Jeg ser mange råd derude, der siger noget i retning af, "Skift din markør til en sæt-baseret operation; det vil gøre det hurtigere." Selvom det ofte kan være tilfældet, er det ikke altid sandt. Et tilfælde jeg ser, hvor en markør gentagne gange udkonkurrerer den typiske sætbaserede tilgang, er beregningen af løbende totaler. Dette skyldes, at den sæt-baserede tilgang normalt skal se på en del af de underliggende data mere end én gang, hvilket kan være en eksponentielt dårlig ting, efterhånden som dataene bliver større; hvorimod en markør – hvor smertefuld det end kan lyde – kan gå gennem hver række/værdi præcis én gang.
Dette er vores grundlæggende muligheder i de fleste almindelige versioner af SQL Server. I SQL Server 2012 er der dog foretaget adskillige forbedringer af vinduesfunktioner og OVER-klausulen, hovedsagelig udspring fra adskillige gode forslag indsendt af andre MVP Itzik Ben-Gan (her er et af hans forslag). Faktisk har Itzik en ny MS-Press-bog, der dækker alle disse forbedringer meget mere detaljeret, med titlen "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions."
Så naturligvis var jeg nysgerrig; ville den nye vinduesfunktionalitet gøre markør- og selvsammenføjningsteknikkerne forældede? Ville de være nemmere at kode? Ville de være hurtigere i alle tilfælde? Hvilke andre tilgange kan være gyldige?
Opsætningen
For at lave nogle test, lad os opsætte en database:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Og fyld derefter en tabel med 10.000 rækker, som vi kan bruge til at udføre nogle løbende totaler mod. Intet for kompliceret, bare en oversigtstabel med en række for hver dato og et tal, der repræsenterer, hvor mange fartbøder der blev udstedt. Jeg har ikke haft en fartbøde i et par år, så jeg ved ikke, hvorfor dette var mit ubevidste valg til en forenklet datamodel, men der er den.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Forkortede resultater:
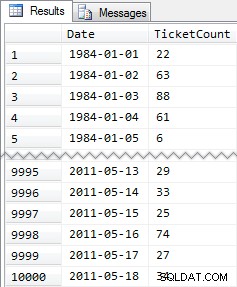
Så igen, 10.000 rækker af ret simple data – små INT-værdier og en række datoer fra 1984 til maj 2011.
Tilgange
Nu er min opgave relativt enkel og typisk for mange applikationer:returner et resultatsæt, der har alle 10.000 datoer, sammen med den samlede sum af alle fartbøder til og med den dato. De fleste mennesker ville først prøve noget som dette (vi kalder dette "indre join). " metode):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
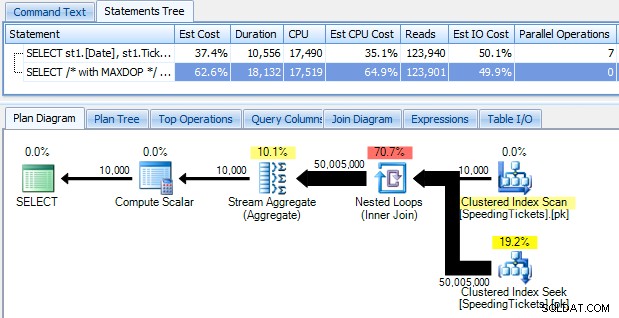
…og bliv chokeret over at opdage, at det tager næsten 10 sekunder at køre. Lad os hurtigt undersøge hvorfor ved at se den grafiske udførelsesplan ved hjælp af SQL Sentry Plan Explorer:

De store fede pile skulle give en umiddelbar indikation af, hvad der foregår:den indlejrede løkke læser en række for den første sammenlægning, to rækker for den anden, tre rækker for den tredje, og videre og videre gennem hele sættet på 10.000 rækker. Det betyder, at vi bør se nogenlunde ((10000 * (10000 + 1)) / 2) rækker behandlet, når hele sættet er gennemkørt, og det ser ud til at stemme overens med antallet af rækker vist i planen.
Bemærk, at kørsel af forespørgslen uden parallelitet (ved at bruge OPTION (MAXDOP 1) forespørgselstip) gør planformen lidt enklere, men det hjælper slet ikke i hverken udførelsestid eller I/O; som vist i planen fordobles varigheden faktisk næsten, og læsningerne falder kun med en meget lille procentdel. Sammenligning med den tidligere plan:
Der er masser af andre tilgange, som folk har prøvet for at få effektive løbende totaler. Et eksempel er "underforespørgselsmetoden " som bare bruger en korreleret underforespørgsel på nogenlunde samme måde som den indre joinmetode beskrevet ovenfor:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Sammenligning af disse to planer:
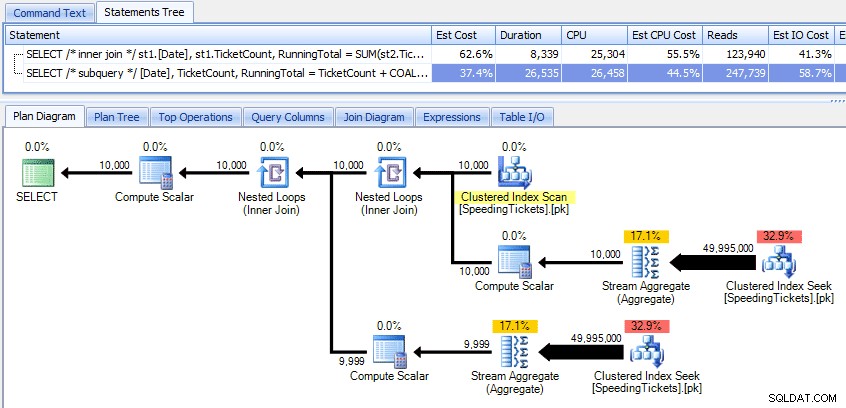
Så selvom underforespørgselsmetoden ser ud til at have en mere effektiv overordnet plan, er den værre, hvor den betyder noget:varighed og I/O. Vi kan se, hvad der bidrager til dette, ved at grave lidt dybere i planerne. Ved at flytte til fanen Top Operations kan vi se, at i den indre join-metode udføres den klyngede indekssøgning 10.000 gange, og alle andre operationer udføres kun få gange. Flere operationer udføres dog 9.999 eller 10.000 gange i underforespørgselsmetoden:
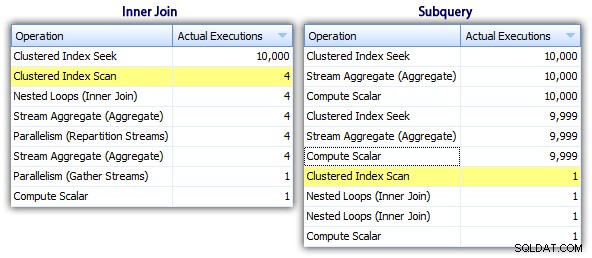
Så underforespørgselstilgangen ser ud til at være værre, ikke bedre. Den næste metode, vi prøver, kalder jeg "quirky update " metode. Det er ikke ligefrem garanteret at virke, og jeg vil aldrig anbefale det til produktionskode, men jeg inkluderer det for fuldstændighedens skyld. Grundlæggende udnytter den skæve opdatering, at du under en opdatering kan omdirigere opgave og matematik, så at variablen stiger bag kulisserne, efterhånden som hver række opdateres.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Jeg gentager, at jeg ikke tror, at denne tilgang er sikker for produktion, uanset hvilket vidnesbyrd, du vil høre fra folk, der indikerer, at det "aldrig fejler." Medmindre adfærd er dokumenteret og garanteret, forsøger jeg at holde mig væk fra antagelser baseret på observeret adfærd. Du ved aldrig, hvornår en ændring i optimeringsprogrammets beslutningsvej (baseret på en statistikændring, dataændring, servicepakke, sporingsflag, forespørgselstip, hvad har du) vil drastisk ændre planen og potentielt føre til en anden rækkefølge. Hvis du virkelig kan lide denne uintuitive tilgang, kan du få dig selv til at føle dig lidt bedre ved at bruge forespørgselsindstillingen FORCE ORDER (og dette vil forsøge at bruge en bestilt scanning af PK, da det er det eneste kvalificerede indeks på tabelvariablen):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
For lidt mere selvtillid til en lidt højere I/O-pris kan du bringe det originale bord i spil igen og sikre, at PK'en på basisbordet bruges:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Personligt tror jeg ikke, det er så meget mere garanteret, da SET-delen af operationen potentielt kan påvirke optimizeren uafhængigt af resten af forespørgslen. Igen, jeg anbefaler ikke denne tilgang, jeg inkluderer bare sammenligningen for fuldstændighedens skyld. Her er planen fra denne forespørgsel:
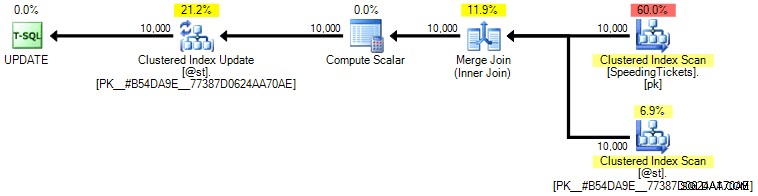
Baseret på antallet af henrettelser, vi ser på fanen Top Operations (jeg skal spare dig for skærmbilledet; det er 1 for hver operation), er det klart, at selvom vi udfører en join for at få det bedre med at bestille, er det skæve opdatering gør det muligt at beregne de løbende totaler i en enkelt passage af dataene. Sammenligner den med de tidligere forespørgsler, er den meget mere effektiv, selvom den først dumper data ind i en tabelvariabel og er adskilt i flere operationer:

Dette bringer os til en "rekursiv CTE " metode. Denne metode bruger datoværdien og er afhængig af den antagelse, at der ikke er huller. Da vi udfyldte disse data ovenfor, ved vi, at det er en fuldstændig sammenhængende serie, men i mange scenarier kan du ikke gøre det antagelse. Så selvom jeg har inkluderet det for fuldstændighedens skyld, vil denne tilgang ikke altid være gyldig. Under alle omstændigheder bruger denne en rekursiv CTE med den første (kendte) dato i tabellen som anker, og den rekursive portion bestemt ved at tilføje én dag (tilføje MAXRECURSION-indstillingen, da vi ved præcis, hvor mange rækker vi har):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Denne forespørgsel fungerer omtrent lige så effektivt som den finurlige opdateringsmetode. Vi kan sammenligne det med underforespørgsel og indre sammenføjningsmetoder:

Ligesom den finurlige opdateringsmetode vil jeg ikke anbefale denne CTE-tilgang i produktionen, medmindre du absolut kan garantere, at din nøglekolonne ikke har nogen huller. Hvis du måske har huller i dine data, kan du konstruere noget lignende ved at bruge ROW_NUMBER(), men det bliver ikke mere effektivt end selvsammenføjningsmetoden ovenfor.
Og så har vi "markøren " tilgang:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …hvilket er meget mere kode, men i modsætning til hvad den almindelige mening antyder, vender tilbage på 1 sekund. Vi kan se hvorfor fra nogle af plandetaljerne ovenfor:de fleste af de andre tilgange ender med at læse de samme data igen og igen, hvorimod markørtilgangen læser hver række én gang og holder den løbende total i en variabel i stedet for at beregne summen over og igen. Vi kan se dette ved at se på de udsagn, der er fanget ved at generere en faktisk plan i Plan Explorer:
Vi kan se, at der er blevet indsamlet over 20.000 udsagn, men hvis vi sorterer efter estimerede eller faktiske rækker faldende, finder vi ud af, at der kun er to operationer, der håndterer mere end én række. Hvilket er langt fra nogle få af ovenstående metoder, der forårsager eksponentielle læsninger på grund af at læse de samme foregående rækker igen og igen for hver ny række.
Lad os nu tage et kig på de nye vinduesforbedringer i SQL Server 2012. Især kan vi nu beregne SUM OVER() og angive et sæt rækker i forhold til den aktuelle række. Så for eksempel:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Disse to forespørgsler giver tilfældigvis det samme svar med korrekte løbende totaler. Men fungerer de nøjagtigt det samme? Planerne tyder på, at de ikke gør det. Versionen med ROWS har en ekstra operatør, et 10.000-rækkers sekvensprojekt:
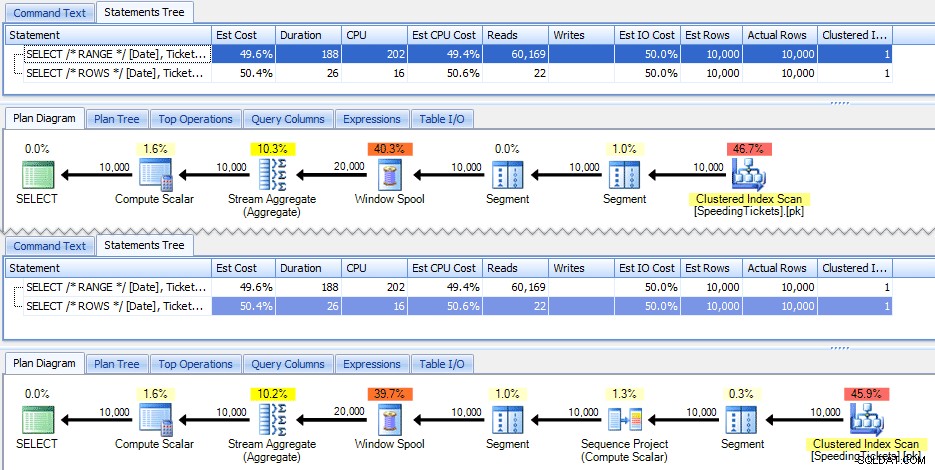
Og det handler om omfanget af forskellen i den grafiske plan. Men hvis du ser lidt nærmere på faktiske runtime-metrics, ser du mindre forskelle i varighed og CPU og en enorm forskel i læsninger. Hvorfor er det? Nå, det er fordi RANGE bruger en spool på disken, mens ROWS bruger en spool i hukommelsen. Med små sæt er forskellen sandsynligvis ubetydelig, men prisen på spolen på disken kan helt sikkert blive mere tydelig, efterhånden som sættene bliver større. Jeg ønsker ikke at ødelægge slutningen, men du har måske mistanke om, at en af disse løsninger vil fungere bedre end den anden i en mere grundig test.
Derudover giver følgende version af forespørgslen de samme resultater, men fungerer som den langsommere RANGE-version ovenfor:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Så mens du leger med de nye vinduesfunktioner, vil du gerne have små ting som dette i tankerne:den forkortede version af en forespørgsel, eller den du tilfældigvis har skrevet først, er ikke nødvendigvis den du ønsker at skubbe til produktion.
De faktiske tests
For at udføre retfærdige tests oprettede jeg en lagret procedure for hver tilgang og målte resultaterne ved at fange sætninger på en server, hvor jeg allerede overvågede med SQL Sentry (hvis du ikke bruger vores værktøj, kan du indsamle SQL:BatchCompleted-hændelser på lignende måde ved hjælp af SQL Server Profiler).
Med "fair tests" mener jeg, at f.eks. den skæve opdateringsmetode kræver en egentlig opdatering til statiske data, hvilket betyder ændring af det underliggende skema eller brug af en midlertidig tabel/tabelvariabel. Så jeg strukturerede de lagrede procedurer for at skabe hver deres egen tabelvariabel og enten gemme resultaterne der, eller gemme rådataene der og derefter opdatere resultatet. Det andet problem, jeg ønskede at eliminere, var at returnere dataene til klienten - så procedurerne har hver en fejlretningsparameter, der angiver, om der ikke skal returneres nogen resultater (standard), top/bund 5 eller alle. I ydeevnetestene satte jeg den til at returnere ingen resultater, men selvfølgelig validerede hver for at sikre, at de returnerede de rigtige resultater.
De lagrede procedurer er alle modelleret på denne måde (jeg har vedhæftet et script, der opretter databasen og de lagrede procedurer, så jeg inkluderer bare en skabelon her for kortheds skyld):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Og jeg kaldte dem i en batch som følger:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Jeg indså hurtigt, at nogle af disse opkald ikke blev vist i Top SQL, fordi standardtærsklen er 5 sekunder. Jeg ændrede det til 100 millisekunder (noget du aldrig vil gøre på et produktionssystem!) som følger:
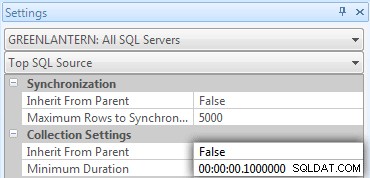
Jeg vil gentage:denne adfærd er ikke tolereret for produktionssystemer!
Jeg fandt stadig ud af, at en af kommandoerne ovenfor ikke blev fanget af den øverste SQL-tærskel; det var Windowed_Rows-versionen. Så jeg tilføjede kun følgende til den batch:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Og nu fik jeg alle 7 rækker returneret i Top SQL. Her er de sorteret efter CPU-brug faldende:
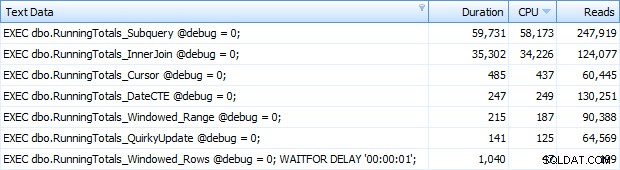
Du kan se det ekstra sekund, jeg tilføjede til Windowed_Rows-batchen; den blev ikke fanget af den øverste SQL-tærskel, fordi den blev fuldført på kun 40 millisekunder! Dette er klart vores bedste performer, og hvis vi har SQL Server 2012 tilgængelig, bør det være den metode, vi bruger. Markøren er heller ikke halvdårlig i betragtning af enten ydeevnen eller andre problemer med de resterende løsninger. At plotte varigheden på en graf er ret meningsløst – to højdepunkter og fem lavpunkter, der ikke kan skelnes. Men hvis I/O er din flaskehals, vil du måske finde visualiseringen af læsninger interessant:
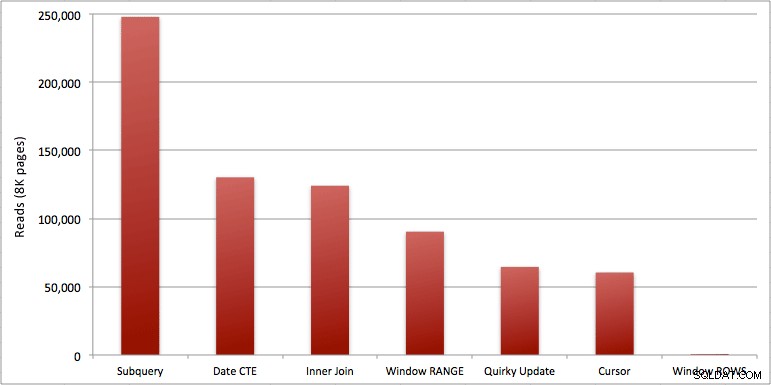
Konklusion
Ud fra disse resultater kan vi drage et par konklusioner:
- Windowed-aggregater i SQL Server 2012 gør problemer med ydeevnen med kørende totalberegninger (og mange andre problemer med næste række(r)/forrige række(r)) alarmerende mere effektive. Da jeg så det lave antal læsninger, troede jeg med sikkerhed, at der var en form for fejl, at jeg må have glemt at udføre noget arbejde. Men nej, du får det samme antal aflæsninger, hvis din lagrede procedure blot udfører en almindelig SELECT fra SpeedingTickets-tabellen. (Test dette gerne selv med STATISTICS IO.)
- De problemer, jeg påpegede tidligere om RANGE vs. ROWS, giver lidt forskellige kørselstider (varighedsforskel på ca. 6x – husk at ignorere den anden, jeg tilføjede med WAITFOR), men læseforskelle er astronomiske på grund af spolen på disken. Hvis dit windowed aggregat kan løses ved hjælp af ROWS, undgå RANGE, men du bør teste, at begge giver det samme resultat (eller i det mindste at ROWS giver det rigtige svar). Du skal også bemærke, at hvis du bruger en lignende forespørgsel, og du ikke angiver RANGE eller ROWS, vil planen fungere, som om du havde angivet RANGE).
- Metoderne for underforespørgsel og indre sammenkædning er relativt afgrundsdybende. 35 sekunder til et minut til at generere disse løbende totaler? Og dette var på et enkelt, tyndt bord uden at returnere resultater til kunden. Disse sammenligninger kan bruges til at vise folk, hvorfor en rent sæt-baseret løsning ikke altid er det bedste svar.
- Af de hurtigere tilgange, forudsat at du endnu ikke er klar til SQL Server 2012, og forudsat at du kasserer både den quirky opdateringsmetode (ikke-understøttet) og CTE-datometoden (kan ikke garantere en sammenhængende sekvens), udfører kun markøren acceptabelt. Den har den højeste varighed af de "hurtigere" løsninger, men den mindste mængde af læsninger.
Jeg håber, at disse test hjælper med at give en bedre forståelse for de vinduesforbedringer, som Microsoft har tilføjet til SQL Server 2012. Vær sikker på at takke Itzik, hvis du ser ham online eller personligt, da han var drivkraften bag disse ændringer. Derudover håber jeg, at dette hjælper med at åbne nogle sind derude, at en markør måske ikke altid er den onde og frygtede løsning, den ofte er afbildet som.
(Som et tillæg testede jeg CLR-funktionen tilbudt af Pavel Pawlowski, og ydeevneegenskaberne var næsten identiske med SQL Server 2012-løsningen ved brug af ROWS. Læsningerne var identiske, CPU var 78 vs. 47, og den samlede varighed var 73 i stedet for 40. Så hvis du ikke vil flytte til SQL Server 2012 i den nærmeste fremtid, kan du måske tilføje Pavels løsning til dine tests.)
Vedhæftede filer:RunningTotals_Demo.sql.zip (2kb)