MySQL master-slave-replikering er ret nem og ligetil at konfigurere. Dette er hovedårsagen til, at folk vælger denne teknologi som det første skridt til at opnå bedre databasetilgængelighed. Det kommer dog til prisen af kompleksitet i forvaltning og vedligeholdelse; det er op til administratoren at vedligeholde dataintegriteten, især under failover, failback, vedligeholdelse, opgradering og så videre.
Der er mange artikler derude, der beskriver, hvordan man udfører failover-operation til replikeringsopsætning. Vi har også dækket dette emne i dette blogindlæg, Introduktion til Failover for MySQL-replikering - 101-bloggen. I dette blogindlæg vil vi dække post-katastrofeopgaverne, når vi gendannes til den originale topologi - udfører failback-operation.
Hvorfor har vi brug for Failback?
Replikeringslederen (master) er den mest kritiske node i en replikeringsopsætning. Det kræver gode hardwarespecifikationer for at sikre, at det kan behandle skrivninger, generere replikeringshændelser, behandle kritiske læsninger og så videre på en stabil måde. Når failover er påkrævet under katastrofegendannelse eller vedligeholdelse, er det måske ikke ualmindeligt, at vi promoverer en ny leder med ringere hardware. Denne situation kan være i orden midlertidigt, men på længere sigt skal den udpegede master bringes tilbage for at lede replikationen, efter at den anses for at være sund.
I modsætning til failover, sker failback-operation normalt i et kontrolleret miljø gennem switchover, det sker sjældent i panik-tilstand. Dette giver operationsteamet lidt tid til at planlægge omhyggeligt og øve øvelsen for en glidende overgang. Hovedformålet er simpelthen at bringe den gode gamle mester tilbage til den seneste tilstand og gendanne replikeringsopsætningen til dens oprindelige topologi. Der er dog nogle tilfælde, hvor failback er kritisk, for eksempel når den nyligt forfremmede master ikke fungerede som forventet og påvirker den overordnede databasetjeneste.
Hvordan udføres Failback sikkert?
Efter failover skete, ville den gamle master være ude af replikeringskæden til vedligeholdelse eller gendannelse. For at udføre omstillingen skal man gøre følgende:
- Forsyn den gamle master til den korrekte tilstand ved at gøre den til den mest opdaterede slave.
- Stop applikationen.
- Bekræft, at alle slaver er fanget.
- Promovér den gamle mester som den nye leder.
- Genpeg alle slaver til den nye master.
- Start applikationen ved at skrive til den nye master.
Overvej følgende replikeringsopsætning:
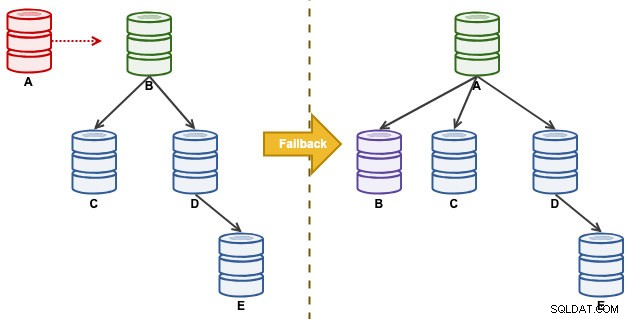
"A" var en mester, indtil en disk fuld hændelse forårsagede kaos i replikeringskæden. Efter en failover-hændelse blev vores replikeringstopologi ledet af B og replikeres til C indtil E. Failback-øvelsen vil bringe A tilbage som leder og genoprette den oprindelige topologi før katastrofen. Bemærk, at alle noder kører på MySQL 8.0.15 med GTID aktiveret. Forskellige større versioner kan bruge forskellige kommandoer og trin.
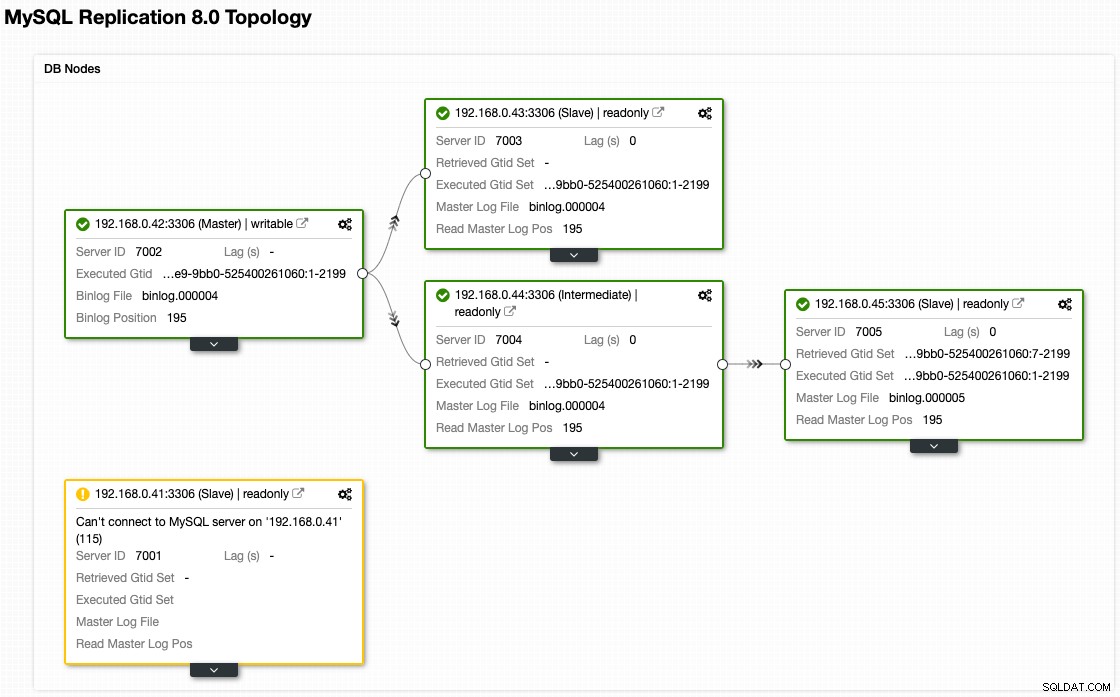
Selvom det er sådan vores arkitektur ser ud nu efter failover (taget fra ClusterControls Topology-visning):
Knudeklargøring
Før A kan være en master, skal den opdateres med den aktuelle databasetilstand. Den bedste måde at gøre dette på er at gøre A som slave til den aktive master, B. Da alle noder er konfigureret med log_slave_updates=ON (det betyder, at en slave også producerer binære logfiler), kan vi faktisk vælge andre slaver som C og D som kilden til sandhed for indledende synkronisering. Men jo tættere på den aktive mester, jo bedre. Husk på den ekstra belastning, det kan forårsage, når du tager sikkerhedskopien. Denne del tager det meste af failback-timerne. Afhængigt af nodetilstanden og datasættets størrelse kan synkronisering af den gamle master tage noget tid (det kan være timer og dage).
Når problemet på "A" er løst og klar til at slutte sig til replikeringskæden, er det bedste første skridt at forsøge at replikere fra "B" (192.168.0.42) med CHANGE MASTER-sætning:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Hvis replikering virker, bør du se følgende i replikeringsstatussen:
Slave_IO_Running: Yes
Slave_SQL_Running: YesHvis replikeringen mislykkes, skal du se på Last_IO_Error eller Last_SQL_Error fra slavestatusoutput. For eksempel, hvis du ser følgende fejl:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Derefter skal vi oprette replikeringsbrugeren på den aktuelle aktive master, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Genstart derefter slaven på A for at begynde at replikere igen:
mysql> STOP SLAVE;
mysql> START SLAVE;En anden almindelig fejl, du vil se, er denne linje:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Det betyder sandsynligvis, at slaven har problemer med at læse den binære logfil fra den aktuelle master. I nogle tilfælde kan slaven være langt bagud, hvorved de nødvendige binære hændelser for at starte replikeringen har manglet fra den aktuelle master, eller binæren på masteren er blevet renset under failover og så videre. I dette tilfælde er den bedste måde at udføre en fuld synkronisering ved at tage en fuld backup på B og gendanne den på A. På B kan du bruge enten mysqldump eller Percona Xtrabackup til at tage en fuld backup:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupOverfør backup-filen til A, geninitialiser den eksisterende MySQL-installation for en ordentlig oprydning og udfør databasegendannelse:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordNår den er gendannet, skal du konfigurere replikeringslinket til den aktive master B (192.168.0.42) og aktivere skrivebeskyttet. På A skal du køre følgende sætninger:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */For Percona Xtrabackup henvises til dokumentationssiden om, hvordan man gendanner til A. Det indebærer et forudsætningstrin at forberede sikkerhedskopien først, før MySQL-databiblioteket udskiftes.
Når A er begyndt at replikere korrekt, skal du overvåge Seconds_Behind_Master i slavestatus. Dette vil give dig en idé om, hvor langt slaven har efterladt sig, og hvor længe du skal vente, før den indhenter. På dette tidspunkt ser vores arkitektur sådan ud:
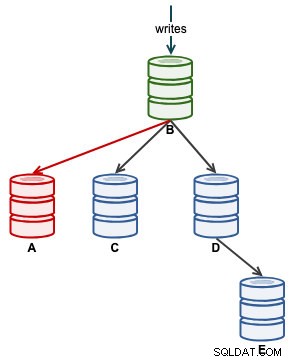
Når Seconds_Behind_Master falder tilbage til 0, er det det øjeblik, hvor A har indhentet som en up-to-date slave.
Hvis du bruger ClusterControl, har du mulighed for at gensynkronisere noden ved at gendanne fra en eksisterende sikkerhedskopi eller oprette og streame sikkerhedskopien direkte fra den aktive masterknude:
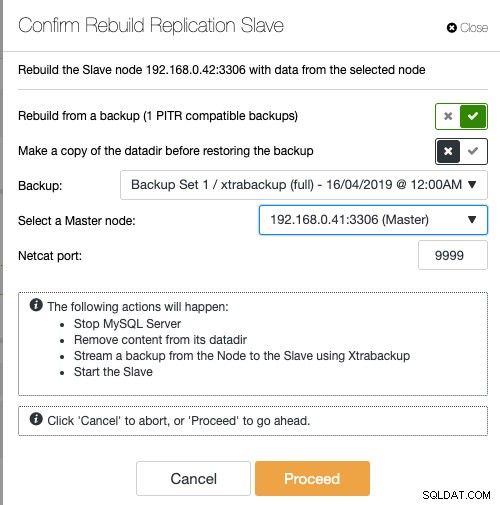
Iscenesættelse af slaven med eksisterende backup er den anbefalede måde at gøre for at bygge slaven, da det ikke har nogen indflydelse på den aktive masterserver, når noden klargøres.
Promover den gamle mester
Før du promoverer A som den nye master, er den sikreste måde at stoppe al skriveoperation på B. Hvis dette ikke er muligt, skal du blot tvinge B til at arbejde i skrivebeskyttet tilstand:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Kør derefter SHOW SLAVE STATUS på A og kontroller følgende replikeringsstatus:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesVærdien af Read_Master_Log_Pos og Exec_Master_Log_Pos skal være identiske, mens Seconds_Behind_Master er 0, og tilstanden skal være 'Slaven har læst al relælog'. Sørg for, at alle slaver har behandlet eventuelle udsagn i deres relæ-log, ellers risikerer du, at de nye forespørgsler vil påvirke transaktioner fra relæ-loggen, hvilket udløser alle mulige problemer (for eksempel kan en applikation fjerne nogle rækker, der tilgås af transaktioner fra relælog).
På A, stop replikeringen og brug RESET SLAVE ALL-sætningen til at fjerne al replikeringsrelateret konfiguration og deaktiver skrivebeskyttet:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';På dette tidspunkt er A klar til at acceptere skrivninger (read_only=OFF), men slaver er ikke forbundet til den, som illustreret nedenfor:
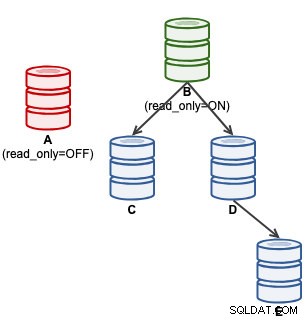
For ClusterControl-brugere kan promovering af A gøres ved at bruge "Promote Slave"-funktionen under Node Actions. ClusterControl vil automatisk degradere den aktive master B, fremme slave A som master og genpege C og D for at replikere fra A. B vil blive lagt til side, og brugeren skal udtrykkeligt vælge "Change Replication Master" for at slutte sig til B replikerende fra A på et senere tidspunkt .
Genudpegning af slave
Det er nu sikkert at ændre masteren på relaterede slaver til at replikere fra A (192.168.0.41). Konfigurer følgende på alle slaver undtagen E:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Hvis du er en ClusterControl-bruger, kan du springe dette trin over, da genpegning udføres automatisk, når du besluttede at promovere A tidligere.
Vi kan derefter starte vores applikation til at skrive på A. På dette tidspunkt ser vores arkitektur sådan ud:
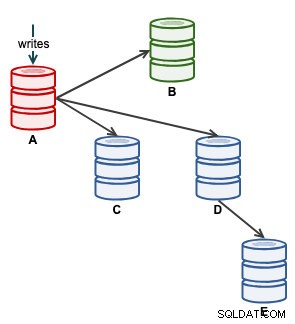
Fra ClusterControl-topologivisningen har vi gendannet vores replikeringsklynge til dens oprindelige arkitektur, som ser sådan ud:
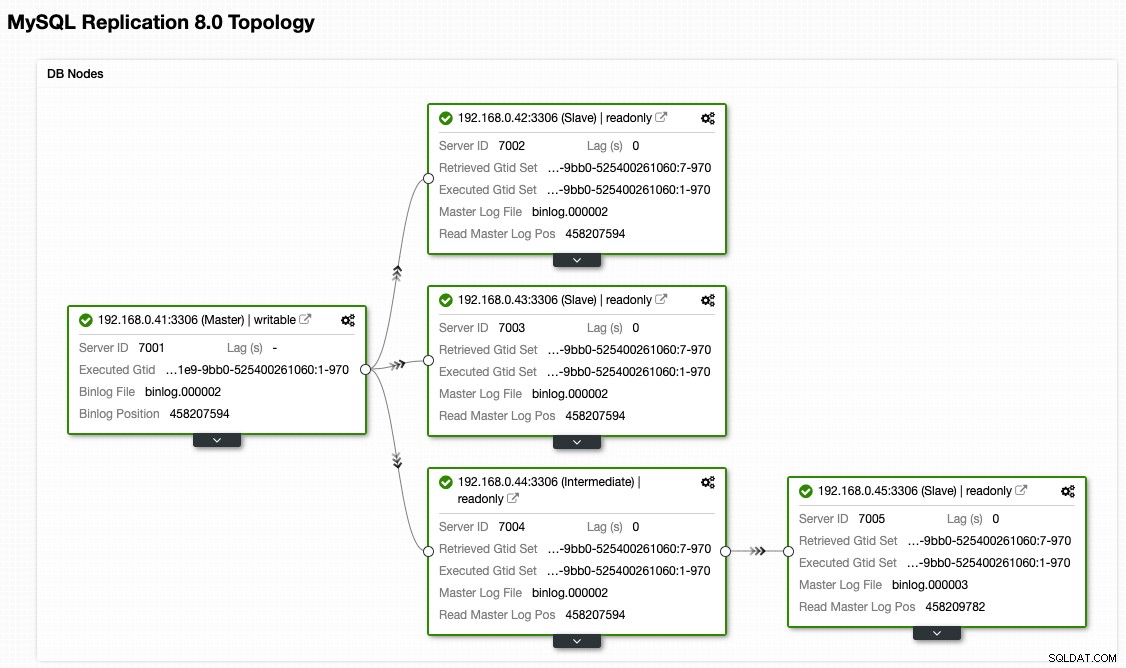
Bemærk, at failback-øvelser er meget mindre risikabelt sammenlignet med failover. Det er vigtigt at planlægge denne øvelse uden for myldretiden for at minimere indvirkningen på din virksomhed.
Sidste tanker
Failover og failback operation skal udføres omhyggeligt. Handlingen er ret enkel, hvis du har et lille antal noder, men for flere noder med kompleks replikeringskæde kan det være en risikabel og fejltilbøjelig øvelse. Vi viste også, hvordan ClusterControl kan bruges til at forenkle komplekse operationer ved at udføre dem gennem brugergrænsefladen, plus topologivisningen visualiseres i realtid, så du har forståelsen for den replikeringstopologi, du vil bygge.