En af de mest populære måder at opnå høj tilgængelighed for MySQL på er replikering. Replikation har eksisteret i mange år, og blev meget mere stabil med introduktionen af GTID'er. Men selv med disse forbedringer kan replikeringsprocessen gå i stykker af forskellige årsager - for eksempel når master og slave er ude af synkronisering, fordi skrivninger blev sendt direkte til slaven. Hvordan fejlfinder du replikeringsproblemer, og hvordan løser du dem?
I dette blogindlæg vil vi diskutere nogle af de almindelige problemer med replikering, og hvordan man løser dem med ClusterControl. Lad os starte med den første.
Replikering stoppet med en fejl
De fleste MySQL DBA'er vil typisk se denne type problemer mindst én gang i deres karriere. Af forskellige årsager kan en slave blive beskadiget eller måske stoppet med at synkronisere med masteren. Når dette sker, er den første ting at gøre for at starte fejlfindingen at tjekke fejlloggen for meddelelser. Det meste af tiden er fejlmeddelelsen let at spore i fejlloggen eller ved at køre VIS SLAVE STATUS-forespørgslen.
Lad os tage et kig på følgende eksempel fra VIS STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Vi kan tydeligt se fejlen er relateret til Fik fatal fejl 1236 fra master ved læsning af data fra binær log:'Kunne ikke finde GTID-tilstand anmodet af slave i nogen binlog-filer. Sandsynligvis er slavetilstanden for gammel og nødvendige binlogfiler er blevet slettet.'. Med ord, hvad fejlen fortæller os i det væsentlige er, at der er inkonsistens i data, og de nødvendige binære logfiler er allerede blevet slettet.
Dette er et godt eksempel, hvor replikeringsprocessen holder op med at virke. Udover VIS SLAVESTATUS kan du også spore status på fanen "Oversigt" for klyngen i ClusterControl. Så hvordan løser man dette med ClusterControl? Du har to muligheder at prøve:
-
Du kan prøve at starte slaven igen fra "Node Action"
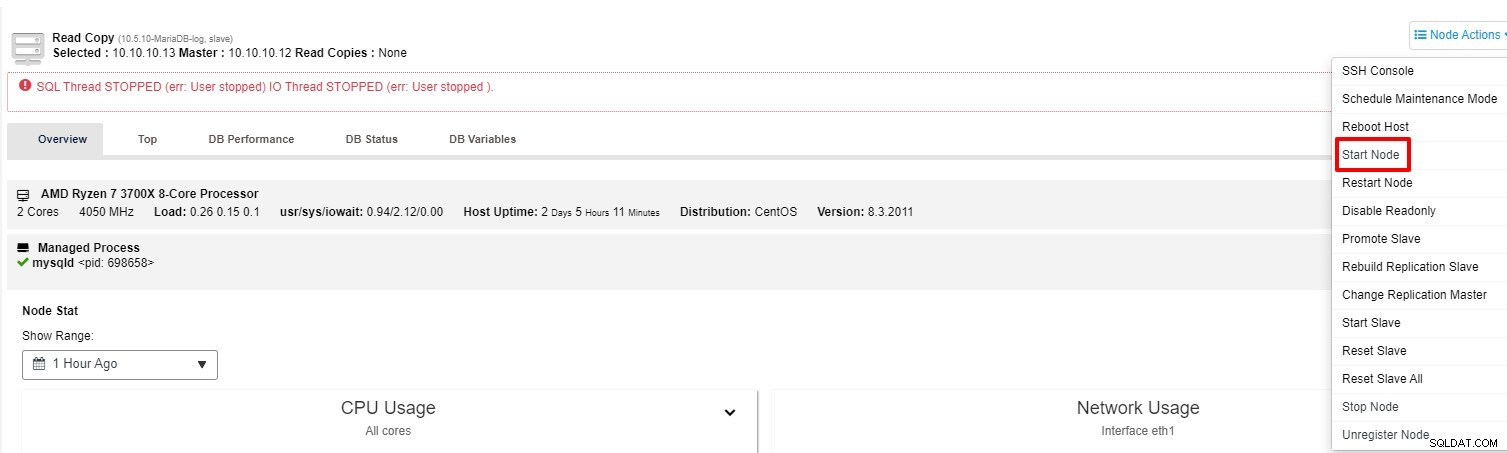
-
Hvis slaven stadig ikke fungerer, kan du køre "Rebuild Replication Slave" job fra "Node Action"
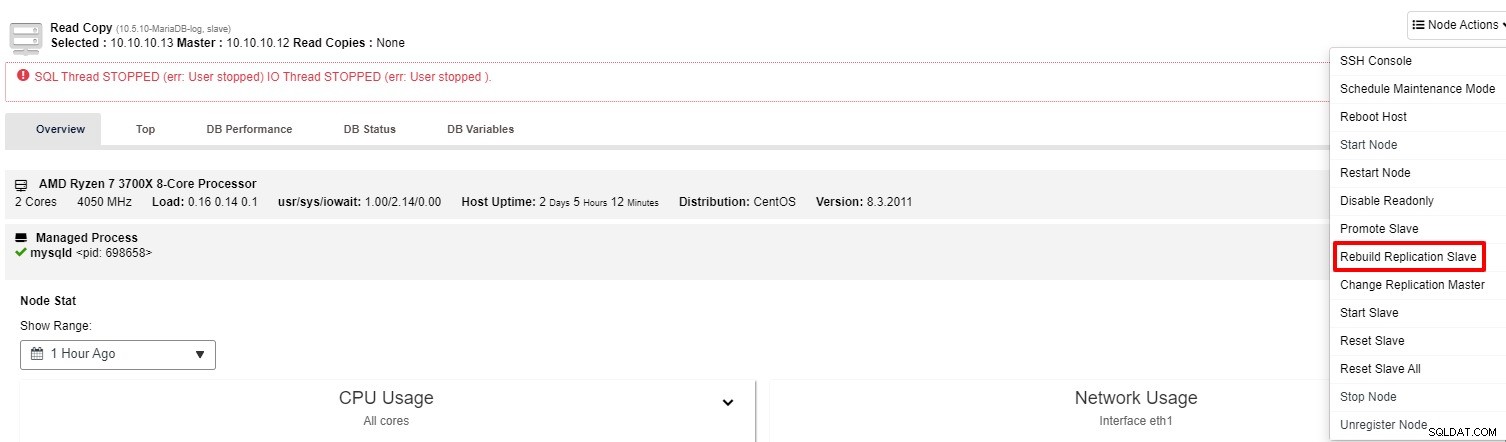
For det meste vil den anden mulighed løse problemet. ClusterControl tager en sikkerhedskopi af masteren og genopbygger den ødelagte slave ved at gendanne dataene. Når dataene er gendannet, forbindes slaven til masteren, så den kan indhente det.
Der er også flere manuelle måder at genopbygge slave på som anført nedenfor. Du kan også henvise til dette link for flere detaljer:
-
Brug af Mysqldump til at genopbygge en inkonsekvent MySQL-slave
-
Brug af Mydumper til at genopbygge en inkonsekvent MySQL-slave
-
Brug af et snapshot til at genopbygge en inkonsekvent MySQL-slave
-
Brug af en Xtrabackup eller Mariabackup til at genopbygge en inkonsekvent MySQL-slave
Promover en slave til at blive en mester
Over tid skal operativsystemet eller databasen lappes eller opgraderes for at opretholde stabilitet og sikkerhed. En af de bedste fremgangsmåder til at minimere nedetiden, især for en større opgradering, er at promovere en af de slaver, der skal mestres, efter at opgraderingen er gennemført på den pågældende node.
Ved at udføre dette kan du pege din applikation til den nye master, og master-slave-replikeringen vil fortsætte med at fungere. I mellemtiden kunne du også fortsætte med opgraderingen på den gamle master med ro i sindet. Med ClusterControl kan dette udføres med nogle få klik, kun forudsat at replikeringen er konfigureret som Global Transaction ID-baseret eller GTID-baseret for kort. For at undgå tab af data er det værd at stoppe alle applikationsforespørgsler, hvis den gamle master fungerer korrekt. Dette er ikke den eneste situation, hvor du kan promovere slaven. I tilfælde af at masternoden er nede, kan du også udføre denne handling.
Uden ClusterControl er der et par trin til at promovere slaven. Hvert af trinene kræver også et par forespørgsler for at køre:
-
Fjern masteren manuelt
-
Vælg den mest avancerede slave til at være mester, og forbered den
-
Forbind andre slaver igen til den nye master
-
Ændring af den gamle herre til at være slave
Alligevel er trinene til at promovere slave med ClusterControl kun et par klik:Cluster> Noder> vælg slaveknude> Promoter slave som på skærmbilledet nedenfor:
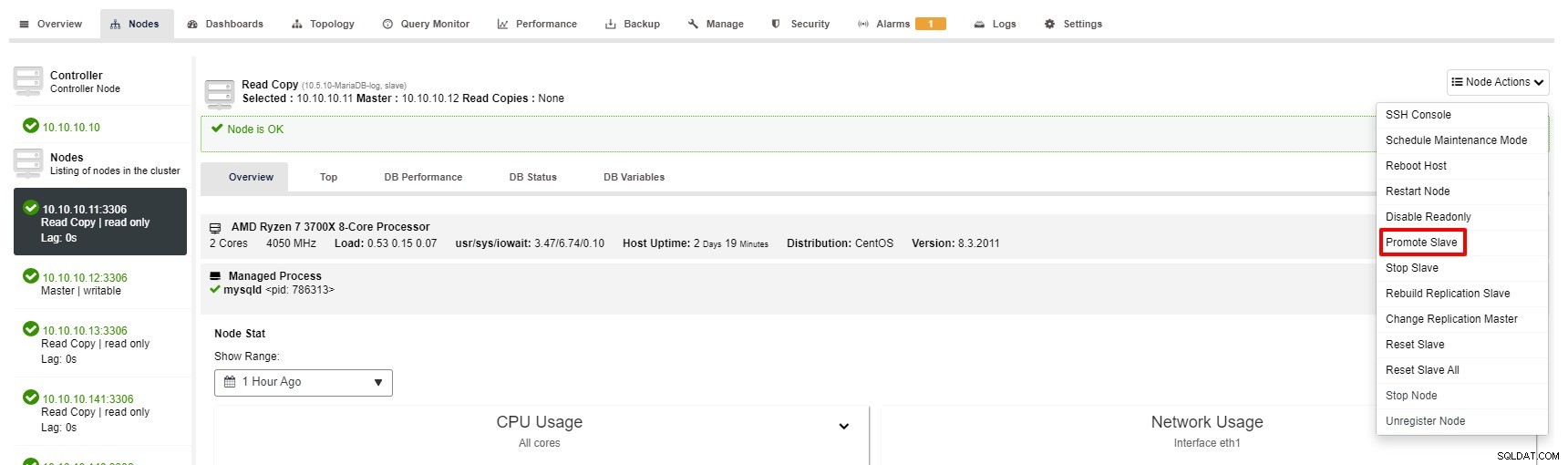
Master bliver utilgængelig
Forestil dig, at du har store transaktioner at køre, men databasen er nede. Det er lige meget hvor forsigtig du er, dette er sandsynligvis den mest alvorlige eller kritiske situation for en replikeringsopsætning. Når dette sker, er din database ikke i stand til at acceptere en enkelt skrivning, hvilket er dårligt. Desuden vil din(e) ansøgning(er) selvfølgelig ikke fungere korrekt.
Der er et par årsager eller årsager, der fører til dette problem. Nogle af eksemplerne er hardwarefejl, OS-korruption, databasekorruption og så videre. Som DBA skal du handle hurtigt for at gendanne masterdatabasen.
Takket være "Auto Recovery"-klyngefunktionen, der er tilgængelig i ClusterControl, kan failover-processen automatiseres. Det kan aktiveres eller deaktiveres med et enkelt klik. Som navnet siger, er det, det vil gøre, at bringe hele klyngetopologien op, når det er nødvendigt. For eksempel skal en master-slave-replikation have mindst én master i live på et givet tidspunkt, uanset antallet af tilgængelige slaver. Når masteren ikke er tilgængelig, vil den automatisk promovere en af slaverne.
Lad os tage et kig på skærmbilledet nedenfor:
I ovenstående skærmbillede kan vi se, at "Auto Recovery" er aktiveret for både Cluster og Node. I topologien skal du bemærke, at den aktuelle master-IP-adresse er 10.10.10.11. Hvad vil der ske, hvis vi fjerner masterknuden til testformål?
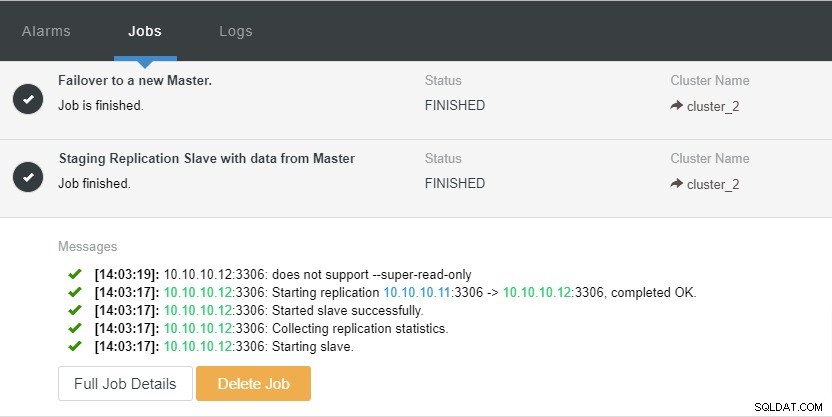
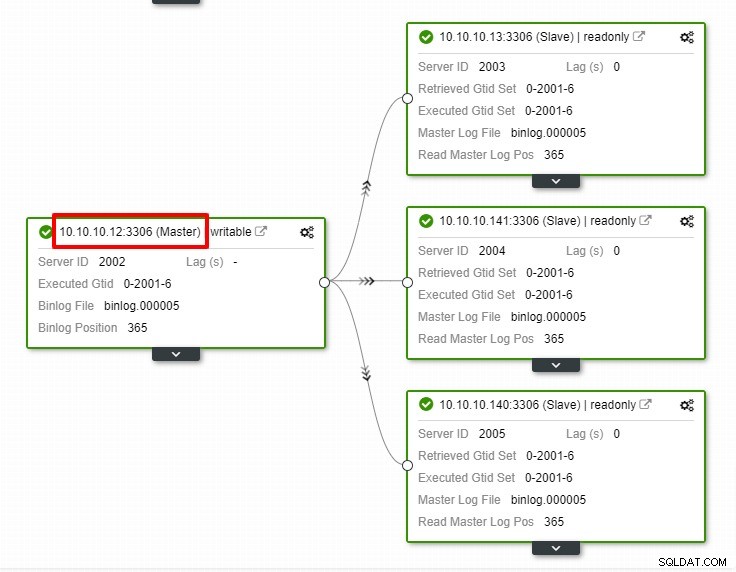
Som du kan se, er slavenoden med IP 10.10.10.12 automatisk forfremmet til master, så replikeringstopologien omkonfigureres. I stedet for at gøre det manuelt, hvilket naturligvis vil involvere en masse trin, hjælper ClusterControl dig med at vedligeholde din replikeringsopsætning ved at tage besværet fra dine hænder.
Konklusion
I enhver uheldig begivenhed med din replikering, er rettelsen meget enkel og mindre besvær med ClusterControl. ClusterControl hjælper dig med at genoprette dine replikeringsproblemer hurtigt, hvilket øger oppetiden for dine databaser.