En af mine største glæder som udvikler er at lære, hvordan forskellige teknologier krydser hinanden.
Gennem årene har jeg haft mulighed for at arbejde med forskellige typer software og værktøjer. Af de mange værktøjer, jeg har brugt, er Python og Structured Query Language (SQL) to af mine favoritter.
I denne artikel vil jeg dele med dig, hvordan Python og de forskellige SQL-databaser interagerer.
Jeg vil tale om de mest populære databaser, SQLite, MySQL og PostgreSQL. Jeg vil forklare de vigtigste forskelle i hver database og de tilsvarende use cases. Og jeg vil afslutte artiklen med noget Python-kode.
Koden viser dig, hvordan du skriver en SQL-forespørgsel for at trække data fra en PostgreSQL-database og gemme dataene i en pandas-dataramme.
Hvis du ikke er bekendt med relationelle databaser (RDBMS), foreslår jeg, at du tjekker Sameers artikel om grundlæggende RDBMS-terminologi her. Resten af artiklen vil bruge udtryk, der refereres til i Sameers artikel.
Populære SQL-databaser
SQLite
SQLite er bedst kendt for at være en integreret database. Det betyder, at du ikke behøver at installere en ekstra applikation eller bruge en separat server for at køre databasen.
Hvis du opretter en MVP eller ikke har brug for et væld af datalagerplads, vil du gerne gå med en SQLite-database.
Fordelene er, at du kan bevæge dig hurtigere med en SQLite-database i forhold til MySQL og PostgreSQL. Når det er sagt, vil du sidde fast med begrænset funktionalitet. Du vil ikke være i stand til at tilpasse funktioner eller tilføje et væld af flerbrugerfunktionalitet.
MySQL/PostgreSQL
Der er tydelige forskelle mellem MySQL og PostgreSQL. Når det er sagt, i betragtning af artiklens kontekst passer de ind i en lignende kategori.
Begge databasetyper er gode til virksomhedsløsninger. Hvis du har brug for at skalere hurtigt, er MySQL og PostgreSQL dit bedste bud. De vil give langsigtet infrastruktur og styrke din sikkerhed.
En anden grund til, at de er gode til virksomheder, er, at de kan håndtere højtydende aktiviteter. Længere indsæt, opdater og vælg sætninger kræver meget computerkraft. Du vil være i stand til at skrive disse udsagn med mindre latenstid end hvad en SQLite-database ville give dig.
Hvorfor forbinde Python og en SQL-database?
Du undrer dig måske, "hvorfor skulle jeg bekymre mig om at forbinde Python og en SQL-database?"
Der er mange use cases, når nogen ønsker at forbinde Python til en SQL-database. Som jeg nævnte tidligere, arbejder du muligvis på en webapplikation. I dette tilfælde skal du tilslutte en SQL-database, så du kan gemme de data, der kommer fra webapplikationen.
Måske arbejder du med datateknik, og du har brug for at bygge en automatiseret ETL-pipeline. At forbinde Python til en SQL-database vil give dig mulighed for at bruge Python til dets automatiseringsmuligheder. Du vil også være i stand til at kommunikere mellem forskellige datakilder. Du behøver ikke at skifte mellem forskellige programmeringssprog.
At forbinde Python og en SQL-database vil også gøre dit datavidenskabelige arbejde mere bekvemt. Du vil være i stand til at bruge dine Python-færdigheder til at manipulere data fra en SQL-database. Du behøver ikke en CSV-fil.
Sådan forbinder Python og SQL-databaser

Python- og SQL-databaser forbindes gennem brugerdefinerede Python-biblioteker. Du kan importere disse biblioteker til dit Python-script.
Databasespecifikke Python-biblioteker fungerer som supplerende instruktioner. Disse instruktioner guider din computer til, hvordan den kan interagere med din SQL-database. Ellers vil din Python-kode være et fremmedsprog for den database, du forsøger at oprette forbindelse til.
Sådan konfigurerer du projektet
Lad os tage en PostgreSQL-database, AWS Redshift, for eksempel. Først skal du importere psycopg-biblioteket. Det er et universelt Python-bibliotek til PostgreSQL-databaser.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdDu vil bemærke, at vi også importerede JSON- og panda-bibliotekerne. Vi importerede JSON, fordi oprettelse af en JSON-konfigurationsfil er en sikker måde at gemme dine databaselegitimationsoplysninger. Vi vil ikke have, at andre ser dem!
Panda-biblioteket vil gøre dig i stand til at bruge alle pandas' statistiske muligheder til dit Python-script. I dette tilfælde vil biblioteket gøre det muligt for Python at gemme de data, din SQL-forespørgsel returnerer i en dataramme.
Dernæst vil du have adgang til din konfigurationsfil. json.load() funktionen læser JSON-filen, så du kan få adgang til dine databaselegitimationsoplysninger i næste trin.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Nu hvor dit Python-script kan få adgang til din JSON-konfigurationsfil, vil du gerne oprette en databaseforbindelse. Du skal læse og bruge legitimationsoplysningerne fra din konfigurationsfil:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()Du har lige oprettet en databaseforbindelse! Da du importerede psycopg-biblioteket, oversatte du Python-koden, du skrev ovenfor, for at tale til PostgreSQL-databasen (AWS Redshift).
I sig selv ville AWS Redshift ikke forstå ovenstående kode. Men fordi du importerede psycopg-biblioteket, taler du nu et sprog, AWS Redshift kan forstå.
Det gode ved Python er, at det har biblioteker til SQLite, MySQL og PostgreSQL. Du vil være i stand til at integrere teknologierne med lethed.
Sådan skriver man en SQL-forespørgsel
Du er velkommen til at downloade de europæiske fodbolddata til din PostgreSQL-database. Jeg vil bruge dens data til dette eksempel.
Den databaseforbindelse, du oprettede i det sidste trin, lader dig skrive SQL for derefter at gemme dataene i en Python-venlig datastruktur. Nu hvor du har etableret en databaseforbindelse, kan du skrive en SQL-forespørgsel for at begynde at trække data:
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Arbejdet er dog ikke færdigt endnu. Du skal skrive noget ekstra Python-kode, der udfører SQL-forespørgslen:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Så skal du gemme de returnerede data i en pandas dataramme:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)Du burde få en panda-dataramme (raw_initial_df), der ser sådan ud:
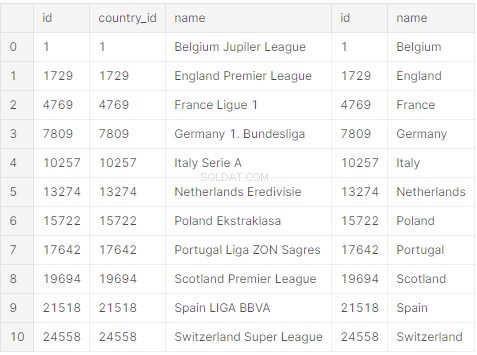
Der er en database for alle

SQLite, MySQL og PostgreSQL har alle deres fordele og ulemper. Den, du vælger, bør afhænge af dit projekt eller din virksomheds behov. Du bør også overveje, hvad du har brug for nu versus flere år hen ad vejen.
Det vigtige at huske er, at Python kan integreres med hver databasetype.
Denne artikel ridser i overfladen for, hvad der er muligt ved at forbinde Python til en SQL-database. Jeg elsker at se, hvordan software krydser og kombinerer for at tilføje en utrolig værdi.
Ønsker du mere af denne type indhold, kan du finde mig på Course to Hire! Jeg vil gerne hjælpe flere mennesker med at lære at kode og få et job inden for tech. Kontakt venligst for spørgsmål, eller hvis du bare vil sige hej :)