I det forrige indlæg diskuterede vi, hvordan man verificerer, at MySQL-replikering er i god form. Vi så også på nogle af de typiske problemer. I dette indlæg vil vi se på nogle flere problemer, som du kan se, når du beskæftiger dig med MySQL-replikering.
Manglende eller duplikerede poster
Dette er noget, der ikke bør ske, men alligevel sker det meget ofte - en situation, hvor en SQL-sætning, der udføres på masteren, lykkes, men den samme sætning, der udføres på en af slaverne, mislykkes. Hovedårsagen er slavedrift - noget (normalt fejlagtige transaktioner, men også andre problemer eller fejl i replikationen) får slaven til at adskille sig fra sin master. For eksempel eksisterer en række, som eksisterede på masteren, ikke på en slave, og den kan ikke slettes eller opdateres. Hvor ofte dette problem dukker op, afhænger for det meste af dine replikeringsindstillinger. Kort sagt er der tre måder, hvorpå MySQL gemmer binære loghændelser. For det første betyder "statement", at SQL er skrevet i almindelig tekst, ligesom det er blevet udført på en master. Denne indstilling har den højeste tolerance på slavedrift, men det er også den, der ikke kan garantere slavekonsistens - det er svært at anbefale at bruge det i produktionen. Andet format, "række", gemmer forespørgselsresultatet i stedet for forespørgselssætning. For eksempel kan en begivenhed se ud som nedenfor:
### OPDATERING `test`.`tab`### WHERE### @1=2### @2=5### SET### @1=2### @ 2=4 Det betyder, at vi opdaterer en række i 'tab'-tabellen i 'test'-skemaet, hvor første kolonne har værdien 2 og anden kolonne har værdien 5. Vi sætter første kolonne til 2 (værdien ændres ikke) og anden kolonne kolonne til 4. Som du kan se, er der ikke meget plads til fortolkning - det er præcist defineret, hvilken række der bruges, og hvordan den ændres. Som et resultat er dette format fantastisk til slavekonsistens, men som du kan forestille dig, er det meget sårbart, når det kommer til datadrift. Det er stadig den anbefalede måde at køre MySQL-replikering på.
Endelig fungerer den tredje, "blandet", på en måde, så de begivenheder, der er sikre at skrive i form af udsagn, bruger "statement"-format. De, der kan forårsage datadrift, vil bruge "række"-format.
Hvordan opdager du dem?
Som sædvanlig vil VIS SLAVE STATUS hjælpe os med at identificere problemet.
Last_SQL_Errno:1032 Last_SQL_Error:Kunne ikke udføre Update_rows-hændelsen på tabel test.tab; Kan ikke finde post i 'faneblad', Error_code:1032; handler fejl HA_ERR_KEY_NOT_FOUND; hændelsens masterlog binlog.000021, end_log_pos 970 Last_SQL_Errno:1062 Last_SQL_Error:Kunne ikke udføre Write_rows-begivenheden på tabel test.tab; Dublet indtastning '3' for nøgle 'PRIMARY', fejlkode:1062; handler fejl HA_ERR_FOUND_DUPP_KEY; hændelsens masterlog binlog.000021, end_log_pos 1229 Som du kan se, er fejl tydelige og selvforklarende (og de er grundlæggende identiske mellem MySQL og MariaDB.
Hvordan løser du problemet?
Dette er desværre den komplekse del. Først og fremmest skal du identificere en kilde til sandhed. Hvilken vært indeholder de korrekte data? Mester eller slave? Normalt vil du antage, at det er mesteren, men antager det ikke som standard - undersøg! Det kunne være, at en del af applikationen efter failover stadig udstedte skriverier til den gamle mester, som nu fungerer som en slave. Det kan være, at read_only ikke er blevet indstillet korrekt på den vært, eller måske bruger applikationen superbruger til at oprette forbindelse til databasen (ja, vi har set dette i produktionsmiljøer). I et sådant tilfælde kunne slaven være kilden til sandheden - i hvert fald til en vis grad.
Afhængigt af hvilke data der skal forblive, og hvilke der skal gå, ville den bedste fremgangsmåde være at identificere, hvad der er nødvendigt for at få replikering tilbage i synkronisering. Først og fremmest er replikering brudt, så du skal passe på dette. Log ind på masteren og tjek den binære log, selv det der fik replikeringen til at bryde.
Retrieved_Gtid_Set:5d1e2227-07c6-11e7-8123-080027495a77:1106672 Executed_Gtid_Set:5d1e2227-07c6-11e7-80127-80127-40127-40127-code:a Som du kan se, savner vi én begivenhed:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Lad os tjekke det i masterens binære logfiler:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021#170320 170320 1_65 1_65 id:3_65 1_65id CRC32 0xc582a367 GTID last_committed=3 sequence_number=4SET @@SESSION.GTID_NEXT='5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*1106672'/*1106672'/*1106672'/*1106672'/* 1*36# 7. 1*30#:1. 02# server:7 1*36#; 0x6f33754d Forespørgsel thread_id=5285 exec_time=0 error_code=0SET TIMESTAMP=1490043217/*!*/;SET @@session.pseudo_thread_id=5285/*!*/;SET @@session.foreign_key@0session=1, @null_key_autosession=1, @null=, @@session.unique_checks=1, @@session.autocommit=1/*!*/;SET @@session.sql_mode=1436549152/*!*/;SET @@session.auto_increment_increment=1, @@session.auto_increment_offset =1/*!*/;/*!\C utf8 *//*!*/;SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!* /;SET @@session.lc_time_names=0/*!*/;SET @@session.collation_database=DEFAULT/*!*/;BEGIN/*!*/;# på 1138#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map:`test`.`tab` mapped to number 571# at 1185#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows:table id 571 flags:STMT_END_FBINLOG 'UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC// wDAAAABwAAAArll1U='/*!*/;### INDSÆT I `test`.`tab`### SET### @1=3### @2=7# på 1229#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid =5224257COMMIT/*!*/; Vi kan se, at det var en indsættelse, der sætter første kolonne til 3 og anden til 7. Lad os kontrollere, hvordan vores tabel ser ud nu:
mysql> VÆLG * FRA test.tab;+----+------+| id | b |+----+------+| 1 | 2 || 2 | 4 || 3 | 10 |+----+------+3 rækker i sæt (0,01 sek.) Nu har vi to muligheder, alt efter hvilke data der skal være gældende. Hvis korrekte data er på masteren, kan vi blot slette række med id=3 på slaven. Bare sørg for at deaktivere binær logning for at undgå at introducere fejlagtige transaktioner. På den anden side, hvis vi besluttede, at de korrekte data er på slaven, skal vi køre REPLACE-kommandoen på masteren for at indstille rækken med id=3 til at rette indholdet af (3, 10) fra nuværende (3, 7). På slaven bliver vi dog nødt til at springe det aktuelle GTID over (eller, for at være mere præcis, bliver vi nødt til at oprette en tom GTID-hændelse) for at kunne genstarte replikering.
Det er enkelt at slette en række på en slave:
INDSTIL SESSION log_bin=0; SLET FRA test.tab WHERE id=3; SET SESSION log_bin=1; At indsætte et tomt GTID er næsten lige så enkelt:
mysql> SET @@SESSION.GTID_NEXT='5d1e2227-07c6-11e7-8123-080027495a77:1106672';Forespørgsel OK, 0 rækker påvirket (0,00 sek.) mysql> BEGIN;Forespørgsel OK, 0 rækker påvirket (0,00 sek.) mysql> COMMIT;Forespørgsel OK, 0 rækker påvirket (0,00 sek.) mysql> SET @@SESSION.GTID_NEXT=automatic;Forespørgsel OK, 0 rækker påvirket (0,00 sek.) En anden metode til at løse dette særlige problem (så længe vi accepterer masteren som en kilde til sandhed) er at bruge værktøjer som pt-table-checksum og pt-table-sync til at identificere, hvor slaven ikke er i overensstemmelse med sin master, og hvad SQL skal udføres på masteren for at bringe slaven tilbage i synkronisering. Desværre er denne metode temmelig på den tunge side - masser af belastning tilføjes til master, og en masse forespørgsler bliver skrevet ind i replikeringsstrømmen, hvilket kan påvirke forsinkelser på slaver og den generelle ydeevne af replikeringsopsætningen. Dette gælder især, hvis der er et betydeligt antal rækker, der skal synkroniseres.
Endelig kan du som altid genopbygge din slave ved hjælp af data fra masteren - på den måde kan du være sikker på, at slaven bliver opdateret med de nyeste, opdaterede data. Dette er faktisk ikke nødvendigvis en dårlig idé - når vi taler om et stort antal rækker, der skal synkroniseres ved hjælp af pt-table-checksum/pt-table-sync, kommer dette med betydelig overhead i replikeringsydelse, samlet CPU og I/O belastning og mandetimer påkrævet.
ClusterControl giver dig mulighed for at genopbygge en slave ved at bruge en ny kopi af masterdataene.
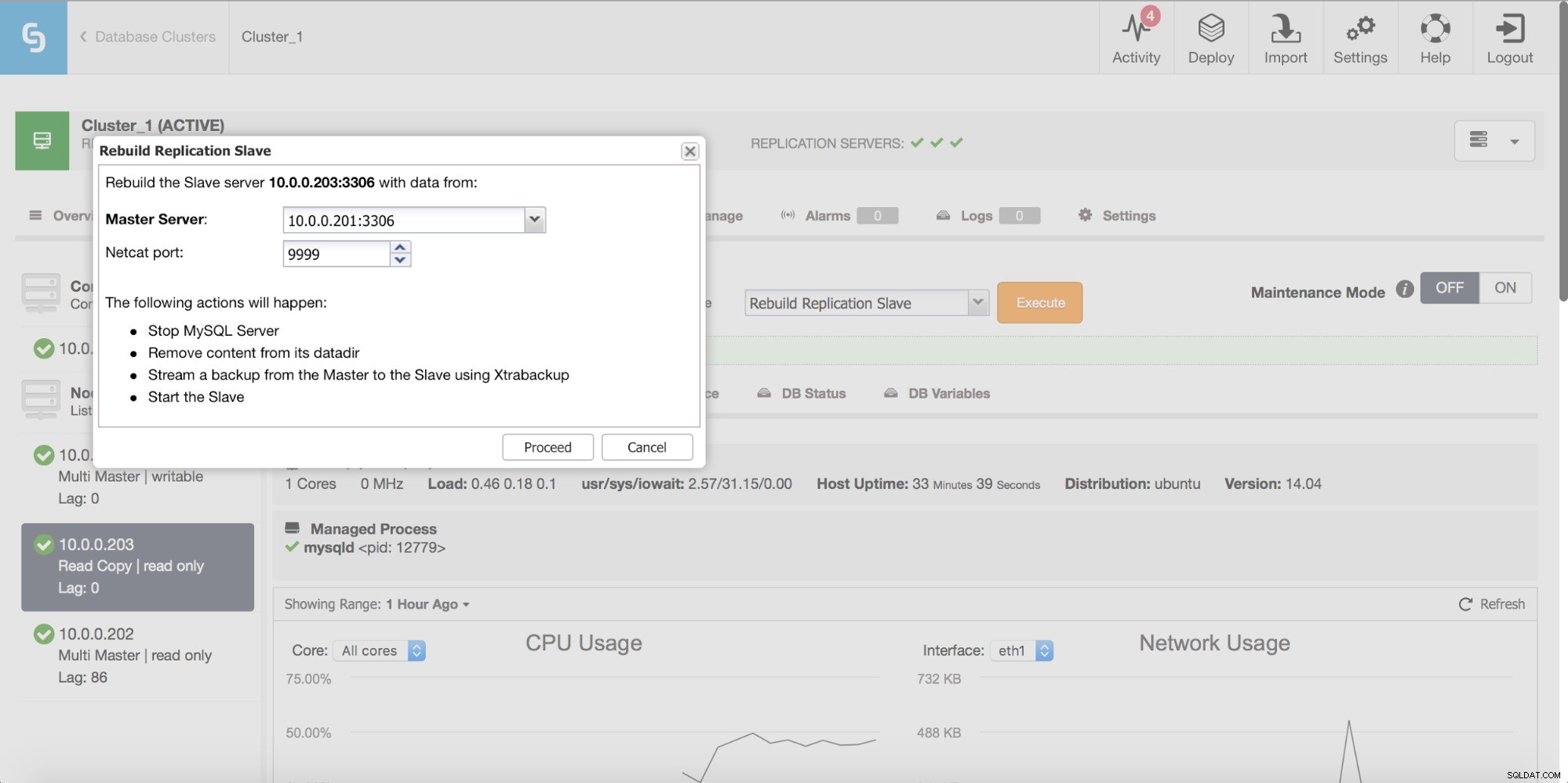
Konsistenstjek
Som vi nævnte i det foregående kapitel, kan konsistens blive et alvorligt problem og kan forårsage en masse hovedpine for brugere, der kører MySQL-replikeringsopsætninger. Lad os se, hvordan du kan verificere, at dine MySQL-slaver er synkroniserede med masteren, og hvad du kan gøre ved det.
Sådan registreres en inkonsekvent slave
Desværre er den typiske måde, en bruger får at vide, at en slave er inkonsekvent på, ved at løbe ind i et af de problemer, vi nævnte i det foregående kapitel. For at undgå at proaktiv overvågning af slavekonsistens er påkrævet. Lad os tjekke, hvordan det kan gøres.
Vi skal bruge et værktøj fra Percona Toolkit:pt-table-checksum. Den er designet til at scanne replikeringsklynge og identificere eventuelle uoverensstemmelser.
Vi byggede et brugerdefineret scenarie ved hjælp af sysbench, og vi introducerede en smule inkonsekvens på en af slaverne. Hvad der er vigtigt (hvis du gerne vil teste det som vi gjorde), skal du anvende en patch nedenfor for at tvinge pt-table-checksum til at genkende 'sbtest'-skemaet som ikke-systemskema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000+++ pt-table-checksum-fix 2017-03-21 20:32:53.2822500094@ +0000+++ -7614,7 +7614,7 @@ mit $filter =$selv->{filtre};- if ( $db =~ m/information_skema|performance_schema|lost\+found|percona|percona_schema|test/ ) {+ if ( $db =~ m/information_skema|performance_schema|lost\+found|percona|percona_schema|^test/ ) { PTDEBUG &&_d('Database', $db, 'er en systemdatabase, ignorerer'); returner 0; }
Først skal vi udføre pt-table-checksum på følgende måde:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest' TS-fejl diffs rækker bidder sprunget over tid Tabel03-21T20:33:30 0 0 1000000 15 0 27.103 SBTEST.SBTEST103-21T20:33:57 0 1 1000000 17 0 26.785 SBTEST.SBTEST203-21T20:34:26 0 1000000 15 0 28.503 SBTEST.SBTEST303-21T20:34:52 0 0 1000000 18 0 26.021 SBTEST.SBTEST403-21T20:35:34 0 0 1000000 17 0 42.730 SBTEST.SBTEST503-21T20:36:04 0 0 1000000 16 0 29.309 SBTEST.SBT603-21T20 :36:42 0 0 1000000 15 0 38.071 sbtest.sbtest703-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8
Et par vigtige bemærkninger om, hvordan vi påberåbte værktøjet. Først og fremmest skal den bruger, vi indstiller, eksistere på alle slaver. Hvis du vil, kan du også bruge '--slave-bruger' til at definere andre, mindre privilegerede brugere til at få adgang til slaver. En anden ting, der er værd at forklare - vi bruger rækkebaseret replikering, som ikke er fuldt ud kompatibel med pt-table-checksum. Hvis du har rækkebaseret replikering, er det, der sker, at pt-table-checksum vil ændre binært logformat på sessionsniveau til 'statement', da dette er det eneste understøttede format. Problemet er, at en sådan ændring kun vil fungere på et første niveau af slaver, som er direkte forbundet med en master. Hvis du har mellemliggende mastere (altså mere end ét niveau af slaver), kan brug af pt-table-checksum bryde replikationen. Det er derfor, som standard, hvis værktøjet registrerer rækkebaseret replikering, afsluttes det og udskriver fejl:
"Replika slave1 har binlog_format ROW, som kan få pt-table-checksum til at bryde replikering. Læs venligst "Replikaer, der bruger rækkebaseret replikering" i afsnittet BEGRÆNSNINGER i værktøjets dokumentation. Hvis du forstår risiciene, så specificer --no-check-binlog-format for at deaktivere denne kontrol."
Vi brugte kun ét niveau af slaver, så det var sikkert at angive "--no-check-binlog-format" og gå videre.
Til sidst sætter vi maksimal forsinkelse til 5 sekunder. Hvis denne tærskel nås, vil pt-table-checksum holde pause i den nødvendige tid for at bringe forsinkelsen under tærsklen.
Som du kunne se fra outputtet,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
en inkonsekvens er blevet opdaget i tabellen sbtest.sbtest2.
Som standard gemmer pt-table-checksum kontrolsummer i tabellen percona.checksums. Disse data kan bruges til et andet værktøj fra Percona Toolkit, pt-table-sync, for at identificere, hvilke dele af tabellen der skal kontrolleres i detaljer for at finde den nøjagtige forskel i data.
Sådan rettes inkonsistent slave
Som nævnt ovenfor vil vi bruge pt-table-sync til at gøre det. I vores tilfælde vil vi bruge data indsamlet af pt-table-checksum, selvom det også er muligt at pege pt-table-sync til to værter (masteren og en slave), og det vil sammenligne alle data på begge værter. Det er bestemt mere tids- og ressourcekrævende proces, så længe du allerede har data fra pt-table-checksum, er det meget bedre at bruge det. Sådan udførte vi det for at teste outputtet:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --print
REPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-128875447709-74147709-74247709-74247709-361427 -86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=... ,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaktion:1 changing_src:percona.checksums replicate:percona.checksums tovejs:0 pid:25776 bruger :root vært:vagrant-ubuntu-trusty-64*/;
Som du kan se, er der som følge heraf blevet genereret noget SQL. Vigtigt at bemærke er --replicate variabel. Hvad der sker her er, at vi peger pt-table-sync til tabel genereret af pt-table-checksum. Vi peger også på master.
For at kontrollere, om SQL giver mening, brugte vi --print option. Bemærk venligst, at den genererede SQL kun er gyldig på det tidspunkt, den genereres - du kan ikke rigtig gemme den et sted, gennemgå den og derefter udføre. Alt du kan gøre er at kontrollere, om SQL'en giver mening, og umiddelbart efter genudføre værktøjet med --execute flag:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --execute
Dette skulle gøre slave tilbage i sync med masteren. Vi kan verificere det med pt-table-checksum:
eksempel@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases ='sbtest' TS FEJL FORSKELLIGE RÆKKER KUNDER OVERSPRUDT TIDSTABEL03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest103-21T21:36:26 00 020 s:020s 3:020 3s:020 3s:020 s:3b 3:020 3 1000000 10 0 24.780 SBTEST.SBTEST303-21T21:37:11 0 0 1000000 14 0 19.782 SBTEST.SBTEST403-21T21:37:42 0 0 1000000 15 0 30.954 SBTEST.SBTEST503-21T21:38:07 0 100000000 15 0 25.593 SBTEST .sbtest603-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest703-21T21:38:44 0 0 1000000 15 0 17.371 test sbtests.
Som du kan se, er der ingen forskelle længere i tabellen sbtest.sbtest2.
Vi håber, du fandt dette blogindlæg informativt og nyttigt. Klik her for at lære mere om MySQL-replikering. Hvis du har spørgsmål eller forslag, er du velkommen til at kontakte os via kommentarerne nedenfor.