For et par uger siden skrev jeg om, hvor overrasket jeg var over udførelsen af en ny indbygget funktion i SQL Server 2016, STRING_SPLIT() :
- Ydeevne-overraskelser og antagelser:STRING_SPLIT()
Efter at indlægget blev offentliggjort, fik jeg et par kommentarer (offentligt og privat) med disse forslag (eller spørgsmål, som jeg forvandlede til forslag):
- Angivelse af en eksplicit outputdatatype for JSON-tilgangen, så denne metode ikke lider under potentielle ydeevneomkostninger på grund af tilbagefaldet af
nvarchar(max). - Test en lidt anden tilgang, hvor der rent faktisk bliver gjort noget med dataene – nemlig
SELECT INTO #temp. - Viser, hvordan estimerede rækkeantal sammenligner med eksisterende metoder, især ved indlejring af opdelte operationer.
Jeg svarede nogle personer offline, men tænkte, at det ville være værd at skrive en opfølgning her.
Vær mere retfærdig over for JSON
Den originale JSON-funktion så sådan ud uden specifikation for outputdatatype:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Jeg omdøbte det og oprettede to mere med følgende definitioner:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Jeg troede, at dette ville forbedre ydeevnen drastisk, men desværre var det ikke tilfældet. Jeg kørte testene igen, og resultaterne var som følger:
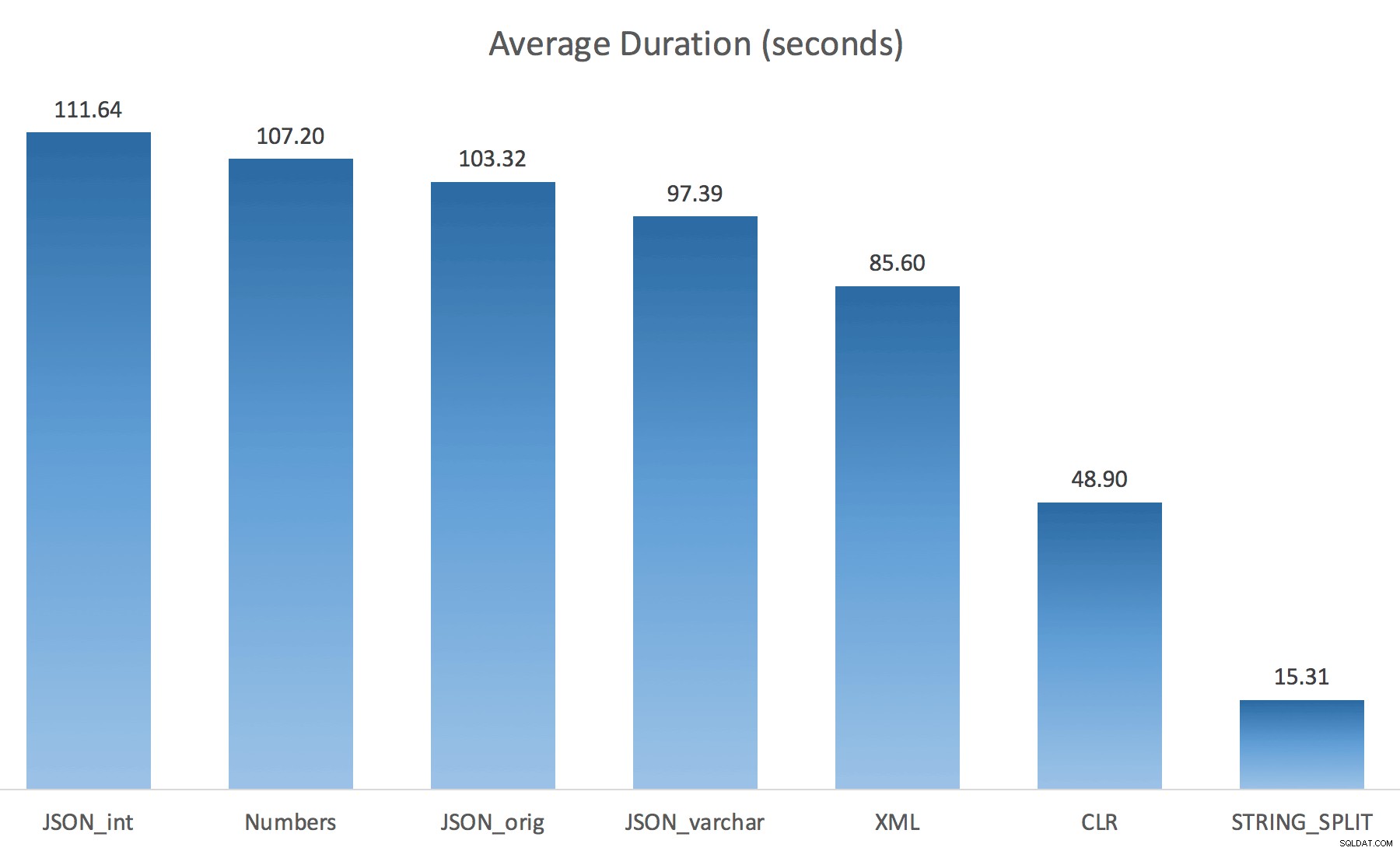
Ventetiden observeret under en tilfældig forekomst af testen (filtreret til dem> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Tal | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1.616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Venter observeret> 25 (bemærk, at der ikke er nogen post for STRING_SPLIT )
Mens du skifter fra standard til varchar(100) forbedrede ydeevnen lidt, forstærkningen var ubetydelig, og skiftede til int faktisk gjort det værre. Tilføj til dette, at du sandsynligvis skal tilføje STRING_ESCAPE() til den indkommende streng i nogle scenarier, bare hvis de har tegn, der vil ødelægge JSON-parsing. Min konklusion er stadig, at dette er en pæn måde at bruge den nye JSON-funktionalitet på, men for det meste en nyhed, der er upassende i en rimelig skala.
Materialisering af output
Jonathan Magnan gjorde denne skarpsindige observation på mit tidligere indlæg:
STRING_SPLIT er faktisk meget hurtig, men også langsom som fanden, når du arbejder med midlertidige tabeller (medmindre det bliver rettet i en fremtidig build).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Vil være MEGET langsommere end SQL CLR-løsning (15x og mere!).
Så jeg gravede i. Jeg oprettede kode, der ville kalde hver af mine funktioner og dumpe resultaterne i en #temp-tabel og time dem:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Jeg kørte bare hver test én gang (i stedet for at sløjfe 100 gange), fordi jeg ikke ville fuldstændig tæske I/O'en på mit system. Alligevel, efter at have kørt i gennemsnit tre testkørsler, havde Jonathan helt, 100% ret. Her var varigheden af at udfylde en #temp-tabel med ~500.000 rækker ved hjælp af hver metode:
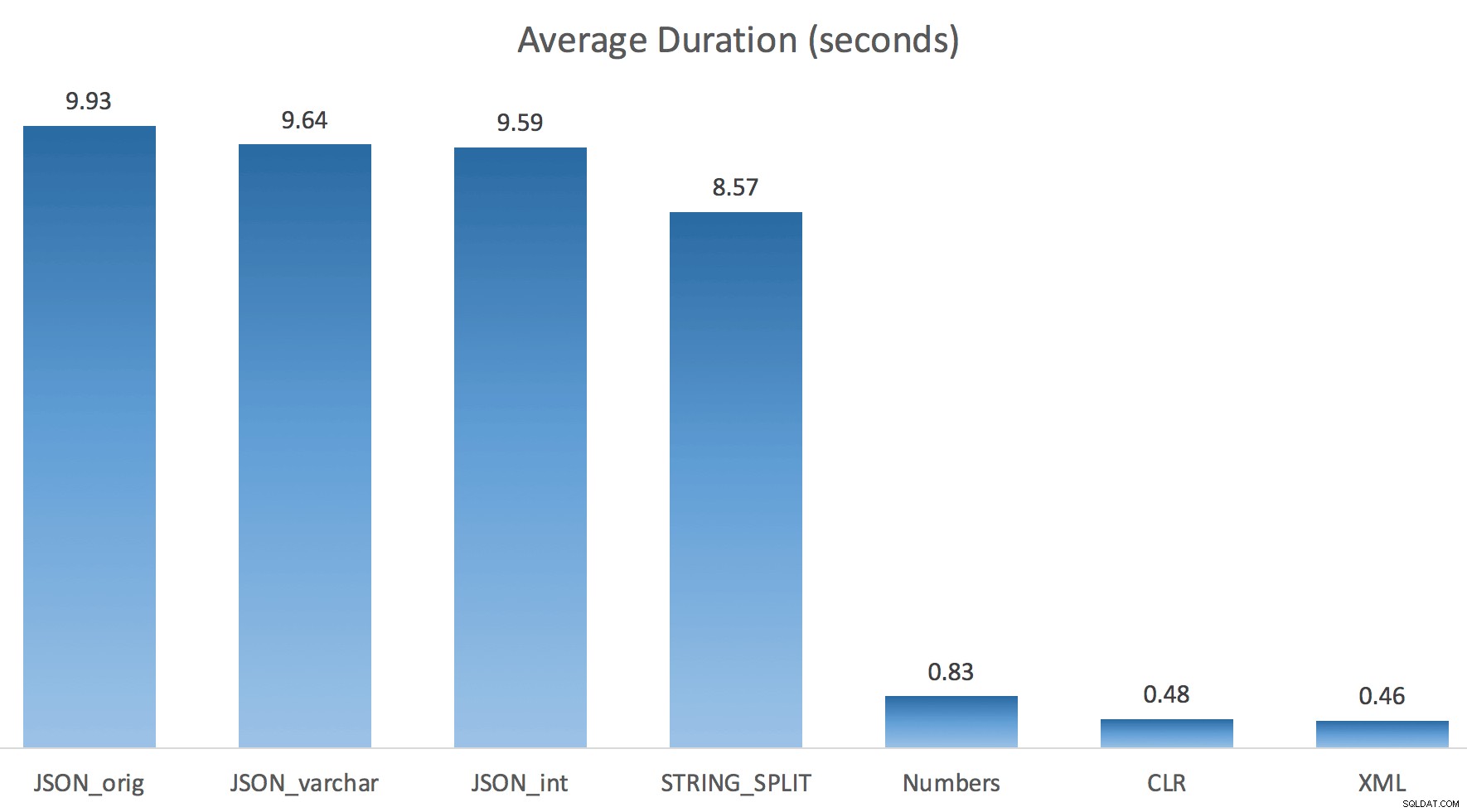
Så her, JSON og STRING_SPLIT metoderne tog omkring 10 sekunder hver, mens taltabellen, CLR og XML-tilgange tog mindre end et sekund. Forvirret undersøgte jeg ventetiden, og ganske vist pådrog de fire metoder til venstre betydelige LATCH_EX venter (ca. 25 sekunder) ikke set i de tre andre, og der var ingen andre væsentlige ventetider at tale om.
Og da låseventerne var større end den samlede varighed, gav det mig et fingerpeg om, at dette havde at gøre med parallelitet (denne særlige maskine har 4 kerner). Så jeg genererede testkode igen, og ændrede kun en linje for at se, hvad der ville ske uden parallelitet:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Nu STRING_SPLIT klarede sig meget bedre (ligesom JSON-metoderne), men stadig mindst dobbelt så lang tid, som CLR tog:
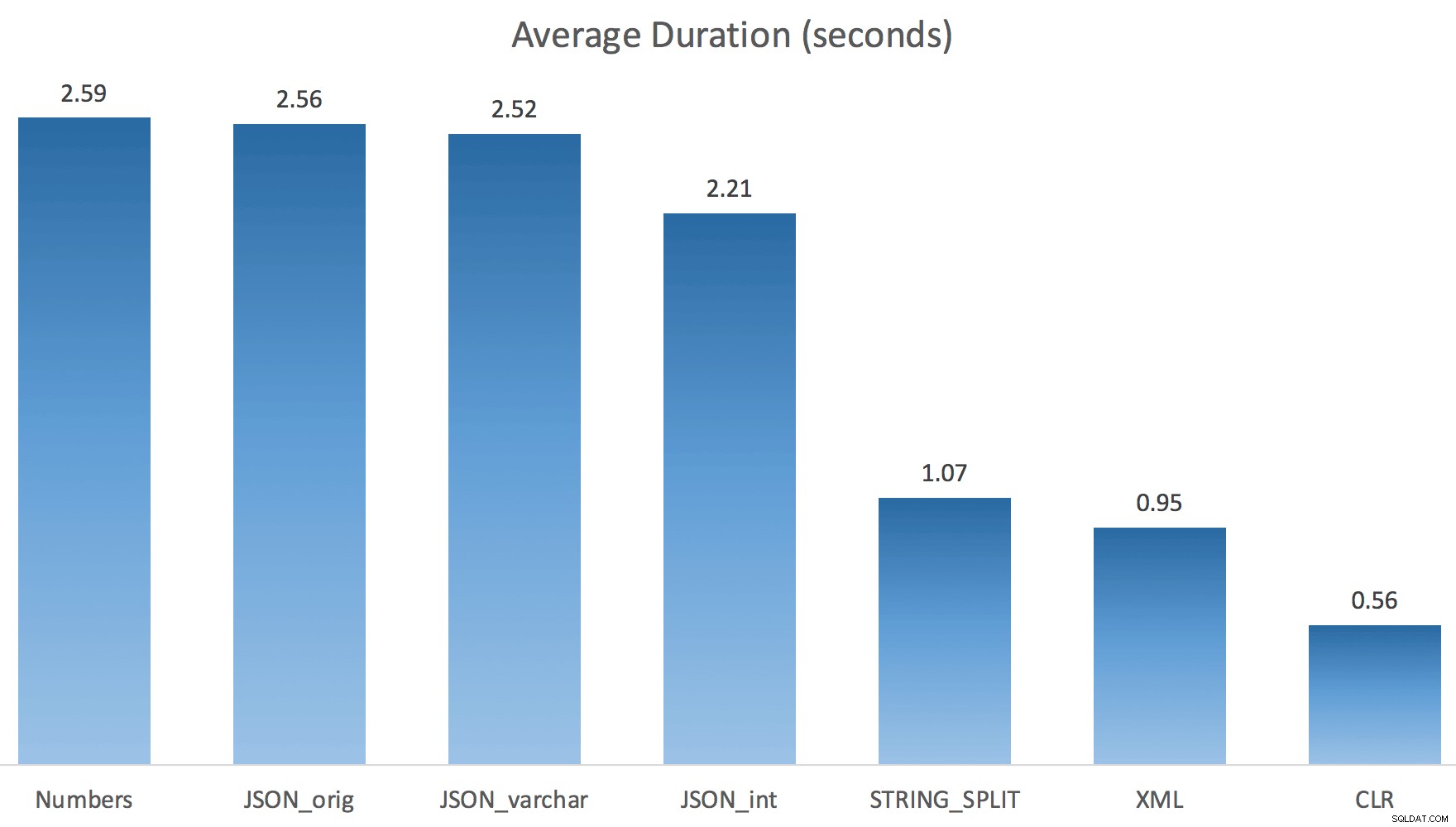
Så der kan være et tilbageværende problem i disse nye metoder, når parallelisme er involveret. Det var ikke et problem med trådfordeling (jeg tjekkede det), og CLR havde faktisk dårligere estimater (100x faktisk vs. kun 5x for STRING_SPLIT ); bare et underliggende problem med koordinering af låse mellem tråde, formoder jeg. Indtil videre kan det være umagen værd at bruge MAXDOP 1 hvis du ved, at du skriver outputtet på nye sider.
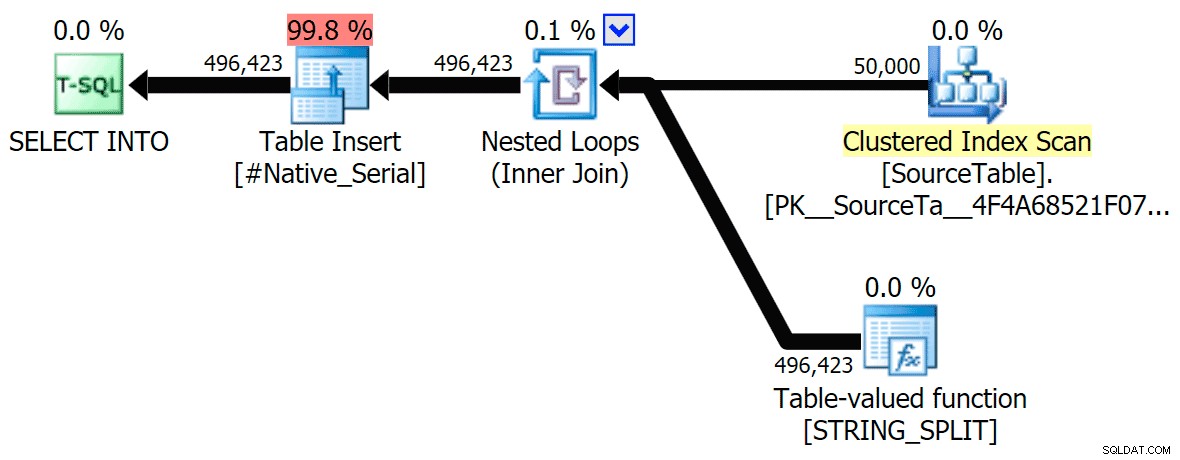
Jeg har inkluderet de grafiske planer, der sammenligner CLR-tilgangen med den oprindelige, til både parallel og seriel udførelse (jeg har også uploadet en Query Analysis-fil, som du kan åbne i SQL Sentry Plan Explorer for at snuse rundt på egen hånd):
STRING_SPLIT
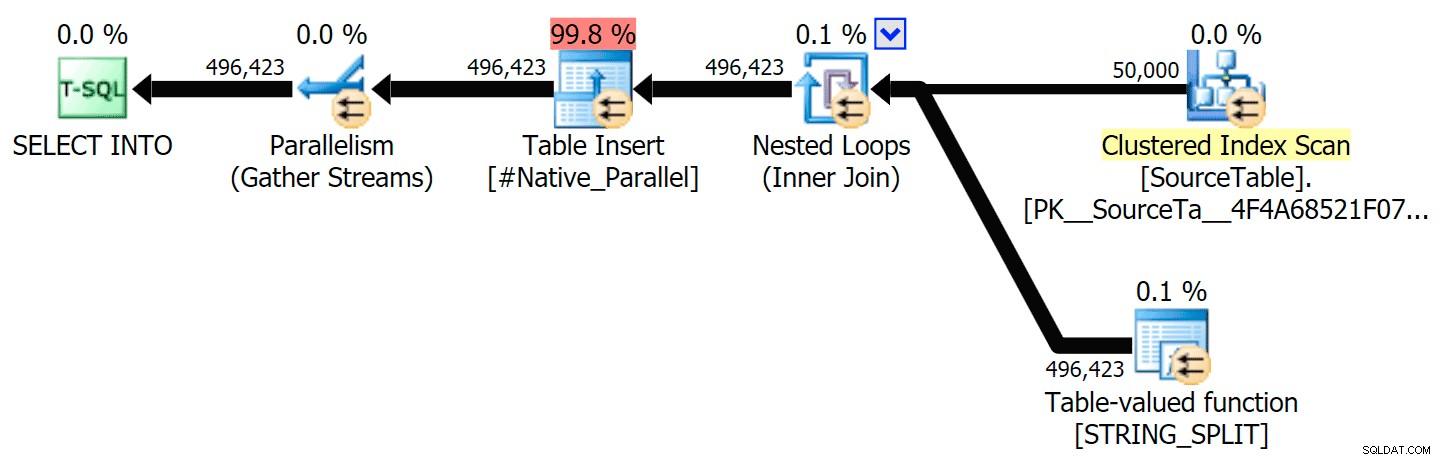
CLR
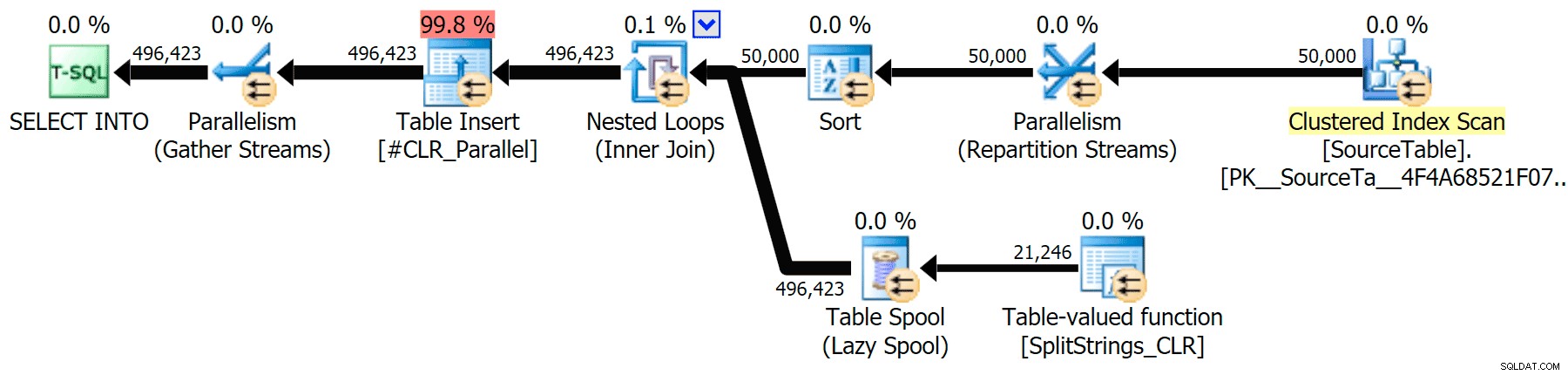
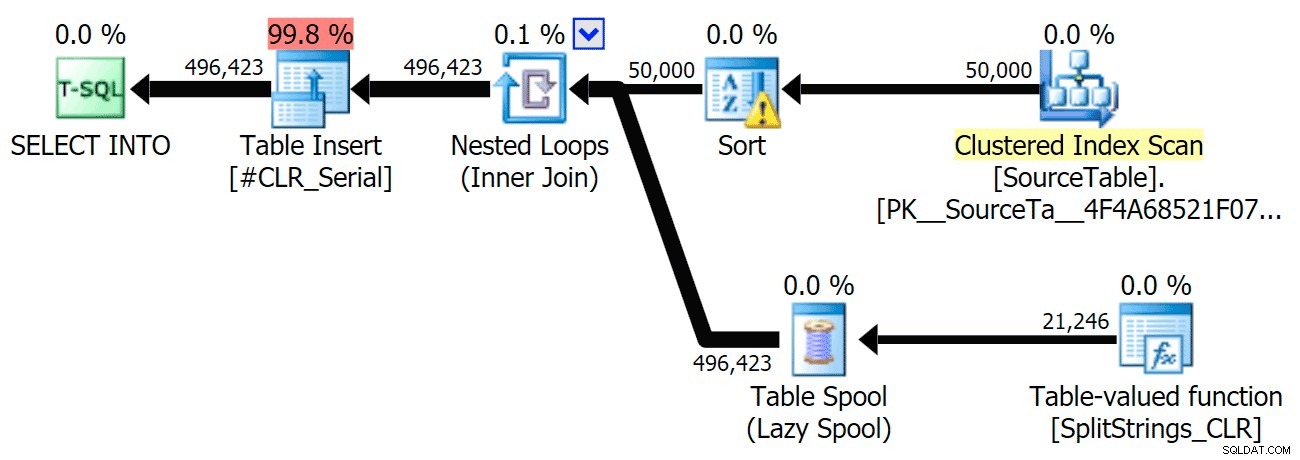
Sorteringsadvarslen, FYI, var ikke noget for chokerende og havde åbenbart ikke meget håndgribelig effekt på forespørgslens varighed:

- StringSplit.queryanalysis.zip (25 kb)
Spoler ud til sommer
Da jeg så lidt nærmere på de planer, lagde jeg mærke til, at der i CLR-planen er en doven spole. Dette er introduceret for at sikre, at dubletter behandles sammen (for at spare arbejde ved at lave mindre faktisk opsplitning), men denne spole er ikke altid mulig i alle planformer, og det kan give lidt af en fordel for dem, der kan bruge det ( fx CLR-planen), afhængigt af estimater. For at sammenligne uden spoler aktiverede jeg sporingsflag 8690 og kørte testene igen. For det første er her den parallelle CLR-plan uden spolen:
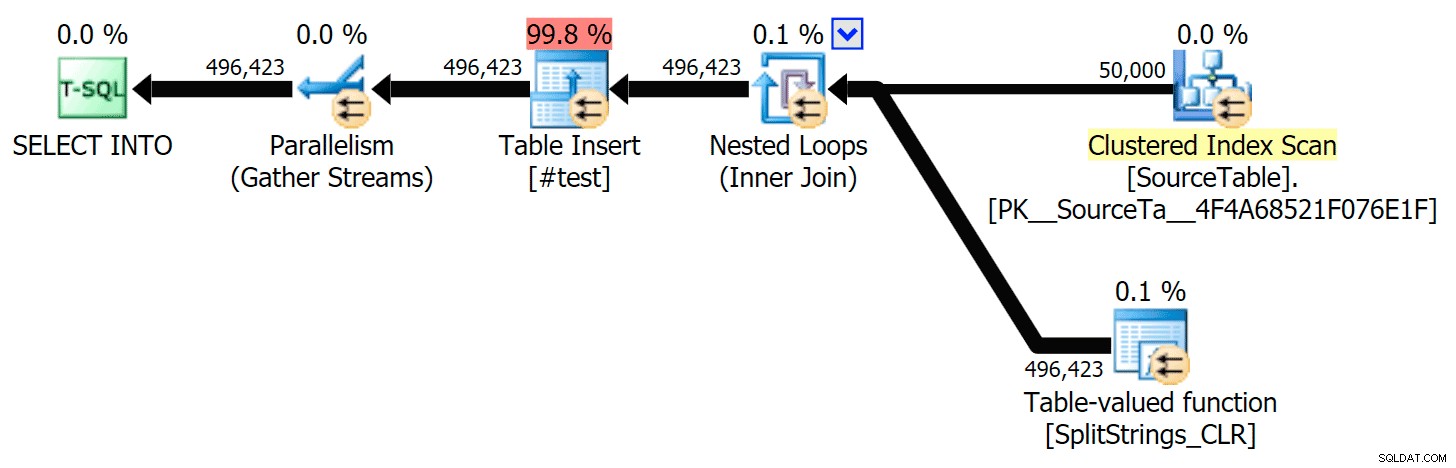
Og her var de nye varigheder for alle forespørgsler, der går parallelt med TF 8690 aktiveret:
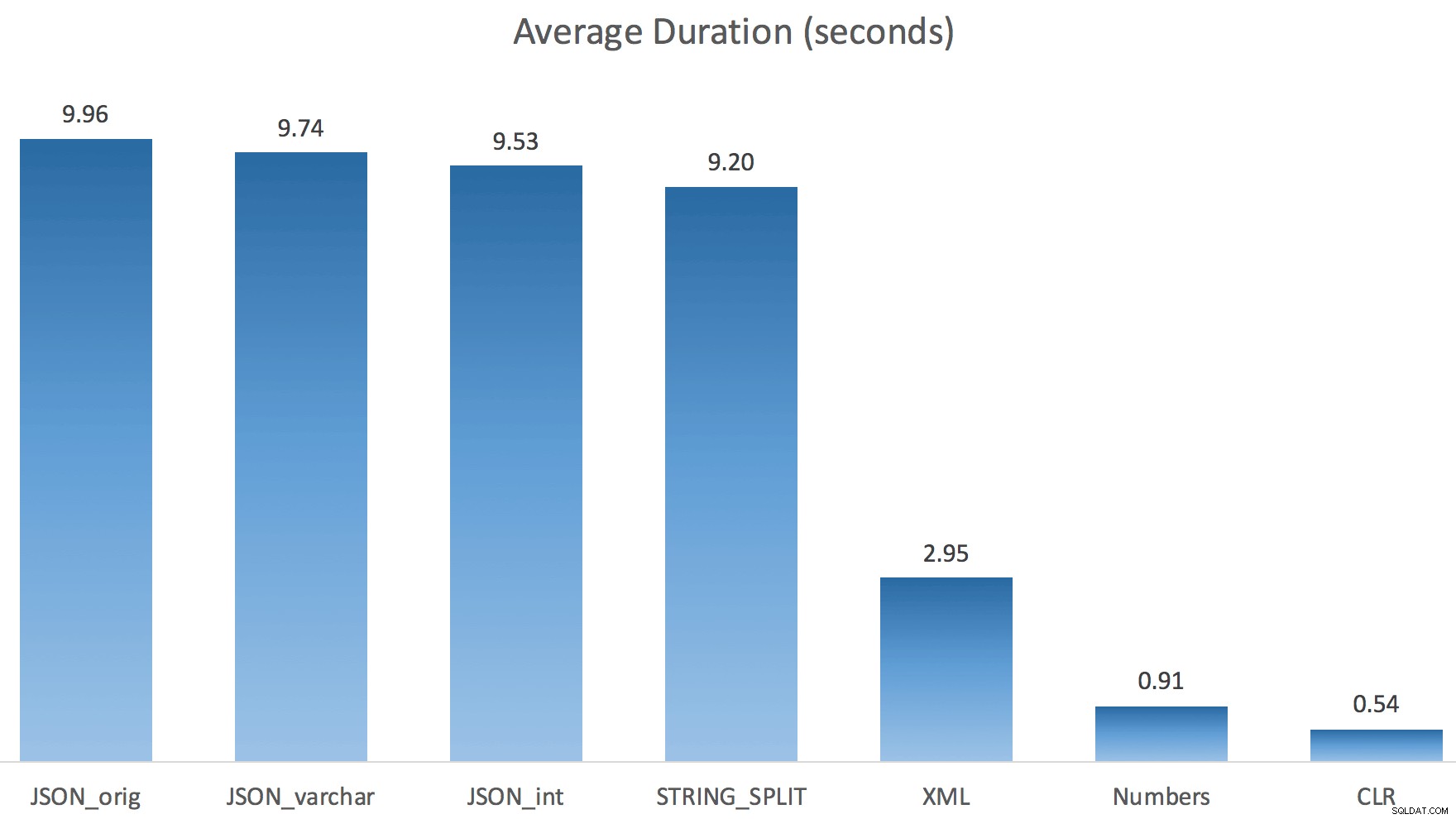
Her er den serielle CLR-plan uden spolen:
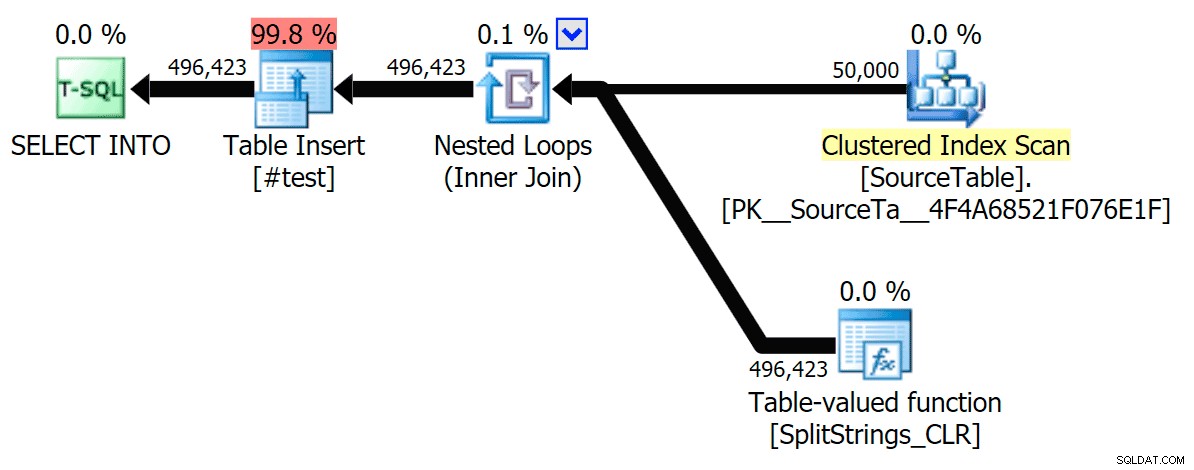
Og her var timingresultaterne for forespørgsler, der bruger både TF 8690 og MAXDOP 1 :
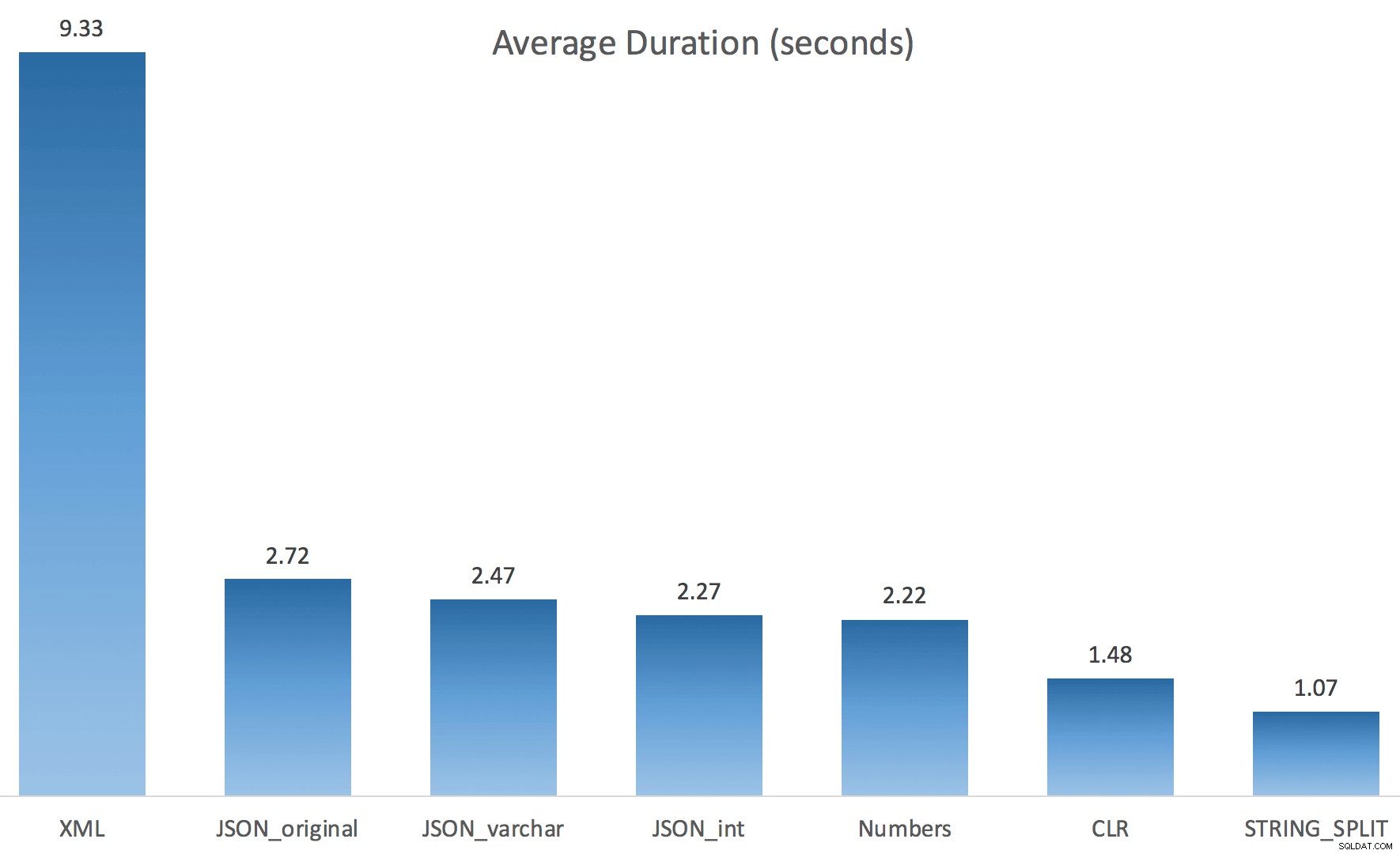
(Bemærk, at bortset fra XML-planen ændrede de fleste af de andre sig slet ikke, med eller uden sporingsflaget.)
Sammenligning af estimerede rækkeantal
Dan Holmes stillede følgende spørgsmål:
Hvordan estimerer den datastørrelsen, når den forbindes med en anden (eller flere) opdelt funktion? Linket nedenfor er en opskrivning af en CLR-baseret splitimplementering. Gør 2016 et 'bedre' arbejde med dataestimater? (Jeg har desværre ikke mulighed for at installere RC'en endnu).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Så jeg swipede koden fra Dans indlæg, ændrede den til at bruge mine funktioner og kørte den gennem Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
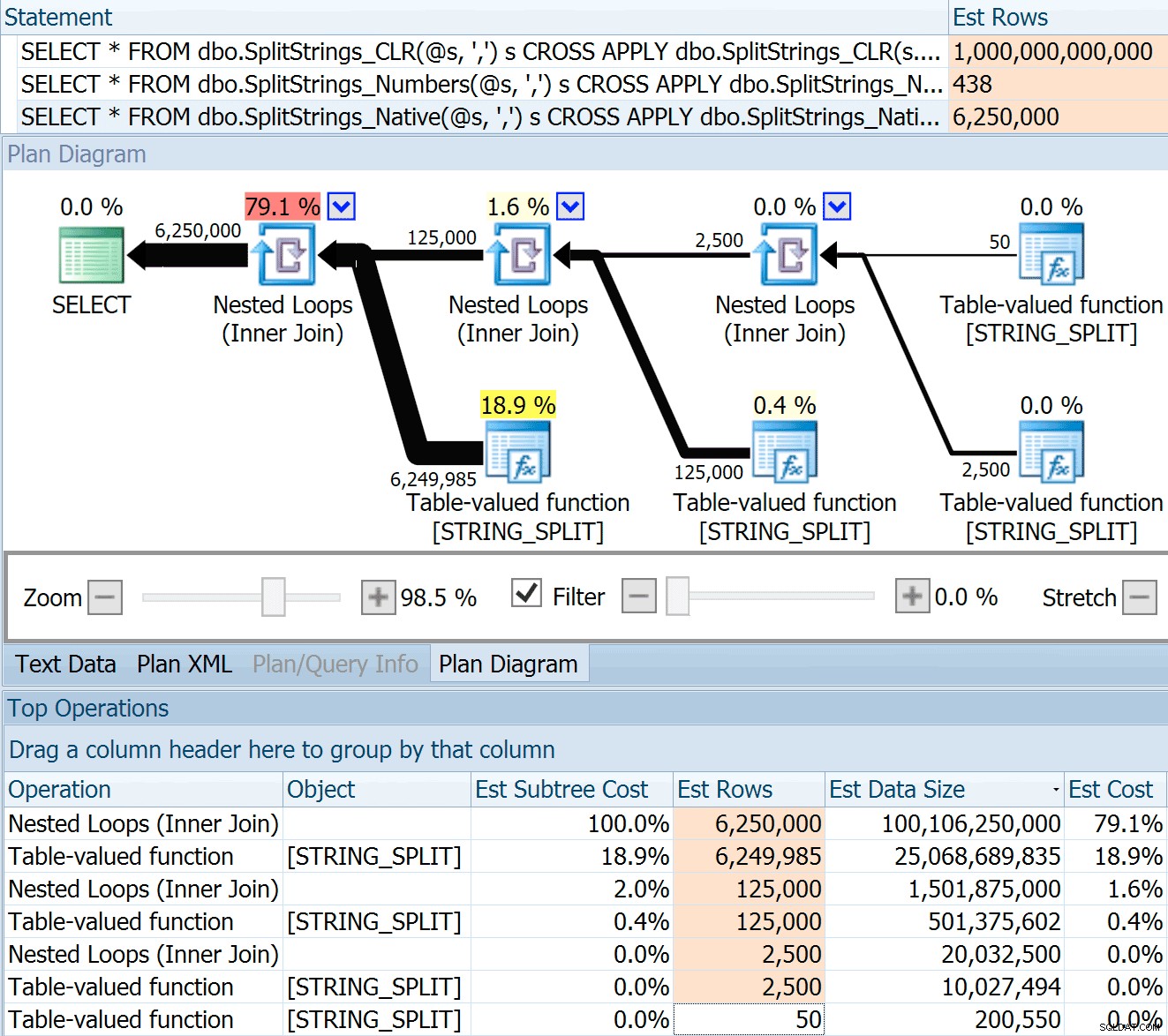
Bemærk:OPENJSON() opfører sig på nøjagtig samme måde som STRING_SPLIT – det antager også, at der kommer 50 rækker ud af en given opdelingsoperation. Jeg tænker, at det kunne være nyttigt at have en måde at antyde kardinalitet for funktioner som denne, ud over sporingsflag som 4137 (før 2014), 9471 &9472 (2014+) og selvfølgelig 9481...
Dette estimat på 6,25 millioner rækker er ikke fantastisk, men det er meget bedre end CLR-tilgangen, som Dan talte om, som estimerer EN TRILLION RÆKKER , og jeg mistede antallet af kommaer til at bestemme datastørrelsen – 16 petabyte? exabytes?
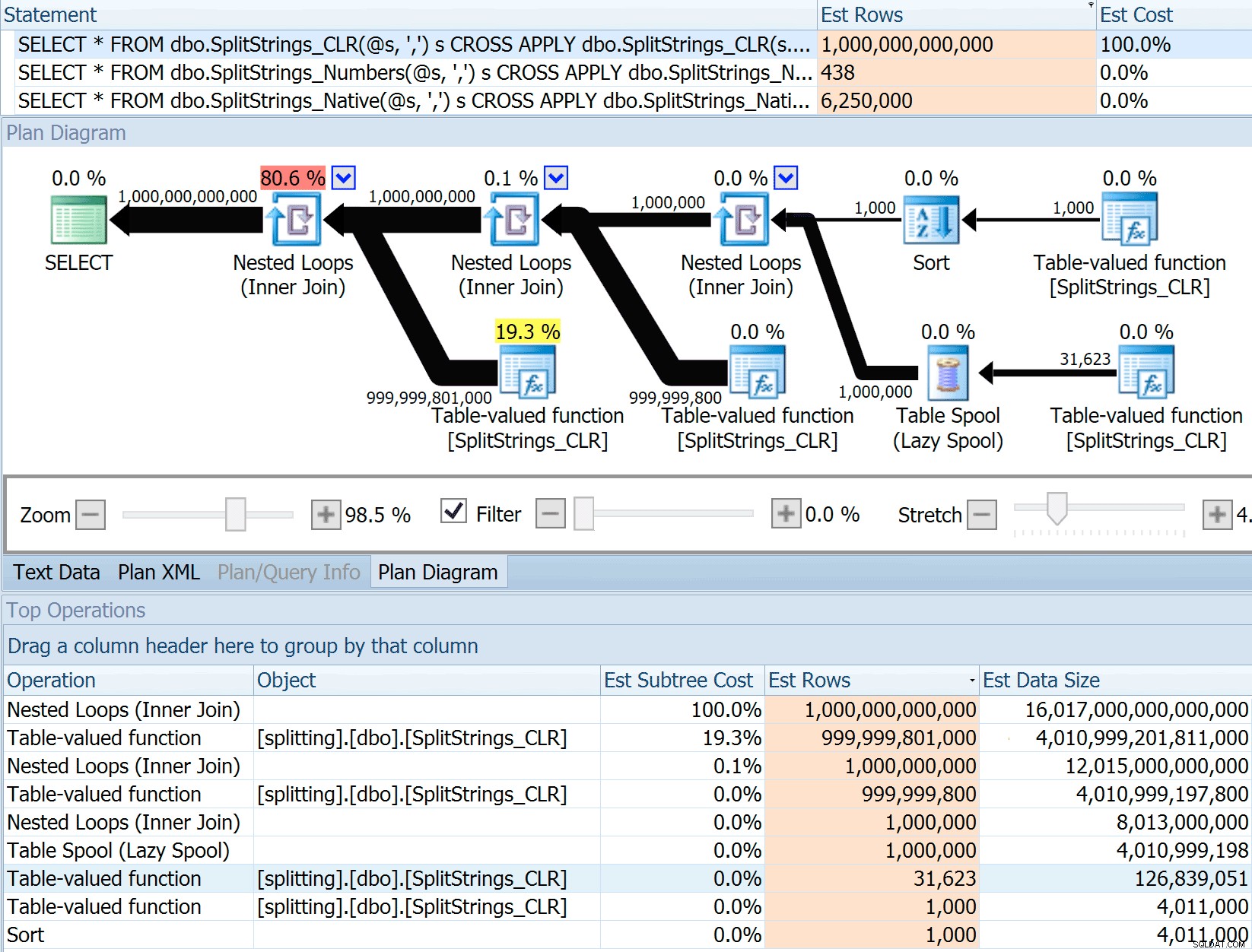
Nogle af de andre tilgange klarer sig naturligvis bedre med hensyn til estimater. Numbers-tabellen estimerede for eksempel en meget mere rimelig 438 rækker (i SQL Server 2016 RC2). Hvor kommer dette tal fra? Nå, der er 8.000 rækker i tabellen, og hvis du husker det, har funktionen både et ligheds- og et ulighedsprædikat:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Så SQL Server multiplicerer antallet af rækker i tabellen med 10 % (som et gæt) for lighedsfilteret og derefter kvadratroden på 30 % (igen et gæt) for ulighedsfilteret. Kvadratroden skyldes eksponentiel backoff, som Paul White forklarer her. Dette giver os:
8000 * 0,1 * SQRT(0,3) =438,178XML-variationen estimerede lidt over en milliard rækker (på grund af en tabelspole anslået til at blive udført 5,8 millioner gange), men dens plan var alt for kompleks til at forsøge at illustrere her. Under alle omstændigheder skal du huske, at estimater tydeligvis ikke fortæller hele historien – bare fordi en forespørgsel har mere nøjagtige estimater, betyder det ikke, at den vil yde bedre.
Der var et par andre måder, jeg kunne justere estimaterne lidt på:nemlig at fremtvinge den gamle kardinalitetsestimatmodel (som påvirkede både XML- og Numbers-tabelvariationerne) og bruge TF'erne 9471 og 9472 (som kun påvirkede Numbers-tabelvariationen, da de kontrollerer begge kardinalitet omkring flere prædikater). Her var måderne, hvorpå jeg kunne ændre estimaterne en lille smule (eller MEGET). , i tilfælde af tilbagevenden til den gamle CE-model):

Den gamle CE-model bragte XML-estimaterne ned med en størrelsesorden, men for taltabellen sprængte den fuldstændigt i luften. Prædikatflagene ændrede estimaterne for taltabellen, men disse ændringer er meget mindre interessante.
Ingen af disse sporingsflag havde nogen effekt på estimaterne for CLR, JSON eller STRING_SPLIT variationer.
Konklusion
Så hvad lærte jeg her? En hel flok, faktisk:
- Parallelisme kan hjælpe i nogle tilfælde, men når det ikke hjælper, er det virkelig hjælper ikke. JSON-metoderne var ~5x hurtigere uden parallelitet og
STRING_SPLITvar næsten 10 gange hurtigere. - Spolen hjalp faktisk CLR-tilgangen til at fungere bedre i dette tilfælde, men TF 8690 kan være nyttig at eksperimentere med i andre tilfælde, hvor du ser spoler og forsøger at forbedre ydeevnen. Jeg er sikker på, at der er situationer, hvor eliminering af spolen vil ende med at blive bedre generelt.
- Eliminering af spolen gjorde virkelig ondt på XML-tilgangen (men kun drastisk, da den blev tvunget til at være enkelttrådet).
- Der kan ske en masse sjove ting med estimater afhængigt af tilgangen, sammen med de sædvanlige statistikker, distribution og sporingsflag. Nå, det vidste jeg vel allerede, men der er helt sikkert et par gode, håndgribelige eksempler her.
Tak til de folk, der stillede spørgsmål eller tilskyndede mig til at inkludere mere information. Og som du måske har gættet ud fra titlen, adresserer jeg endnu et spørgsmål i en anden opfølgning, dette om TVP'er:
- STRING_SPLIT() i SQL Server 2016:Opfølgning #2