I denne 3. del af Benchmarking Managed PostgreSQL Cloud Solutions , jeg benyttede mig af Googles gratis GCP-tilbud. Det har været en værdifuld oplevelse, og som en systemadministrator, der tilbringer det meste af sin tid på konsollen, kunne jeg ikke gå glip af muligheden for at prøve cloud shell, en af de konsolfunktioner, der adskiller Google fra den cloud-udbyder, jeg er mere fortrolig med , Amazon Web Services.
For hurtigt at opsummere så jeg i del 1 på de tilgængelige benchmarkværktøjer og forklarede, hvorfor jeg valgte AWS Benchmark Procedure for Aurora. Jeg benchmarkede også Amazon Aurora til PostgreSQL version 10.6. I del 2 anmeldte jeg AWS RDS til PostgreSQL version 11.1.
I løbet af denne runde vil testene baseret på AWS Benchmark Procedure for Aurora blive kørt mod Google Cloud SQL til PostgreSQL 9.6, da version 11.1 stadig er i beta.
Cloud-forekomster
Forudsætninger
Som nævnt i de to foregående artikler valgte jeg at lade PostgreSQL-indstillingerne være på deres cloud GUC-standarder, medmindre de forhindrer test i at køre (se længere nede nedenfor). Husk fra tidligere artikler, at antagelsen har været, at cloud-udbyderen ud af boksen skulle have databaseforekomsten konfigureret for at give en rimelig ydeevne.
AWS pgbench-timing-patchen til PostgreSQL 9.6.5 blev anvendt rent på Google Cloud-versionen af PostgreSQL 9.6.10.
Ved at bruge de oplysninger, Google udgav i deres blog Google Cloud for AWS Professionals, matchede jeg specifikationerne for klienten og målforekomsterne med hensyn til Compute-, Storage- og Networking-komponenterne. For eksempel opnås Google Cloud, der svarer til AWS Enhanced Networking ved at dimensionere beregningsknuden baseret på formlen:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Når det kommer til opsætning af måldatabaseinstansen, på samme måde som AWS, tillader Google Cloud ingen replikaer, men lageret er krypteret i hvile, og der er ingen mulighed for at deaktivere det.
Endelig, for at opnå den bedste netværksydelse, skal klienten og målforekomsterne være placeret i samme tilgængelighedszone.
Kunde
Klientforekomstens specifikationer, der matcher den nærmeste AWS-forekomst, er:
- vCPU:32 (16 kerner x 2 tråde/kerne)
- RAM:208 GiB (maksimalt for 32 vCPU-forekomsten)
- Lagring:Compute Engine persistent disk
- Netværk:16 Gbps (maks. [32 vCPU'er x 2 Gbps/vCPU] og 16 Gbps)
Forekomstdetaljer efter initialisering:
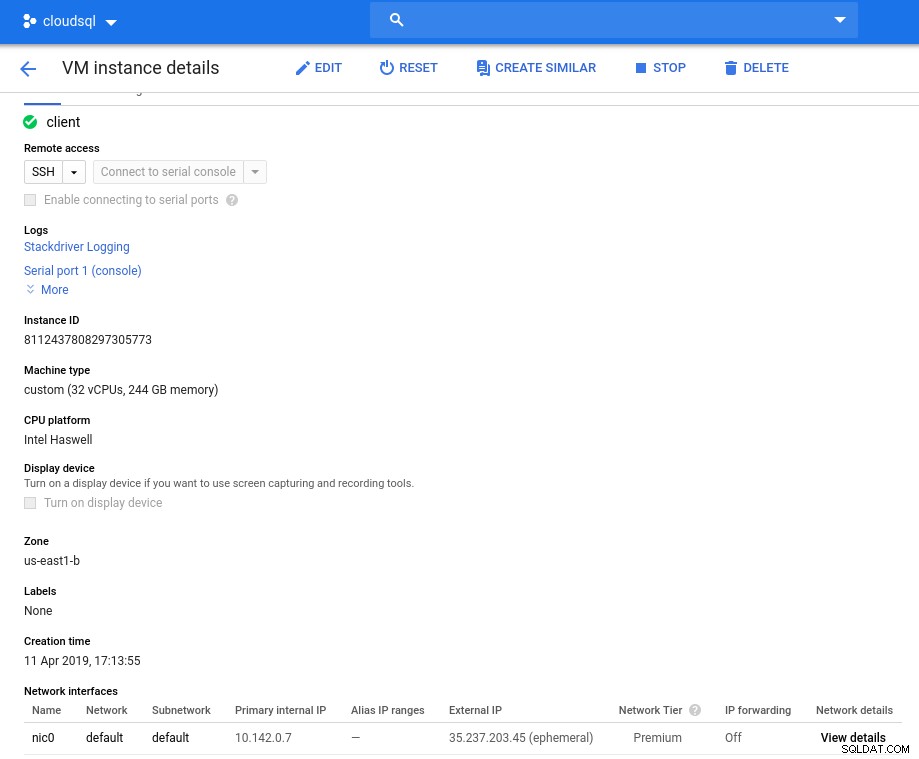 Klientforekomst:Compute and Network
Klientforekomst:Compute and Network Bemærk:Forekomster er som standard begrænset til 24 vCPU'er. Googles tekniske support skal godkende kvoteforhøjelsen til 32 vCPU'er pr. instans.

Selvom sådanne anmodninger normalt behandles inden for 2 hverdage, er jeg nødt til at give Google Support Services en tommel op for at fuldføre min anmodning på kun 2 timer.
For de nysgerrige er formlen for netværkshastighed baseret på den computerdokumentation, der refereres til i denne GCP-blog.
DB-klynge
Nedenfor er databaseforekomstens specifikationer:
- vCPU:8
- RAM:52 GiB (maksimalt)
- Lagerplads:144 MB/s, 9.000 IOPS
- Netværk:2.000 MB/s
Bemærk, at den maksimalt tilgængelige hukommelse for en 8 vCPU-instans er 52 GiB. Mere hukommelse kan allokeres ved at vælge en større instans (flere vCPU'er):
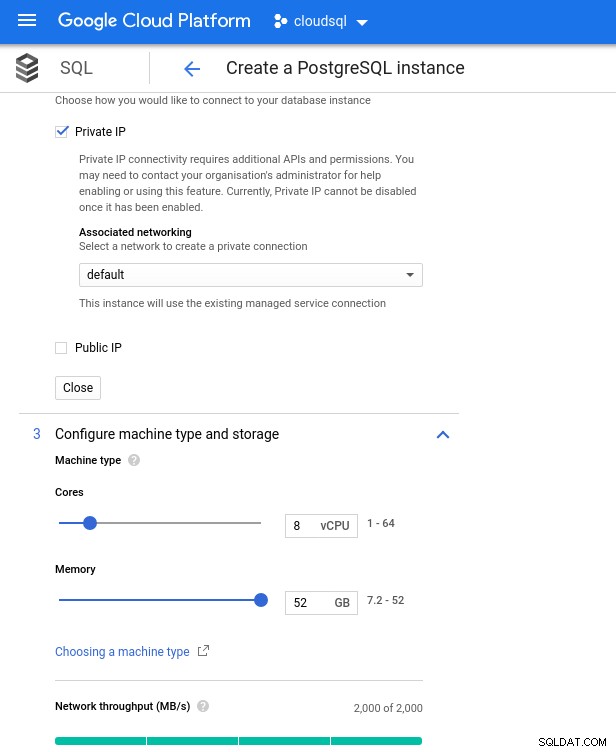 Database CPU og hukommelsesstørrelse
Database CPU og hukommelsesstørrelse Mens Google SQL automatisk kan udvide det underliggende lager, hvilket i øvrigt er en rigtig fed funktion, valgte jeg at deaktivere muligheden for at være konsistent med AWS-funktionssættet, og undgå en potentiel I/O-påvirkning under resize-operationen. ("potentiale", fordi det ikke burde have nogen negativ indvirkning overhovedet, men efter min erfaring øger størrelsen på enhver form for underliggende lagring I/O, selvom det er i et par sekunder).
Husk på, at AWS-databaseforekomsten blev sikkerhedskopieret af et optimeret EBS-lager, som gav maksimalt:
- 1.700 Mbps båndbredde
- 212,5 MB/s gennemløb
- 12.000 IOPS
Med Google Cloud opnår vi en lignende konfiguration ved at justere antallet af vCPU'er (se ovenfor) og lagerkapacitet:
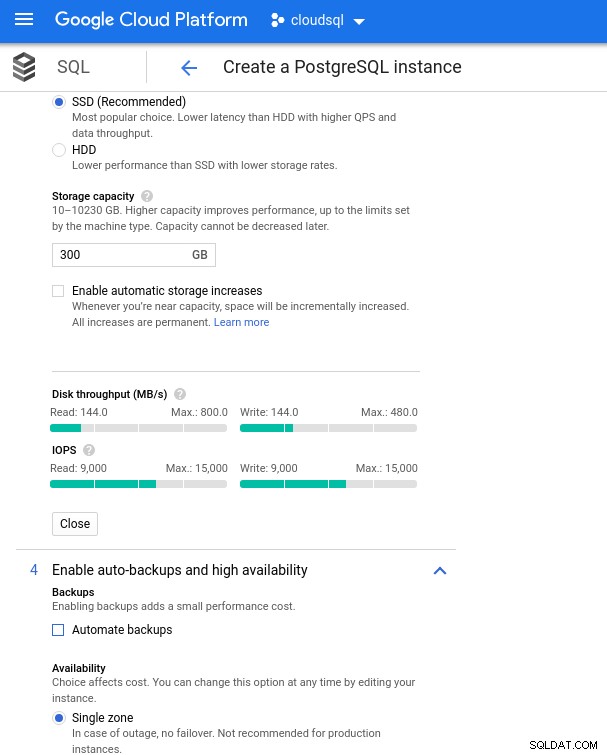 Databaselagringskonfiguration og sikkerhedskopieringsindstillinger
Databaselagringskonfiguration og sikkerhedskopieringsindstillinger Kørsel af benchmarks
Opsætning
Installer derefter benchmarkværktøjerne, pgbench og sysbench ved at følge instruktionerne i Amazon-guiden tilpasset PostgreSQL version 9.6.10.
Initialiser PostgreSQL-miljøvariablerne i .bashrc og indstil stierne til PostgreSQL-binære filer og biblioteker:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libPreflight-tjekliste:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Og vi er klar til start:
pgbench
Initialiser pgbench-databasen.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…og flere minutter senere:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Som vi nu er vant til, skal databasestørrelsen være 160GB. Lad os bekræfte det:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Når alle forberedelser er afsluttet, start læse/skrive-testen:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsUps! Hvad er maksimum?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Så mens AWS sætter et stort set nok max_connections, da jeg ikke stødte på det problem, kræver Google Cloud en lille tweak...Tilbage til cloud-konsollen, opdater databaseparameteren, vent et par minutter og kontroller derefter:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Genstart af testen ser ud til at alt fungerer fint:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...men der er en anden fangst. Jeg fik en overraskelse, da jeg forsøgte at åbne en ny psql-session for at tælle antallet af forbindelser:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsKan det være, at superuser_reserved_connections ikke er standard?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Det er standarden, hvad kan det så ellers være?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! En anden bump af max_connections tager sig af det, dog krævede det, at jeg genstartede pgbench-testen. Og det er folks historien bag den tilsyneladende duplikatkørsel i graferne nedenfor.
Og endelig er resultaterne i:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Udfyld databasen:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareOutput:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Og kør nu testen:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runOg resultaterne:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Benchmark-metrics
PostgreSQL-pluginnet til Stackdriver er blevet forældet fra den 28. februar 2019. Mens Google anbefaler Blue Medora, valgte jeg i forbindelse med denne artikel at gøre op med at oprette en konto og stole på tilgængelige Stackdriver-metrics.
- CPU-udnyttelse:
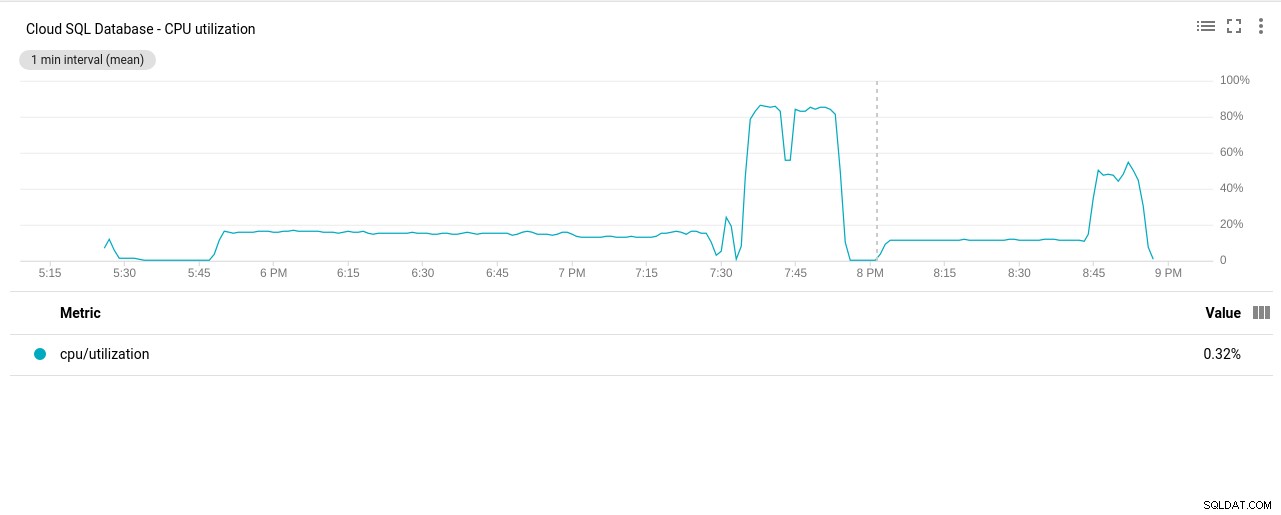 Fotoforfatter Google Cloud SQL:PostgreSQL CPU-udnyttelse
Fotoforfatter Google Cloud SQL:PostgreSQL CPU-udnyttelse - Disk læse-/skrivehandlinger:
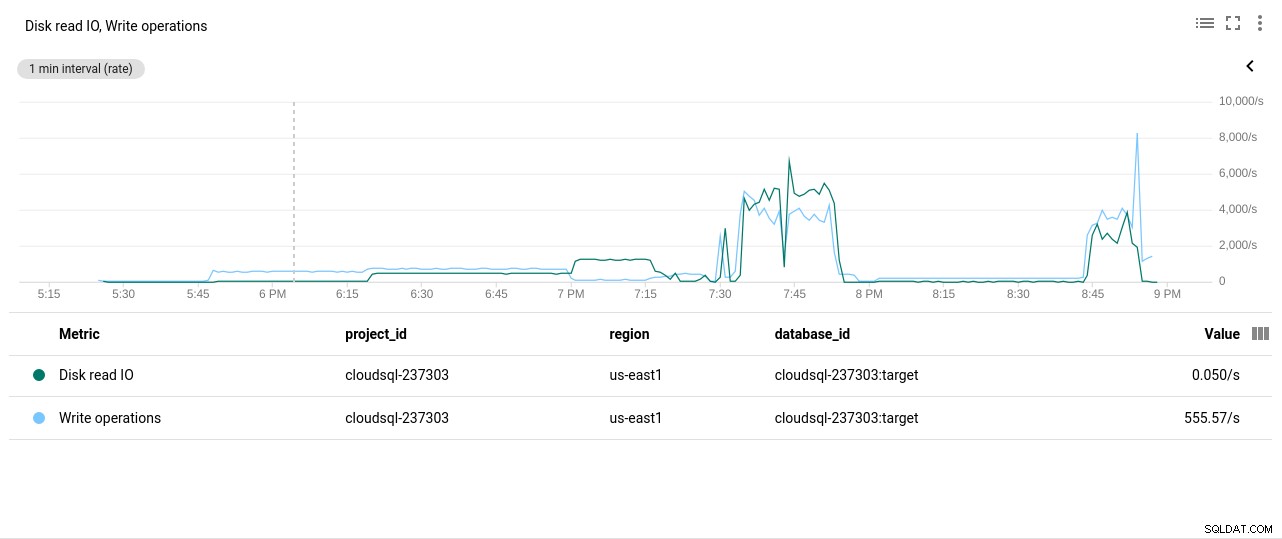 Fotoforfatter Google Cloud SQL:PostgreSQL Disk Læse/skrive operationer
Fotoforfatter Google Cloud SQL:PostgreSQL Disk Læse/skrive operationer - Netværk sendte/modtagne bytes:
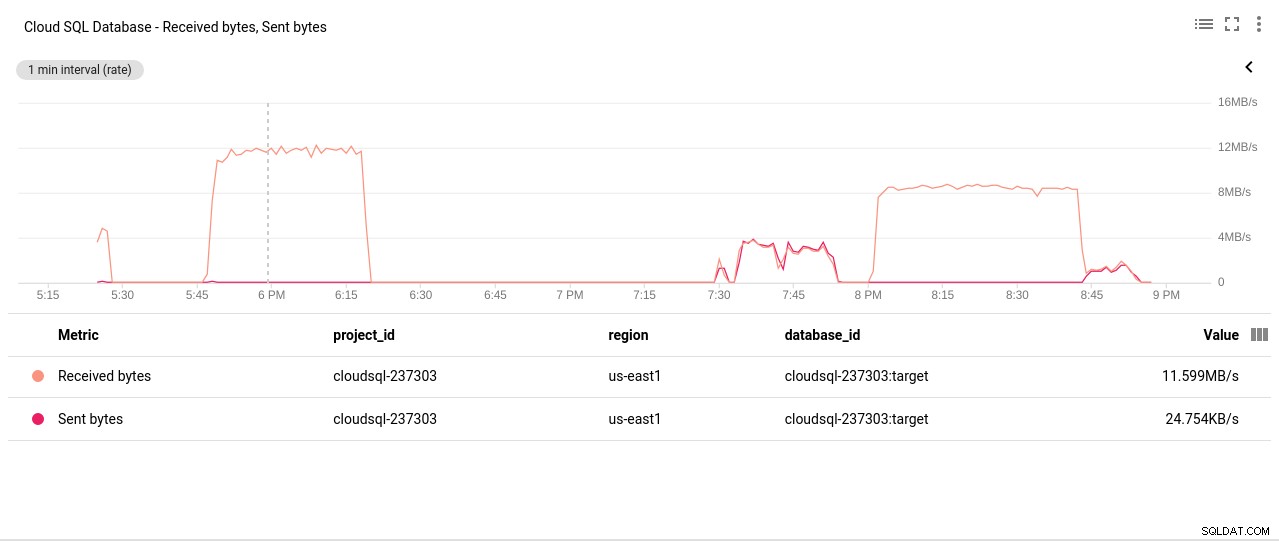 Fotoforfatter Google Cloud SQL:PostgreSQL Network Sendt/Modtaget bytes
Fotoforfatter Google Cloud SQL:PostgreSQL Network Sendt/Modtaget bytes - Antal PostgreSQL-forbindelser:
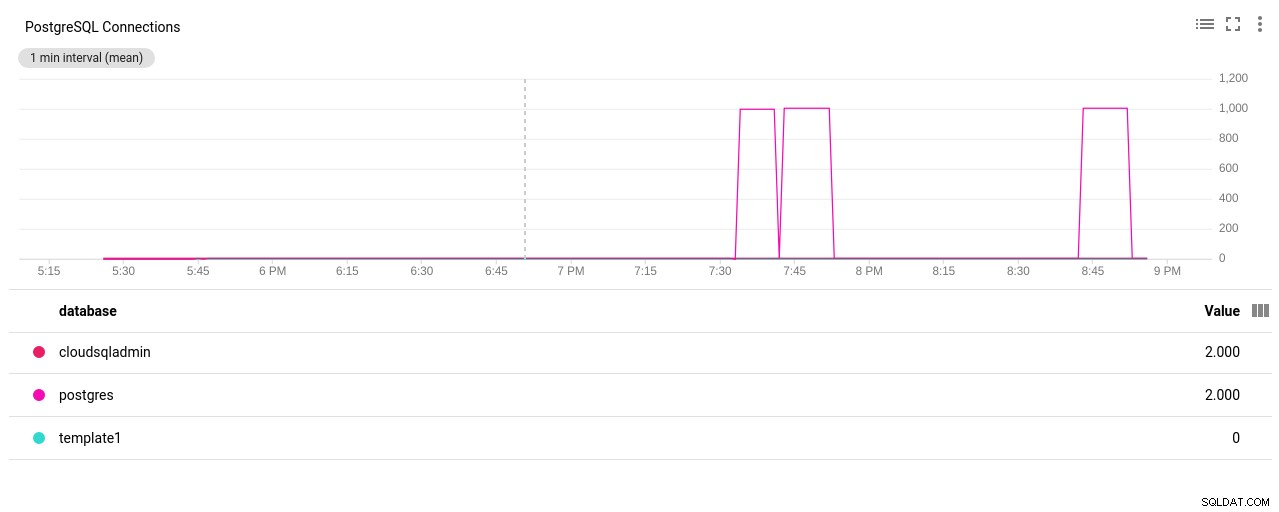 Fotoforfatter Google Cloud SQL:Antal PostgreSQL-forbindelser
Fotoforfatter Google Cloud SQL:Antal PostgreSQL-forbindelser
Benchmark-resultater
pgbench-initialisering
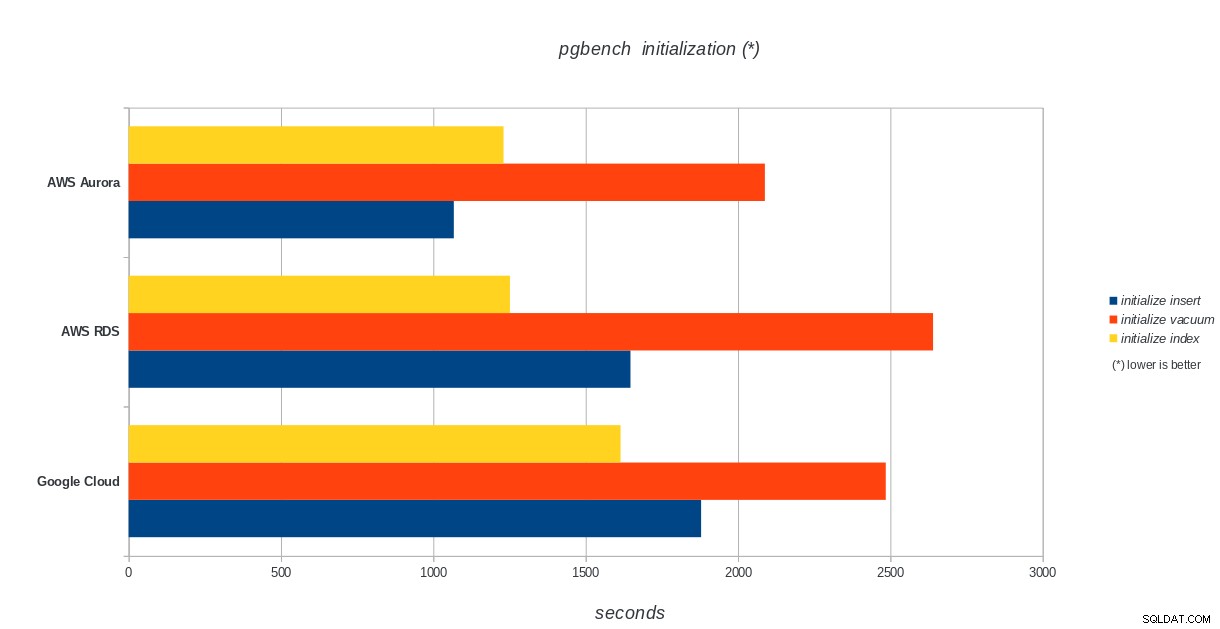 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench initialiseringsresultater
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench initialiseringsresultater pgbench run
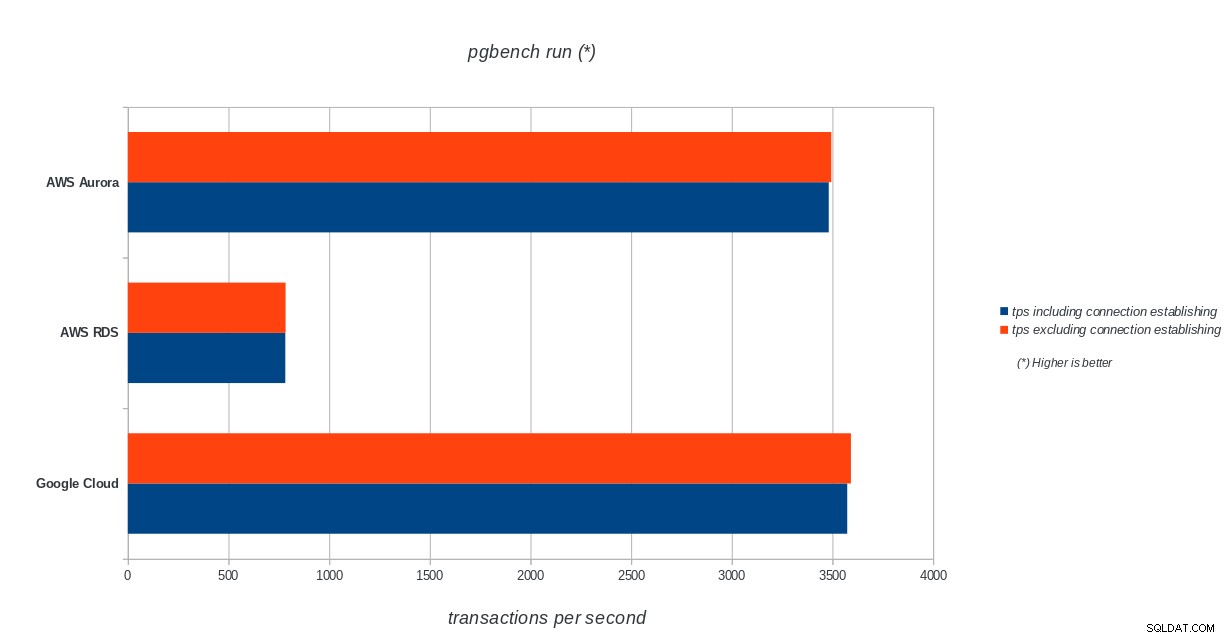 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run resultater
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run resultater sysbench
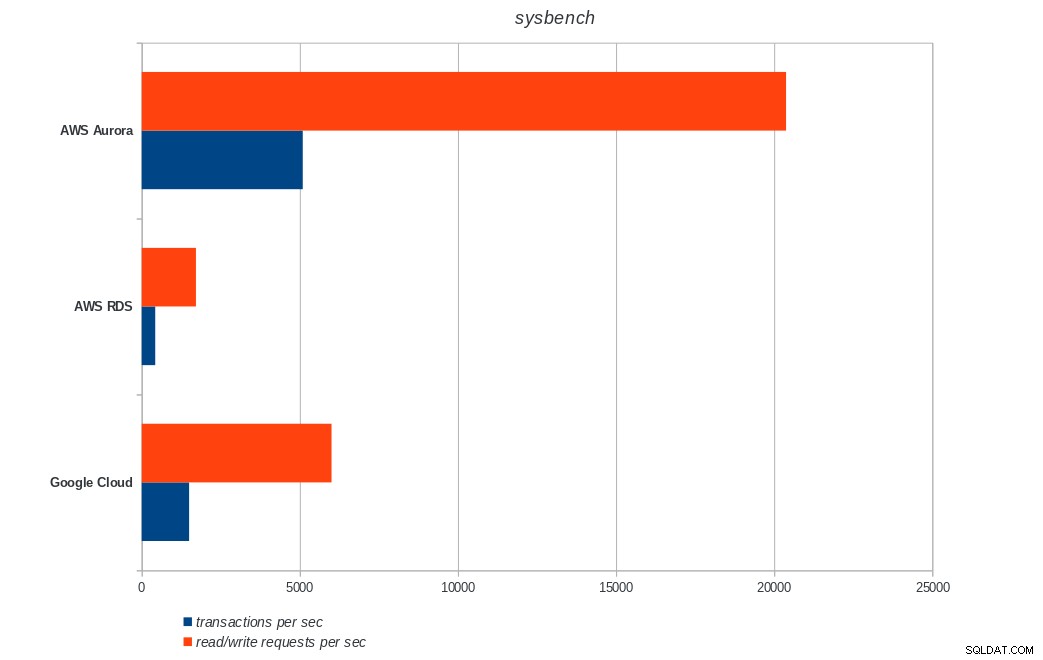 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench-resultater
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench-resultater Konklusion
Amazon Aurora kommer langt først i skrive tunge (sysbench) test, mens den er på niveau med Google Cloud SQL i pgbench læse/skrive tests. Belastningstesten (pgbench-initialisering) sætter Google Cloud SQL i første omgang, efterfulgt af Amazon RDS. Baseret på et overfladisk blik på prismodellerne for AWS Aurora og Google Cloud SQL, vil jeg risikere at sige, at Google Cloud ud af boksen er et bedre valg for den gennemsnitlige bruger, mens AWS Aurora er bedre egnet til højtydende miljøer. Flere analyser følger efter at have gennemført alle benchmarks.
Den næste og sidste del af denne benchmark-serie vil være på Microsoft Azure PostgreSQL.
Tak fordi du læste med, og kommenter venligst nedenfor, hvis du har feedback.