SQL Server 2014 CTP1 har været ude i et par uger nu, og du har sandsynligvis set en del presse om hukommelsesoptimerede tabeller og opdaterbare kolonnelagerindekser. Selvom disse bestemt er værd at være opmærksomme på, ville jeg i dette indlæg udforske den nye SELECT ... INTO parallelisme forbedring. Forbedringen er en af de ready-to-wear ændringer, der set ud fra dens udseende ikke vil kræve væsentlige kodeændringer for at begynde at drage fordel af den. Mine udforskninger blev udført ved hjælp af version Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
Parallel SELECT … INTO
SQL Server 2014 introducerer parallelaktiveret SELECT ... INTO til databaser og for at teste denne funktion brugte jeg AdventureWorksDW2012-databasen og en version af FactInternetSales-tabellen, der havde 61.847.552 rækker (jeg var ansvarlig for at tilføje disse rækker; de følger ikke med databasen som standard).
Fordi denne funktion, fra og med CTP1, kræver databasekompatibilitetsniveau 110, til testformål satte jeg databasen til kompatibilitetsniveau 100 og udførte følgende forespørgsel til min første test:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Forespørgselsudførelsesvarigheden var 3 minutter og 19 sekunder på min test-VM, og den faktiske forespørgselsudførelsesplan var som følger:

SQL Server brugte en seriel plan, som jeg forventede. Bemærk også, at min tabel havde et ikke-clustered columnstore-indeks på sig, som blev scannet (jeg oprettede dette ikke-clustered columnstore-indeks til brug med andre tests, men jeg vil også vise dig udførelsesplanen for clustered columnstore-indeksforespørgsel senere). Planen brugte ikke parallelitet, og Columnstore Index Scan brugte rækkeudførelsestilstand i stedet for batchudførelsestilstand.
Så derefter ændrede jeg databasekompatibilitetsniveauet (og bemærk, at der endnu ikke er et SQL Server 2014-kompatibilitetsniveau i CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Jeg droppede FactInternetSales_V2-tabellen og genudførte derefter min originale SELECT ... INTO operation. Denne gang var forespørgselsudførelsen 1 minut og 7 sekunder, og den faktiske plan for udførelse af forespørgslen var som følger:
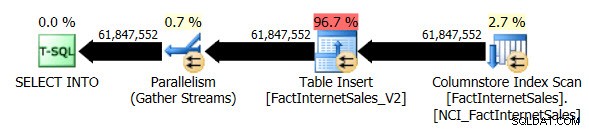
Vi har nu en parallel plan, og den eneste ændring, jeg skulle foretage, var til databasekompatibilitetsniveauet for AdventureWorksDW2012. Min test-VM har fire vCPU'er allokeret til sig, og forespørgselsudførelsesplanen fordelte rækker på tværs af fire tråde:

Den ikke-klyngede Columnstore Index Scan brugte, mens den brugte parallelisme, ikke batch-udførelsestilstand. I stedet brugte den rækkeudførelsestilstand.
Her er en tabel, der viser testresultaterne indtil videre:
| Scanningstype | Kompatibilitetsniveau | Parallel SELECT … INTO | Udførelsestilstand | Varighed |
|---|---|---|---|---|
| Ikke-klyngede Columnstore Index Scan | 100 | Nej | Række | 3:19 |
| Ikke-klyngede Columnstore Index Scan | 110 | Ja | Række | 1:07 |
Så som en næste test droppede jeg det ikke-klyngede kolonnelagerindeks og genudførte SELECT ... INTO forespørgsel ved hjælp af både databasekompatibilitetsniveau 100 og 110.
Kompatibilitetsniveau 100-testen tog 5 minutter og 44 sekunder at køre, og følgende plan blev genereret:
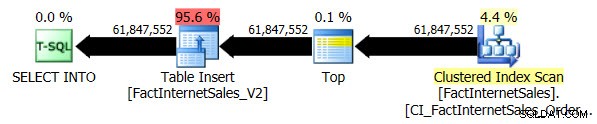
Den serielle Clustered Index Scan tog 2 minutter og 25 sekunder længere end den serielle ikke-clustered Columnstore Index Scan.
Ved at bruge kompatibilitetsniveau 110 tog forespørgslen 1 minut og 55 sekunder at køre, og følgende plan blev genereret:

I lighed med den parallelle ikke-klyngede Columnstore Index Scan-test fordelte den parallelle Clustered Index Scan rækker på tværs af fire tråde:
Følgende tabel opsummerer disse to førnævnte tests:
| Scanningstype | Kompatibilitetsniveau | Parallel SELECT … INTO | Udførelsestilstand | Varighed |
|---|---|---|---|---|
| Clustered Index Scan | 100 | Nej | Række (N/A) | 5:44 |
| Clustered Index Scan | 110 | Ja | Række (N/A) | 1:55 |
Så så undrede jeg mig over ydeevnen for et clustered columnstore-indeks (nyt i SQL Server 2014), så jeg droppede de eksisterende indekser og oprettede et clustered columnstore-indeks på FactInternetSales-tabellen. Jeg var også nødt til at droppe de otte forskellige fremmednøglebegrænsninger, der var defineret i tabellen, før jeg kunne oprette det klyngede kolonnelagerindeks.
Diskussionen bliver noget akademisk, da jeg sammenligner SELECT ... INTO ydeevne på databasekompatibilitetsniveauer, der ikke tilbød klyngede columnstore-indekser i første omgang – og det gjorde de tidligere tests for ikke-clustered columnstore-indekser på databasekompatibilitetsniveau 100 – og alligevel er det interessant at se og sammenligne de overordnede ydeevnekarakteristika.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
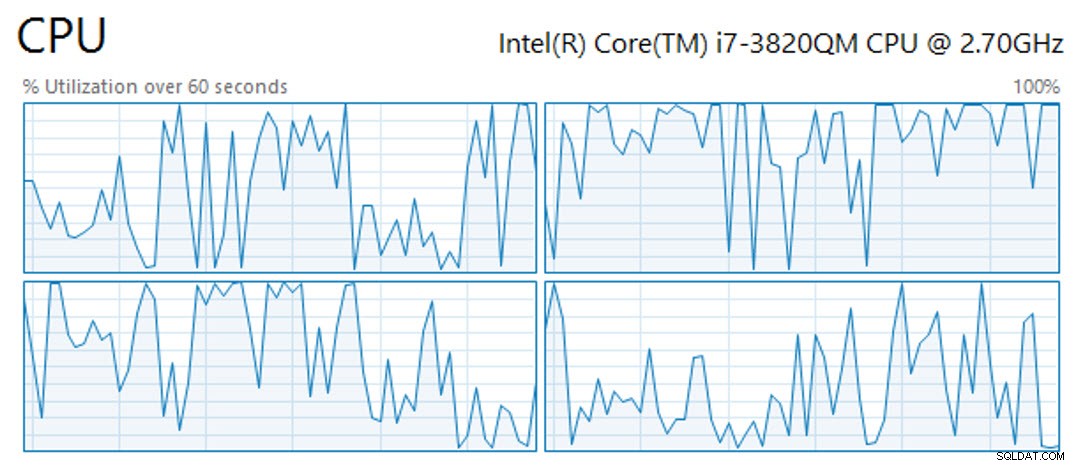
Som en sidebemærkning tog operationen med at oprette det klyngede kolonnelagerindeks på en tabel med 61.847.552 millioner rækker 11 minutter og 25 sekunder med fire tilgængelige vCPU'er (hvoraf operationen udnyttede dem alle), 4 GB RAM og virtuel gæstelagring på OCZ Vertex SSD'er. I løbet af den tid var CPU'erne ikke fastgjort hele tiden, men viste snarere toppe og dale (et udsnit af 60 sekunders CPU-aktivitet vist nedenfor):
Efter det klyngede kolonnelagerindeks blev oprettet, genudførte jeg de to SELECT ... INTO tests. Kompatibilitetsniveau 100-testen tog 3 minutter og 22 sekunder at køre, og planen var en seriel som forventet (jeg viser SQL Server Management Studio-versionen af planen siden den klyngede Columnstore Index Scan, fra SQL Server 2014 CTP1 , er endnu ikke fuldt ud genkendt af Plan Explorer):

Dernæst ændrede jeg databasekompatibilitetsniveauet til 110 og kørte testen igen, som denne gang tog 1 minut og 11 sekunder og havde følgende faktiske eksekveringsplan:

Planen fordelte rækker på tværs af fire tråde, og ligesom det ikke-klyngede columnstore-indeks var udførelsestilstanden for den klyngede Columnstore Index Scan række og ikke batch.
Følgende tabel opsummerer alle testene i dette indlæg (i rækkefølge efter varighed, lav til høj):
| Scanningstype | Kompatibilitetsniveau | Parallel SELECT … INTO | Udførelsestilstand | Varighed |
|---|---|---|---|---|
| Ikke-klyngede Columnstore Index Scan | 110 | Ja | Række | 1:07 |
| Clustered Columnstore Index Scan | 110 | Ja | Række | 1:11 |
| Clustered Index Scan | 110 | Ja | Række (N/A) | 1:55 |
| Ikke-klyngede Columnstore Index Scan | 100 | Nej | Række | 3:19 |
| Clustered Columnstore Index Scan | 100 | Nej | Række | 3:22 |
| Clustered Index Scan | 100 | Nej | Række (N/A) | 5:44 |
Et par observationer:
- Jeg er ikke sikker på, om forskellen mellem en parallel
SELECT ... INTOoperation mod et ikke-klynget kolonnelagerindeks versus klynget kolonnelagerindeks er statistisk signifikant. Jeg skulle lave flere tests, men jeg tror, jeg ville vente med at udføre dem indtil RTM. - Jeg kan roligt sige, at den parallelle
SELECT ... INTOklarede sig markant bedre end de serielle ækvivalenter på tværs af et klynget indeks, ikke-klynget kolonnelager og klynget kolonnelagerindekstest.
Det er værd at nævne, at disse resultater er for en CTP-version af produktet, og mine tests skal ses som noget, der kunne ændre adfærd af RTM - så jeg var mindre interesseret i de selvstændige varigheder i forhold til hvordan disse varigheder sammenlignet mellem seriel og parallel betingelser.
Nogle ydeevnefunktioner kræver betydelig refaktorering – men for SELECT ... INTO forbedring, alt hvad jeg skulle gøre var at øge databasekompatibilitetsniveauet for at begynde at se fordelene, hvilket bestemt er noget jeg sætter pris på.