"Gentag ikke dig selv"-princippet foreslår, at du skal reducere gentagelser. I denne uge stødte jeg på en sag, hvor DRY skulle smides ud af vinduet. Der er også andre tilfælde (for eksempel skalarfunktioner), men denne var interessant, der involverede Bitwise-logik.
Lad os forestille os følgende tabel:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); "WheelFlag"-bittene repræsenterer følgende muligheder:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Så mulige kombinationer er:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Lad os lægge argumenter til side, i det mindste for nu, om hvorvidt dette skal pakkes ind i en enkelt TINYINT i første omgang, eller gemmes som separate kolonner, eller bruge en EAV-model... at rette designet er et separat problem. Det her handler om at arbejde med det, du har.
For at gøre eksemplerne nyttige, lad os fylde denne tabel op med en masse tilfældige data. (Og for nemheds skyld antager vi, at denne tabel kun indeholder ordrer, der endnu ikke er afsendt.) Dette vil indsætte 50.000 rækker med nogenlunde ligelig fordeling mellem de seks valgmuligheder:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Hvis vi ser på opdelingen, kan vi se denne fordeling. Bemærk, at dine resultater kan afvige en smule fra mine afhængigt af objekterne i dit system:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Resultater:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Lad os nu sige, at det er tirsdag, og vi har lige fået en forsendelse af 18" hjul, som tidligere var udsolgt. Det betyder, at vi er i stand til at opfylde alle de ordrer, der kræver 18" fælge – både dem, der har opgraderet dæk (6), og dem der ikke gjorde (2). Så vi *kunne* skrive en forespørgsel som følgende:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); I det virkelige liv kan man selvfølgelig ikke rigtig gøre det; hvad hvis flere muligheder tilføjes senere, såsom hjullåse, livstidshjulgaranti eller flere dækmuligheder? Du ønsker ikke at skulle skrive en række IN()-værdier for hver mulig kombination. I stedet kan vi skrive en BITWISE AND operation for at finde alle de rækker, hvor den 2. bit er sat, såsom:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Dette giver mig de samme resultater som IN()-forespørgslen, men hvis jeg sammenligner dem ved hjælp af SQL Sentry Plan Explorer, er ydeevnen helt anderledes:

Det er nemt at se hvorfor. Den første bruger en indekssøgning til at isolere de rækker, der opfylder forespørgslen, med et filter på WheelFlag-kolonnen:
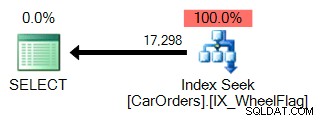

Den anden bruger en scanning, kombineret med en implicit konverter, og frygtelig unøjagtig statistik. Alt sammen på grund af BITWISE OG operatøren:
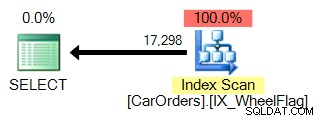


Så hvad betyder det? Kernen i det fortæller os, at BITWISE AND-operationen ikke er sargerbar .
Men alt håb er ikke ude.
Hvis vi ignorerer DRY princippet et øjeblik, kan vi skrive en lidt mere effektiv forespørgsel ved at være lidt overflødig for at udnytte indekset på WheelFlag kolonnen. Hvis vi antager, at vi er ude efter en WheelFlag-indstilling over 0 (ingen opgradering overhovedet), kan vi omskrive forespørgslen på denne måde og fortælle SQL Server, at WheelFlag-værdien skal være mindst den samme værdi som flag (hvilket eliminerer 0 og 1 ), og tilføjer derefter den supplerende information, at den også skal indeholde dette flag (hvilket eliminerer 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
>=-delen af denne klausul er naturligvis dækket af BITWISE-delen, så det er her, vi overtræder DRY. Men fordi denne klausul, vi har tilføjet, er sargerbar, giver en relegering af BITWISE AND-operationen til en sekundær søgebetingelse stadig det samme resultat, og den overordnede forespørgsel giver bedre ydeevne. Vi ser en lignende indekssøgning til den hårdkodede version af forespørgslen ovenfor, og selvom estimaterne er endnu længere væk (noget, der kan behandles som et separat problem), er læsningerne stadig lavere end med BITWISE AND-operationen alene:

Vi kan også se, at der bruges et filter mod indekset, som vi ikke så, når vi brugte BITWISE AND-operationen alene:

Konklusion
Vær ikke bange for at gentage dig selv. Der er tidspunkter, hvor disse oplysninger kan hjælpe optimizeren; selvom det måske ikke er helt intuitivt at *tilføje* kriterier for at forbedre ydeevnen, er det vigtigt at forstå, hvornår yderligere klausuler hjælper med at skære dataene ned til slutresultatet i stedet for at gøre det "let" for optimeringsværktøjet at finde de nøjagtige rækker på egen hånd.