Vigtigheden af failover
Failover er en af de vigtigste databasepraksis for databasestyring. Det er nyttigt ikke kun, når du administrerer store databaser i produktionen, men også hvis du vil være sikker på, at dit system altid er tilgængeligt, når du har adgang til det - især på applikationsniveau.
Før en failover kan finde sted, skal dine databaseforekomster opfylde visse krav. Disse krav er faktisk meget vigtige for høj tilgængelighed. Et af kravene, som dine databaseinstanser skal opfylde, er redundans. Redundans gør det muligt for failover at fortsætte, hvor redundansen er sat op til at have en failover-kandidat, som kan være en replika (sekundær) node eller fra en pulje af replikaer, der fungerer som standby eller hot-standby noder. Kandidaten vælges enten manuelt eller automatisk baseret på den mest avancerede eller opdaterede node. Normalt vil du have en hot-standby-replika, da den kan redde din database fra at trække indekser fra disken, da en hot-standby ofte udfylder indekser i databasebufferpuljen.
Failover er det udtryk, der bruges til at beskrive, at en gendannelsesproces har fundet sted. Før gendannelsesprocessen sker dette, når en primær (eller master) databaseknude svigter efter et nedbrud, efter naturkatastrofer, efter en hardwarefejl, eller den kan have været udsat for en netværksopdeling; disse er de mest almindelige tilfælde, hvorfor en failover kan finde sted. Gendannelsesprocessen fortsætter normalt automatisk og søger derefter efter den mest ønskede og opdaterede sekundære (replika) som tidligere nævnt.
Avanceret failover
Selvom gendannelsesprocessen under en failover er automatisk, er der visse tilfælde, hvor det ikke er nødvendigt at automatisere processen, og en manuel proces skal tage over. Kompleksitet er ofte den vigtigste overvejelse forbundet med teknologierne, der omfatter hele stakken af din database - automatisk failover kan også blandes med manuel failover.
I de fleste daglige overvejelser med administration af databaser er størstedelen af bekymringerne omkring den automatiske failover virkelig ikke trivielle. Det er ofte praktisk at implementere og konfigurere en automatisk failover, hvis der opstår problemer. Selvom det lyder lovende, da det dækker kompleksiteter, kommer der de avancerede failover-mekanismer, og det involverer "før"-hændelser og "post-hændelser", som er bundet som kroge i en failover-software eller -teknologi.
Disse før- og posthændelser kommer med enten kontroller eller visse handlinger, der skal udføres, før det endelig kan fortsætte med failover, og efter en failover er udført, nogle oprydninger for at sikre, at failover endelig er en succes en. Heldigvis er der tilgængelige værktøjer, som ikke kun tillader automatisk failover, men som også giver mulighed for at anvende pre- og post-script-hooks.
I denne blog vil vi bruge ClusterControl (CC) automatisk failover og vil forklare, hvordan man bruger pre- og post-script-hooks, og hvilken klynge de gælder for.
ClusterControl Replication Failover
ClusterControl-failovermekanismen er effektivt anvendelig over asynkron replikering, som er anvendelig til MySQL-varianter (MySQL/Percona Server/MariaDB). Det gælder også for PostgreSQL/TimescaleDB-klynger - ClusterControl understøtter streamingreplikering. MongoDB- og Galera-klynger har sin egen mekanisme til automatisk failover indbygget i sin egen databaseteknologi. Læs mere om, hvordan ClusterControl udfører automatisk databasegendannelse og failover.
ClusterControl-failover virker ikke, medmindre Node- og Cluster-gendannelsen (Auto Recovery er aktiveret). Det betyder, at disse knapper skal være grønne.

Dokumentationen angiver, at disse konfigurationsmuligheder også kan bruges til at aktivere / deaktiver følgende:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl genstart cmon
For denne blog fokuserer vi hovedsageligt på, hvordan man bruger pre/post script-hooks, hvilket i bund og grund er en stor fordel for avanceret replikeringsfailover.
Cluster failover-replikering før/efter script-understøttelse
Som tidligere nævnt understøtter MySQL-varianter, der bruger asynkron (inklusive semi-synkron) replikering og streaming replikering til PostgreSQL/TimescaleDB denne mekanisme. ClusterControl har følgende konfigurationsmuligheder, som kan bruges til pre og post script hooks. Dybest set kan disse konfigurationsmuligheder indstilles via deres konfigurationsfiler eller kan indstilles via web-brugergrænsefladen (vi vil behandle dette senere).
Vores dokumentation angiver, at disse er følgende konfigurationsmuligheder, der kan ændre failover-mekanismen ved at bruge pre/post script-hooks:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Teknisk, når du har indstillet følgende konfigurationsindstillinger i din /etc/cmon.d/cmon_
$ systemctl restart cmonAlternativt kan du også indstille konfigurationsmulighederne ved at gå til
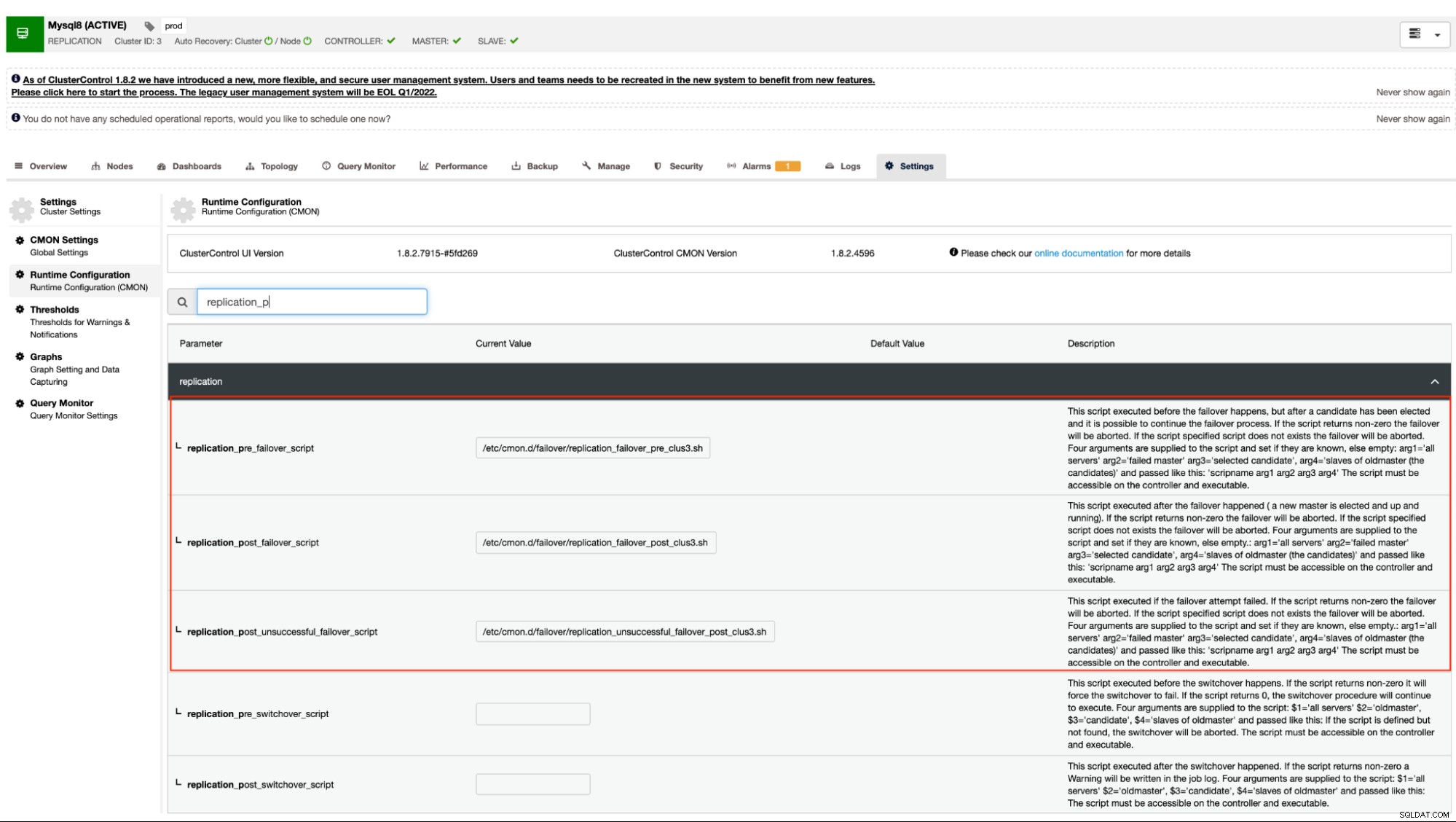
Denne tilgang vil stadig kræve en genstart til cmon-tjenesten, før den kan afspejle ændringer foretaget for disse konfigurationsmuligheder for pre/post script hooks.
Eksempel på pre/post script hooks
Ideelt set er pre/post script-hooks dedikeret, når du har brug for en avanceret failover, som ClusterControl ikke kunne håndtere kompleksiteten af din databaseopsætning til. For eksempel, hvis du kører forskellige datacentre med skærpet sikkerhed, og du vil afgøre, om alarmen om, at netværket ikke kan nås, ikke er en falsk positiv alarm. Den skal kontrollere, om den primære og slaven kan nå hinanden og omvendt, og den kan også nå fra databasenoderne, der går til ClusterControl-værten.
Lad os gøre det i vores eksempel og demonstrere, hvordan du kan drage fordel af det.
Serverdetaljer og scripts
I dette eksempel bruger jeg en MariaDB-replikeringsklynge med kun en primær og en replika. Administreret af ClusterControl til at administrere failover.
ClusterControl =192.168.40.110
primær (debnode5) =192.168.30.50
replika (debnode9) =192.168.30.90
I den primære node skal du oprette scriptet som angivet nedenfor,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Sørg for, at /opt/pre_failover.sh er eksekverbar, dvs.
$ chmod +x /opt/pre_failover.shBrug derefter dette script til at blive involveret via cron. I dette eksempel oprettede jeg en fil /etc/cron.d/ccfailover og har følgende indhold:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shI din replika skal du blot bruge følgende trin, vi gjorde for den primære, bortset fra at ændre værtsnavnet. Se følgende af, hvad jeg har nedenfor i min replika:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"og sørg for, at scriptet, der påberåbes i vores cron, er eksekverbart,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl før/efter scripts
I denne demonstration er mit cluster_id 3. Som nævnt tidligere i vores dokumentation, kræver det, at disse scripts skal ligge i vores CC-controller-vært. Så i min /etc/cmon.d/cmon_3.cnf har jeg følgende:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shMen det følgende "pre" failover-script bestemmer, om begge noder var i stand til at nå CC-controllerværten. Se følgende:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demo af failover
Lad os nu prøve at simulere netværksudfald på den primære node og se, hvordan den vil reagere. I min primære node fjerner jeg netværksgrænsefladen, der bruges til at kommunikere med replikaen og CC-controlleren.
example@sqldat.com:~# ip link set enp0s8 downUnder det første forsøg på failover var CC i stand til at køre mit præscript, som er placeret på /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Se nedenfor, hvordan det virker:
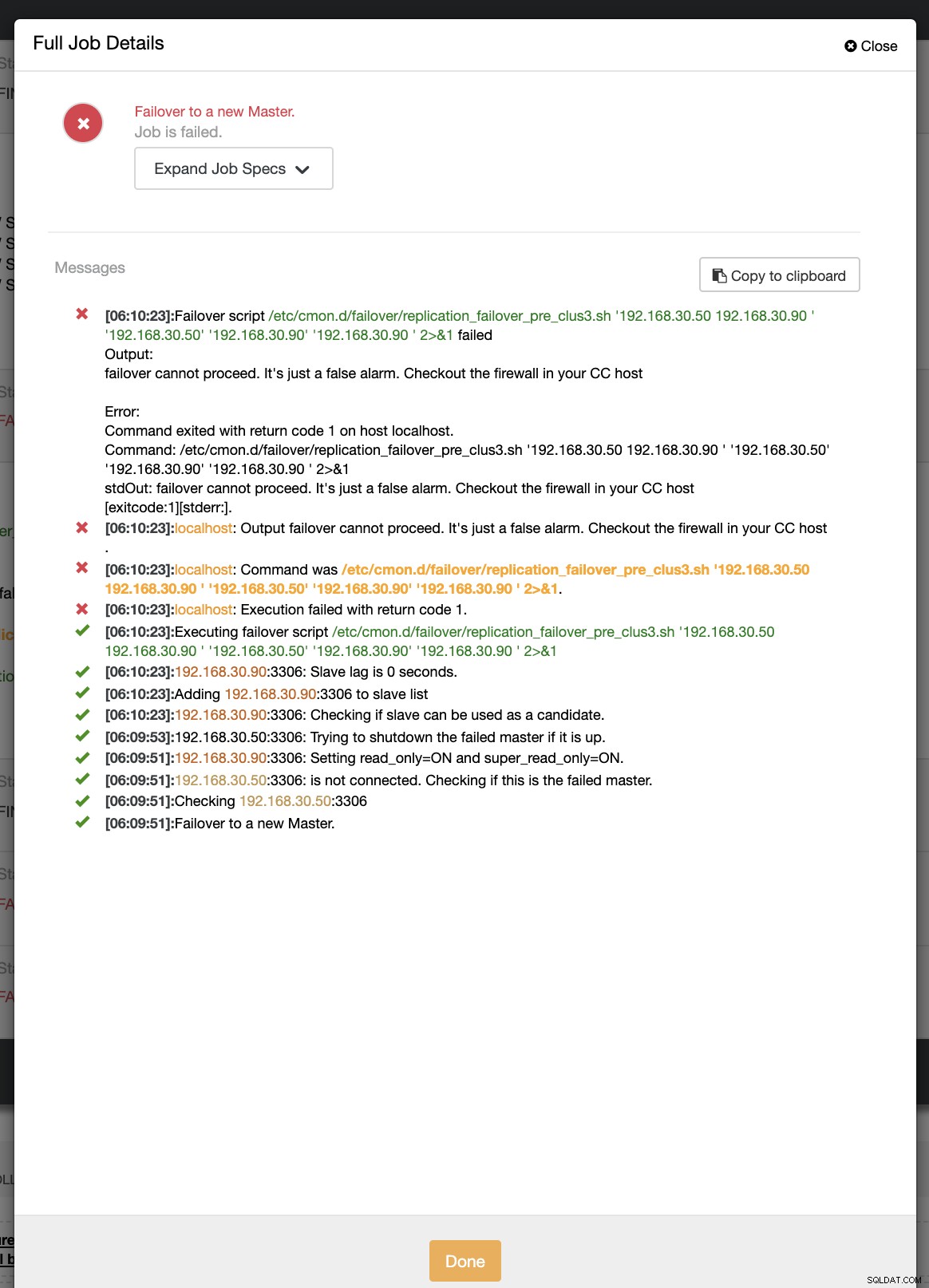
Det mislykkes naturligvis, fordi tidsstemplet, der er blevet logget, endnu ikke er mere end et minut, eller det var blot et par sekunder siden, at den primære stadig var i stand til at oprette forbindelse til CC-controlleren. Det er naturligvis ikke den perfekte tilgang, når du har at gøre med et rigtigt scenarie. ClusterControl var dog i stand til at påkalde og udføre scriptet perfekt som forventet. Hvad med, hvis den faktisk når mere end et minut (dvs.> 60 sekunder)?
I vores andet forsøg på failover, da tidsstemplet når mere end 60 sekunder, anses det for at være et sandt positivt resultat, og det betyder, at vi skal failover som tilsigtet. CC har været i stand til at udføre det perfekt og endda eksekvere postscriptet efter hensigten. Dette kan ses i jobloggen. Se skærmbilledet nedenfor:
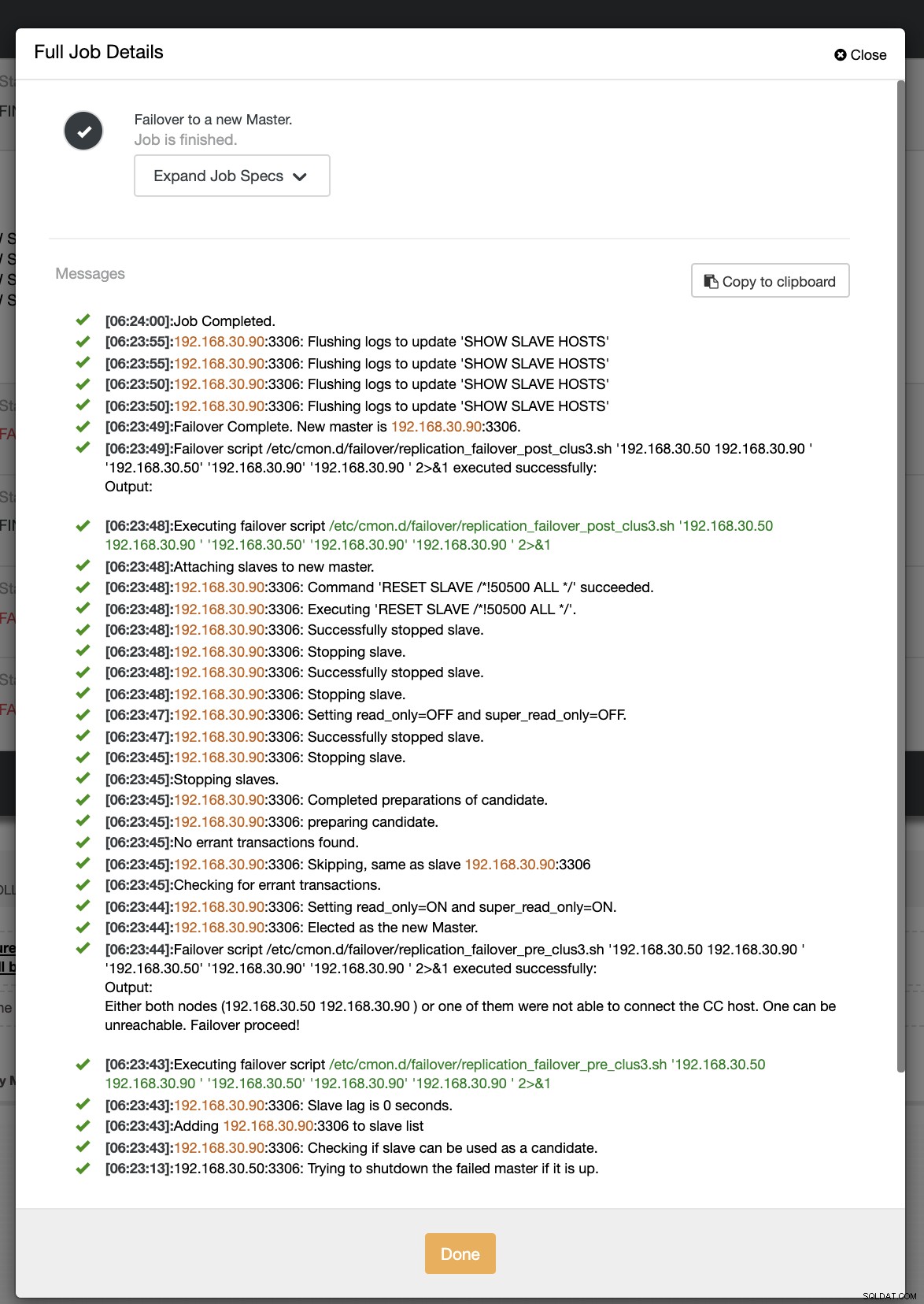
Ved at bekræfte, om mit indlægsscript blev kørt, var det i stand til at oprette loggen fil i CC /tmp-mappen som forventet,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtpost failover-script på klynge 3 med args:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
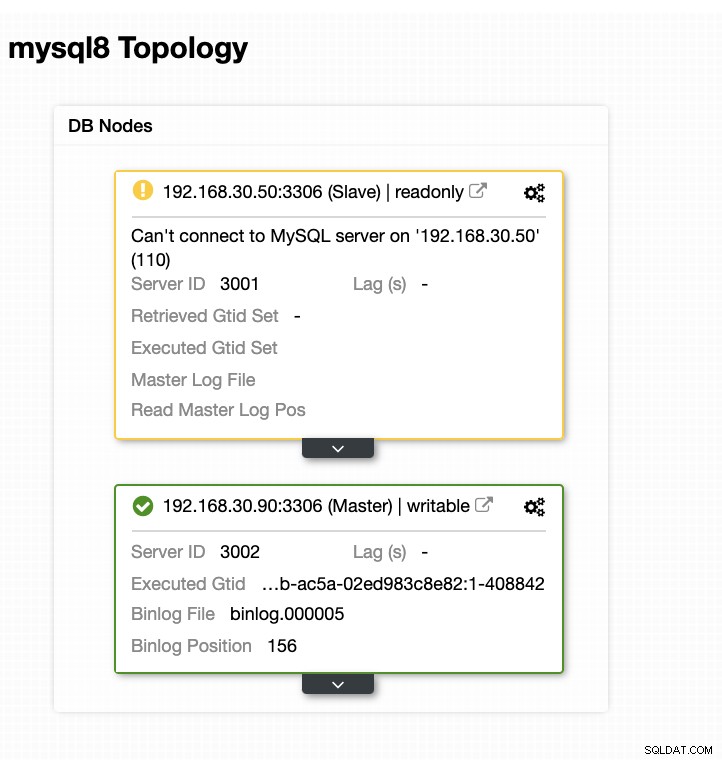
Nu er min topologi blevet ændret, og failoveren lykkedes!
Konklusion
For enhver kompliceret databaseopsætning, du måtte have, når en avanceret failover er påkrævet, kan pre/post-scripts være meget nyttige for at gøre tingene opnåelige. Da ClusterControl understøtter disse funktioner, har vi demonstreret, hvor kraftfuldt og nyttigt det er. Selv med dets begrænsninger er der altid måder at gøre tingene opnåelige og nyttige, især i produktionsmiljøer.