I mit sidste indlæg startede jeg en serie til at dække proaktive sundhedstjek, der er afgørende for din SQL Server. Vi startede med diskplads, og i dette indlæg vil vi diskutere vedligeholdelsesopgaver. Et af de grundlæggende ansvar for en DBA er at sikre, at følgende vedligeholdelsesopgaver kører regelmæssigt:
- Sikkerhedskopier
- Integritetstjek
- Indeksvedligeholdelse
- Statistikopdateringer
Mit bud er, at du allerede har job på plads til at klare disse opgaver. Og jeg vil også vædde på, at du har konfigureret notifikationer til at e-maile dig og dit team, hvis et job mislykkes. Hvis begge dele er sande, er du allerede proaktiv med hensyn til vedligeholdelse. Og hvis du ikke gør begge dele, er det noget, der skal rettes lige nu - som i, stop med at læse dette, download Ola Hallengrens scripts, planlæg dem, og sørg for at konfigurere notifikationer. (Et andet alternativ specifikt til indeksvedligeholdelse, som vi også anbefaler til kunder, er SQL Sentry Fragmentation Manager.)
Hvis du ikke ved, om dine job er indstillet til at sende dig e-mail, hvis de mislykkes, skal du bruge denne forespørgsel:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
At være proaktiv omkring vedligeholdelse går dog et skridt videre. Udover blot at sikre, at dine job kører, skal du vide, hvor lang tid de tager. Du kan bruge systemtabellerne i msdb til at overvåge dette:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Eller, hvis du bruger Olas scripts og logoplysninger, kan du forespørge i hans CommandLog-tabel:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Ovenstående script viser backupvarigheden for hver fuld backup til AdventureWorks2014-databasen. Du kan forvente, at varigheden af vedligeholdelsesopgaver langsomt vil stige over tid, efterhånden som databaser vokser sig større. Som sådan leder du efter store stigninger eller uventede fald i varigheden. For eksempel havde jeg en klient med en gennemsnitlig backup-varighed på mindre end 30 minutter. Pludselig begynder sikkerhedskopiering at tage mere end en time. Databasen havde ikke ændret sig væsentligt i størrelse, ingen indstillinger var ændret for forekomsten eller databasen, intet var ændret med hardware eller diskkonfiguration. Et par uger senere faldt backup-varigheden tilbage til mindre end en halv time. En måned efter gik de op igen. Vi korrelerede til sidst ændringen i backup-varighed til failovers mellem klyngeknudepunkter. På én node tog sikkerhedskopierne mindre end en halv time. På den anden side tog de over en time. En lille undersøgelse af konfigurationen af NIC'erne og SAN-strukturen, og vi var i stand til at lokalisere problemet.
Det er også vigtigt at forstå den gennemsnitlige udførelsestid for CHECKDB-operationer. Dette er noget, som Paul taler om i vores High Availability and Disaster recovery Immersion Event:du skal vide, hvor lang tid CHECKDB normalt tager at køre, så hvis du finder korruption, og du kører en kontrol på hele databasen, ved du, hvor lang tid den skal tage for CHECKDB at fuldføre. Når din chef spørger:"Hvor længe går der, før vi kender omfanget af problemet?" du vil være i stand til at give et kvantitativt svar på den minimale tid, du skal vente. Hvis CHECKDB tager længere tid end normalt, så ved du, at det har fundet noget (som ikke nødvendigvis er korruption; du skal altid lade kontrollen afslutte).
Nu, hvis du administrerer hundredvis af databaser, ønsker du ikke at køre ovenstående forespørgsel for hver database eller hvert job. I stedet vil du måske bare finde job, der falder uden for den gennemsnitlige varighed med en vis procentdel, som du kan få ved hjælp af denne forespørgsel:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Denne forespørgsel viser job, der tog 25 % længere tid end gennemsnittet. Forespørgslen vil kræve nogle justeringer for at give de specifikke oplysninger, du ønsker - nogle job med en kort varighed (f.eks. mindre end 5 minutter) vil dukke op, hvis de bare tager et par ekstra minutter - det er måske ikke et problem. Ikke desto mindre er denne forespørgsel en god start, og indse, at der er mange måder at finde afvigelser på – du kan også sammenligne hver udførelse med den forrige og lede efter job, der tog en vis procentdel længere tid end den forrige.
Det er klart, at jobvarighed er den mest logiske identifikator at bruge til potentielle problemer - uanset om det er et backupjob, et integritetstjek eller jobbet, der fjerner fragmentering og opdaterer statistik. Jeg har fundet ud af, at den største variation i varighed typisk ligger i opgaverne med at fjerne fragmentering og opdatere statistik. Afhængigt af dine tærskler for omorganisering versus genopbygning og volatiliteten af dine data, kan du gå dage med for det meste omorganiseringer, hvorefter du pludselig får et par indeksgenopbygninger i gang for store tabeller, hvor disse genopbygninger fuldstændig ændrer den gennemsnitlige varighed. Du vil måske ændre dine tærskler for nogle indekser eller justere fyldfaktoren, så genopbygninger sker oftere eller sjældnere – afhængigt af indekset og fragmenteringsniveauet. For at foretage disse justeringer skal du se på, hvor ofte hvert indeks bliver genopbygget eller reorganiseret, hvilket du kun kan gøre, hvis du bruger Olas scripts og logger på CommandLog-tabellen, eller hvis du har rullet din egen løsning og logger hver omorganisering eller ombygning. For at se på dette ved hjælp af CommandLog-tabellen kan du starte med at kontrollere, hvilke indekser der oftest ændres:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Ud fra dette output kan du begynde at se, hvilke tabeller (og derfor indekser) der har den største volatilitet, og derefter bestemme, om tærsklen for omorganisering versus genopbygning skal justeres, eller fyldfaktoren skal ændres.
Gør livet lettere
Nu er der en nemmere løsning end at skrive dine egne forespørgsler, så længe du bruger SQL Sentry Event Manager (EM). Værktøjet overvåger alle agentjob, der er konfigureret på en instans, og ved hjælp af kalendervisningen kan du hurtigt se, hvilke job der mislykkedes, blev annulleret eller kørte længere end normalt:
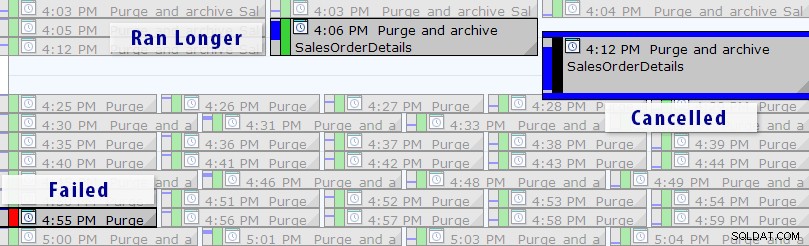 SQL Sentry Event Manager-kalendervisning (med etiketter tilføjet i Photoshop)
SQL Sentry Event Manager-kalendervisning (med etiketter tilføjet i Photoshop)
Du kan også bore i individuelle udførelser for at se, hvor meget længere tid det tog et job at køre, og der er også praktiske runtime-grafer, der giver dig mulighed for hurtigt at visualisere eventuelle mønstre i varigheds-anomalier eller fejltilstande. I dette tilfælde kan jeg se, at køretidsvarigheden for dette specifikke job omkring hvert 15. minut steg med næsten 400 %:
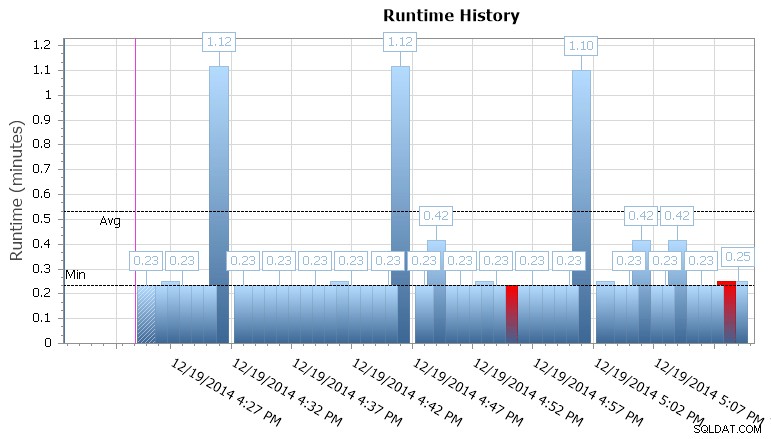 SQL Sentry Event Manager runtime graf
SQL Sentry Event Manager runtime graf
Dette giver mig et fingerpeg om, at jeg bør undersøge andre planlagte job, der kan forårsage nogle samtidighedsproblemer her. Jeg kunne zoome ud på kalenderen igen for at se, hvilke andre job der kører på samme tid, eller jeg behøver måske ikke engang at kigge efter, at dette er et rapporterings- eller backupjob, der kører mod denne database.
Oversigt
Jeg vil vædde på, at de fleste af jer allerede har de nødvendige vedligeholdelsesjob på plads, og at I også har notifikationer opsat for jobfejl. Hvis du ikke er bekendt med gennemsnitlige varigheder for dine job, så er det dit næste skridt i at være proaktiv. Bemærk:Du skal muligvis også tjekke for at se, hvor længe du beholder jobhistorikken. Når jeg leder efter afvigelser i jobbets varighed, foretrækker jeg at se på et par måneders data frem for et par uger. Du behøver ikke at huske disse køretider, men når du har bekræftet, at du har nok data til at have historikken til brug for forskning, så begynd at lede efter variationer regelmæssigt. I et ideelt scenarie kan den øgede køretid advare dig om et potentielt problem, så du kan løse det, før der opstår et problem i dit produktionsmiljø.