For at besvare dit spørgsmål, hvorfor SQL Server gør dette, så er svaret, at forespørgslen ikke er kompileret i en logisk rækkefølge, hver erklæring er kompileret efter sin egen værdi, så når forespørgselsplanen for din select-sætning genereres, vil optimeringsværktøjet ved ikke, at @val1 og @Val2 bliver henholdsvis 'val1' og 'val2'.
Når SQL Server ikke kender værdien, skal den lave et bedste bud på, hvor mange gange den variabel vil blive vist i tabellen, hvilket nogle gange kan føre til suboptimale planer. Min hovedpointe er, at den samme forespørgsel med forskellige værdier kan generere forskellige planer. Forestil dig dette simple eksempel:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Alt jeg har gjort her er at oprette en simpel tabel og tilføje 1000 rækker med værdierne 1-10 for kolonnen val 1 vises dog 991 gange, og de andre 9 vises kun én gang. Udgangspunktet er denne forespørgsel:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Ville være mere effektivt bare at scanne hele tabellen end at bruge indekset til en søgning og derefter foretage 991 bogmærkeopslag for at få værdien for Filler , dog med kun 1 række følgende forespørgsel:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
vil være mere effektivt at lave en indekssøgning og et enkelt bogmærkeopslag for at få værdien for Filler (og at køre disse to forespørgsler vil ratificere dette)
Jeg er ret sikker på, at afskæringen for et søge- og bogmærkeopslag faktisk varierer afhængigt af situationen, men det er ret lavt. Ved at bruge eksempeltabellen, med lidt forsøg og fejl, fandt jeg ud af, at jeg havde brug for Val kolonne for at have 38 rækker med værdien 2, før optimeringsværktøjet gik til en fuld tabelscanning over en indekssøgning og bogmærkeopslag:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Så for dette eksempel er grænsen 3,7 % af matchende rækker.
Da forespørgslen ikke ved, hvor mange rækker der matcher, når du bruger en variabel, skal den gætte, og den enkleste måde er ved at finde ud af det samlede antal rækker og dividere dette med det samlede antal forskellige værdier i kolonnen, så i dette eksempel det estimerede antal rækker for WHERE val = @Val er 1000 / 10 =100, Den faktiske algoritme er mere kompleks end dette, men for eksempel vil dette gøre det. Så når vi ser på udførelsesplanen for:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
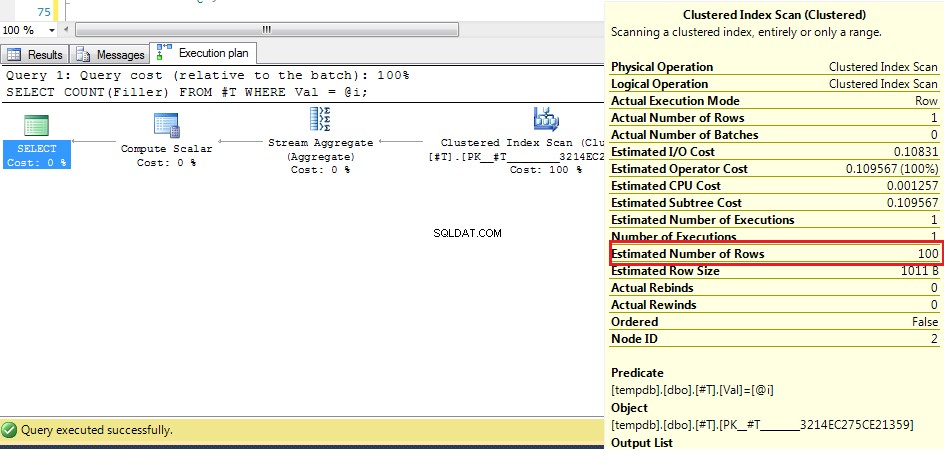
Vi kan se her (med de originale data), at det estimerede antal rækker er 100, men de faktiske rækker er 1. Fra de foregående trin ved vi, at med mere end 38 rækker vil optimeringsværktøjet vælge en klynget indeksscanning over et indeks søg, så da det bedste gæt for antallet af rækker er højere end dette, er planen for en ukendt variabel en klynget indeksscanning.
Bare for yderligere at bevise teorien, hvis vi opretter tabellen med 1000 rækker af tallene 1-27 jævnt fordelt (så det estimerede rækkeantal vil være cirka 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Kør derefter forespørgslen igen, vi får en plan med en indekssøgning:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
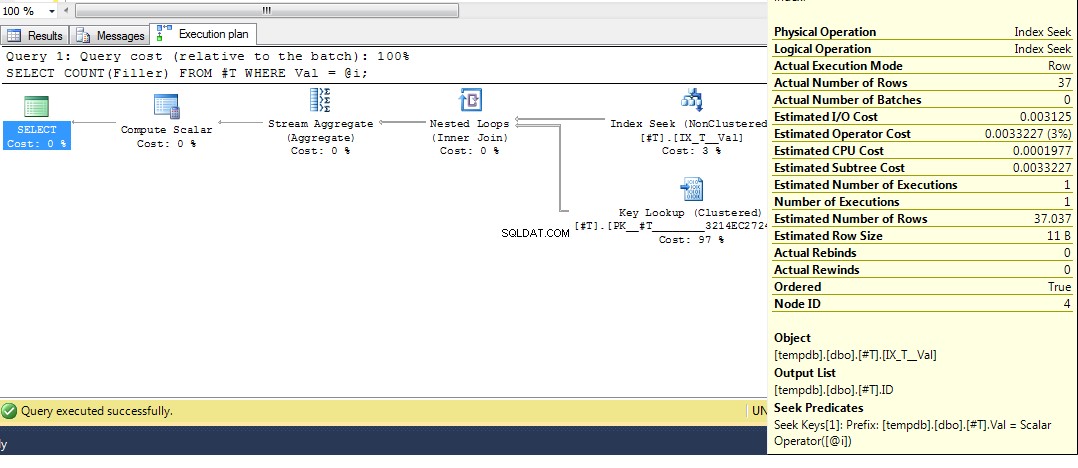
Så forhåbentlig dækker det ret udførligt, hvorfor du får den plan. Nu formoder jeg, at det næste spørgsmål er, hvordan fremtvinger du en anden plan, og svaret er, at bruge forespørgselstippet OPTION (RECOMPILE) , for at tvinge forespørgslen til at kompilere på udførelsestidspunktet, når værdien af parameteren er kendt. Vender tilbage til de originale data, hvor den bedste plan for Val = 2 er et opslag, men at bruge en variabel giver en plan med en indeksscanning, vi kan køre:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
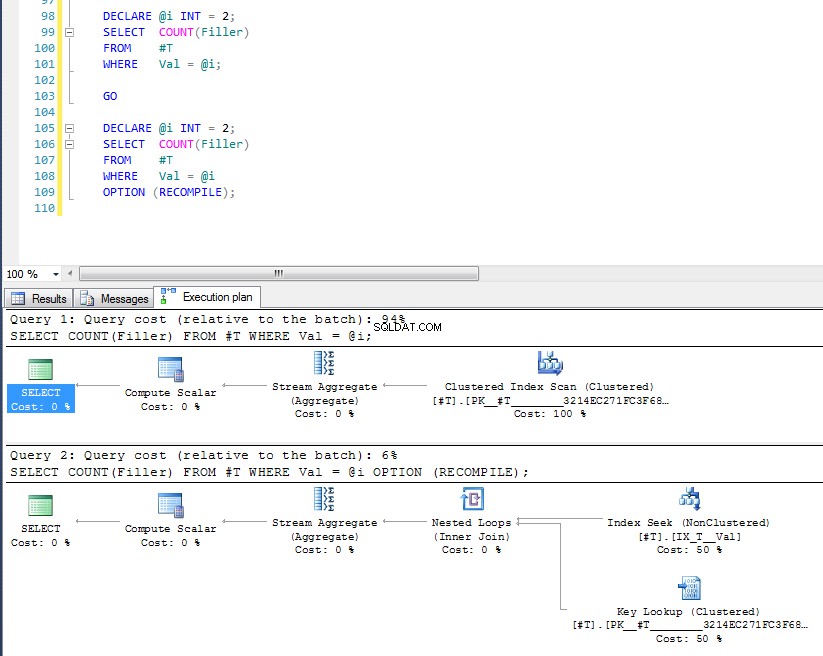
Vi kan se, at sidstnævnte bruger indekssøgning og nøgleopslag, fordi den har kontrolleret værdien af variabel på udførelsestidspunktet, og den mest passende plan for den specifikke værdi er valgt. Problemet med OPTION (RECOMPILE) er det betyder, at du ikke kan drage fordel af cachelagrede forespørgselsplaner, så der er en ekstra omkostning ved at kompilere forespørgslen hver gang.