Vi har for nylig skrevet adskillige blogs, der dækker, hvordan forskellige cloud-udbydere håndterer database-failover. Vi sammenlignede failover-ydeevne i Amazon Aurora, Amazon RDS og ClusterControl, testede failover-adfærden i Amazon RDS og også på Google Cloud Platform. Selvom disse tjenester giver gode muligheder, når det kommer til failover, er de måske ikke rigtige for enhver applikation.
I dette blogindlæg vil vi bruge lidt tid på at analysere fordele og ulemper ved at bruge DBaaS-løsningerne sammenlignet med at designe et miljø manuelt eller ved at bruge en databasestyringsplatform som ClusterControl.
Implementering af databaser med høj tilgængelighed med administrerede løsninger
Den primære grund til at bruge eksisterende løsninger er brugervenlighed. Du kan implementere en yderst tilgængelig løsning med automatiseret failover med blot et par klik. Der er ikke behov for at kombinere forskellige værktøjer sammen, administrere databaserne i hånden, implementere værktøjer, skrive scripts, designe overvågningen eller andre databasestyringsoperationer. Alt er allerede på plads. Dette kan alvorligt reducere indlæringskurven og kræver mindre erfaring at opsætte et meget tilgængeligt miljø for databaserne; giver stort set alle mulighed for at implementere sådanne opsætninger.
I de fleste tilfælde med disse løsninger udføres failover-processen inden for en rimelig tid. Det kan være lynhurtigt som med Amazon Aurora eller noget langsommere som med Google Cloud Platform SQL-noder. For de fleste tilfælde er disse typer resultater acceptable.
Bundlinjen. Hvis du kan acceptere 30 - 60 sekunders nedetid, bør du være okay ved at bruge en af DBaaS-platformene.
Ulempen ved at bruge en administreret løsning til HA
Selv om DBaaS-løsninger er enkle at bruge, har de også nogle alvorlige ulemper. Til at begynde med er der altid en leverandørlåsningskomponent at overveje. Når du først implementerer en klynge i Amazon Web Services, er det ret vanskeligt at migrere ud af den udbyder. Der er ingen nemme metoder til at downloade det fulde datasæt gennem en fysisk backup. Hos de fleste udbydere er kun manuelt udførte logiske sikkerhedskopier tilgængelige. Selvfølgelig er der altid muligheder for at opnå dette, men det er typisk en kompleks, tidskrævende proces, som trods alt stadig kan kræve noget nedetid.
Brug af en udbyder som Amazon RDS kommer også med begrænsninger. Nogle handlinger kan ikke let udføres, hvilket ville være meget nemt at udføre i miljøer, der er implementeret på en fuldt brugerstyret måde (f.eks. AWS EC2). Nogle af disse begrænsninger er allerede blevet dækket i andre blogs, men for at opsummere er, at ingen DBaaS-tjeneste giver dig det samme niveau af fleksibilitet som almindelig MySQL GTID-baseret replikering. Du kan promovere enhver slave, du kan gen-slave hver node fra enhver anden ... stort set alle handlinger er mulige. Med værktøjer som RDS står du over for design-inducerede begrænsninger, som du ikke kan omgå.
Problemet er også evnen til at forstå ydeevnedetaljer. Når du designer dit eget meget tilgængelige opsætning, bliver du vidende om potentielle ydeevneproblemer, der kan dukke op. På den anden side er RDS og lignende miljøer stort set "sorte bokse." Ja, vi har erfaret, at Amazon RDS bruger DRBD til at skabe en skyggekopi af masteren, vi ved, at Aurora bruger delt, replikeret lager til at implementere meget hurtige failovers. Det er bare en generel viden. Vi kan ikke fortælle, hvad der er præstationsimplikationerne af disse løsninger ud over det, vi tilfældigt bemærker. Hvad er almindelige problemer forbundet med dem? Hvor stabile er disse løsninger? Kun udviklerne bag løsningen ved det med sikkerhed.
Hvad er alternativet til DBaaS-løsninger?
Du undrer dig måske, er der et alternativ til DBaaS? Det er trods alt så praktisk at køre den administrerede tjeneste, hvor du kan få adgang til de fleste af de typiske handlinger via brugergrænsefladen. Du kan oprette og gendanne sikkerhedskopier, failover håndteres automatisk for dig. Miljøet er let at bruge, hvilket kan være overbevisende for virksomheder, der ikke har dedikeret og erfarent personale til at håndtere databaser.
ClusterControl giver et godt alternativ til cloud-baserede DBaaS-tjenester. Det giver dig en grafisk brugergrænseflade, som kan bruges til at implementere, administrere og overvåge open source-databaser.
Med et par klik kan du nemt implementere en meget tilgængelig databaseklynge med automatiseret failover (hurtigere end de fleste af DBaaS-tilbuddene), sikkerhedskopieringsstyring, avanceret overvågning og andre funktioner som integration med eksterne værktøjer (f.eks. Slack eller PagerDuty) eller opgraderingsstyring. Alt dette samtidig med, at man helt undgår leverandørlåsning.
ClusterControl er ligeglad med, hvor dine databaser er placeret, så længe den kan oprette forbindelse til dem ved hjælp af SSH. Du kan have opsætninger i cloud, on-prem eller i et blandet miljø af flere cloud-udbydere. Så længe der er forbindelse, vil ClusterControl være i stand til at styre miljøet. Ved at bruge de løsninger, du ønsker (og ikke dem, du ikke kender eller kender til), kan du tage fuld kontrol over miljøet på ethvert tidspunkt.
Uanset hvilken opsætning du har implementeret med ClusterControl, kan du nemt administrere den på en mere traditionel, manuel eller scriptet måde. ClusterControl giver dig endda kommandolinjegrænseflade, som giver dig mulighed for at inkorporere opgaver udført af ClusterControl i dine shell-scripts. Du har al den kontrol, du ønsker - intet er en sort boks, hvert stykke af miljøet ville blive bygget ved hjælp af open source-løsninger kombineret og implementeret af ClusterControl.
Lad os tage et kig på, hvor nemt du kan implementere en MySQL-replikeringsklynge ved hjælp af ClusterControl. Lad os antage, at du har forberedt miljøet med ClusterControl installeret på én instans og alle andre noder tilgængelige via SSH fra ClusterControl-værten.
Vi starter med at vælge "Deploy"-guiden.
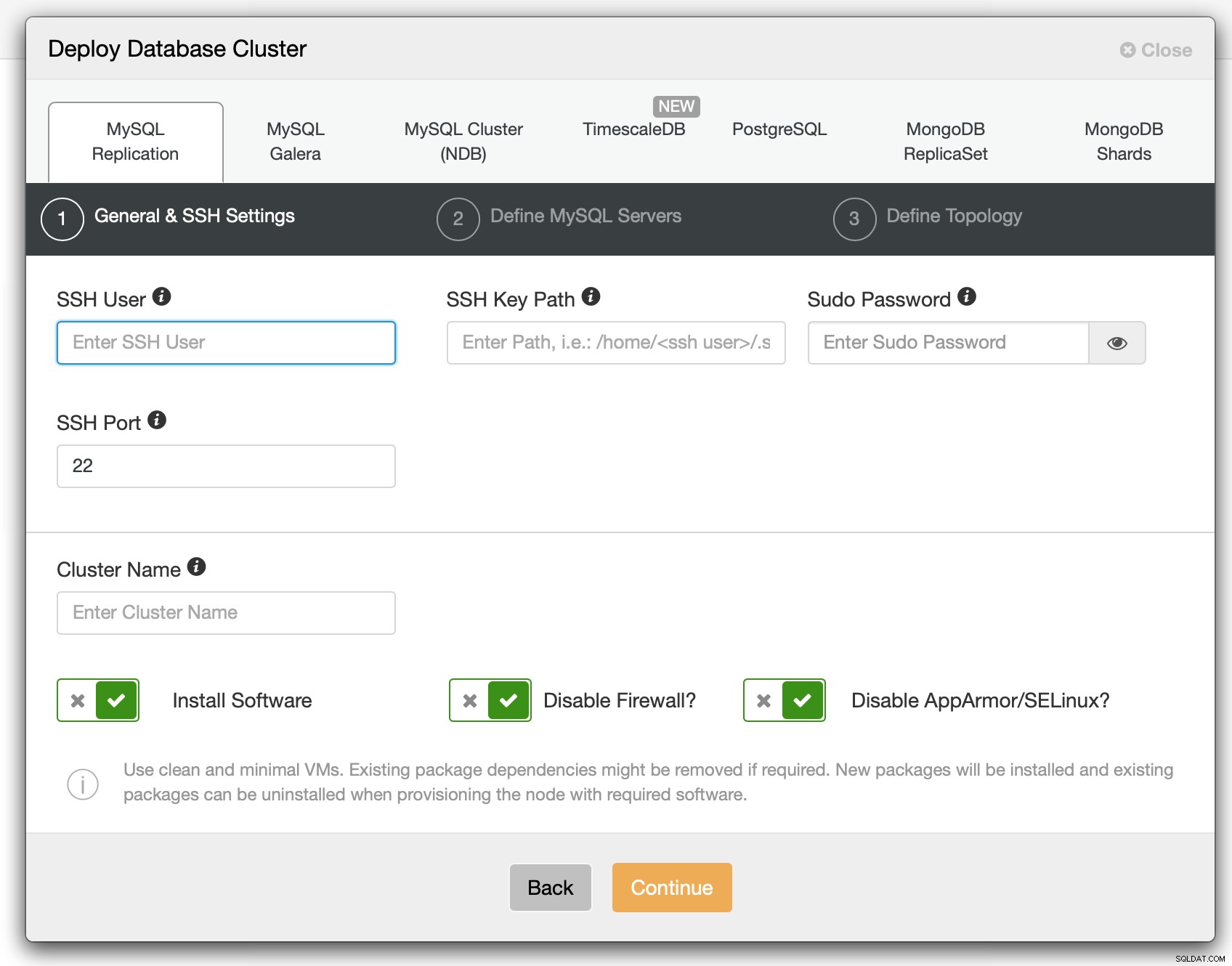
På det første trin skal vi definere, hvordan ClusterControl skal oprette forbindelse til noderne på hvilke databaser der skal installeres. Både root-adgang eller sudo (med eller uden adgangskode) understøttes.
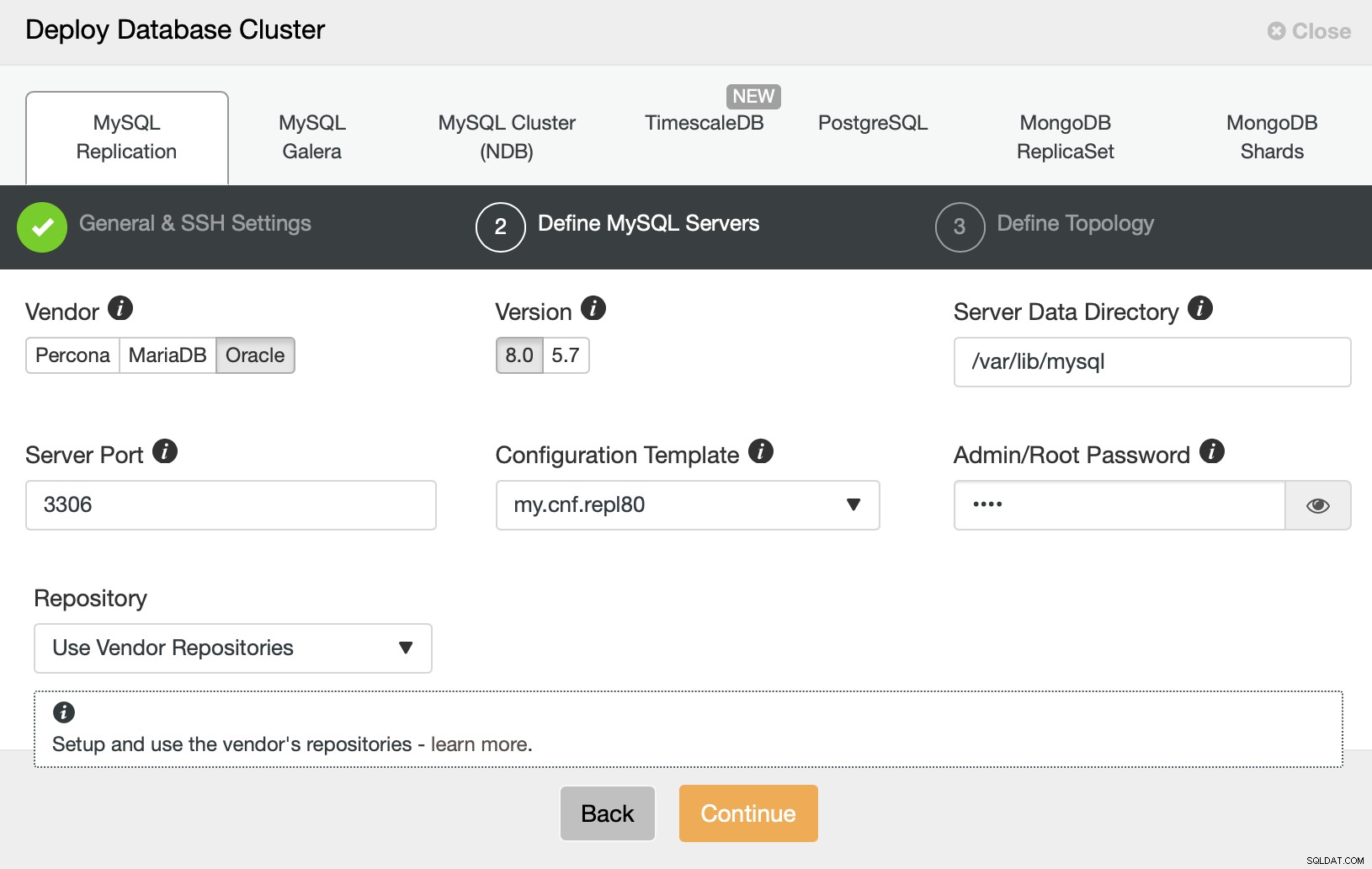
Derefter vil vi vælge en leverandør, version og videregive adgangskoden til den administrative bruger i vores MySQL-database.
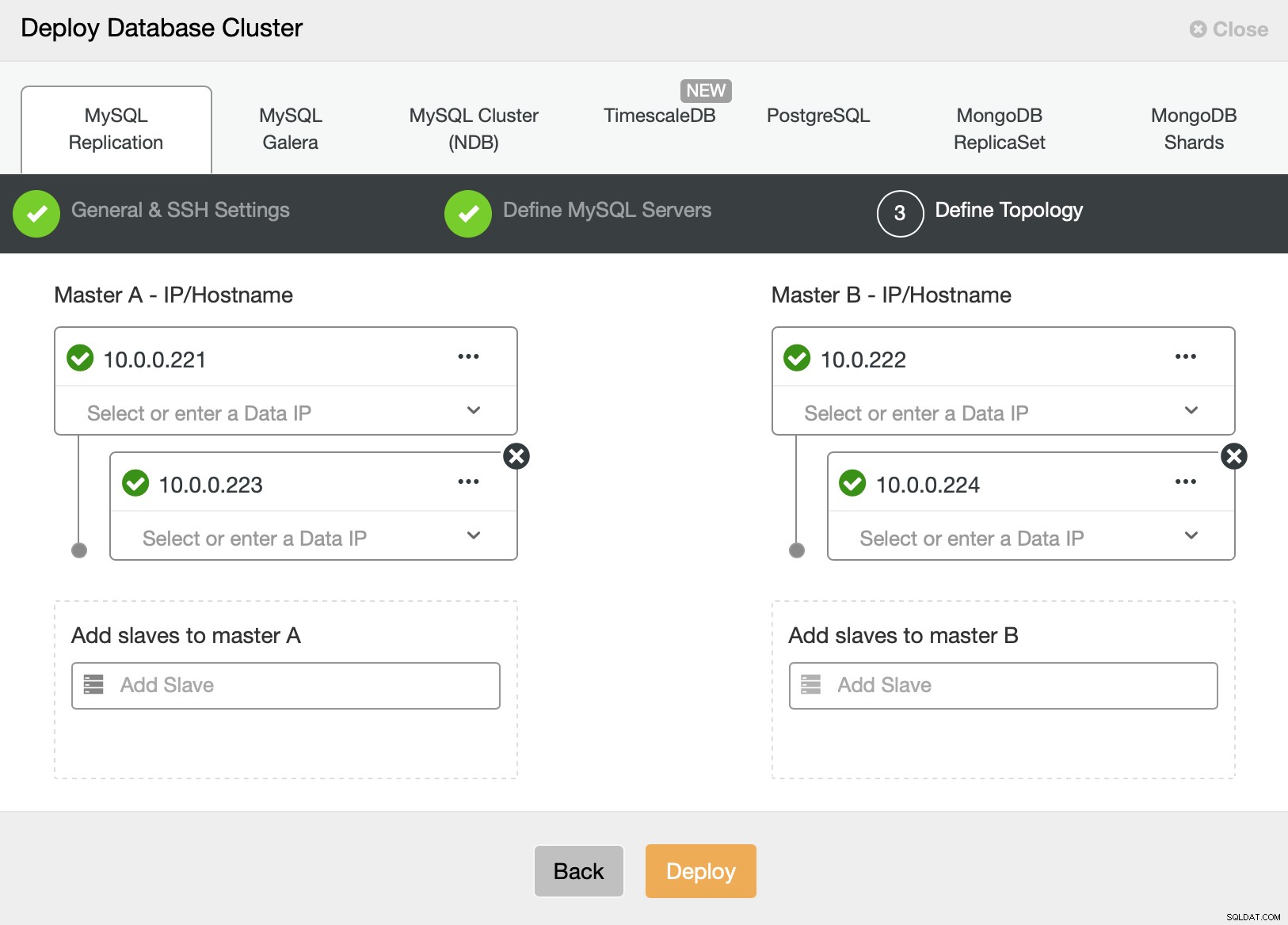
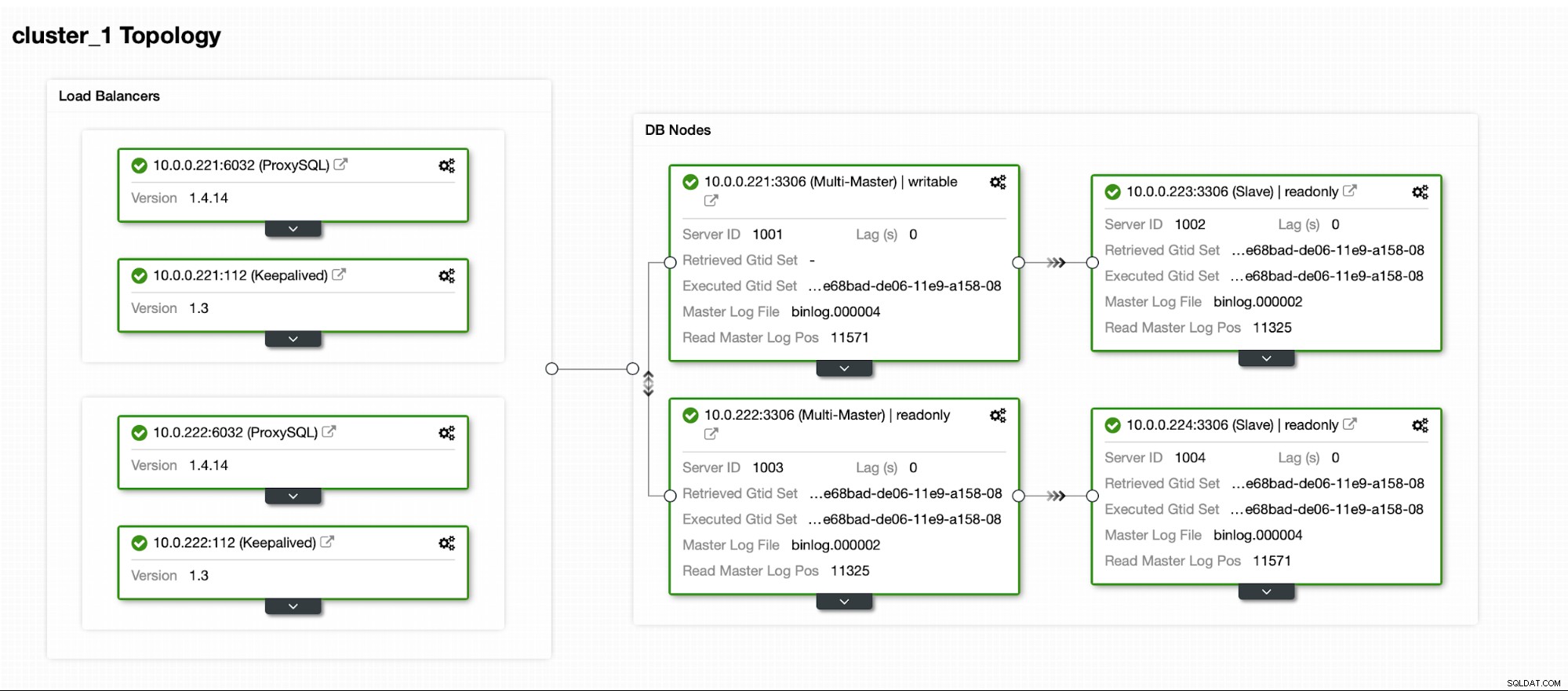
Til sidst vil vi definere topologien for vores nye klynge. Som du kan se, er dette allerede en ret kompleks opsætning, i modsætning til noget, du kan implementere ved hjælp af AWS RDS eller GCP SQL node.
Alt, vi skal gøre nu, er at vente på, at processen er fuldført. ClusterControl vil gøre sit bedste for at forstå det miljø, det implementerer til, og installere det nødvendige sæt pakker, inklusive selve databasen.

Når klyngen er oppe og køre, kan du fortsætte med at implementere proxylaget (som vil give din applikation et enkelt indgangspunkt til databaselaget). Det er mere eller mindre det, der sker bag kulisserne med DBaaS, hvor man også har endepunkter til at forbinde til databaseklyngen. Det er ret almindeligt at bruge et enkelt endepunkt til at skrive og flere endepunkter til at nå bestemte replikaer.
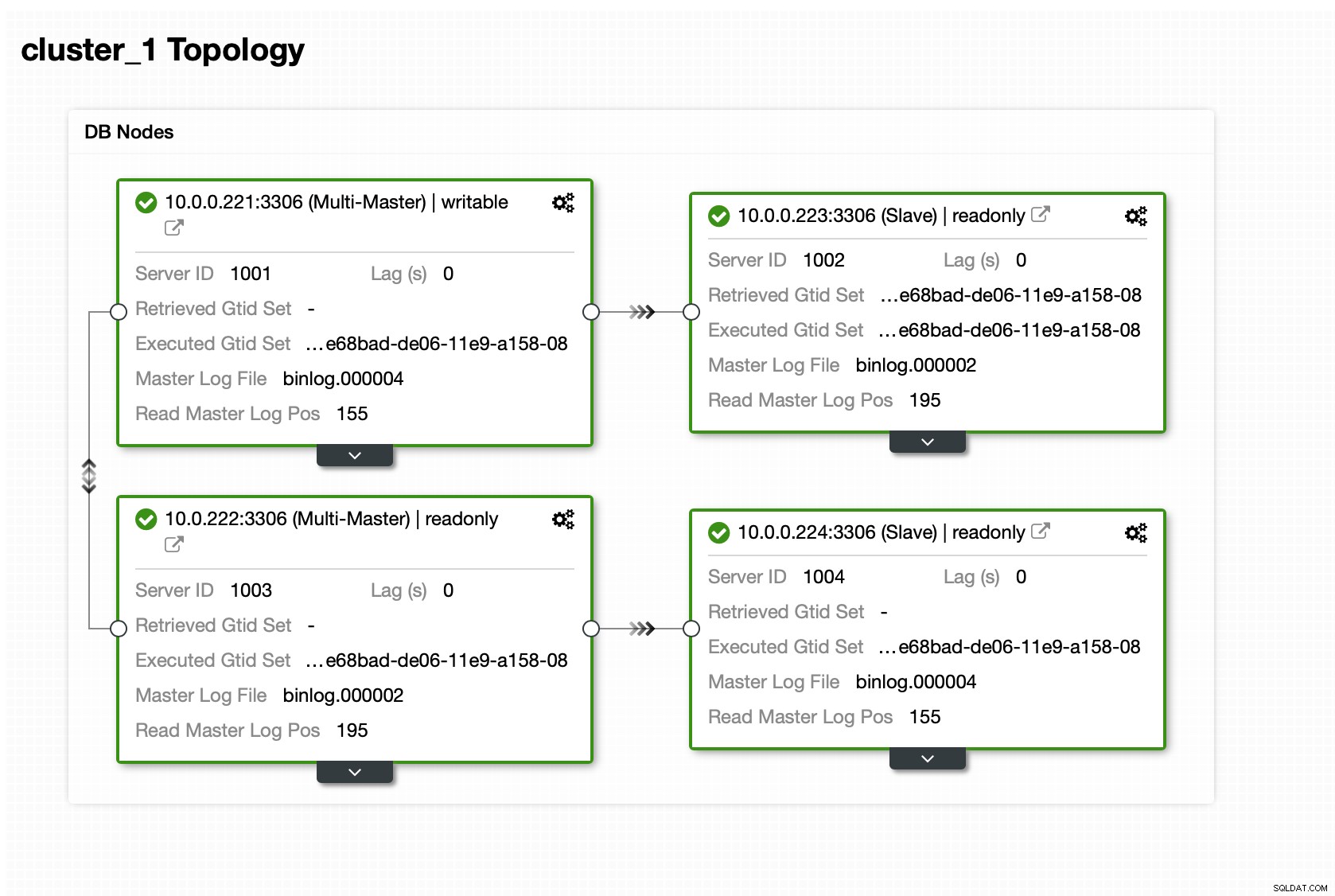
Her vil vi bruge ProxySQL, som vil gøre det beskidte arbejde for os - det vil forstå topologien, sender kun skrivelser til masteren og load balance skrivebeskyttede forespørgsler på tværs af alle replikaer, vi har.
For at implementere ProxySQL går vi til Administrer -> Load Balancers.
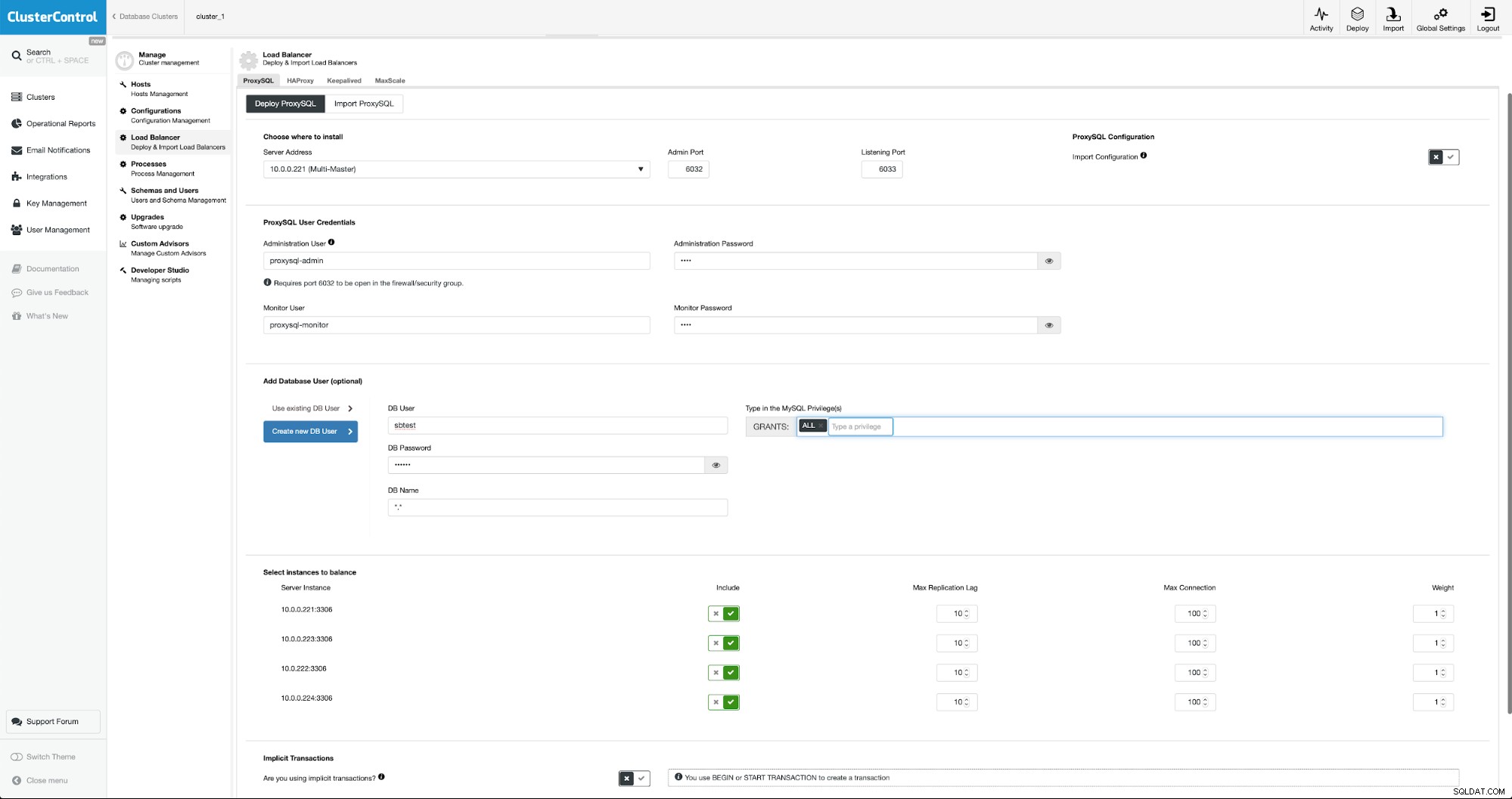
Vi skal udfylde alle påkrævede felter:værter, der skal implementeres på, legitimationsoplysninger for den administrative og overvågende bruger, kan vi importere eksisterende bruger fra MySQL til ProxySQL eller oprette en ny. Alle detaljer om ProxySQL kan nemt findes i flere blogs i vores blogsektion.
Vi ønsker, at mindst to ProxySQL-noder skal installeres for at sikre høj tilgængelighed. Så, når de er implementeret, vil vi implementere Keepalived oven på ProxySQL. Dette vil sikre, at Virtual IP konfigureres og peger på en af ProxySQL-forekomsterne, så længe der vil være mindst én sund node.
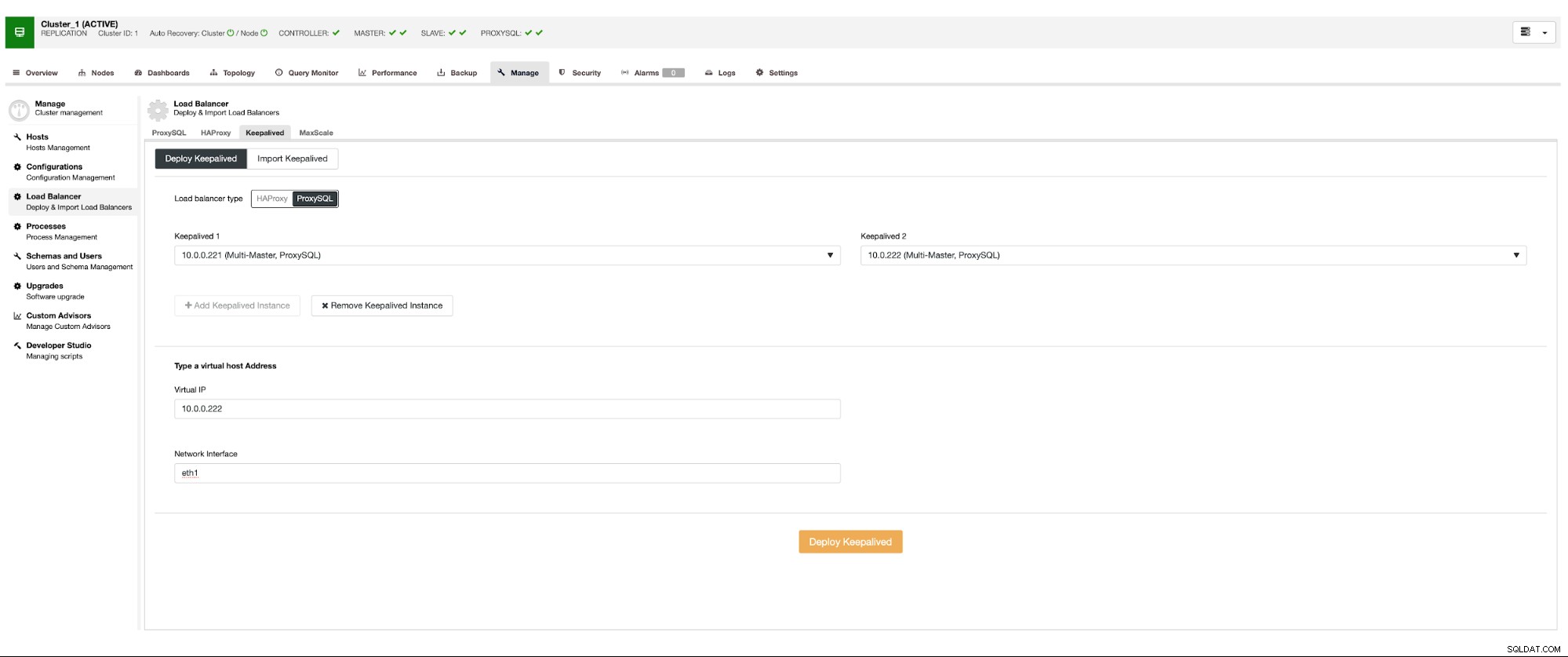
Her er det eneste potentielle problem, hvis du bruger skymiljøer, hvor routing fungerer på en måde, så du ikke nemt kan få en netværksgrænseflade frem. I et sådant tilfælde bliver du nødt til at ændre konfigurationen af Keepalived, introducere 'notify_master' script og bruge et script, som vil foretage de nødvendige IP ændringer - i tilfælde af EC2 vil det skulle frakoble Elastic IP fra én vært og knytte det til anden vært.
Der er masser af instruktioner om, hvordan man gør det ved at bruge bredt testet open source-software i opsætninger implementeret af ClusterControl. Du kan nemt finde yderligere oplysninger, tips og vejledninger, der er relevante for dit særlige miljø.
Konklusion
Vi håber, du fandt dette blogindlæg indsigtsfuldt. Hvis du gerne vil teste ClusterControl, kommer den med en 30 dages virksomhedsprøve, hvor du har alle funktionerne til rådighed. Du kan downloade det gratis og teste, om det passer ind i dit miljø.