Hybrid Cloud er et nyere koncept, der er blevet udvidet i et par år, og som nu er en almindelig topologi i enhver virksomhed for en Disaster Recovery Plan (DRP), eller endda for at have redundans på dine systemer.
Når du har dit Hybrid Cloud-miljø kørende, bliver du nødt til at vide, hvad der sker hele tiden. Overvågning er et must, hvis du vil være sikker på, at alt går fint, eller hvis du måske skal ændre noget. For hver databaseteknologi er der flere ting, der skal overvåges. Nogle af disse er specifikke for databasemotoren, leverandøren eller endda den specifikke version, du bruger.
I denne blog vil vi se, hvad du har brug for at overvåge i en PostgreSQL-database, der kører på et Hybrid Cloud-miljø, og hvordan ClusterControl kan hjælpe dig med denne opgave.
Hvad skal overvåges i PostgreSQL
Når du overvåger en databaseklynge eller en node, er der to hovedting at tage hensyn til:operativsystemet og selve databasen. Du bliver nødt til at definere, hvilke målinger du vil overvåge fra begge sider, og hvordan du vil gøre det.
Husk, at når en af dine metrics påvirkes, kan den også påvirke andre, hvilket gør fejlfinding af problemet mere kompleks. At have et godt overvågnings- og alarmeringssystem er vigtigt for at gøre denne opgave så enkel som muligt.
Overvågning af operativsystem
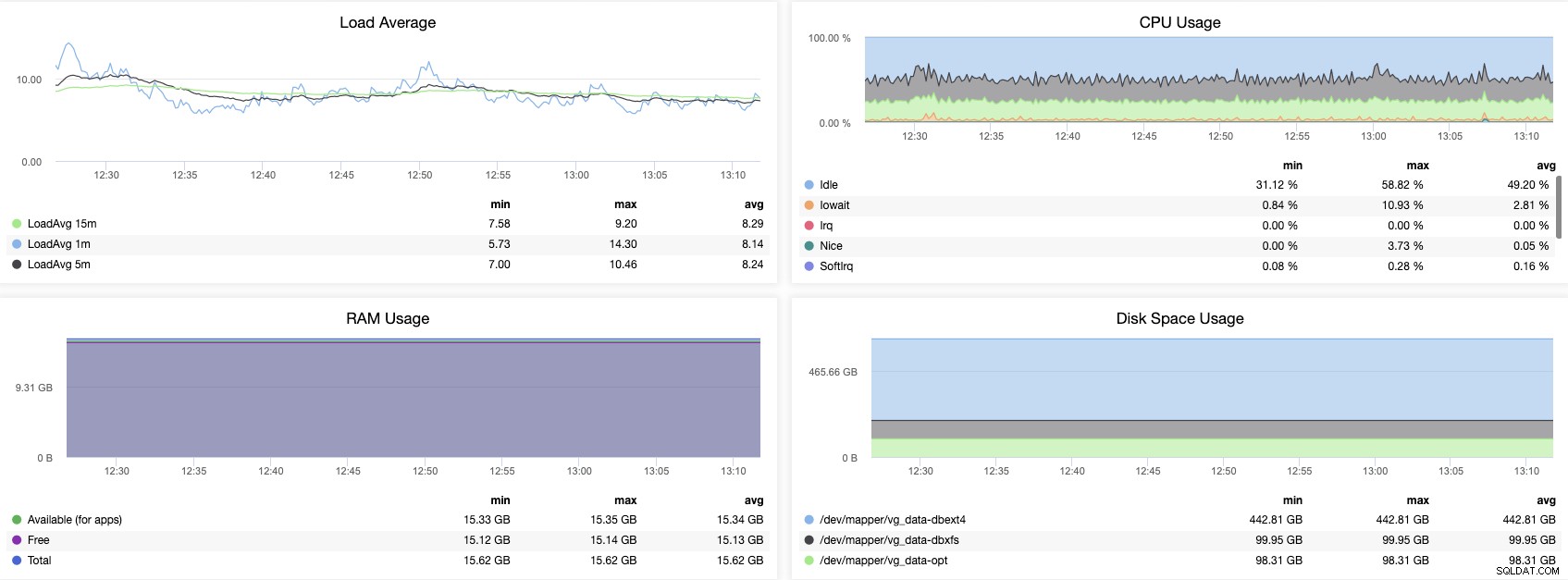
En vigtig ting (som er fælles for alle databasemotorer og endda for alle systemer) er at overvåge operativsystemets adfærd. Lad os se nogle punkter at tjekke her.
CPU-brug
En for høj procentdel af CPU-brug kan være et problem, hvis det ikke er normal adfærd. I dette tilfælde er det vigtigt at identificere processen/processerne, der genererer dette problem. Hvis problemet er databaseprocessen, skal du kontrollere, hvad der sker inde i databasen.
RAM-hukommelse eller SWAP-brug
Hvis du ser en høj værdi for denne metrik, og intet er ændret i dit system, skal du sandsynligvis tjekke din databasekonfiguration. Parametre som shared_buffers og work_mem kan påvirke dette direkte, da de definerer mængden af hukommelse, der skal kunne bruges til PostgreSQL-databasen.
Diskbrug
En unormal stigning i brugen af diskplads eller et for stort forbrug af diskadgang er vigtige ting at overvåge, da du kan have et stort antal fejl logget i PostgreSQL-logfilen eller en dårlig cache-konfiguration, der kan generere et vigtigt diskadgangsforbrug i stedet for at bruge hukommelse til at behandle forespørgslerne.
Indlæsningsgennemsnit
Det er relateret til de tre punkter nævnt ovenfor. Et højt belastningsgennemsnit kan genereres af overdreven CPU-, RAM- eller diskbrug.
Netværk
Et netværksproblem kan påvirke alle systemerne, da applikationen ikke kan oprette forbindelse (eller forbinde tabende pakker) til databasen, så dette er en vigtig metrik at overvåge. Du kan overvåge latens eller pakketab, og hovedproblemet kan være en netværksmætning, et hardwareproblem eller bare en dårlig netværkskonfiguration.
Databaseovervågning
Overvågning af din PostgreSQL-database er ikke kun vigtigt for at se, om du har et problem, men også for at vide, om du skal ændre noget for at forbedre din databaseydeevne, det er nok en af de vigtigste ting at overvåge i en database. Lad os se nogle målinger, der er vigtige for dette.
Forespørgselsovervågning
Generelt er databaserne konfigureret med kompatibilitet og stabilitet i tankerne som standard, så du skal kende dine forespørgsler og deres mønster og konfigurere dine databaser afhængigt af den trafik, du har. Her kan du bruge EXPLAIN-kommandoen til at kontrollere forespørgselsplanen for en specifik forespørgsel, og du kan også overvåge mængden af SELECT, INSERT, UPDATE eller DELETE på hver node. Hvis du har en lang forespørgsel eller et stort antal forespørgsler, der kører på samme tid, kan det være et problem for alle systemerne.
Aktive sessioner
Du bør også overvåge antallet af aktive sessioner. Hvis du er tæt på grænsen, skal du tjekke, om der er noget galt, eller om du blot skal øge den maksimale forbindelsesværdi i databasekonfigurationen. Forskellen i antallet kan være en stigning eller et fald af forbindelser. Dårlig brug af forbindelsespooling, låsning eller netværksproblemer er de mest almindelige problemer relateret til antallet af forbindelser.
Databaselåse
Hvis du har en forespørgsel, der venter på en anden forespørgsel, skal du kontrollere, om den anden forespørgsel er en normal proces eller noget nyt. I nogle tilfælde, hvis nogen for eksempel laver en opdatering på et stort bord, kan denne handling påvirke din databases normale adfærd og generere et stort antal låse.
replikeringsstatus
Nøglemålingerne, der skal overvåges for replikering, er forsinkelsen og replikeringstilstanden. De mest almindelige problemer er netværksproblemer, hardwareressourceproblemer eller problemer med underdimensionering. Hvis du står over for et replikeringsproblem, skal du vide dette hurtigst muligt, da du skal rette det for at sikre et miljø med høj tilgængelighed.
Sikkerhedskopier
At undgå tab af data er en af de grundlæggende DBA-opgaver, så du behøver ikke kun tage sikkerhedskopien, du skal vide, om sikkerhedskopieringen er gennemført, og om den er brugbar. Normalt tages der ikke højde for dette sidste punkt, men det er nok den vigtigste kontrol i en backup-proces.
Databaselogfiler
Du bør overvåge din databaselog for fejl, autentificeringsproblemer eller endda langvarige forespørgsler. De fleste af fejlene er skrevet i logfilen med detaljerede nyttige oplysninger til at rette dem.
Meddelelser og advarsler
Det er ikke nok at overvåge et system, hvis du ikke modtager en meddelelse om hvert problem. Uden et alarmeringssystem bør du gå til overvågningsværktøjet for at se, om alt er i orden, og det kan være muligt, at du har et stort problem siden mange timer siden. Dette advarselsjob kunne udføres ved at bruge e-mail-beskeder, tekstbeskeder eller andre værktøjer som Slack.
Det er virkelig svært at finde et værktøj til at overvåge alle de nødvendige metrics for PostgreSQL, generelt skal du bruge mere end én og endda nogle scripting skal laves. En måde at centralisere overvågnings- og advarselsopgaven på er ved at bruge ClusterControl, som giver dig funktioner som sikkerhedskopiering, overvågning og alarmering, implementering og skalering, automatisk gendannelse og flere vigtige funktioner til at hjælpe dig med at administrere dine databaser. Alle disse funktioner på det samme system.
Et vigtigt punkt her er, at ClusterControl fungerer på Cloud, On-prem eller endda en kombination af begge. Kravet her er at have SSH-adgang til noderne, og så vil ClusterControl tage sig af dem.
Overvågning af din PostgreSQL-database med ClusterControl
ClusterControl er et administrations- og overvågningssystem, der hjælper med at implementere, administrere, overvåge og skalere dine databaser fra en brugervenlig grænseflade. Det har understøttelse af de bedste open source-databaseteknologier, og du kan automatisere mange af de databaseopgaver, du skal udføre regelmæssigt, såsom tilføjelse og skalering af nye noder, kørsel af sikkerhedskopier og gendannelser og mere.
ClusterControl giver dig mulighed for at overvåge dine servere i realtid med et foruddefineret sæt dashboards for at analysere nogle af de mest almindelige metrics.
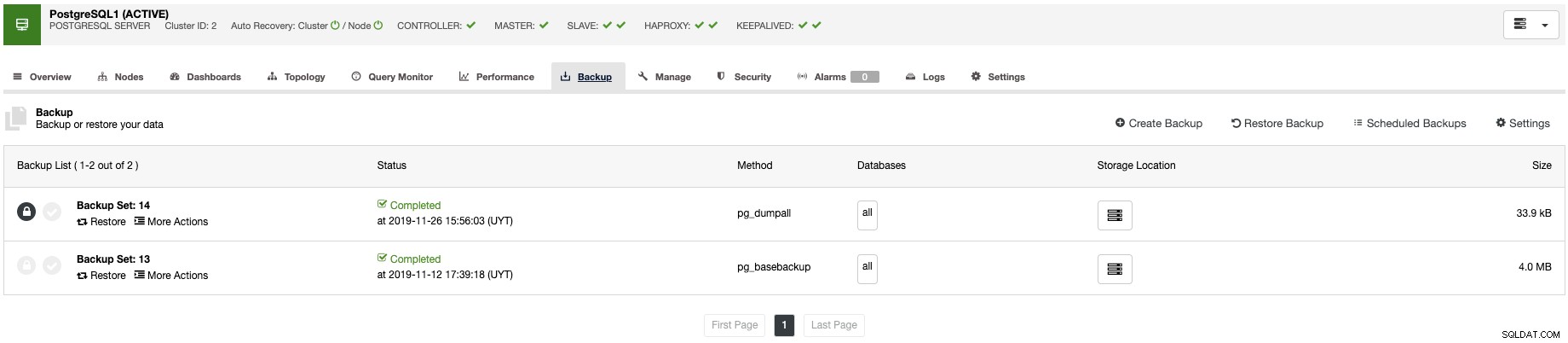
Det giver dig mulighed for at tilpasse de tilgængelige grafer i klyngen, og du kan aktivere den agentbaserede overvågning for at generere mere detaljerede dashboards.
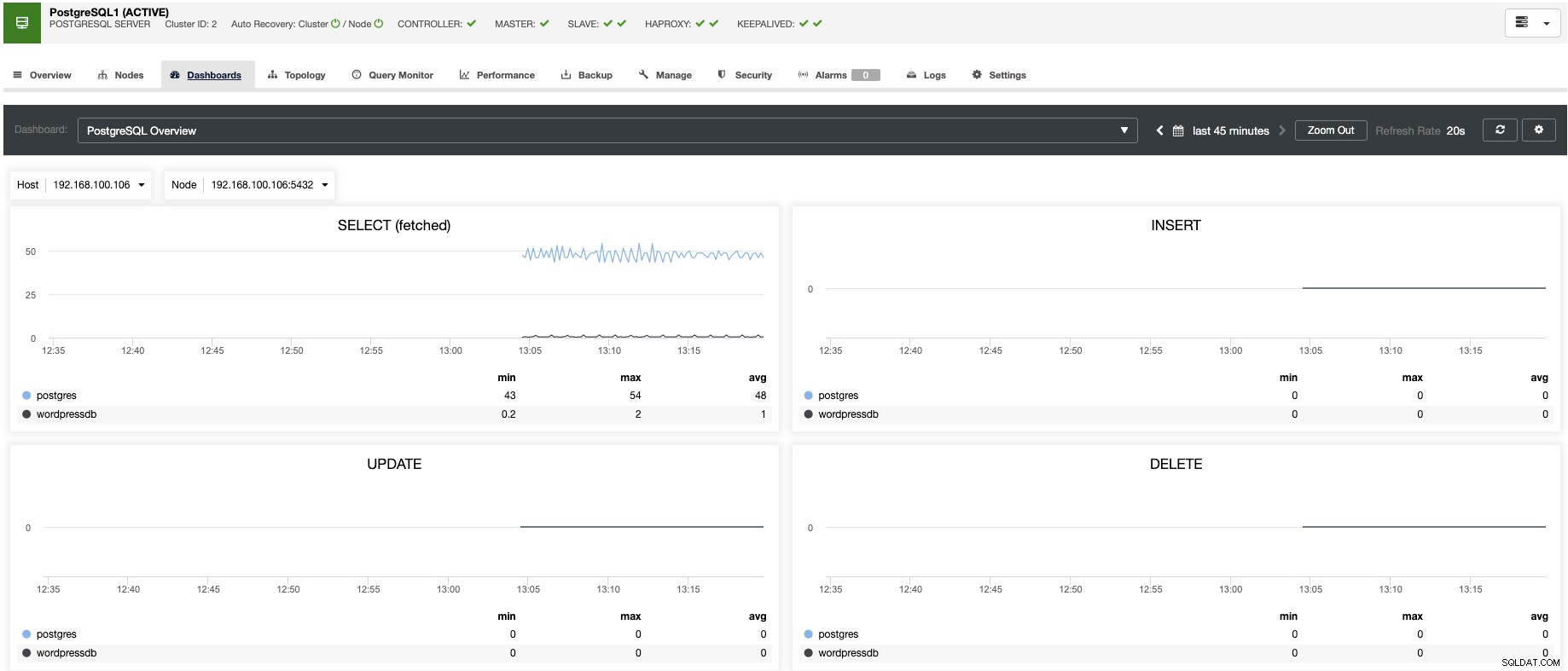
Du kan også oprette advarsler, som informerer dig om begivenheder i din klynge, eller integreres med forskellige tjenester såsom PagerDuty eller Slack.
I sektionen for forespørgselsovervågning kan du finde de øverste forespørgsler, de kørende forespørgsler, forespørgselsudlignere og forespørgselsstatistikker for at overvåge din databasetrafik.
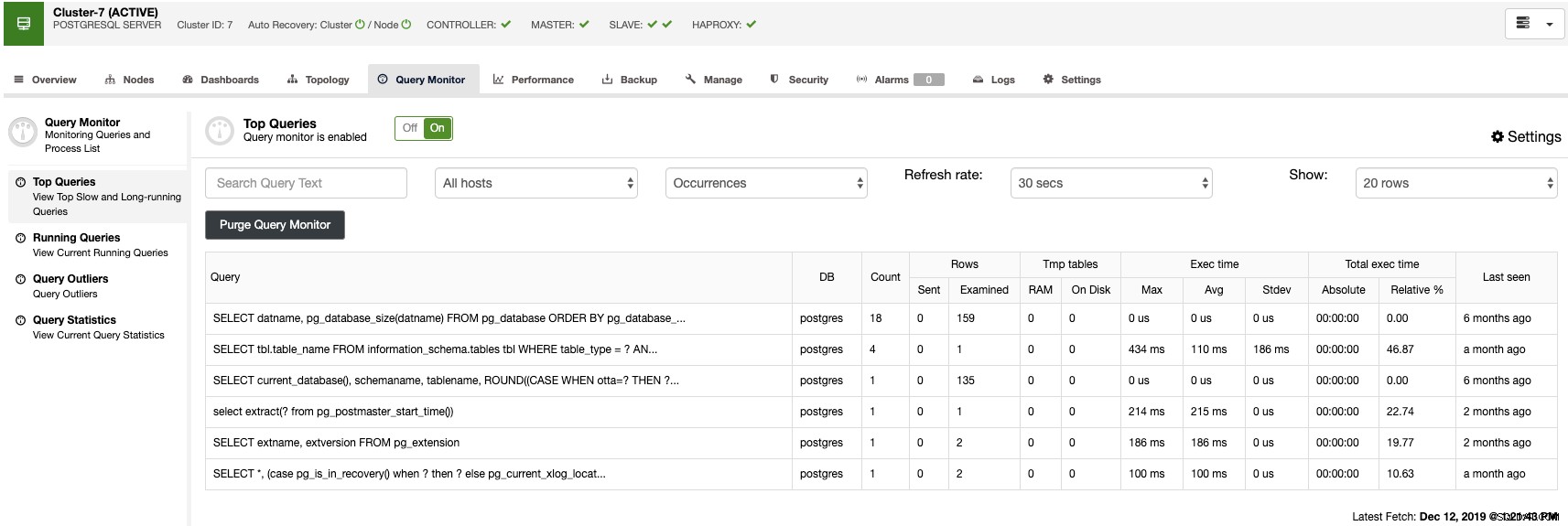
Med disse funktioner kan du se, hvordan det går med din PostgreSQL-database.
Til sikkerhedskopiering centraliserer ClusterControl det for at beskytte, sikre og gendanne dine data, og med bekræftelsessikkerhedskopieringsfunktionen kan du bekræfte, om sikkerhedskopieringen er god til at gå.
Dette bekræftelses-backupjob vil gendanne sikkerhedskopien i en separat selvstændig vært, så du kan sikre dig, at sikkerhedskopieringen fungerer.
Endelig behøver du ikke at få adgang til din databaseknude for at kontrollere logfilerne, du kan finde alle dine databaselogfiler centraliseret i sektionen ClusterControl Log.
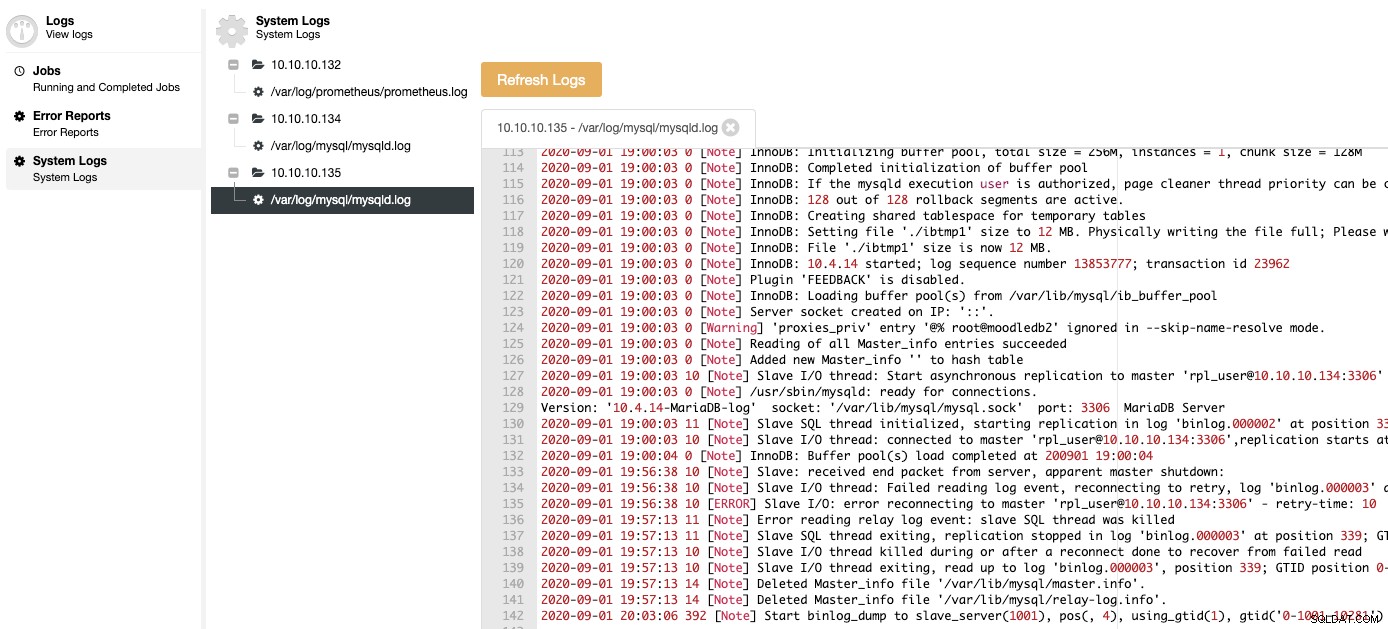
Som du kan se, kan du håndtere alle de nævnte ting fra det samme centraliserede system:ClusterControl.
Overvågning med ClusterControl-kommandolinjen
Til scripting og automatisering af opgaver, eller selvom du bare foretrækker kommandolinjen, har ClusterControl værktøjet s9s. Det er et kommandolinjeværktøj til at administrere eller overvåge din databaseklynge.
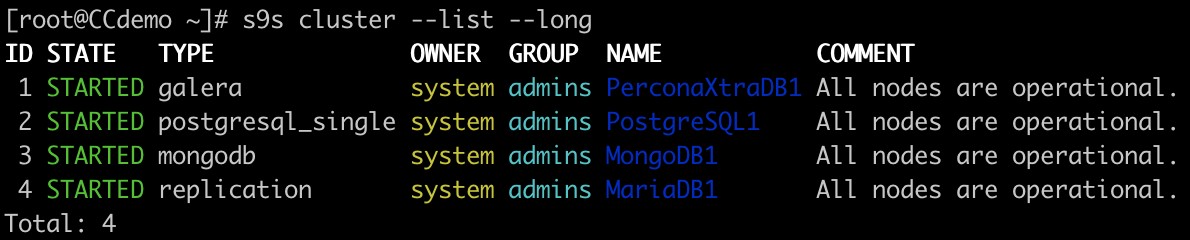
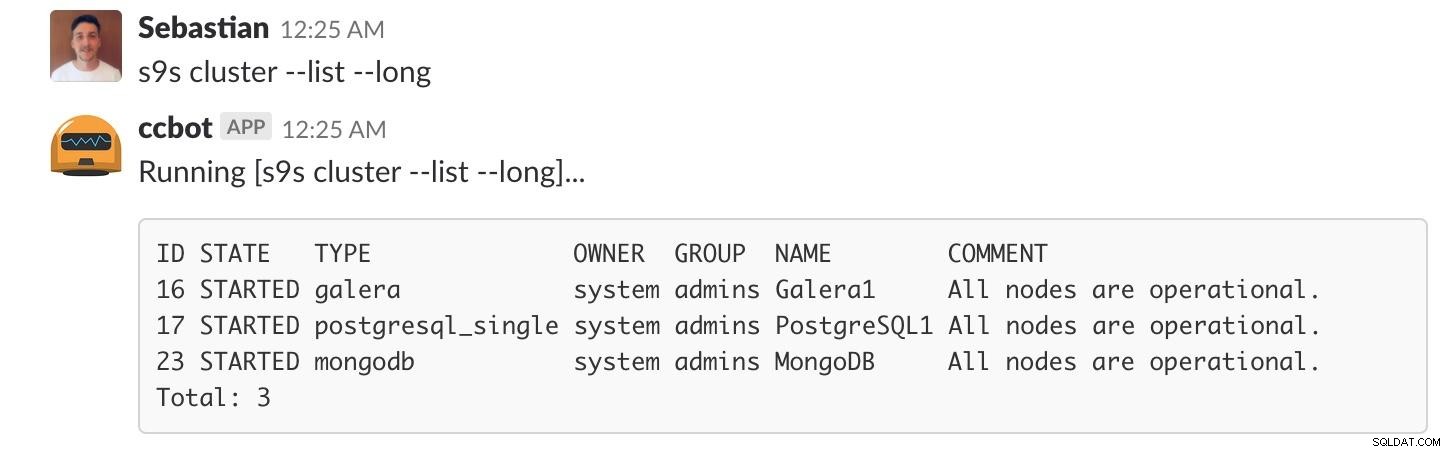
Klyngeliste
Nodeliste
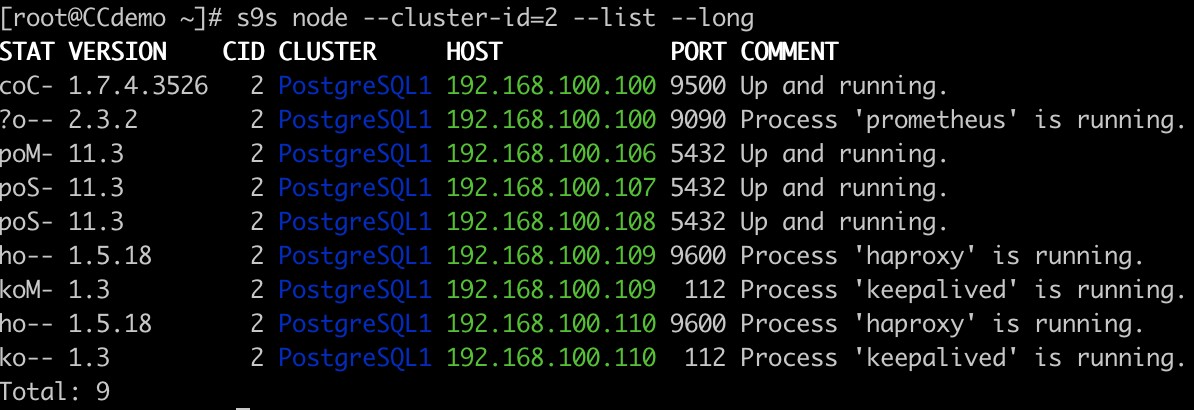
Du kan udføre alle de opgaver (og endnu flere), der er tilgængelige i ClusterControl-brugergrænsefladen, og du kan integrere denne funktion med nogle eksterne værktøjer som slack for at administrere den derfra.
Konklusion
Som du kan se, er overvågning absolut nødvendig, uanset om den kører on-prem, i skyen eller endda på en blanding af dem, og den bedste måde at gøre det på afhænger af infrastrukturen og selve systemet. I denne blog nævnte vi nogle vigtige metrics til at overvåge i dit PostgreSQL-miljø, hvordan du bruger ClusterControl til at udføre jobbet.