
Den typiske MySQL DBA kan være bekendt at arbejde og administrere en OLTP-database (Online Transaction Processing) som en del af deres daglige rutine. Du er måske bekendt med, hvordan det fungerer, og hvordan man håndterer komplekse operationer. Selvom standardlagringsmotoren, som MySQL leverer, er god nok til OLAP (Online Analytical Processing), er den ret forenklet, især dem, der gerne vil lære kunstig intelligens, eller som beskæftiger sig med prognoser, datamining, dataanalyse.
I denne blog skal vi diskutere MariaDB ColumnStore. Indholdet vil blive skræddersyet til fordel for MySQL DBA, som måske har mindre forståelse for ColumnStore, og hvordan det kan være anvendeligt til OLAP (Online Analytical Processing) applikationer.
OLTP vs. OLAP
OLTP
Relaterede ressourcer Analytics med MariaDB AX - Open Source Columnar Datastore En introduktion til tidsseriedatabaser Hybrid OLTP/Analytics Database Workloads in Galera Cluster Using Asynchronous SlavesDen typiske MySQL DBA-aktivitet til håndtering af denne type data er ved at bruge OLTP (Online Transaction Processing). OLTP er karakteriseret ved store databasetransaktioner, der foretager indsættelser, opdateringer eller sletninger. OLTP-typen af databaser er specialiserede til hurtig forespørgselsbehandling og opretholdelse af dataintegritet, mens de er tilgået i flere miljøer. Dens effektivitet måles ved antallet af transaktioner pr. sekund (tps). Det er ret almindeligt, at forældre-barn relationstabellerne (efter implementering af normaliseringsformularen) reducerer overflødige data i en tabel.
Optegnelser i en tabel behandles og gemmes sædvanligvis sekventielt på en rækkeorienteret måde og er meget indekseret med unikke nøgler for at optimere datahentning eller -skrivning. Dette er også almindeligt for MySQL, især når det drejer sig om store inserts eller høje samtidige skrivninger eller bulk inserts. De fleste lagringsmotorer, som MariaDB understøtter, er anvendelige til OLTP-applikationer - InnoDB (standardlagringsmotoren siden 10.2), XtraDB, TokuDB, MyRocks eller MyISAM/Aria.
Applikationer som CMS, FinTech, Web Apps håndterer ofte tunge skrivninger og læsninger og kræver ofte høj gennemstrømning. For at få disse applikationer til at fungere kræver det ofte dyb ekspertise inden for høj tilgængelighed, redundans, robusthed og gendannelse.
OLAP
OLAP håndterer de samme udfordringer som OLTP, men bruger en anden tilgang (især når det drejer sig om datahentning). OLAP beskæftiger sig med større datasæt og er fælles for data warehousing, ofte brugt til applikationer af typen business intelligence. Det bruges almindeligvis til Business Performance Management, Planlægning, Budgettering, Forecasting, Financial Reporting, Analysis, Simulation Models, Knowledge Discovery og Data Warehouse Reporting.
Data, der er gemt i OLAP, er typisk ikke så kritiske som dem, der er gemt i OLTP. Dette skyldes, at de fleste data kan simuleres, der kommer fra OLTP og derefter kan føres til din OLAP-database. Disse data bruges typisk til masseindlæsning, der ofte er nødvendige for forretningsanalyse, som til sidst gengives til visuelle grafer. OLAP udfører også multidimensionel analyse af forretningsdata og leverer resultater, som kan bruges til komplekse beregninger, trendanalyser eller sofistikeret datamodellering.
OLAP gemmer normalt data vedvarende ved hjælp af et søjleformat. I MariaDB ColumnStore er posterne dog opdelt baseret på dens kolonner og gemmes separat i en fil. På denne måde er datahentning meget effektiv, da den kun scanner den relevante kolonne, der henvises til i din SELECT-sætningsforespørgsel.
Tænk på det sådan her, OLTP-behandling håndterer dine daglige og afgørende datatransaktioner, der kører din virksomhedsapplikation, mens OLAP hjælper dig med at administrere, forudsige, analysere og bedre markedsføre dit produkt - byggestenene i at have en forretningsapplikation.
Hvad er MariaDB ColumnStore?
MariaDB ColumnStore er en pluggbar søjleformet lagermotor, der kører på MariaDB Server. Den bruger en parallel distribueret dataarkitektur, mens den bevarer den samme ANSI SQL-grænseflade, som bruges på tværs af MariaDB-serverporteføljen. Denne lagringsmotor har eksisteret i et stykke tid, da den oprindeligt blev porteret fra InfiniDB (en nu nedlagt kode, som stadig er tilgængelig på github.) Den er designet til big data-skalering (til at behandle petabytes af data), lineær skalerbarhed og reel - tidssvar på analyseforespørgsler. Det udnytter I/O-fordelene ved søjleopbevaring; komprimering, just-in-time projektion og vandret og lodret partitionering for at levere en enorm ydeevne, når der analyseres store datasæt.
Endelig er MariaDB ColumnStore rygraden i deres MariaDB AX-produkt som den vigtigste lagermotor, der bruges af denne teknologi.
Hvordan er MariaDB ColumnStore anderledes end InnoDB?
InnoDB er anvendelig til OLTP-behandling, der kræver, at din ansøgning reagerer hurtigst muligt. Det er nyttigt, hvis din ansøgning omhandler den slags. På den anden side er MariaDB ColumnStore et velegnet valg til styring af big data-transaktioner eller store datasæt, der involverer komplekse sammenføjninger, aggregering på forskellige niveauer af dimensionshierarki, projektering af en finansiel total i en lang række år eller brug af lighed og rækkeviddevalg . Disse tilgange ved hjælp af ColumnStore kræver ikke, at du indekserer disse felter, da det kan fungere tilstrækkeligt hurtigere. InnoDB kan ikke rigtigt håndtere denne type ydeevne, selvom der ikke er nogen der forhindrer dig i at prøve det, som det er muligt med InnoDB, men til en pris. Dette kræver, at du tilføjer indekser, som tilføjer store mængder data til dit disklager. Det betyder, at det kan tage længere tid at afslutte din forespørgsel, og at den måske slet ikke bliver færdig, hvis den er fanget i en tidsløkke.
MariaDB ColumnStore-arkitektur
Lad os se på MariaDB ColumStore-arkitekturen nedenfor:
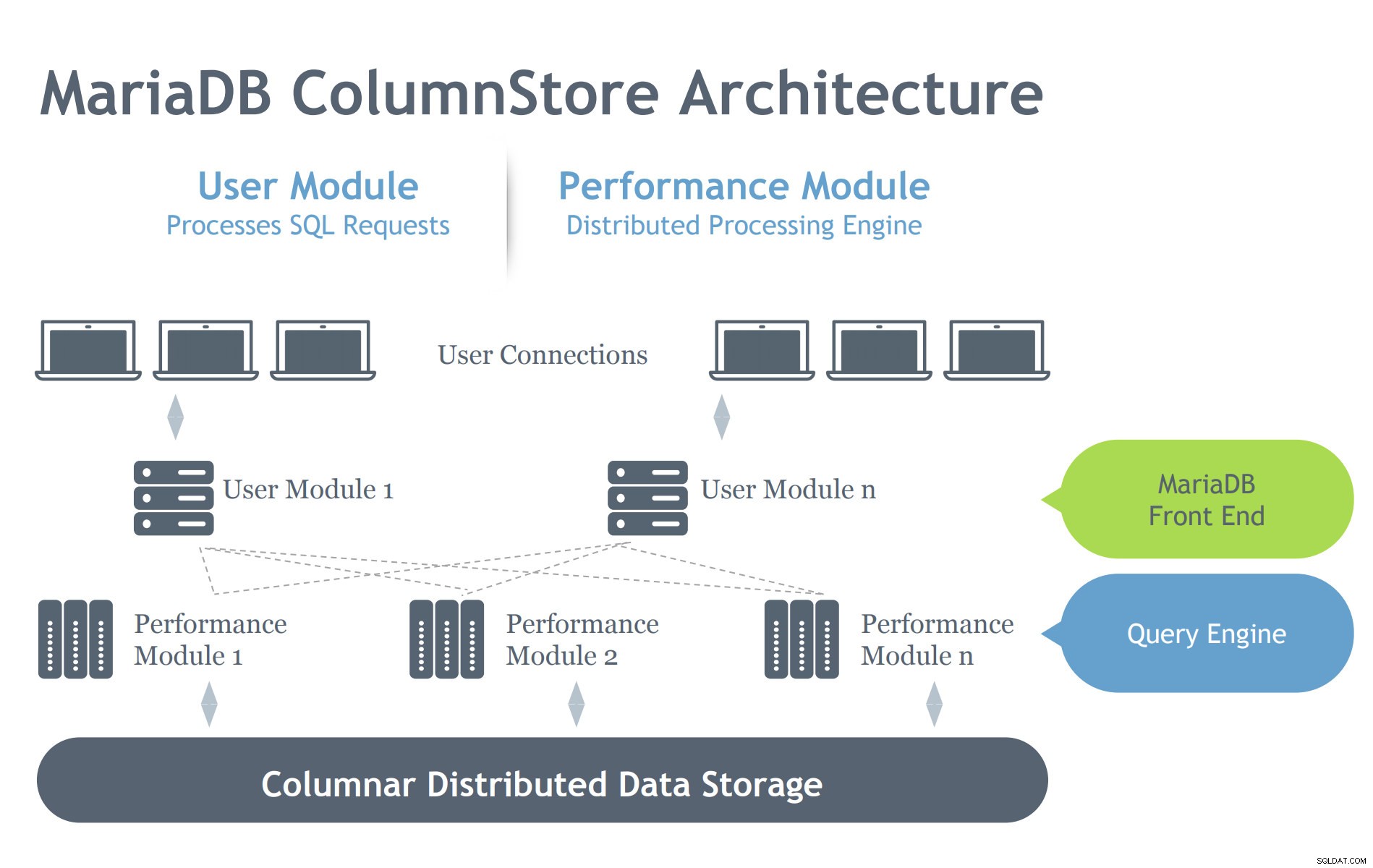 Billede med tilladelse fra MariaDB ColumnStore-præsentation
Billede med tilladelse fra MariaDB ColumnStore-præsentation I modsætning til InnoDB-arkitekturen indeholder ColumnStore to moduler, som angiver, at dens hensigt er at arbejde effektivt på et distribueret arkitektonisk miljø. InnoDB er beregnet til at skalere på en server, men spænder over flere sammenkoblede noder afhængigt af en klyngeopsætning. Derfor har ColumnStore flere niveauer af komponenter, som tager sig af de processer, der anmodes om til MariaDB-serveren. Lad os grave på disse komponenter nedenfor:
- Brugermodul (UM):UM er ansvarlig for at parse SQL-anmodningerne til et optimeret sæt primitive jobtrin, der udføres af en eller flere PM-servere. UM er således ansvarlig for forespørgselsoptimering og orkestrering af forespørgselsudførelse af PM-serverne. Mens flere UM-instanser kan implementeres i en multi-server-implementering, er en enkelt UM ansvarlig for hver enkelt forespørgsel. En databasebelastningsbalancer, som MariaDB MaxScale, kan implementeres for at afbalancere eksterne anmodninger korrekt mod individuelle UM-servere.
- Performance Module (PM):PM'en udfører granulære jobtrin modtaget fra en UM på en flertrådet måde. ColumnStore tillader fordeling af arbejde på tværs af mange præstationsmoduler. UM er sammensat af MariaDB mysqld-processen og ExeMgr-processen.
- Extent Maps:ColumnStore vedligeholder metadata om hver kolonne i et delt distribueret objekt kendt som Extent Map UM-serveren refererer til Extent Map for at hjælpe med at generere de korrekte primitive jobtrin. PM-serveren refererer til Extent Map for at identificere de korrekte diskblokke, der skal læses. Hver kolonne består af en eller flere filer, og hver fil kan indeholde flere omfang. Så meget som muligt forsøger systemet at allokere sammenhængende fysisk lager for at forbedre læseydelsen.
- Lagring:ColumnStore kan bruge enten lokal lagring eller delt lagring (f.eks. SAN eller EBS) til at gemme data. Brug af delt lagring giver mulighed for, at databehandling mislykkes automatisk til en anden node i tilfælde af, at en PM-server svigter.
Nedenfor er hvordan MariaDB ColumnStore behandler forespørgslen,
- Kunder udsteder en forespørgsel til MariaDB-serveren, der kører på brugermodulet. Serveren udfører en tabeloperation for alle tabeller, der er nødvendige for at opfylde anmodningen og henter den indledende forespørgselsudførelsesplan.
- Ved brug af MariaDB-lagringsmotorgrænsefladen konverterer ColumnStore servertabelobjektet til ColumnStore-objekter. Disse objekter sendes derefter til brugermodulets processer.
- Brugermodulet konverterer MariaDB-udførelsesplanen og optimerer de givne objekter til en ColumnStore-udførelsesplan. Den bestemmer derefter de nødvendige trin for at køre forespørgslen og den rækkefølge, de skal køres i.
- Brugermodulet konsulterer derefter udvidelseskortet for at bestemme, hvilke ydeevnemoduler, der skal konsulteres for de data, det har brug for, det udfører derefter omfangseliminering, og eliminerer alle ydeevnemoduler fra listen, der kun indeholder data uden for rækkevidden af, hvad forespørgslen kræver.
- Brugermodulet sender derefter kommandoer til et eller flere ydeevnemoduler for at udføre blok I/O-operationer.
- Performancemodulet eller -modulerne udfører prædikatfiltrering, join-behandling, indledende aggregering af data fra lokalt eller eksternt lager, og sender derefter dataene tilbage til brugermodulet.
- Brugermodulet udfører den endelige aggregering af resultatsæt og sammensætter resultatsættet for forespørgslen.
- Brugermodulet / ExeMgr implementerer alle vinduesfunktionsberegninger såvel som enhver nødvendig sortering på resultatsættet. Det returnerer derefter resultatsættet til serveren.
- MariaDB-serveren udfører alle udvalgte listefunktioner, ORDER BY og LIMIT operationer på resultatsættet.
- MariaDB-serveren returnerer resultatsættet til klienten.
Forespørgselsudførelsesparadigmer
Lad os grave lidt mere, hvordan ColumnStore udfører forespørgslen, og hvornår den påvirker.
ColumnStore adskiller sig fra standard MySQL/MariaDB-lagringsmotorer såsom InnoDB, da ColumnStore opnår ydeevne ved kun at scanne nødvendige kolonner, bruge systemvedligeholdt partitionering og bruge flere tråde og servere til at skalere forespørgselssvarstid. Ydeevne er fordelagtigt, når du kun inkluderer kolonner, der er nødvendige for din datahentning. Det betyder, at den grådige stjerne (*) i din udvalgte forespørgsel har betydelig indflydelse sammenlignet med en SELECT
Samme som med InnoDB og andre lagringsmotorer har datatype også betydning for ydeevnen på det, du brugte. Hvis du siger, at du har en kolonne, der kun kan have værdierne 0 til 100, så erklær dette som en tinyint, da dette vil blive repræsenteret med 1 byte i stedet for 4 bytes for int. Dette vil reducere I/O-omkostningerne med 4 gange. For strengtyper er en vigtig tærskel char(9) og varchar(8) eller højere. Hver kolonnelagerfil bruger et fast antal bytes pr. værdi. Dette muliggør hurtigt positionsopslag af andre kolonner for at danne rækken. I øjeblikket er den øvre grænse for søjleformet datalagring 8 bytes. Så for strenge længere end dette opretholder systemet en ekstra 'ordbog'-udstrækning, hvor værdierne er gemt. Den søjleformede udstrækningsfil gemmer derefter en pointer i ordbogen. Så det er dyrere at læse og behandle en varchar(8) kolonne end en char(8) kolonne for eksempel. Så hvor det er muligt vil du få bedre ydeevne, hvis du kan bruge kortere strenge, især hvis du undgår ordbogsopslag. Alle TEKST/BLOB-datatyper i 1.1 og fremefter bruger en ordbog og laver et multiple blok 8KB opslag for at hente disse data, hvis det kræves, jo længere data er, jo flere blokke hentes og jo større er en potentiel effekt på ydeevnen.
I et rækkebaseret system øger tilføjelse af redundante kolonner de samlede forespørgselsomkostninger, men i et søjlebaseret system opstår en omkostning kun, hvis der henvises til kolonnen. Derfor bør der oprettes yderligere kolonner for at understøtte forskellige adgangsstier. Gem f.eks. en førende del af et felt i én kolonne for at give mulighed for hurtigere opslag, men for at gemme den lange formværdi som en anden kolonne. Scanninger på en kortere kode eller indledende delkolonne vil være hurtigere.
Forespørgselssammenføjninger er optimeret-klar til sammenkædninger i stor skala og undgår behovet for indekser og overhead af indlejret sløjfebehandling. ColumnStore vedligeholder tabelstatistik for at bestemme den optimale joinrækkefølge. Lignende tilgange deles med InnoDB som f.eks. hvis joinforbindelsen er for stor til UM-hukommelsen, bruger den diskbaseret join til at gøre forespørgslen fuldført.
For aggregeringer distribuerer ColumnStore aggregeret evaluering så meget som muligt. Dette betyder, at det deler på tværs af UM og PM for at håndtere forespørgsler, især eller meget store antal værdier i den/de samlede kolonne(r). Select count(*) er internt optimeret til at vælge det mindste antal bytes lager i en tabel. Dette betyder, at den ville vælge CHAR(1)-kolonnen (bruger 1 byte) over den INT-kolonne, som tager 4 bytes. Implementeringen respekterer stadig ANSI-semantikken ved, at udvalgt antal(*) vil inkludere nuller i det samlede antal i modsætning til en eksplicit udvælgelse(COL-N), som udelukker nulværdier i optællingen.
Ordre efter og grænse er i øjeblikket implementeret til allersidst af mariadb-serverprocessen på den midlertidige resultatsættabel. Dette er blevet nævnt i trin #9 om, hvordan ColumnStore behandler forespørgslen. Så teknisk set sendes resultaterne til MariaDB Server for at sortere dataene.
For komplekse forespørgsler, der bruger underforespørgsler, er det grundlæggende den samme tilgang, hvor de udføres i rækkefølge og administreres af UM, det samme som med Window-funktioner, der håndteres af UM, men det bruger en dedikeret hurtigere sorteringsproces, så det er dybest set hurtigere.
Partitionering af dine data leveres af ColumnStore, som den bruger Extent Maps, som opretholder min/maks-værdierne for kolonnedata og giver et logisk område til partitionering og fjerner behovet for indeksering. Extent Maps giver også manuel tabelopdeling, materialiserede visninger, oversigtstabeller og andre strukturer og objekter, som rækkebaserede databaser skal implementere for forespørgselsydeevne. Der er visse fordele ved kolonneværdier, når de er i rækkefølge eller semi-rækkefølge, da dette giver mulighed for meget effektiv dataopdeling. Med min- og max-værdier vil hele udstrækningskort efter filteret og ekskluderingen blive elimineret. Se denne side i deres manual om Extent Elimination. Dette fungerer generelt særligt godt for tidsseriedata eller lignende værdier, der stiger over tid.
Installation af MariaDB ColumnStore
Installation af MariaDB ColumnStore kan være enkel og ligetil. MariaDB har en række noter her, som du kan henvise til. For denne blog er vores installationsmålmiljø CentOS 7. Du kan gå til dette link https://downloads.mariadb.com/ColumnStore/1.2.4/ og tjekke pakkerne baseret på dit OS-miljø. Se de detaljerede trin nedenfor for at hjælpe dig med at fremskynde:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Når du er færdig, skal du køre postConfigure kommando for endelig at installere og konfigurere din MariaDB ColumnStore. I denne eksempelinstallation er der to noder, jeg har konfigureret på vagrant-maskine:
csnode1:192.168.2.10
csnode2:192.168.2.20
Begge disse noder er defineret i deres respektive /etc/hosts, og begge noder er målrettet er indstillet til at have sine bruger- og ydeevnemoduler kombineret i begge værter. Installationen er en lille smule triviel i starten. Derfor deler vi, hvordan du kan konfigurere det, så du kan have et grundlag. Se detaljerne nedenfor for eksempel på installationsprocessen:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Når installationen og opsætningen er færdig, vil MariaDB oprette en master/slave-opsætning til dette, så uanset hvad vi har indlæst fra csnode1, vil det blive replikeret til csnode2.
Dumper dine Big Data
Efter din installation har du muligvis ingen prøvedata at prøve. IMDB har delt et eksempel på data, som du kan downloade på deres websted https://www.imdb.com/interfaces/. Til denne blog har jeg lavet et script, som gør alt for dig. Tjek det ud her https://github.com/paulnamuag/columnstore-imdb-data-load. Bare gør det eksekverbart, og kør derefter scriptet. Det vil gøre alt for dig ved at downloade filerne, oprette skemaet og derefter indlæse data til databasen. Så enkelt er det.
Kørsel af dine prøveforespørgsler
Lad os nu prøve at køre nogle eksempelforespørgsler.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Dybest set er det hurtigere og hurtigt. Der er forespørgsler, som du ikke kan behandle det samme, som du kører med andre storage-motorer, såsom InnoDB. For eksempel prøvede jeg at lege og lave nogle tåbelige forespørgsler og se, hvordan det reagerer, og det resulterer i:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Derfor fandt jeg MCOL-1620 og MCOL-131, og det peger på at indstille variabelen infinidb_vtable_mode. Se nedenfor:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Men indstilling infinidb_vtable_mode=0 , hvilket betyder, at den behandler forespørgsel som generisk og yderst kompatibel række-for-række-behandlingstilstand. Nogle WHERE-sætningskomponenter kan behandles af ColumnStore, men joins behandles udelukkende af mysqld ved hjælp af en indlejret loop join-mekanisme. Se nedenfor:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Det tog dog noget tid, da det forklarer, at det udelukkende blev behandlet af mysqld. Alligevel er optimering og skrivning af gode forespørgsler stadig den bedste tilgang og ikke uddelegere alt til ColumnStore.
Derudover har du lidt hjælp til at analysere dine forespørgsler ved at køre kommandoer såsom SELECT calSetTrace(1); eller SELECT calGetStats(); . Du kan bruge disse sæt kommandoer, for eksempel optimere de lave og dårlige forespørgsler eller se dens forespørgselsplan. Tjek det ud her for flere detaljer om analyse af forespørgslerne.
Administration af ColumnStore
Når du har fuldt opsat MariaDB ColumnStore, leveres den med sit værktøj ved navn mcsadmin, som du kan bruge til at udføre nogle administrative opgaver. Du kan også bruge dette værktøj til at tilføje endnu et modul, tildele eller flytte til DBroots fra PM til PM osv. Se deres manual om dette værktøj.
Grundlæggende kan du gøre følgende, for eksempel at kontrollere systemoplysningerne:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Konklusion
MariaDB ColumnStore er en meget kraftfuld lagermotor til din OLAP- og big data-behandling. Dette er helt åben kildekode, hvilket er meget fordelagtigt at bruge end at bruge proprietære og dyre OLAP-databaser, der er tilgængelige på markedet. Alligevel er der andre alternativer at prøve, såsom ClickHouse, Apache HBase eller Citus Datas cstore_fdw. Ingen af disse bruger dog MySQL/MariaDB, så det er muligvis ikke din levedygtige mulighed, hvis du vælger at holde fast i MySQL/MariaDB-varianterne.