SQL Server 2014 CTP1 introducerer udvidelser til onlinedriftsmuligheder, der vil være gode nyheder for virksomheder, der hoster meget store databaser, der kræver lidt eller ingen nedetid.
For at indstille konteksten skal du forestille dig, at du bruger SQL Server 2012 Enterprise Edition til online indeksstyring og indekspartitioneringsfunktioner, og du forsøger følgende indeksgenopbygning på en partitioneret tabel:
ALTER INDEX [PK_FactInternetSales_SalesOrderNumber_SalesOrderLineNumber] ON [dbo].[FactInternetSales] REBUILD PARTITION = ALL WITH (ONLINE= ON);
Ved at teste dette i SQL Server 2012 er vi i stand til at genopbygge alle partitioner online uden fejl. Men hvad nu hvis vi ønsker at angive en specifik partition i stedet for alle partitioner?
ALTER INDEX [PK_FactInternetSales_SalesOrderNumber_SalesOrderLineNumber] ON [dbo].[FactInternetSales] REBUILD PARTITION = 1 WITH (ONLINE= ON);
Forsøger du dette i SQL Server 2012 eller tidligere, vil du se følgende fejlmeddelelse:
Meddelelse 155, niveau 15, tilstand 1, linje 4'ONLINE' er ikke en genkendt mulighed for ALTER INDEX REBUILD PARTITION.
Men fra og med SQL Server 2014 (fra CTP1) understøttes online enkeltpartitionsindeksoperationer nu. Og dette er bestemt en stor sag for scenarier for meget store bordvedligeholdelse, hvor du foretrækker eller faktisk skal dele din samlede vedligeholdelse i mindre stykker over en periode. Du vil måske også udføre vedligeholdelse på partitionsniveau for kun de partitioner, der faktisk kræver det - for eksempel de partitioner, der faktisk overstiger et specifikt fragmenteringsniveau.
For at teste denne SQL Server 2014 CTP1-funktionalitet brugte jeg AdventureWorksDW2012 med en version af FactInternetSales, der indeholder 61.847.552 rækker og opdelt efter ShipDate-kolonnen.
Genopbygning af alle partitioner online til tabellen ved hjælp af PARTITION = ALL i mit testmiljø tog det 3 minutter og 23 sekunder. Med hensyn til den samlede varighed var mine tests for indekser, der ikke var så fragmenterede, så varigheden på 3 minutter og 23 sekunder repræsenterer en gennemsnitlig varighed over nogle få tests. Husk også, at jeg ikke havde konkurrerende arbejdsbelastninger kørende på det tidspunkt, så online-genopbygningen sker uden at skulle konkurrere med andre væsentlige arbejdsbelastninger mod det pågældende indeks.
Forespørgselsudførelsesplanens form for onlineindeksgenopbygningen ved hjælp af PARTITION = ALL var som følger:
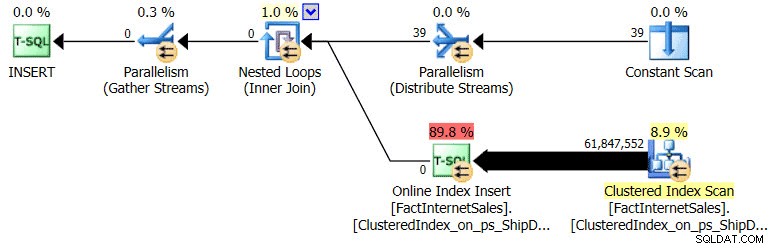
Udførelsesplan for online genopbygning af alle partitioner
Bemærk, at operationerne er parallelaktiverede med undtagelse af Constant Scan-operatøren. I forespørgselsudførelsesplanen kan du se 39 rækker i den ydre reference Constant Scan, der sendes til Distribute Streams-operatøren og derefter køre Nested Loop.
Betydningen af de 39 rækker? Følgende forespørgsel validerer det maksimale antal partitioner fra sys.dm_db_partition_stats . For mit testmiljø var resultatet 39 for det maksimale partitionsantal, hvilket matchede det, jeg så for de faktiske rækker med konstant scanning:
SELECT MAX([partition_number]) AS [max_partition_number]
FROM [sys].[dm_db_partition_stats]
WHERE [object_id] = OBJECT_ID('FactInternetSales');
Nu vil du også bemærke operatøren Online Index Insert i den tidligere plan. Fjernelse af ONLINE = ON mulighed fra min ALTER INDEX REBUILD (gør det til en offline operation), og beholder PARTITION = ALL mulighed, den eneste ændring var at have en "Index Insert"-operator i stedet for en "Online Index Insert" i forespørgselsudførelsesplanen - og også en reduktion i varighed, hvor min test viste en eksekveringsvarighed på 1 minut og 9 sekunder sammenlignet med online 3 minutter og 23 sekunder.
Jeg testede derefter en online genopbygning af en partition med 5.678.080 rækker i i stedet (husk, at det samlede antal tabelrækker er 61.847.552 rækker). For denne test tog den samlede varighed nøjagtigt 1 minut og havde følgende forespørgselsudførelsesplan:

Udførelsesplan for online genopbygning af en enkelt partition
Den første observation er, at dette er en seriel plan. Bemærk også, at jeg sagde, at jeg valgte en partition ud af de originale 39, selvom den pågældende partition repræsenterede ~ 9% af rækkerne i tabellen generelt. Bemærk også, at Constant Scan viser 1 række i stedet for 39, som jeg ville forvente.
Hvad med varigheden af en enkelt partition, offline genopbygning? I mit testmiljø tog dette 11 sekunder sammenlignet med online genopbygningen 1 minut. Forespørgselsudførelsesplanens form for offline-genopbygningen af en enkelt partition var som følger:
Udførelsesplan for offline genopbygning af en enkelt partition
Bemærk, at der ikke er nogen konstant scanning eller tilhørende Nested Loops-proces, og bemærk også, at denne plan nu har parallelle operatører i sig i forhold til den tidligere serielle plan, selvom de begge laver en Clustered Index Scan for 5.678.080 rækker. Også at udføre en søgeordssøgning på "partition" i XML-planteksten for den enkelte partition offline parallel indeksoperation resulterede ikke i nogen match - sammenlignet med den serielle plan, online enkelt partitions indeksoperation, som havde Partitioned ="true" for Clustered Index Scan og Online Index Indsæt fysiske operatorer.
Tilbage til hovedudforskningen...
Kan jeg vælge nogle få, men ikke alle partitioner i en enkelt udførelse? Desværre ikke.
ALTER INDEX og ALTER TABLE kommandoer har PARTITION = ALL argument og derefter PARTITION = <partition number> argument, men ikke muligheden for at angive flere partitioner for en enkelt genopbygningsoperation. Jeg klager dog ikke for højt over dette, da jeg er glad for at have muligheden for at genopbygge en enkelt partition online, og det er ikke voldsomt kompliceret at udføre operationen én gang for hver genopbygning, men den kumulative effekt på varigheden var noget Jeg ville gerne udforske yderligere.
Hvor lang tid ville det tage at genopbygge alle 39 partitioner separat og online versus PARTITION = ALL varighed på 3 minutter og 23 sekunder?
Vi ved, at en fordel ved online-genopbygninger er muligheden for stadig at få adgang til den tilknyttede tabel eller indeks under indeksoperationen. Men til gengæld for den online operation mister vi ydeevnefordelen ved genopbygningen sammenlignet med en offline genopbygning. Og det, jeg ville vide, var, hvordan en online-genopbygning af en-til-en partition ville fungere i forhold til PARTITION = ALL alternativ.
Ved at udføre 39 separate genopbygningsoperationer (en genopbygning for hver unik partition), var den samlede eksekveringsvarighed 9 minutter og 54 sekunder sammenlignet med PARTITION = ALL som tog 3 minutter og 23 sekunder, så det er klart, at den stykkevise tilgang kumulativt ikke er så hurtig som en online genopbygning af alle partitioner i én erklæring. Selvom jeg var i stand til at lave en partition ad gangen, er den overordnede fordel evnen til at adskille vores vedligeholdelsesaktiviteter over tid og bevare adgangen til objekterne, mens de bliver genopbygget, men hvis du leder efter en kortere genopbygning vindue, offline-indstillinger er stadig de hurtigste, efterfulgt af online for PARTITION = ALL og så på sidstepladsen ved at lave en partition ad gangen.
Følgende tabel opsummerer varighedssammenligningerne – og igen var disse test baseret på SQL Server 2014 CTP1 og en meget specifik tabelstørrelse og VM-gæstekonfiguration, så vær mere opmærksom på de relative varigheder på tværs af test frem for selve varighederne:
| Testbeskrivelse | Varighed |
|---|---|
| Offline genopbygning af alle partitioner | 1:09 |
| Online genopbygning af alle partitioner | 3:23 |
| Online genopbygning af én partition | 1:00 |
| Offline genopbygning af én partition | 0:11 |
| Online genopbygning af alle partitioner, én partition ad gangen | 9:54 |
Nu er der også andre aspekter at udforske om dette emne. Bare fordi en operation er online, betyder det ikke, at der ikke er et par øjeblikke (eller længere), hvor der stadig holdes låse på det målrettede objekt. Indeksoperationer har stadig låseadfærd for onlineoperationer – og SQL Server 2014 har også givet muligheder for dette, som jeg vil udforske i et separat indlæg.