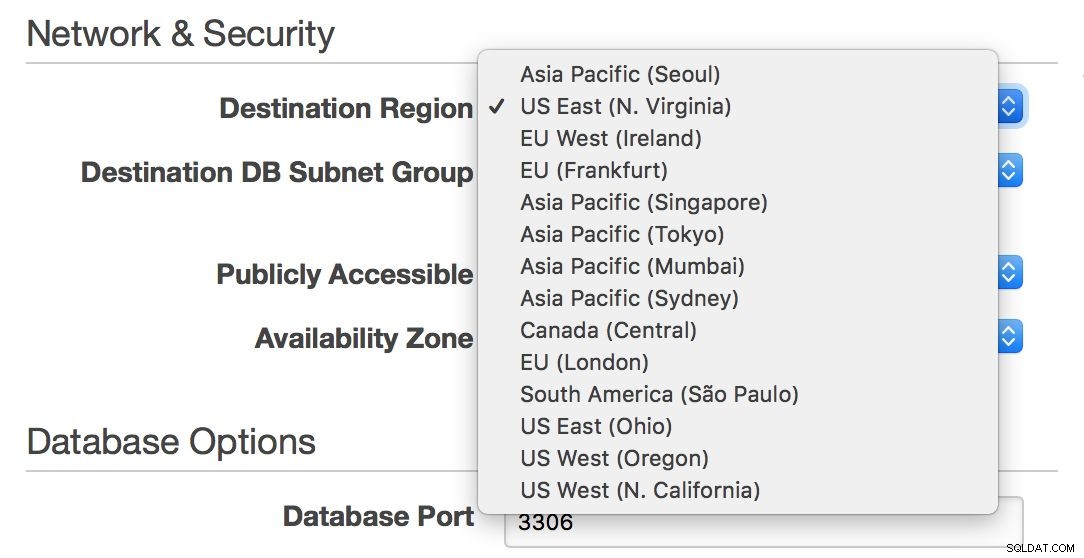
Desværre, hvis du gerne vil flytte din master fra den ene region til den anden, er dette praktisk talt ikke muligt uden nedetid - medmindre din enkelt node kan håndtere al din trafik.
Sikkerhed
Mens MySQL RDS er en administreret tjeneste, er ikke alle aspekter relateret til sikkerhed varetages af Amazons ingeniører. Amazon kalder det "Shared Responsibility Model". Kort sagt tager Amazon sig af sikkerheden på netværket og lagerlaget (så data overføres på en sikker måde), operativsystem (patches, sikkerhedsrettelser). På den anden side skal brugeren tage sig af resten af sikkerhedsmodellen. Sørg for, at trafik til og fra RDS-instans er begrænset inden for VPC, sørg for, at autentificering på databaseniveau udføres korrekt (ingen MySQL-brugerkonti uden adgangskode), bekræft, at API-sikkerhed er sikret (AMI'er er indstillet korrekt og med minimale nødvendige privilegier). Brugeren bør også tage sig af firewall-indstillinger (sikkerhedsgrupper) for at minimere eksponering af RDS og den VPC, den er i, til eksterne netværk. Det er også brugerens ansvar at implementere data ved hvile-kryptering - enten på applikationsniveau eller på databaseniveau ved at oprette en krypteret RDS-instans i første omgang.
Kryptering på databaseniveau kan kun aktiveres ved oprettelsen af forekomsten, du kan ikke kryptere en eksisterende, allerede kørende database.
RDS-begrænsninger
Hvis du planlægger at bruge RDS, eller hvis du allerede bruger det, skal du være opmærksom på de begrænsninger, der følger med MySQL RDS.
Mangel på SUPER-privilegium kan være, som vi nævnte, meget irriterende. Mens lagrede procedurer tager sig af en række operationer, er det en indlæringskurve, da du skal lære at gøre tingene på en anden måde. Mangel på SUPER-privilegier kan også skabe problemer med at bruge eksterne overvågnings- og trendværktøjer - der er stadig nogle værktøjer, som kan kræve dette privilegium for en del af dets funktionalitet.
Mangel på direkte adgang til MySQL-datamappe og logfiler gør det sværere at udføre handlinger som involverer dem. Det sker nu og da, at en DBA skal parse binære logfiler eller halefejl, langsom forespørgsel eller generel log. Selvom det er muligt at få adgang til disse logfiler på RDS, er det mere besværligt end at gøre, hvad du har brug for, ved at logge ind på shell på MySQL-værten. At downloade dem lokalt tager også noget tid og tilføjer yderligere forsinkelse til, hvad end du gør.
Manglende kontrol over replikeringstopologi, høj tilgængelighed kun i multi-AZ-implementeringer. Da du ikke har kontrol over replikeringen, kan du ikke implementere nogen form for høj tilgængelighedsmekanisme i dit databaselag. Det gør ikke noget, at du har flere slaver, du kan ikke bruge nogle af dem som mesterkandidater, for selvom du forfremmer en slave til en mester, er der ingen måde at genslave de resterende slaver fra denne nye mester. Dette tvinger brugerne til at bruge multi-AZ-implementeringer og øge omkostningerne ("skygge"-forekomsten kommer ikke gratis, brugeren skal betale for den).
Reduceret tilgængelighed gennem planlagt nedetid. Når du implementerer en RDS-instans, er du tvunget til at vælge et ugentligt tidsvindue på 30 minutter, hvor vedligeholdelseshandlinger kan udføres på din RDS-instans. På den ene side er dette forståeligt, da RDS er en Database as a Service, så hardware- og softwareopgraderinger af dine RDS-instanser administreres af AWS-ingeniører. På den anden side reducerer dette din tilgængelighed, fordi du ikke kan forhindre, at din masterdatabase går ned under vedligeholdelsesperioden. Igen, i dette tilfælde øger brug af multi-AZ-opsætning tilgængeligheden, da ændringer først sker på skyggeinstansen, og derefter udføres failover. Selve failoveren er dog ikke gennemsigtig, så du mister oppetiden på den ene eller den anden måde. Dette tvinger dig til at designe din app med uventede MySQL-masterfejl i tankerne. Ikke at det er et dårligt designmønster - databaser kan gå ned når som helst, og din applikation bør bygges på en måde, den kan modstå selv de mest alvorlige scenarier. Det er bare det, at med RDS har du begrænsede muligheder for høj tilgængelighed.
Reducerede muligheder for implementering af høj tilgængelighed. I betragtning af manglen på fleksibilitet i replikeringstopologistyringen er den eneste gennemførlige metode med høj tilgængelighed multi-AZ-implementering. Denne metode er god, men der er værktøjer til MySQL-replikering, som vil minimere nedetiden yderligere. For eksempel kan MHA eller ClusterControl, når de bruges i forbindelse med ProxySQL, levere (under nogle forhold som mangel på langvarige transaktioner) gennemsigtig failover-proces for applikationen. Mens du er på RDS, vil du ikke være i stand til at bruge denne metode.
Reduceret indsigt i din databases ydeevne. Selvom du kan få metrics fra MySQL selv, er det nogle gange bare ikke nok til at få en fuld 10k fod overblik over situationen. På et tidspunkt vil størstedelen af brugerne skulle håndtere virkelig mærkelige problemer forårsaget af defekt hardware eller defekt infrastruktur - mistede netværkspakker, brat afbrudte forbindelser eller uventet høj CPU-udnyttelse. Når du har adgang til din MySQL-vært, kan du udnytte masser af værktøjer, der hjælper dig med at diagnosticere en Linux-servers tilstand. Når du bruger RDS, er du begrænset til, hvilke metrics der er tilgængelige i Cloudwatch, Amazons overvågnings- og trendværktøj. Enhver mere detaljeret diagnose kræver, at du kontakter support og beder dem om at kontrollere og løse problemet. Dette kan være hurtigt, men det kan også være en meget lang proces med en masse frem og tilbage e-mail-kommunikation.
Leverandørlåsning forårsaget af kompleks og tidskrævende proces med at få data ud af MySQL RDS. RDS giver ikke adgang til MySQL-databiblioteket, så der er ingen måde at bruge industristandardværktøjer som xtrabackup til at flytte data på en binær måde. På den anden side er RDS under motorhjelmen en MySQL, der vedligeholdes af Amazon, det er svært at sige, om den er 100% kompatibel med upstream eller ej. RDS er kun tilgængelig på AWS, så du ville ikke være i stand til at lave en hybrid opsætning.
Oversigt
MySQL RDS har både styrker og svagheder. Dette er et meget godt værktøj for dem, der gerne vil fokusere på applikationen uden at skulle bekymre sig om at betjene databasen. Du implementerer en database og begynder at udstede forespørgsler. Intet behov for at bygge backup-scripts eller opsætte overvågningsløsning, fordi det allerede er udført af AWS-ingeniører - alt du skal gøre er at bruge det.
Der er også en mørk side af MySQL RDS. Mangel på muligheder for at bygge mere komplekse opsætninger og skalering uden for blot at tilføje flere slaver. Manglende støtte til bedre høj tilgængelighed end det, der foreslås under multi-AZ-implementeringer. Besværlig adgang til MySQL-logfiler. Manglende direkte adgang til MySQL-databiblioteket og manglende understøttelse af fysiske sikkerhedskopier, hvilket gør det svært at flytte dataene ud af RDS-instansen.
For at opsummere det, kan RDS fungere fint for dig, hvis du værdsætter brugervenlighed frem for detaljeret kontrol af databasen. Du skal huske på, at du på et tidspunkt i fremtiden kan vokse ud af MySQL RDS. Vi taler her ikke nødvendigvis kun om ydeevne. Det handler mere om din organisations behov for mere kompleks replikeringstopologi eller et behov for at have bedre indsigt i databaseoperationer for hurtigt at kunne håndtere forskellige problemer, der opstår fra tid til anden. I så fald, hvis dit datasæt allerede er vokset i størrelse, kan du finde det vanskeligt at flytte ud af RDS. Inden der træffes nogen beslutning om at flytte dine data til RDS, skal informationsansvarlige overveje deres organisations krav og begrænsninger på specifikke områder.
I de næste par blogindlæg viser vi dig, hvordan du tager dine data ud af RDS'en til en separat placering. Vi vil diskutere både migrering til EC2 og til lokal infrastruktur.