
Dataens tilgængelighed, tilgængelighed og ydeevne er afgørende for virksomhedens succes. Ydeevnejustering og SQL-forespørgselsoptimering er vanskelige, men nødvendige fremgangsmåder for databaseprofessionelle. De kræver at se på forskellige samlinger af data ved hjælp af udvidede hændelser, perfmon, udførelsesplaner, statistikker og indekser for at nævne nogle få. Nogle gange beder applikationsejere om at øge systemressourcerne (CPU og hukommelse) for at forbedre systemets ydeevne. Du behøver dog muligvis ikke disse ekstra ressourcer, og de kan have en omkostning forbundet med dem. Nogle gange er det eneste, der kræves, at foretage mindre forbedringer for at ændre forespørgselsadfærden.
I denne artikel vil vi diskutere et par bedste fremgangsmåder til optimering af SQL-forespørgsler, der skal anvendes, når du skriver SQL-forespørgsler.
SELECT * vs SELECT kolonneliste
Normalt bruger udviklere SELECT *-sætningen til at læse data fra en tabel. Den læser alle kolonnens tilgængelige data i tabellen. Antag en tabel [AdventureWorks2019].[HumanResources].[Medarbejder] gemmer data for 290 medarbejdere, og du har et krav om at hente følgende oplysninger:
- Medarbejders nationale ID-nummer
- DOB
- Køn
- Lejedato
Ineffektiv forespørgsel: Hvis du bruger SELECT *-sætningen, returnerer den alle kolonnens data for alle 290 medarbejdere.
Vælg * fra [AdventureWorks2019].[HumanResources].[Medarbejder]
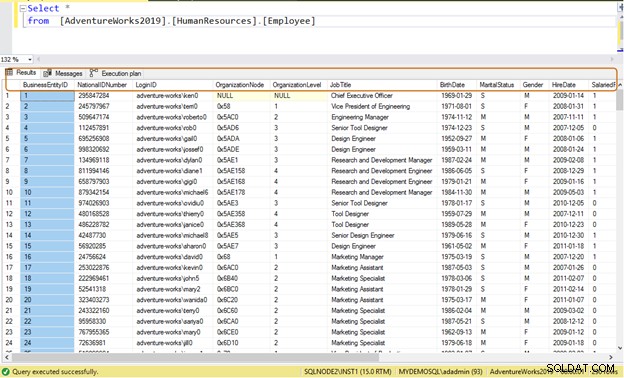
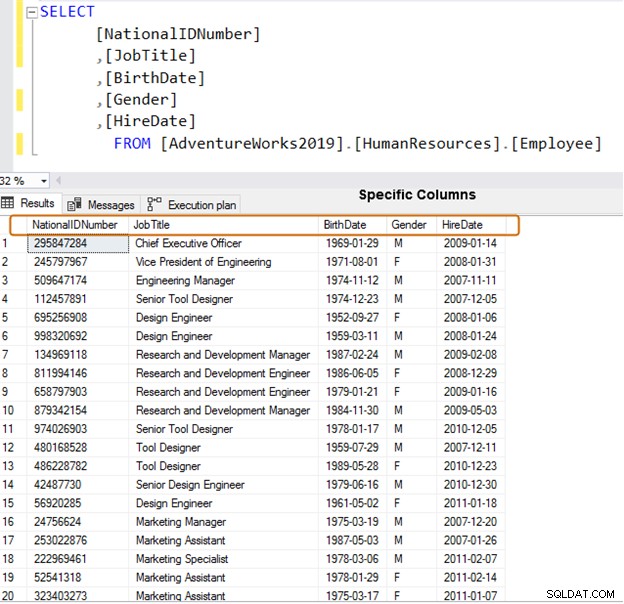
Brug i stedet specifikke kolonnenavne til datahentning.
VÆLG [NationalIDNumber],[JobTitle],[BirthDate],[Køn],[HireDate]FRA [AdventureWorks2019].[HumanResources].[Medarbejder]
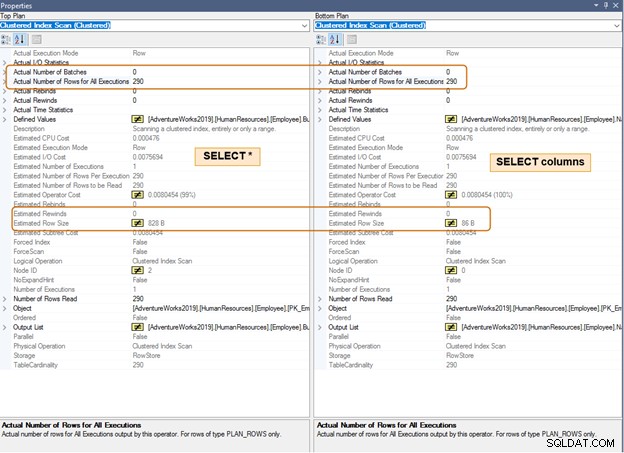
I nedenstående udførelsesplan skal du notere forskellen i den estimerede rækkestørrelse for det samme antal rækker. Du vil også bemærke en forskel i CPU og IO for et stort antal rækker.
Brug af COUNT() vs. EXISTS
Antag, at du vil kontrollere, om der findes en specifik post i SQL-tabellen. Normalt bruger vi COUNT (*) til at kontrollere posten, og den returnerer antallet af poster i outputtet.
Vi kan dog bruge funktionen IF EXISTS() til dette formål. Til sammenligningen aktiverede jeg statistikken, før jeg udførte forespørgslerne.
Forespørgslen for COUNT()
INDSTIL STATISTIK IO ONVælg antal(*) fra [AdventureWorks2019].[Salg].[SalesOrderDetail]hvor [SalesOrderDetailID]=44824INDSTIL STATISTIK IO FRA
Forespørgslen til IF EXISTS()
INDSTIL STATISTIK IO ONIF EXISTS(Vælg [CarrierTrackingNumber] fra [AdventureWorks2019].[Salg].[SalesOrderDetail]hvor [SalesOrderDetailID]=44824) UDSKRIV 'YES'ELSEPRINT 'NO'SET STATISTICS IO IO .Jeg brugte statisticsparser til at analysere statistikresultaterne for begge forespørgsler. Se resultaterne nedenfor. Forespørgslen med COUNT(*) har 276 logiske læsninger, mens IF EXISTS() har 83 logiske læsninger. Du kan endda få en mere signifikant reduktion i logiske læsninger med IF EXISTS(). Derfor bør du bruge det til at optimere SQL-forespørgsler for bedre ydeevne.
Undgå at bruge SQL DISTINCT
Når vi ønsker unikke poster fra forespørgslen, bruger vi sædvanligvis SQL DISTINCT-sætningen. Antag, at du har slået to tabeller sammen, og i outputtet returnerer det de duplikerede rækker. En hurtig løsning er at angive DISTINCT-operatoren, der undertrykker den duplikerede række.
Lad os se på de simple SELECT-udsagn og sammenligne udførelsesplanerne. Den eneste forskel mellem begge forespørgsler er en DISTINCT-operator.
VÆLG SalesOrderID FRA Sales.SalesOrderDetailGoSELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetailGoMed DISTINCT-operatøren er forespørgselsomkostningerne 77 %, mens den tidligere forespørgsel (uden DISTINCT) kun har 23 % batch-omkostninger.
Du kan bruge GROUP BY, CTE eller en underforespørgsel til at skrive effektiv SQL-kode i stedet for at bruge DISTINCT til at få forskellige værdier fra resultatsættet. Derudover kan du hente yderligere kolonner til et bestemt resultatsæt.
VÆLG SalesOrderID FRA Sales.SalesOrderDetail Group efter SalesOrderIDBrug af jokertegn i SQL-forespørgslen
Antag, at du vil søge efter de specifikke poster, der indeholder navne, der starter med den angivne streng. Udviklere bruger et jokertegn til at søge efter de matchende registreringer.
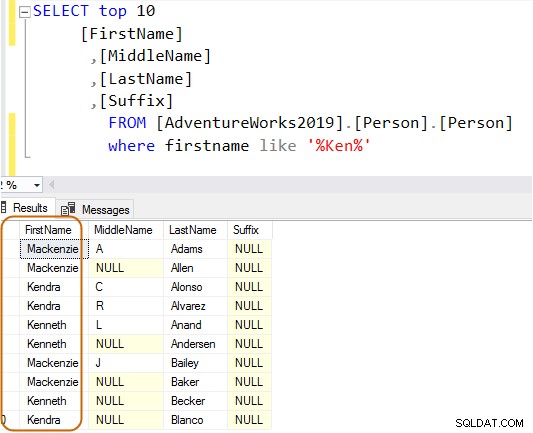
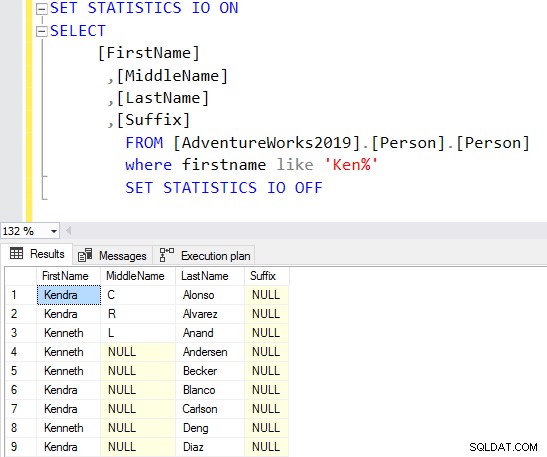
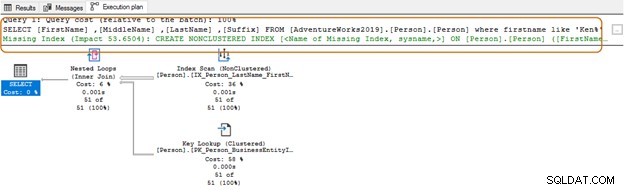
I nedenstående forespørgsel søger den efter strengen Ken i fornavnskolonnen. Denne forespørgsel henter de forventede resultater af Ken dra og Ken neth. Men det giver også uventede resultater, for eksempel Macken zie og Nken ge.
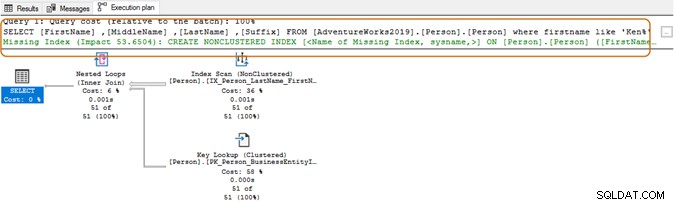
I udførelsesplanen ser du indeksscanningen og nøgleopslaget for ovenstående forespørgsel.
Du kan undgå det uventede resultat ved at bruge jokertegnet i slutningen af strengen.
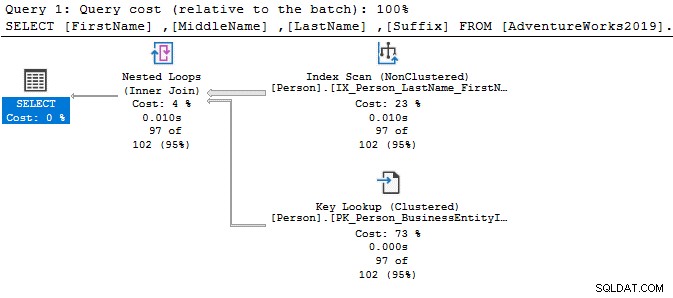
VÆLG Top 10[FirstName],[MiddleName],[LastName],[Suffix]FRA [AdventureWorks2019].[Person].[Person]Hvor fornavn som 'Ken%'Nu får du det filtrerede resultat baseret på dine krav.
Når du bruger jokertegnet i begyndelsen, kan forespørgselsoptimeringsværktøjet muligvis ikke bruge det passende indeks. Som vist på nedenstående skærmbillede, med et efterfølgende vildt tegn, foreslår forespørgselsoptimering også et manglende indeks.
Her vil du gerne evaluere dine ansøgningskrav. Du bør prøve at undgå at bruge et jokertegn i søgestrengene, da det kan tvinge forespørgselsoptimering til at bruge en tabelscanning. Hvis tabellen er enorm, vil den kræve højere systemressourcer til IO, CPU og hukommelse og kan forårsage ydeevneproblemer for din SQL-forespørgsel.
Brug af WHERE- og HAVING-klausulerne
WHERE- og HAVING-sætningerne bruges som datarækkefiltre. WHERE-udtrykket filtrerer dataene før anvendelse af grupperingslogikken, mens HAVING-udtrykket filtrerer rækker efter de aggregerede beregninger.
For eksempel bruger vi i nedenstående forespørgsel et datafilter i HAVING-sætningen uden en WHERE-sætning.
Vælg SalesOrderID,SUM(UnitPrice* OrderQuty) som OrderTotalFrom Sales.salesOrderDetailGROUP BY SalesOrderIDHAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1GoFølgende forespørgsel filtrerer først dataene i WHERE-udtrykket og bruger derefter HAVING-udtrykket til det samlede datafilter.
Vælg SalesOrderID,SUM(UnitPrice* OrderQuty) som OrderTotalFrom Sales.salesOrderDetailwhere SalesOrderID>30000 og SalesOrderID<55555GROUP BY SalesOrderIDHAVING SUM(UnitPrice* OrderQty)>1000GoJeg anbefaler at bruge WHERE-sætningen til datafiltrering og HAVING-sætningen til dit samlede datafilter som bedste praksis.
Brug af IN- og EXISTS-klausulerne
Du bør undgå at bruge IN-operator-klausulen til dine SQL-forespørgsler. I nedenstående forespørgsel fandt vi f.eks. først produkt-id'et fra tabellen [Production].[TransactionHistory]) og ledte derefter efter de tilsvarende poster i tabellen [Produktion].[Produkt].
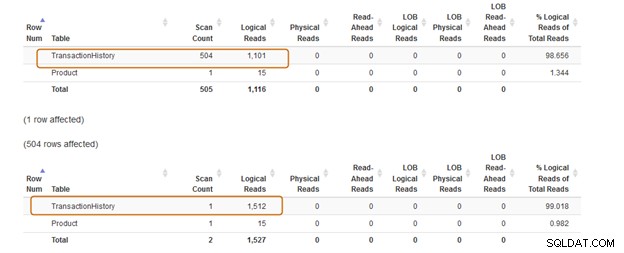
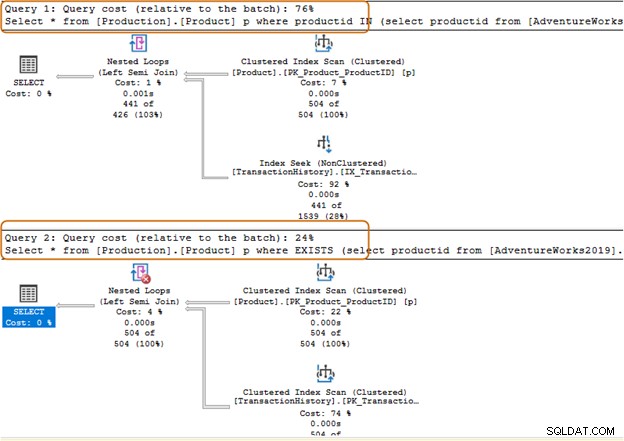
Vælg * fra [Produktion].[Produkt] p hvor produktid IN (vælg produkt-id fra [AdventureWorks2019].[Produktion].[TransactionHistory]);GoI nedenstående forespørgsel erstattede vi IN-sætningen med en EXISTS-sætning.
Vælg * fra [Produktion].[Produkt] p hvor EKSISTERER (vælg produkt-id fra [AdventureWorks2019].[Produktion].[TransactionHistory])Lad os nu sammenligne statistikkerne efter at have udført begge forespørgsler.
IN-klausulen bruger 504 scanninger, mens EXISTS-klausulen bruger 1 scanning til tabellen [Production].[TransactionHistory]).
IN-klausulen-forespørgselsbatchen koster 74 %, mens EXISTS-klausulens omkostninger er 24 %. Derfor bør du undgå IN-sætningen, især hvis underforespørgslen returnerer et stort datasæt.
Manglende indekser
Nogle gange, når vi udfører en SQL-forespørgsel og leder efter den faktiske udførelsesplan i SSMS, får du et forslag om et indeks, der kan forbedre din SQL-forespørgsel.
Alternativt kan du bruge de dynamiske administrationsvisninger til at kontrollere detaljerne om manglende indekser i dit miljø.

- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Normalt følger DBA'er rådene fra SSMS og opretter indekserne. Det kan forbedre forespørgselsydeevne i øjeblikket. Du bør dog ikke oprette indekset direkte baseret på disse anbefalinger. Det kan påvirke andre forespørgselsydelser og sænke dine INSERT- og UPDATE-sætninger.
- Gennemgå først de eksisterende indekser for din SQL-tabel.
- Bemærk, overindeksering og underindeksering er begge dårlige for forespørgselsydeevne.
- Anvend de manglende indeksanbefalinger med den største effekt efter at have gennemgået dine eksisterende indekser, og implementer det på dit lavere miljø. Hvis din arbejdsbyrde fungerer godt efter implementering af det nye manglende indeks, er det værd at tilføje it.
Jeg foreslår, at du refererer til denne artikel for at få detaljerede bedste fremgangsmåder for indeksering: 11 SQL Server Index Best Practices for Improved Performance Tuning.
Forespørgselstip
Udviklere angiver forespørgselstip eksplicit i deres t-SQL-sætninger. Disse forespørgselstip tilsidesætter adfærd for forespørgselsoptimering og tvinger den til at forberede en eksekveringsplan baseret på dit forespørgselstip. Hyppigt brugte forespørgselstip er NOLOCK, Optimize For og Recompile Merge/Hash/Loop. De er kortsigtede rettelser til dine forespørgsler. Du bør dog arbejde på at analysere din forespørgsel, indekser, statistik og eksekveringsplan for en permanent løsning.
I henhold til bedste praksis bør du minimere brugen af ethvert forespørgselstip. Du vil bruge forespørgselstipsene i SQL-forespørgslen efter først at have forstået implikationerne af det, og brug det ikke unødigt.
SQL-forespørgselsoptimeringspåmindelser
Som vi diskuterede, er SQL-forespørgselsoptimering en åben vej. Du kan anvende bedste praksis og små rettelser, der i høj grad kan forbedre ydeevnen. Overvej følgende tips til bedre forespørgselsudvikling:
- Se altid på allokeringer af systemressourcer (diske, CPU, hukommelse)
- Gennemgå dine startsporingsflag, indekser og databasevedligeholdelsesopgaver
- Analyser din arbejdsbyrde ved hjælp af udvidede begivenheder, profileringsværktøjer eller tredjeparts-databaseovervågningsværktøjer
- Implementer altid enhver løsning (selvom du er 100 % sikker) på testmiljøet først og analyser dens indvirkning; når du er tilfreds, planlæg produktionsimplementeringer