Benchmarks er en af de aktiviteter, som databaseadministratorer udfører. Du kører dem for at se, hvordan din hardware opfører sig, du kører dem for at se, hvordan din applikation og database arbejder sammen under pres. Du kører dem i mange forskellige situationer. Lad os tale lidt om dem, hvad er de udfordringer, du kommer til at stå over for, hvad er de problemer, du bør undgå.
Typer af benchmarks
Hvert benchmark er forskelligt. De tjener forskellige formål, og det skal tages i betragtning, når du planlægger at køre en. Generelt kan du definere to hovedtyper af benchmark:syntetisk benchmark og, lad os kalde det, en "den virkelige verden" benchmark.
Syntetiske benchmarks er typisk værktøjer, der simulerer en form for arbejdsbyrde. Det kan være en OLTP-arbejdsbelastning som i tilfældet med Sysbench, det kan være et "standard" benchmark som i TPC-C eller TPC-H. Normalt er ideen, at sådan et benchmark simulerer en form for arbejdsbyrde, og det kan være nyttigt, hvis din virkelige arbejdsbyrde kommer til at følge det samme mønster. Det kan også bruges til at bestemme, hvordan din blanding af hardware og databasekonfiguration fungerer sammen under en given type arbejdsbyrde. Fordelene ved syntetiske benchmarks er ret klare. Du kan køre dem overalt, de afhænger ikke af en bestemt opsætning eller skemadesign. Nå, det gør de, men de kommer med værktøjer til at sætte alt op fra den tomme databaseserver. Den største ulempe er, at dette ikke er din arbejdsbyrde. Hvis du skal køre OLTP-tests ved hjælp af Sysbench, skal du huske på, at din applikation aldrig bliver Sysbench. Det kan også køre OLTP-arbejdsbelastning, men forespørgselsmixet vil være anderledes. Aldrig under nogen omstændigheder vil syntetisk benchmark fortælle dig præcis, hvordan din applikation vil opføre sig på en given hardware/konfigurationsmix.
I den anden ende af spektret har vi, hvad vi kaldte, "den virkelige verden" benchmarks. Det, vi her mener, er et benchmark, der bruger et datasæt og forespørgsler relateret til din applikation. Det har ikke altid et komplet datasæt og fuld forespørgselsmix. Du ønsker måske at fokusere på nogle dele af din applikation, men hovedideen bag det er, at du ønsker at forstå den nøjagtige interaktion mellem applikationen, hardwaren og databasekonfigurationen, enten generelt eller i et bestemt aspekt.
Som vi nævnte ovenfor, har vi to forskellige typer benchmarks, men de har stadig nogle fælles ting, du skal overveje, når du forsøger at køre benchmarks.
-
Beslut hvad du vil teste
For det første er benchmarking for at køre benchmarks meningsløst. Det skal være designet til rent faktisk at udrette noget. Hvad vil du have ud af benchmarkkørslen? Vil du justere forespørgslerne? Vil du justere konfigurationen? Vil du vurdere skalerbarheden af din stack? Vil du forberede din stak til en højere belastning? Vil du lave en generisk konfigurations-tweking til et nyt projekt? Vil du bestemme de bedste indstillinger for din hardware? Det er eksempler på mål, du måske ønsker at nå. Hver af disse vil kræve en anden tilgang og forskellig benchmark-opsætning.
-
Foretag én ændring ad gangen
Uanset hvad du tester og justerer, er det yderst vigtigt, at du kun foretager én konfigurationsændring ad gangen. Dette er virkelig kritisk. Benchmark er beregnet til at give dig en idé om ydeevnen. Forespørgsler pr. sekund, latency, 99 percentil, alt dette fortæller dig, hvor hurtigt du kan udføre forespørgslerne, og hvor stabil og forudsigelig arbejdsbyrden er. Det er let at se, om den ændring, du har foretaget i konfigurationen, hardwaren eller forespørgselsmixet, ændrer noget:Metrics fra benchmark vil se anderledes ud. Sagen er, at hvis du laver et par ændringer på samme tid, er der ingen måde at sige, hvilken der er ansvarlig for det samlede resultat. Det kan gå endnu længere end det. Lad os sige, at du har ændret to værdier i databasekonfigurationen. Værdi A og B. Den overordnede forbedring er 20 %, hvilket er ret godt for blot en konfigurationsændring. Under motorhjelmen bragte ændring til værdi A dog en forbedring på 30 %, mens yderligere ændring af værdi B satte den tilbage til 20 %. Med flere ændringer på samme tid kan du kun observere deres fælles indvirkning, dette er ikke måden til korrekt at bestemme resultatet af hver enkelt ændring, du har foretaget. Selvfølgelig øger dette den tid, du vil bruge på at køre benchmark, markant, men sådan er det.
-
Foretag flere benchmarkkørsler
Computere er komplekse systemer i sig selv. De har flere komponenter, der interagerer med hinanden:hukommelse, CPU, disk, netværk. Lad os så tilføje containerisering til denne virtualisering. Derefter software - styresystem, applikation, database. Lag over lag over lag over lag af elementer, der på en eller anden måde interagerer. Det er ikke nemt at forudsige dens adfærd. Nå, du kan sige, at det er næsten umuligt præcist at forudsige adfærden af sådanne komplekse systemer. Dette er grunden til, at det ikke er nok at køre ét benchmark-løb til at drage konklusionerne. Hvad hvis, ubevidst for dig, et element, der er fuldstændig uden relation til det, du vil teste, påvirker den samlede præstation? Høj belastning på en anden VM placeret på den samme vært. En anden server streamer backup over netværket. Dette kan midlertidigt påvirke ydeevnen og skæve benchmarkresultater. Hvis du kun udfører én benchmarkkørsel, ender du med forkerte resultater. Dette er grunden til, at den bedste praksis er at udføre adskillige omgange af et benchmark og derefter fjerne den langsomste og hurtigste ved at tage et gennemsnit af de andre.
-
Et billede er tusindvis af ord værd
Jamen, dette er stort set en meget præcis beskrivelse af benchmarking. Hvis det kun er muligt, skal du altid generere grafer. Ideelt set skal du spore metrics under benchmark så ofte du kan. Et sekund granularitet burde være nok i de fleste tilfælde. For at undgå at skrive tusindvis af ord, inkluderer vi dette eksempel. Hvad synes du er mere nyttigt? Dette sæt benchmark-output, der repræsenterer gennemsnitlig QPS for hver af 10 gennemløb, hver gang tager 600 sekunder
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
Eller dette plot:
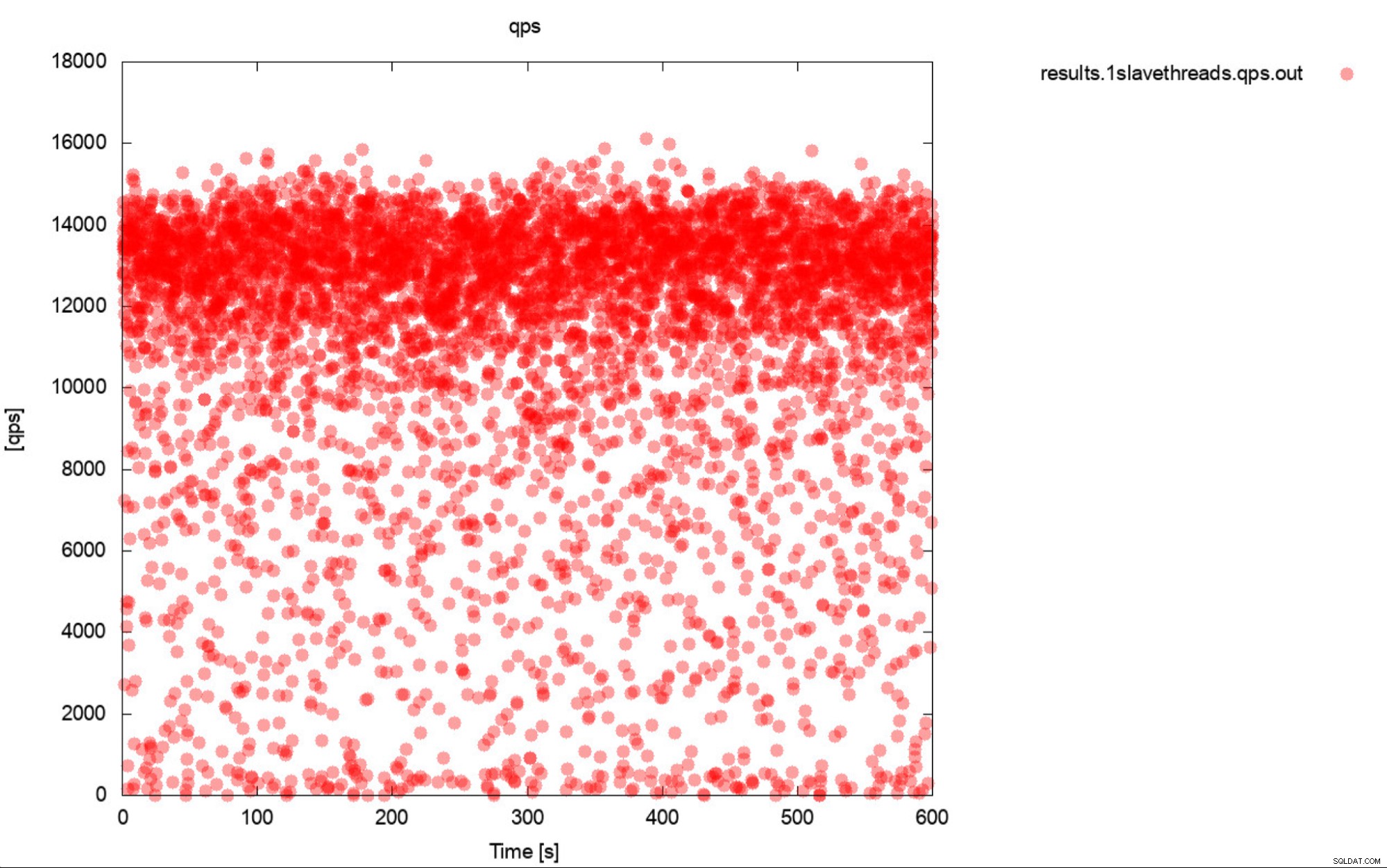
Den gennemsnitlige QPS er 11k, men virkeligheden er, at ydeevnen er overalt sted, inklusive fald til 0 forespørgsler udført inden for et sekund, og det er bestemt noget, du vil arbejde og forbedre på produktionssystemerne.
-
Forespørgsler pr. sekund er ikke den vigtigste metric
Du tror måske, at forespørgsel pr. sekund er ydeevnens hellige gral, da det repræsenterer, hvor mange forespørgsler en database kan udføre inden for et sekund. Sandheden er, at det ikke er den vigtigste metrik, især hvis vi taler om gennemsnittet output fra et benchmark. QPS repræsenterer gennemløbet, men det ignorerer latensen. Du kan prøve at skubbe en stor mængde forespørgsler, men så ender du med at vente på, at de returnerer resultater. Det er ikke, hvad brugerne forventer af applikationen. Brugere forventer stabil ydeevne. Det behøver ikke at være lynhurtigt, men når en handling tager et sekund at fuldføre, har vi en tendens til at forvente, at udførelsen af denne handling altid vil tage det 1 sekund. Hvis det af en eller anden grund begynder at tage længere tid, har mennesker en tendens til at blive angste. Dette er hovedårsagen til, at vi har en tendens til at foretrække latency, især dens P99 (99. percentil) som en mere pålidelig metrik. Latency fortæller os, hvor længe applikationen skulle vente på resultatet fra databasen. P99 fortæller os latens, at 99% af forespørgslerne har lavere end. Lad os sige, at vi har en P99 på 100ms, det betyder, at 99% af forespørgslerne returnerer resultater, der ikke er langsommere end 100ms. Hvis vi ser P99-latens lav, betyder det, at næsten alle forespørgsler vender hurtigt tilbage og udfører på en stabil, forudsigelig måde. Dette er noget, vores brugere gerne vil se.
-
Forstå, hvad der sker, før du drager konklusioner
Sidste punkt, vi har i denne korte blog, men vi vil sige, at det er det vigtigste. Du vil se forskellige mærkelige og uventede resultater og adfærd under benchmarks. Endnu værre, kan du se ret standard, gentagne, men stadig mangelfulde resultater. De fleste af dem kan spores til databasens eller hardwarens adfærd. Dette er virkelig afgørende – før du tager resultatet for givet, bør du være i stand til at forklare adfærden og beskrive, hvad der skete. Vi ved, at det ikke er let, og vi ved, at det virkelig kræver databasespecifik viden, især viden relateret til databasens interne elementer. Vi ved, at folk i den virkelige verden typisk ikke gider dette, de vil bare gerne opnå nogle resultater. Sagen er, især i tilfælde, hvor du forsøger at forbedre ydeevnen gennem konfiguration eller hardwarejusteringer, at forstå, hvad der skete under motorhjelmen, giver dig mulighed for at vælge den rigtige måde, hvorpå din tuning skal fortsætte. Det gør det også muligt at se, om det benchmark, der er blevet udført, kan have nogen mening. Tester vi faktisk det rigtige element? Et eksempel kunne være en test udført over netværket (fordi du ikke ønsker at bruge lokale CPU-kerner i databasenoden til benchmarkværktøj). Det er ret sandsynligt, at selve netværket og softirq CPU-belastning vil være den begrænsende faktor, langt tidligere end du ville ramme "forventede" flaskehalse som CPU-mætning. Hvis du ikke er opmærksom på dit miljø og dets adfærd, vil du måle din netværksydelse for at overføre store mængder data, ikke CPU-ydeevnen.
Som du kan se, er benchmarking ikke den nemmeste ting at gøre, du skal have et niveau af bevidsthed om, hvad der foregår, du bør have en ordentlig plan for, hvad du skal gøre og hvad vil du teste? I den næste del af denne blog skal vi gennemgå nogle af de virkelige testcases. Hvad kan gå galt, hvilke problemer vil vi støde på, og hvordan man håndterer dem.