Databaseskema er ikke noget, der er skrevet i sten. Det er designet til en given applikation, men så kan kravene ændre sig, og som regel ændres det. Nye moduler og funktionaliteter tilføjes til applikationen, flere data indsamles, kode- og datamodelrefaktorering udføres. Derved behovet for at ændre databaseskemaet for at tilpasse sig disse ændringer; tilføje eller ændre kolonner, oprette nye tabeller eller partitionere store. Forespørgsler ændrer sig også, efterhånden som udviklere tilføjer nye måder for brugere at interagere med dataene - nye forespørgsler kunne bruge nye, mere effektive indekser, så vi skynder os at oprette dem for at give applikationen den bedste databaseydeevne.
Så hvordan griber vi bedst an til en skemaændring? Hvilke værktøjer er nyttige? Hvordan minimerer man påvirkningen af en produktionsdatabase? Hvad er de mest almindelige problemer med skemadesign? Hvilke værktøjer kan hjælpe dig med at holde dig på toppen af dit skema? I dette blogindlæg vil vi give dig et kort overblik over, hvordan du laver skemaændringer i MySQL og MariaDB. Bemærk venligst, at vi ikke vil diskutere skemaændringer i forbindelse med Galera Cluster. Vi har allerede diskuteret Total Order Isolation, Rolling Schema Upgrades og tips til at minimere påvirkningen fra RSU i tidligere blogindlæg. Vi vil også diskutere tips og tricks relateret til skemadesign, og hvordan ClusterControl kan hjælpe dig med at holde styr på alle skemaændringer.
Typer af skemaændringer
Første ting først. Før vi graver ind i emnet, skal vi forstå, hvordan MySQL og MariaDB udfører skemaændringer. Du kan se, en skemaændring er ikke lig med en anden skemaændring.
Du har måske hørt om online ændringer, øjeblikkelige ændringer eller in-place ændringer. Alt dette er et resultat af et igangværende arbejde for at minimere skemaændringernes indvirkning på produktionsdatabasen. Historisk set var næsten alle skemaændringer blokerende. Hvis du udførte en skemaændring, vil alle forespørgslerne begynde at hobe sig op, mens de venter på, at ALTER er fuldført. Dette medførte naturligvis alvorlige problemer for produktionsinstallationer. Sikker på, folk begynder straks at lede efter løsninger, og vi vil diskutere dem senere på denne blog, da de selv i dag stadig er relevante. Men også arbejdet begyndte at forbedre MySQL's evne til at køre DDL'er (Data Definition Language) uden stor indflydelse på andre forespørgsler.
Øjeblikkelige ændringer
Nogle gange er det ikke nødvendigt at røre ved nogen data i tablespacet, fordi det eneste, der skal ændres, er metadataene. Et eksempel her vil være at slette et indeks eller omdøbe en kolonne. Sådanne operationer er hurtige og effektive. Typisk er deres virkning begrænset. Det er dog ikke uden indflydelse. Nogle gange tager det et par sekunder at udføre ændringen i metadataene, og en sådan ændring kræver en metadatalås for at blive erhvervet. Denne lås er på en per-tabel basis, og den kan blokere for andre operationer, der skal udføres på denne tabel. Du vil se dette som "Venter på tabelmetadatalås"-poster i proceslisten.
Et eksempel på en sådan ændring kan være øjeblikkelig ADD COLUMN, introduceret i MariaDB 10.3 og MySQL 8.0. Det giver mulighed for at udføre denne ret populære skemaændring uden forsinkelse. Både MariaDB og Oracle besluttede at inkludere kode fra Tencent Game, som giver mulighed for øjeblikkeligt at tilføje en ny kolonne til tabellen. Dette er under nogle specifikke forhold; kolonne skal tilføjes som den sidste, fuldtekstindekser kan ikke eksistere i tabellen, rækkeformat kan ikke komprimeres - du kan finde mere information om, hvordan øjeblikkelig tilføjelse af kolonne fungerer i MariaDB-dokumentationen. For MySQL kan den eneste officielle reference findes på mysqlserverteam.com blog, selvom der findes en fejl for at opdatere den officielle dokumentation.
På stedet ændringer
Nogle af ændringerne kræver modifikation af dataene i tablespacet. Sådanne ændringer kan udføres på selve dataene, og der er ingen grund til at oprette en midlertidig tabel med en ny datastruktur. Sådanne ændringer tillader typisk (men ikke altid) andre forespørgsler, der berører tabellen, at blive udført, mens skemaændringen kører. Et eksempel på en sådan operation er at tilføje et nyt sekundært indeks til tabellen. Denne handling vil tage noget tid at udføre, men vil tillade, at DML'er kan udføres.
Genopbygning af tabel
Hvis det ikke er muligt at lave en ændring på plads, vil InnoDB oprette en midlertidig tabel med den nye, ønskede struktur. Det vil derefter kopiere eksisterende data til den nye tabel. Denne operation er den dyreste, og det er sandsynligt (selvom det ikke altid sker) at låse DML'erne. Som følge heraf er en sådan skemaændring meget vanskelig at udføre på et stort bord på en selvstændig server uden hjælp fra eksterne værktøjer - typisk har du ikke råd til at have din database låst i lange minutter eller endda timer. Et eksempel på en sådan operation ville være at ændre kolonnedatatypen, for eksempel fra INT til VARCHAR.
Skemaændringer og replikering
Ok, så vi ved, at InnoDB tillader online skemaændringer, og hvis vi konsulterer MySQL dokumentation, vil vi se, at størstedelen af skemaændringerne (i hvert fald blandt de mest almindelige) kan udføres online. Hvad er årsagen til at dedikere timers udvikling til at skabe online skemaændringsværktøjer som gh-ost? Vi kan acceptere, at pt-online-schema-change er en rest af de gamle, dårlige tider, men gh-ost er en ny software.
Svaret er komplekst. Der er to hovedproblemer.
For det første, når du først starter en skemaændring, har du ikke kontrol over den. Du kan afbryde det, men du kan ikke sætte det på pause. Du kan ikke drosle den. Som du kan forestille dig, er genopbygning af tabellen en dyr operation, og selvom InnoDB tillader at DML'er kan udføres, påvirker yderligere I/O-arbejdsbelastning fra DDL alle andre forespørgsler, og der er ingen måde at begrænse denne påvirkning til et niveau, der er acceptabelt for ansøgning.
For det andet, endnu mere alvorligt problem, er replikering. Hvis du udfører en ikke-blokerende operation, som kræver en tabelgenopbygning, vil den faktisk ikke låse DML'er, men dette er kun sandt på masteren. Lad os antage, at en sådan DDL tog 30 minutter at fuldføre - ALTER-hastigheden afhænger af hardwaren, men det er ret almindeligt at se sådanne eksekveringstider på tabeller med en størrelse på 20 GB. Den replikeres derefter til alle slaver, og fra det øjeblik, DDL starter på disse slaver, vil replikering vente på, at den er fuldført. Det er ligegyldigt, om du bruger MySQL eller MariaDB, eller om du har multi-threaded replikering. Slaver vil halte - de vil vente de 30 minutter på, at DDL'en er færdig, før de begynder at anvende de resterende binlog-begivenheder. Som du kan forestille dig, er 30 minutters forsinkelse (nogle gange vil endda 30 sekunder ikke være acceptabelt - det hele afhænger af applikationen) noget, der gør det umuligt at bruge disse slaver til udskalering. Selvfølgelig er der løsninger - du kan udføre skemaændringer fra bunden til toppen af replikeringskæden, men dette begrænser i høj grad dine muligheder. Især hvis du bruger rækkebaseret replikering, kan du kun udføre kompatible skemaændringer på denne måde. Et par eksempler på begrænsninger af rækkebaseret replikering; du kan ikke slippe nogen kolonne, der ikke er den sidste, du kan ikke tilføje en kolonne til en anden position end den sidste. Du kan ikke også ændre kolonnetype (f.eks. INT -> VARCHAR).
Som du kan se, tilføjer replikering kompleksitet til, hvordan du kan udføre skemaændringer. Operationer, der er ikke-blokerende på den selvstændige vært, bliver blokerende, mens de udføres på slaver. Lad os tage et kig på et par metoder, du kan bruge til at minimere virkningen af skemaændringer.
Online skemaændringsværktøjer
Som vi nævnte tidligere, er der værktøjer, som er beregnet til at udføre skemaændringer. De mest populære er pt-online-schema-change skabt af Percona og gh-ost, skabt af GitHub. I en række blogindlæg sammenlignede vi dem og diskuterede, hvordan gh-ost kan bruges til at udføre skemaændringer, og hvordan du kan drosle og omkonfigurere en igangværende migrering. Her vil vi ikke gå i detaljer, men vi vil alligevel gerne nævne nogle af de vigtigste aspekter ved at bruge disse værktøjer. For det første vil en skemaændring, der udføres gennem pt-osc eller gh-ost, ske på alle databasenoder på én gang. Der er ingen som helst forsinkelse med hensyn til, hvornår ændringen vil blive anvendt. Dette gør det muligt at bruge disse værktøjer selv til skemaændringer, der er inkompatible med rækkebaseret replikering. De nøjagtige mekanismer for, hvordan disse værktøjer sporer ændringer på bordet, er forskellige (triggere i pt-osc vs. binlog-parsing i gh-ost), men hovedideen er den samme - en ny tabel oprettes med det ønskede skema, og eksisterende data er kopieret fra den gamle tabel. I mellemtiden spores DML'er (på den ene eller den anden måde) og anvendes på den nye tabel. Når alle data er migreret, omdøbes tabeller, og den nye tabel erstatter den gamle. Dette er atomoperation, så det er ikke synligt for applikationen. Begge værktøjer har en mulighed for at drosle belastningen og sætte driften på pause. Gh-ost kan stoppe al aktivitet, kun pt-osc kan stoppe processen med at kopiere data mellem gammel og ny tabel - triggere forbliver aktive, og de vil fortsætte med at duplikere data, hvilket tilføjer nogle overhead. På grund af omdøbningstabellen har begge værktøjer nogle begrænsninger med hensyn til fremmednøgler - ikke understøttet af gh-ost, delvist understøttet af pt-osc enten gennem almindelig ALTER, hvilket kan forårsage replikeringsforsinkelse (ikke muligt, hvis den underordnede tabel er stor) eller ved at droppe den gamle tabel, før du omdøber den nye - det er farligt, da der ikke er nogen måde at rulle tilbage, hvis data af en eller anden grund ikke blev kopieret til den nye tabel korrekt. Udløsere er også vanskelige at understøtte.
De er ikke understøttet i gh-ost, pt-osc i MySQL 5.7 og nyere har begrænset understøttelse af tabeller med eksisterende triggere. Andre vigtige begrænsninger for online skemaændringsværktøjer er, at en unik eller primær nøgle skal eksistere i tabellen. Det bruges til at identificere rækker, der skal kopieres mellem gamle og nye tabeller. Disse værktøjer er også meget langsommere end direkte ALTER - en ændring, der tager timer, mens du kører ALTER, kan tage dage, når den udføres med pt-osc eller gh-ost.
På den anden side, som vi nævnte, så længe kravene er opfyldt, og begrænsninger ikke kommer i spil, kan du køre alle skemaændringer ved at bruge et af værktøjerne. Alt vil ske på samme tid på alle værter, så du behøver ikke bekymre dig om kompatibilitet. Du har også en vis grad af kontrol over, hvordan processen udføres (mindre i pt-osc, meget mere i gh-ost).
Du kan reducere virkningen af skemaændringen, du kan sætte dem på pause og kun lade dem køre under overvågning, du kan teste ændringen, før du rent faktisk udfører den. Du kan få dem til at spore replikeringsforsinkelse og pause, hvis en påvirkning skulle opdages. Dette gør disse værktøjer til en rigtig god tilføjelse til DBA's arsenal, mens du arbejder med MySQL-replikering.
Rullende skemaændringer
Typisk vil en DBA bruge et af de online skemaændringsværktøjer. Men som vi diskuterede tidligere, kan de under nogle omstændigheder ikke bruges, og en direkte ændring er den eneste levedygtige mulighed. Hvis vi taler om selvstændig MySQL, har du intet valg - hvis ændringen er ikke-blokerende, er det godt. Hvis det ikke er, så er der ikke noget du kan gøre ved det. Men så er det ikke så mange mennesker, der kører MySQL som enkeltforekomster, vel? Hvad med replikering? Som vi diskuterede tidligere, er direkte ændring på masteren ikke mulig - i de fleste tilfælde vil det forårsage forsinkelse på slaven, og dette er muligvis ikke acceptabelt. Hvad der dog kan gøres, er at udføre ændringen på en rullende måde. Du kan starte med slaver og, når ændringen er anvendt på dem alle, fremme en af slaverne som en ny mester, degradere den gamle mester til en slave og udføre ændringen på den. Selvfølgelig skal ændringen være kompatibel, men for at sige sandheden er de mest almindelige tilfælde, hvor du ikke kan bruge online skemaændringer, på grund af mangel på primær eller unik nøgle. For alle andre tilfælde er der en form for løsning, især i pt-online-schema-change, da gh-ost har mere hårde begrænsninger. Det er en løsning, du ville kalde "så så" eller "langt fra ideel", men det vil gøre jobbet, hvis du ikke har andre muligheder at vælge imellem. Hvad der også er vigtigt, de fleste af begrænsningerne kan undgås, hvis du overvåger dit skema og fanger problemerne, før tabellen vokser. Selvom nogen opretter en tabel uden en primær nøgle, er det ikke et problem at køre en direkte ændring, som tager et halvt sekund eller mindre, da tabellen næsten er tom.
Hvis det vokser, vil det blive et alvorligt problem, men det er op til DBA at fange den slags problemer, før de rent faktisk begynder at skabe problemer. Vi vil dække nogle tips og tricks til, hvordan du sikrer dig, at du fanger sådanne problemer til tiden. Vi vil også dele generiske tips om, hvordan du designer dine skemaer.
Tips og tricks
Skemadesign
Som vi viste i dette indlæg, er online skemaændringsværktøjer ret vigtige, når du arbejder med en replikeringsopsætning, derfor er det ret vigtigt at sørge for, at dit skema er designet på en sådan måde, at det ikke vil begrænse dine muligheder for at udføre skemaændringer. Der er tre vigtige aspekter. For det første skal primær eller unik nøgle eksistere - du skal sikre dig, at der ikke er nogen tabeller uden en primær nøgle i din database. Du bør overvåge dette regelmæssigt, ellers kan det blive et alvorligt problem i fremtiden. For det andet bør du seriøst overveje, om det er en god idé at bruge fremmednøgler. Sikker på, de har deres anvendelser, men de tilføjer også overhead til din database, og de kan gøre det problematisk at bruge online skemaændringsværktøjer. Relationer kan håndhæves af ansøgningen. Selvom det betyder mere arbejde, kan det stadig være en bedre idé end at begynde at bruge fremmednøgler og være stærkt begrænset til, hvilke typer skemaændringer der kan udføres. For det tredje udløser. Samme historie som med fremmednøgler. De er en god funktion at have, men de kan blive en byrde. Du skal seriøst overveje, om gevinsterne ved at bruge dem opvejer de begrænsninger, de udgør.
Sporing af skemaændringer
Styring af skemaændringer handler ikke kun om at køre skemaændringer. Du skal også være på toppen af din skemastruktur, især hvis du ikke er den eneste, der foretager ændringerne.
ClusterControl giver brugerne værktøjer til at spore nogle af de mest almindelige skemadesignproblemer. Det kan hjælpe dig med at spore tabeller, der ikke har primærnøgler:
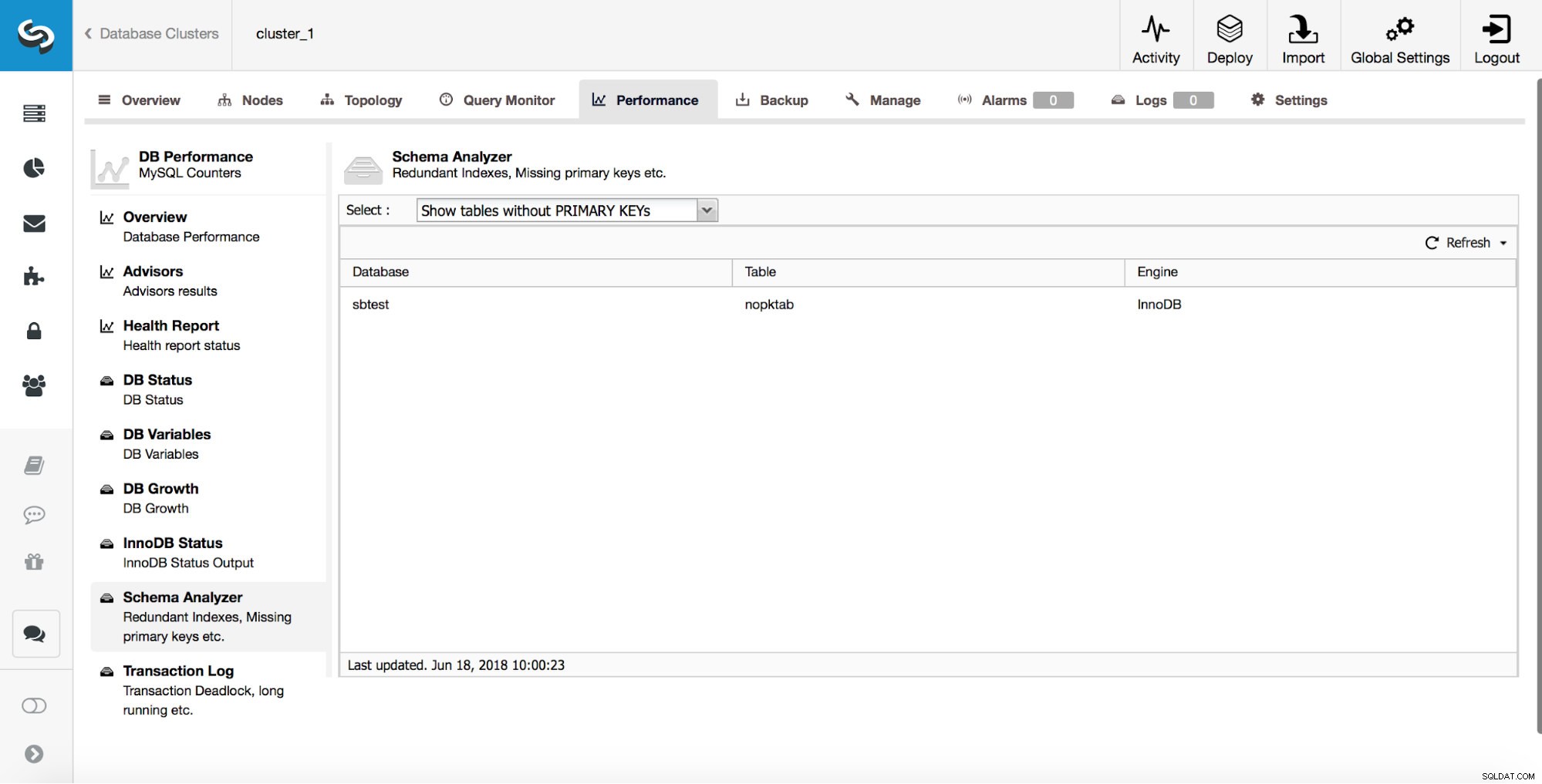
Som vi diskuterede tidligere, er det meget vigtigt at fange sådanne tabeller tidligt, da primærnøgler skal tilføjes ved hjælp af direkte ændring.
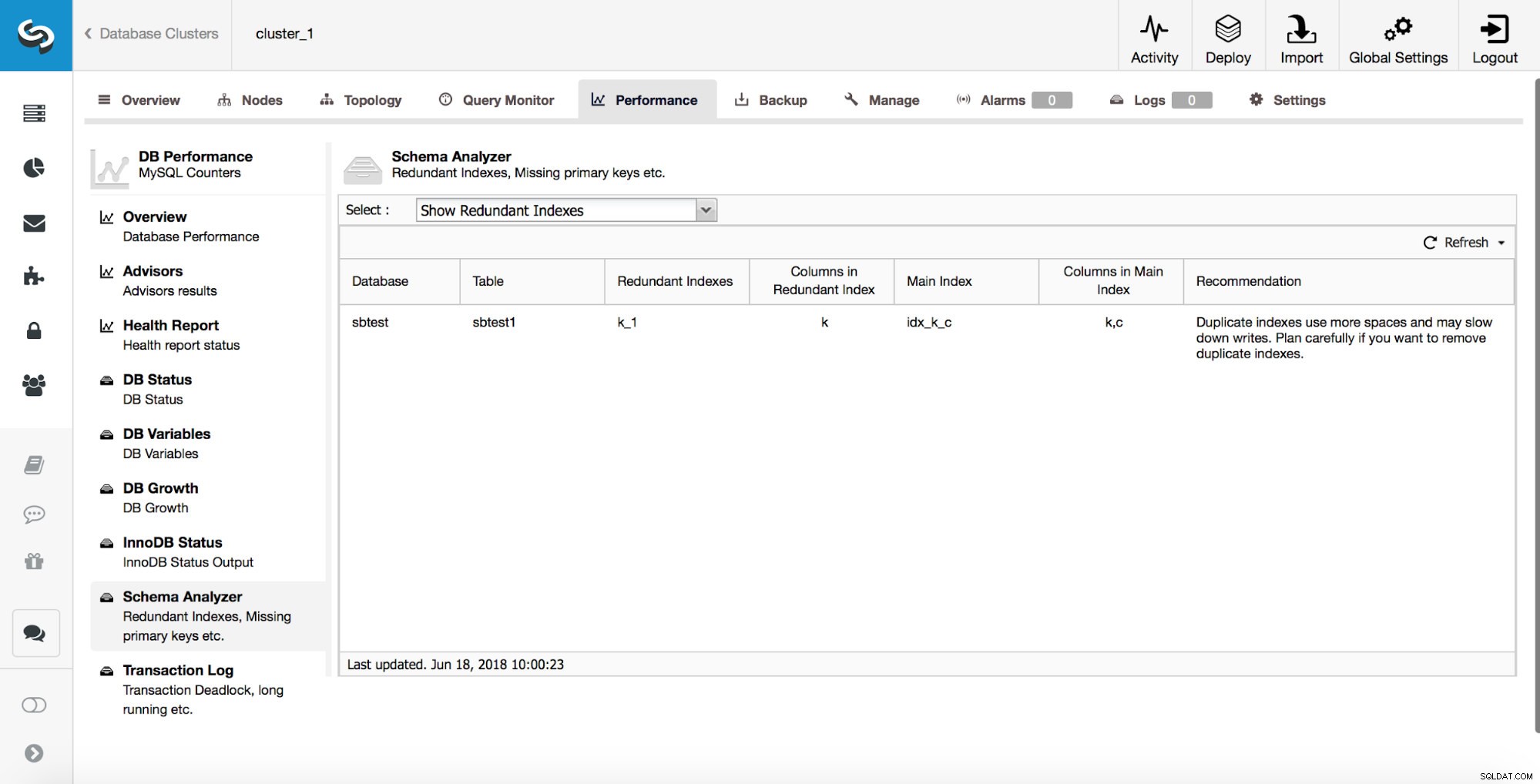
ClusterControl kan også hjælpe dig med at spore duplikerede indekser. Typisk vil du ikke have flere indekser, som er overflødige. I eksemplet ovenfor kan du se, at der er et indeks på (k, c), og der er også et indeks på (k). Enhver forespørgsel, der kan bruge indeks oprettet på kolonne 'k', kan også bruge et sammensat indeks oprettet på kolonner (k, c). Der er tilfælde, hvor det er fordelagtigt at holde overflødige indekser, men du er nødt til at gribe det an fra sag til sag. Med udgangspunkt i MySQL 8.0 er det muligt hurtigt at teste, om et indeks virkelig er nødvendigt eller ej. Du kan gøre et redundant indeks 'usynligt' ved at køre:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Dette vil få MySQL til at ignorere det indeks, og gennem overvågning kan du kontrollere, om der var nogen negativ indvirkning på databasens ydeevne. Hvis alt fungerer som planlagt i nogen tid (et par dage eller endda uger), kan du planlægge at fjerne det overflødige indeks. Hvis du opdager, at noget ikke er rigtigt, kan du altid genaktivere dette indeks ved at køre:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Disse handlinger er øjeblikkelige, og indekset er der hele tiden og opretholdes stadig - det er kun, at det ikke vil blive taget i betragtning af optimeringsværktøjet. Takket være denne mulighed vil fjernelse af indekser i MySQL 8.0 være meget mere sikker drift. I de tidligere versioner kunne det tage timer, hvis ikke dage på store borde, at tilføje et forkert fjernet indeks igen.
ClusterControl kan også fortælle dig om MyISAM-tabeller.
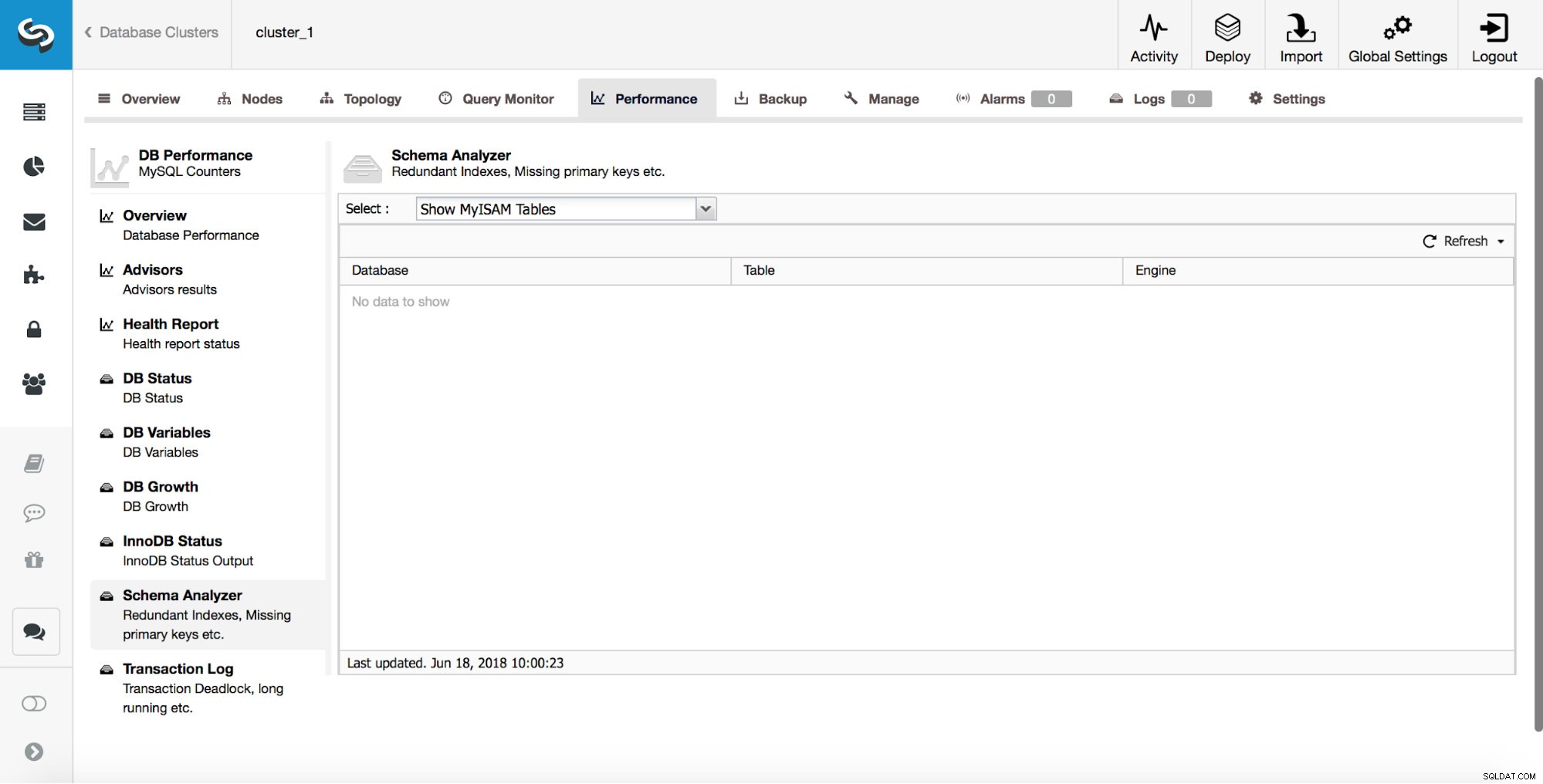
Selvom MyISAM stadig kan have sine anvendelser, skal du huske på, at det ikke er en transaktionslagringsmotor. Som sådan kan det nemt indføre datainkonsistens mellem noder i en replikeringsopsætning.
En anden meget nyttig funktion ved ClusterControl er en af driftsrapporterne - en Schema Change Report.
I en ideel verden gennemgår, godkender og implementerer en DBA alle skemaændringer. Det er desværre ikke altid tilfældet. En sådan gennemgangsproces går bare ikke godt med agil udvikling. Ud over det er Developer-to-DBA ratio typisk ret høj, hvilket også kan blive et problem, da DBA'er ville kæmpe for ikke at blive en flaskehals. Derfor er det ikke ualmindeligt at se skemaændringer udføres uden for DBA’s viden. Alligevel er DBA normalt den, der er ansvarlig for databasens ydeevne og stabilitet. Takket være skemaændringsrapporten kan de nu holde styr på skemaændringerne.
I første omgang er der behov for en vis konfiguration. I en konfigurationsfil for en given klynge (/etc/cmon.d/cmon_X.cnf), skal du definere, på hvilken vært ClusterControl skal spore ændringerne, og hvilke skemaer der skal kontrolleres.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestNår det er gjort, kan du planlægge en rapport, der skal udføres på regelmæssig basis. Et eksempel på output kan være som nedenfor:
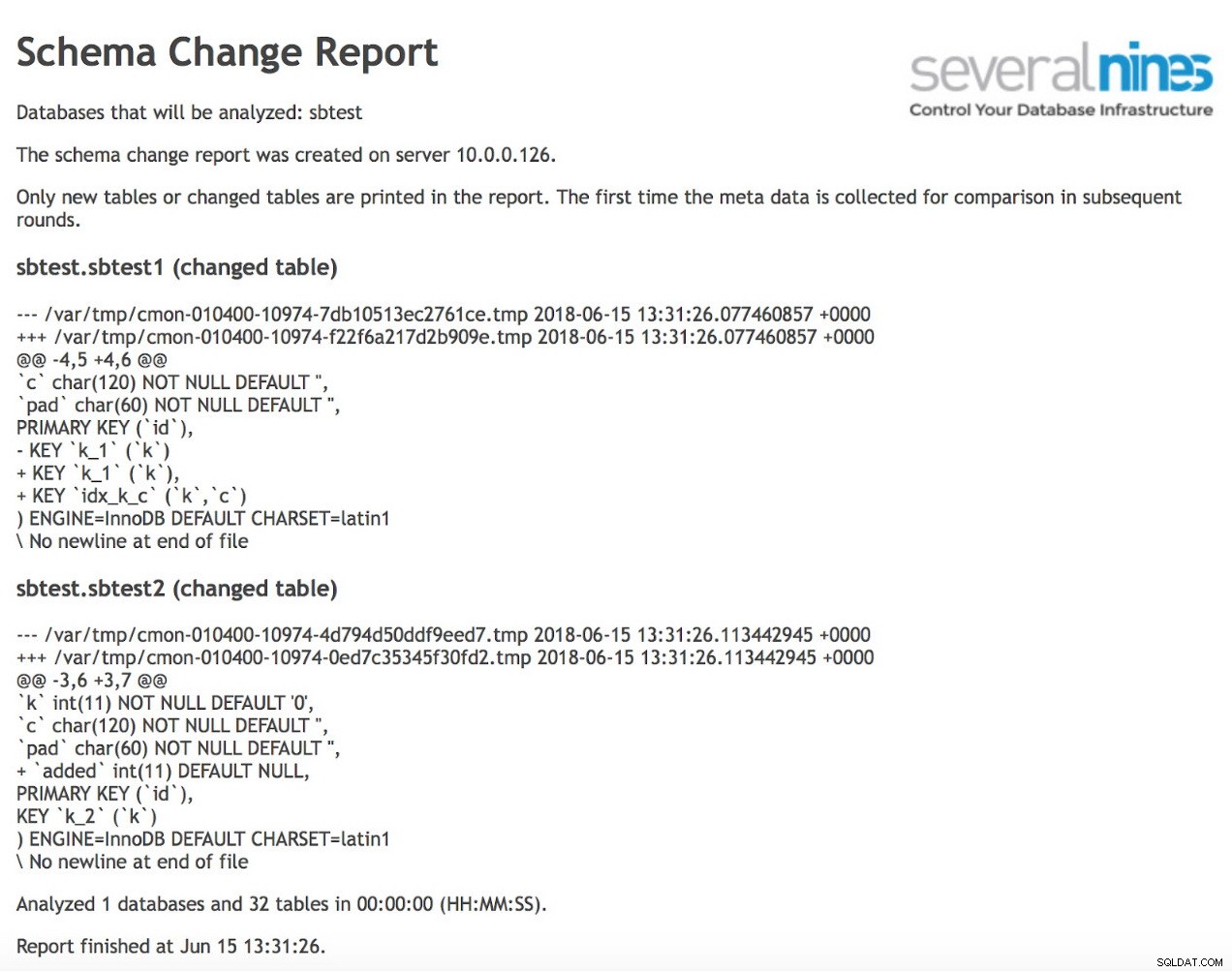
Som du kan se, er to tabeller ændret siden den forrige kørsel af rapporten. I den første er der oprettet et nyt sammensat indeks på kolonner (k, c). I den anden tabel blev der tilføjet en kolonne.
I den efterfølgende kørsel fik vi information om ny tabel, som blev oprettet uden indeks eller primær nøgle. Ved at bruge denne form for information kan vi nemt handle, når det er nødvendigt, og løse problemerne, før de rent faktisk begynder at blive blokere.