Holder du stadig på forælder/barn-designet, eller vil du gerne prøve noget nyt, såsom SQL Server hierarchyID? Nå, det er virkelig nyt, fordi hierarchyID har været en del af SQL Server siden 2008. Selvfølgelig er nyheden i sig selv ikke et overbevisende argument. Men bemærk, at Microsoft tilføjede denne funktion for at repræsentere én-til-mange-relationer med flere niveauer på en bedre måde.
Du kan undre dig over, hvilken forskel det gør, og hvilke fordele du får ved at bruge hierarchyID i stedet for de sædvanlige forældre/barn-forhold. Hvis du aldrig har udforsket denne mulighed, kan det være overraskende for dig.
Sandheden er, at jeg ikke undersøgte denne mulighed, siden den blev udgivet. Men da jeg endelig gjorde det, fandt jeg det en stor innovation. Det er en flottere kode, men den har meget mere i sig. I denne artikel skal vi finde ud af om alle disse fremragende muligheder.
Før vi dykker ned i særegenhederne ved at bruge SQL Server hierarchyID, lad os dog afklare dets betydning og omfang.
Hvad er SQL Server HierarchyID?
SQL Server hierarchyID er en indbygget datatype designet til at repræsentere træer, som er den mest almindelige type hierarkiske data. Hvert element i et træ kaldes en node. I et tabelformat er det en række med en kolonne med hierarchyID datatype.
Normalt demonstrerer vi hierarkier ved hjælp af et tabeldesign. En ID-kolonne repræsenterer en node, og en anden kolonne står for overordnet. Med SQL Server HierarchyID behøver vi kun én kolonne med en datatype hierarchyID.
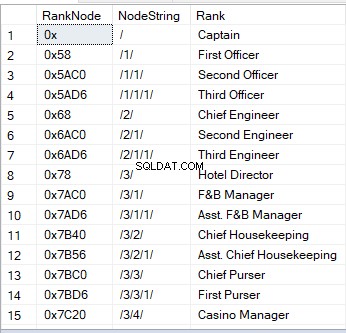
Når du forespørger i en tabel med en hierarchyID-kolonne, ser du hexadecimale værdier. Det er et af de visuelle billeder af en node. En anden måde er en streng:
'/' står for rodnoden;
'/1/', '/2/', '/3/' eller '/n/' står for børnene – direkte efterkommere 1 til n;
'/1/1/' eller '/1/2/' er "børn af børn - "børnebørn." Strengen som '/1/2/' betyder, at det første barn fra roden har to børn, som igen er to børnebørn af roden.
Her er et eksempel på, hvordan det ser ud:
I modsætning til andre datatyper kan hierarchyID-kolonner drage fordel af indbyggede metoder. For eksempel, hvis du har en hierarkiID-kolonne ved navn RankNode , kan du have følgende syntaks:
RankNode.
SQL Server HierarchyID Metoder
En af de tilgængelige metoder er IsDescendantOf . Den returnerer 1, hvis den aktuelle node er en efterkommer af en hierarki-id-værdi.
Du kan skrive kode med denne metode, der ligner den nedenfor:
VÆLG r.RankNode,r.RankFROM dbo.Ranks rWHERE r.RankNode.IsDescendantOf(0x58) =1 Andre metoder, der bruges med hierarchyID, er følgende:
- GetRoot – den statiske metode, der returnerer roden af træet.
- GetDescendant – returnerer en underordnet node af en forælder.
- GetAncestor – returnerer et hierarki-ID, der repræsenterer den n'te forfader til en given node.
- GetLevel – returnerer et heltal, der repræsenterer dybden af noden.
- ToString – returnerer strengen med den logiske repræsentation af en node. ToString kaldes implicit, når konverteringen fra hierarchyID til strengtypen finder sted.
- GetReparentedValue – flytter en node fra den gamle forælder til den nye forælder.
- Parse – fungerer som det modsatte af ToString . Det konverterer strengvisningen af et hierarki-id værdi til hexadecimal.
SQL Server HierarchyID Indexing Strategies
For at sikre, at forespørgsler til tabeller, der bruger hierarchyID, kører så hurtigt som muligt, skal du indeksere kolonnen. Der er to indekseringsstrategier:
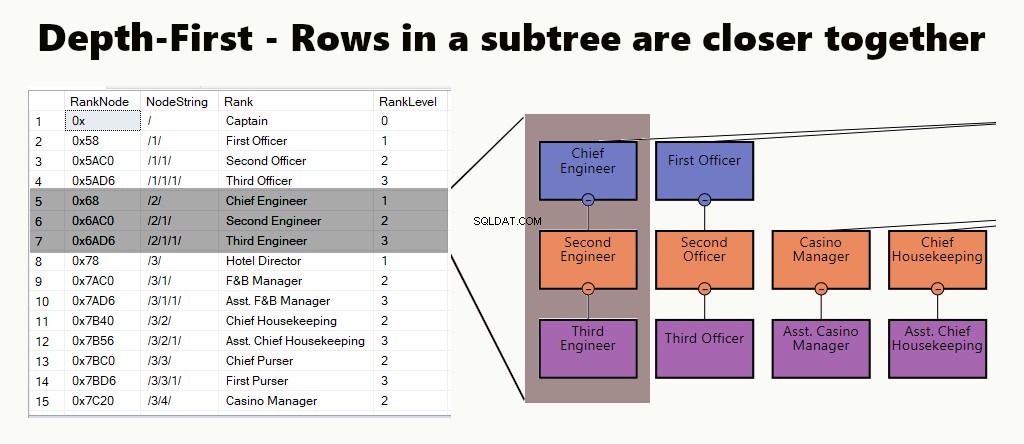
DYBDE-FØRST
I et dybde-først-indeks er undertrærækkerne tættere på hinanden. Det passer til forespørgsler som at finde en afdeling, dens underenheder og medarbejdere. Et andet eksempel er en leder og dens medarbejdere opbevaret tættere sammen.
I en tabel kan du implementere et dybde-først-indeks ved at oprette et klynget indeks for noderne. Yderligere udfører vi et af vores eksempler, bare sådan.
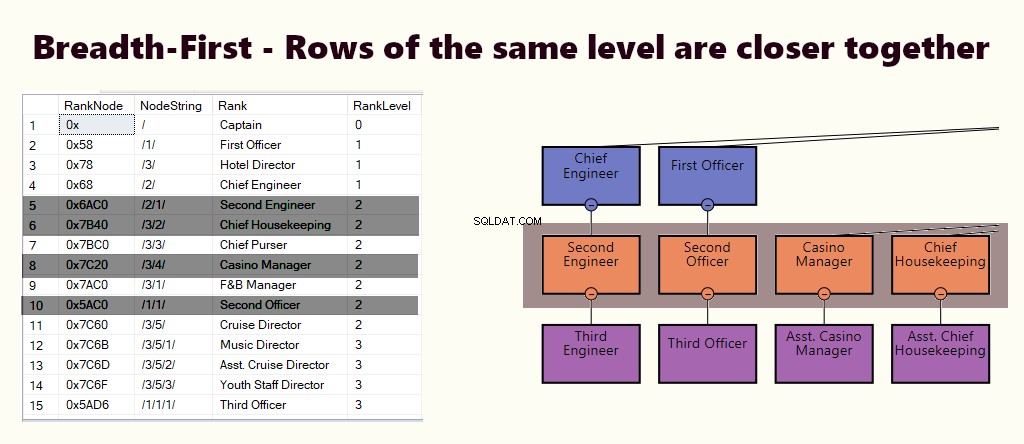
BREDDE-FØRST
I et bredde-først-indeks er det samme niveaus rækker tættere på hinanden. Det passer til forespørgsler som at finde alle lederens direkte rapporterende medarbejdere. Hvis de fleste af forespørgslerne ligner dette, skal du oprette et klynget indeks baseret på (1) niveau og (2) node.
Det afhænger af dine krav, om du har brug for et dybde-først-indeks, et bredde-først eller begge dele. Du skal balancere mellem vigtigheden af forespørgselstypen og de DML-sætninger, du udfører på bordet.
SQL Server HierarchyID Begrænsninger
Desværre kan brug af hierarchyID ikke løse alle problemer:
- SQL Server kan ikke gætte, hvad barnet til en forælder er. Du skal definere træet i tabellen.
- Hvis du ikke bruger en unik begrænsning, vil den genererede hierarki-id-værdi ikke være unik. Håndtering af dette problem er udviklerens ansvar.
- Relationer mellem en forælder og underordnede noder håndhæves ikke som et fremmednøgleforhold. Før du sletter en node, skal du derfor forespørge efter eventuelle efterkommere.
Visualisering af hierarkier
Inden vi fortsætter, overveje endnu et spørgsmål. Ser du på resultatsættet med nodestrenge, synes du, at hierarkiet visualiserer svært for dine øjne?
For mig er det et stort ja, fordi jeg ikke bliver yngre.
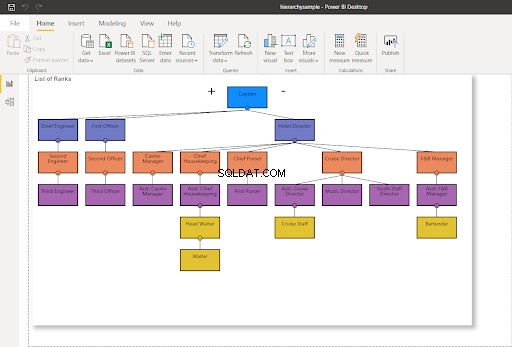
Af denne grund vil vi bruge Power BI og Hierarchy Chart fra Akvelon sammen med vores databasetabeller. De vil hjælpe med at vise hierarkiet i et organisationsdiagram. Jeg håber, det vil gøre arbejdet lettere.
Lad os nu gå i gang.
Brug af SQL Server HierarchyID
Du kan bruge HierarchyID med følgende forretningsscenarier:
- Organisationsstruktur
- Mapper, undermapper og filer
- Opgaver og delopgaver i et projekt
- Sider og undersider på et websted
- Geografiske data med lande, regioner og byer
Selvom dit forretningsscenarie ligner ovenstående, og du sjældent forespørger på tværs af hierarki-sektionerne, behøver du ikke hierarki-id.
For eksempel behandler din organisation lønsedler for medarbejdere. Har du brug for at få adgang til undertræet for at behandle en persons lønseddel? Slet ikke. Men hvis du behandler kommissioner af personer i et multi-level marketing system, kan det være anderledes.
I dette indlæg bruger vi delen af organisationsstrukturen og kommandovejen på et krydstogtskib. Strukturen er tilpasset fra organisationsdiagrammet herfra. Tag et kig på det i figur 4 nedenfor:

Nu kan du visualisere det pågældende hierarki. Vi bruger nedenstående tabeller i hele dette indlæg:
- Fartøjer – er bordet, der står for krydstogtskibenes liste.
- Rangeringer – er tabellen over mandskabsrækker. Der etablerer vi hierarkier ved hjælp af hierarchyID.
- Besætning – er listen over besætningen på hvert fartøj og deres rækker.
Tabelstrukturen for hver sag er som følger:
OPRET TABEL [dbo].[Vessel]([VesselId] [int] IDENTITET(1,1) IKKE NULL,[VesselName] [varchar](20) IKKE NULL, BEGRÆNSNING [PK_Fartøj] PRIMÆR NØGLE KLYNGET ([VesselId] ASC) MED (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, IGNORE_DUP_KEY =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ON [PRIMARY]) PÅ [PRIMARY](PRIMARY]) PÅ [PRIMARY]AB. [int] IDENTITY(1,1) NOT NULL,[Rank] [varchar](50) NOT NULL,[RankNode] [hierarchyid] NOT NULL,[RankLevel] [smallint] NOT NULL,[ParentRankId] [int] -- dette er overflødigt, men vi vil bruge dette til at sammenligne -- med forælder/barn) PÅ [PRIMÆR]GOCREATE UNIKT IKKE-KLUSTERET INDEX [IX_RankId] PÅ [dbo].[Ranks]([RankId] ASC)WITH (PAD_INDEX =FRA, STATISTICS_NORECOMPUTE =OFF, SORT_IN_TEMPDB =OFF, IGNORE_DUP_KEY =OFF, DROP_EXISTING =OFF, ONLINE =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ON [PRIMÆR]GOCREATE UNIQUE CLUSTERED INDEX [DE] ) MED (PAD_INDEX =FRA, STATISTI CS_NORECOMPUTE =FRA, SORT_IN_TEMPDB =FRA, IGNORE_DUP_KEY =FRA, DROP_EXISTING =FRA, ONLINE =FRA, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) PÅ [PRIMARY]GOCREATE-TABLE [PRIMARY]GOCREATE](ENT. 1,1) NOT NULL,[CrewName] [varchar](50) NOT NULL,[DateHired] [date] NOT NULL,[RankId] [int] NOT NULL,[VesselId] [int] NOT NULL, CONSTRAINT [PK_Crew] PRIMÆR NØGLE KLUSTERET([CrewId] ASC)Med (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, IGNORE_DUP_KEY =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) PÅ [PRIMÆR] WICCLE [PRIMÆR]. CHECK ADD CONSTRAINT [FK_Crew_Ranks] UDENLANDSKE KEY([RankId])REFERENCER [dbo].[Ranks] ([RankId])GOALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]GOALTER TABLE [dbo] .[THC CHECK TILFØJ BEGRÆNSNING [FK_Crew_Vessel] UDENLANDSKE NØGLE([VesselId])REFERENCER [dbo].[Vessel] ([VesselId])GOALTER TABEL [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]GO Indsættelse af tabeldata med SQL Server HierarchyID
Den første opgave i at bruge hierarchyID grundigt er at tilføje poster i tabellen med ethierarchyID kolonne. Der er to måder at gøre det på.
Brug af strenge
Den hurtigste måde at indsætte data med hierarchyID på er at bruge strenge. For at se dette i aktion, lad os føje nogle poster til rækkerne tabel.
INSERT INTO dbo.Ranks([Rank], RankNode, RankLevel)VALUES ('Captain', '/',0),('First Officer','/1/',1),(' Chief Engineer','/2/',1),('Hotel Director','/3/',1),('Second Officer','/1/1/',2),('Second Engineer' ,'/2/1/',2),('F&B Manager','/3/1/',2),('Chief Housekeeping','/3/2/',2),('Chief Purser ','/3/3/',2),('Casino Manager','/3/4/',2),('Cruise Director','/3/5/',2),('Tredje Officer','/1/1/1/',3),('Third Engineer','/2/1/1/',3),('Asst. F&B Manager','/3/1/1 /',3),('Asst. Chief Housekeeping','/3/2/1/',3),('First Purser','/3/3/1/',3),('Asst. Casino Manager','/3/4/1/',3),('Music Director','/3/5/1/',3),('Asst. Cruise Director','/3/5/ 2/',3),('Youth Staff Director','/3/5/3/',3) Ovenstående kode tilføjer 20 poster til rangeringstabellen.
Som du kan se, er træstrukturen blevet defineret i INSERT udtalelse ovenfor. Det er let at se, når vi bruger strenge. Desuden konverterer SQL Server den til de tilsvarende hexadecimale værdier.
Brug af Max(), GetAncestor() og GetDescendant()
Brug af strenge passer til opgaven med at udfylde de oprindelige data. I det lange løb har du brug for koden til at håndtere indsættelse uden at angive strenge.
For at udføre denne opgave skal du få den sidste node brugt af en forælder eller forfader. Vi opnår det ved at bruge funktionerne MAX() og GetAncestor() . Se eksempelkoden nedenfor:
-- tilføj en bartenderrangering, der rapporterer til Asst. F&B ManagerDECLARE @MaxNode HIERARCHYIDDECLARE @ImmediateSuperior HIERARCHYID =0x7AD6SELECT @MaxNode =MAX(RankNode) FRA dbo.Ranks rWHERE r.RankNode.GetAncestor(1) =@ImmediateSuperiorRankart,BImmediateSuperiorRankart'Rank INTO dboRankInSERT (IndgåendeSuperiorRank. ', @ImmediateSuperior.GetDescendant(@MaxNode,NULL), @ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel()) Nedenfor er pointene hentet fra ovenstående kode:
- Først skal du have en variabel for den sidste node og den umiddelbare overordnede.
- Den sidste node kan hentes ved hjælp af MAX() mod RankNode for den angivne forælder eller nærmeste overordnede. I vores tilfælde er det Assistant F&B Manager med en nodeværdi på 0x7AD6.
- Nu skal du bruge @ImmediateSuperior.GetDescendant(@MaxNode, NULL) for at sikre, at der ikke vises et duplikat underordnet. . Værdien i @MaxNode er det sidste barn. Hvis det ikke er NULL , GetDescendant() returnerer den næste mulige nodeværdi.
- Sidst, GetLevel() returnerer niveauet for den nye oprettede node.
Forespørgsel efter data
Efter at have tilføjet poster til vores tabel, er det tid til at forespørge på det. Der er 2 måder at forespørge data på:
Forespørgslen efter Direct Descendants
Når vi leder efter de medarbejdere, der refererer direkte til lederen, skal vi vide to ting:
- Knudeværdien for lederen eller forælderen
- Niveauet for medarbejderen under lederen
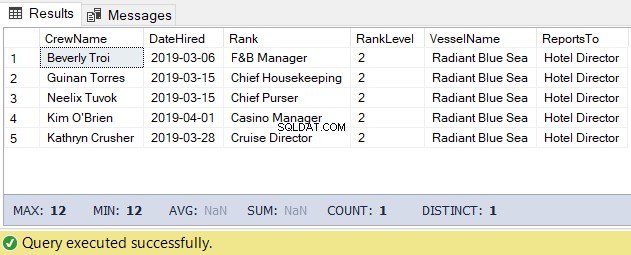
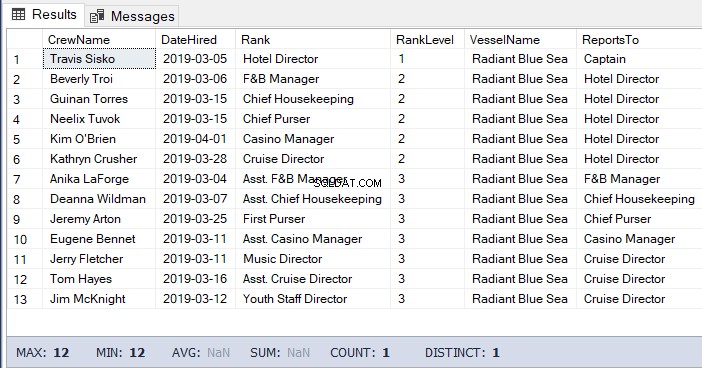
Til denne opgave kan vi bruge koden nedenfor. Outputtet er listen over besætningen under hoteldirektøren.
-- Hent listen over besætningen, der rapporterer direkte til Hotel DirectorDECLARE @Node HIERARCHYID =0x78 -- Hoteldirektørens node/hierarchyidDECLARE @Level SMALLINT =@Node.GetLevel()SELECT a.CrewName,a.DateHired ,b.Rank,b.RankLevel,c.VesselName,(SELECT Rank FROM dbo.Ranks WHERE RankNode =b.RankNode.GetAncestor(1)) AS ReportsToFROM dbo.Crew aINNER JOIN DBO.Ranks b ON a.RankId =b. RankIdINNER JOIN dbo.Vessel c ON a.VesselId =c.VesselIdWHERE b.RankNode.IsDescendantOf(@Node)=1AND b.RankLevel =@Level + 1 -- tilføj 1 for niveauet af besætningen under -- Hotel Director Resultatet af ovenstående kode er som følger i figur 5:
Forespørgsel efter undertræer
Nogle gange skal du også liste børnene og børnenes børn ned til bunden. For at gøre dette skal du have overordnets hierarki-ID.
Forespørgslen vil ligne den forrige kode, men uden behov for at få niveauet. Se kodeeksemplet:
-- Få listen over besætningen under Hotel Director ned til det laveste niveauDECLARE @Node HIERARCHYID =0x78 -- Hoteldirektørens node/hierarchyidSELECT a.CrewName,a.DateHired,b.Rank,b. RankLevel,c.VesselName,(SELECT Rank FROM dbo.Ranks WHERE RankNode =b.RankNode.GetAncestor(1)) AS ReportsToFROM dbo.Crew aINNER JOIN dbo.Ranks b ON a.RankId =b.RankIdINNER JOIN c dboONV. a.VesselId =c.VesselIdWHERE b.RankNode.IsDescendantOf(@Node)=1 Resultatet af ovenstående kode:
Flytning af noder med SQL Server HierarchyID
En anden standardoperation med hierarkiske data er at flytte et barn eller et helt undertræ til en anden forælder. Men før vi fortsætter, bedes du bemærke et potentielt problem:
Potentielt problem
- For det første involverer bevægelige noder I/O. Hvor ofte du flytter noder kan være den afgørende faktor, hvis du bruger hierarchyID eller det sædvanlige forælder/barn.
- For det andet, flytning af en node i et overordnet/underordnet design opdaterer én række. På samme tid, når du flytter en node med hierarchyID, opdaterer den en eller flere rækker. Antallet af berørte rækker afhænger af hierarkiniveauets dybde. Det kan blive til et betydeligt ydeevneproblem.
Løsning
Du kan håndtere dette problem med dit databasedesign.
Lad os overveje det design, vi brugte her.
I stedet for at definere hierarkiet på Besætningen tabellen, definerede vi den i Rangene bord. Denne tilgang adskiller sig fra medarbejderen tabellen i AdventureWorks eksempeldatabase, og den giver følgende fordele:
- Besætningsmedlemmerne bevæger sig oftere end rækkerne i et fartøj. Dette design vil reducere bevægelserne af noder i hierarkiet. Som et resultat minimerer det problemet defineret ovenfor.
- Definition af mere end ét hierarki i Besætningen tabellen er mere kompliceret, da to fartøjer har brug for to kaptajner. Resultatet er to rodknuder.
- Hvis du har brug for at vise alle rækker med det tilsvarende besætningsmedlem, kan du bruge en LEFT JOIN. Hvis der ikke er nogen om bord for den rang, viser den en tom plads til positionen.
Lad os nu gå videre til formålet med dette afsnit. Tilføj børneknuder under de forkerte forældre.
For at visualisere, hvad vi er ved at gøre, forestil dig et hierarki som det nedenfor. Bemærk de gule noder.

Flyt en node uden børn
Flytning af en underordnet node kræver følgende:
- Definer hierarki-id'et for den underordnede node, der skal flyttes.
- Definer den gamle forælders hierarki-id.
- Definer den nye forælders hierarki-id.
- Brug OPDATERING med GetReparentedValue() for at flytte noden fysisk.
Start med at flytte en node uden børn. I eksemplet nedenfor flytter vi krydstogtstaben fra under krydstogtdirektøren til under asst. Krydstogtsdirektør.
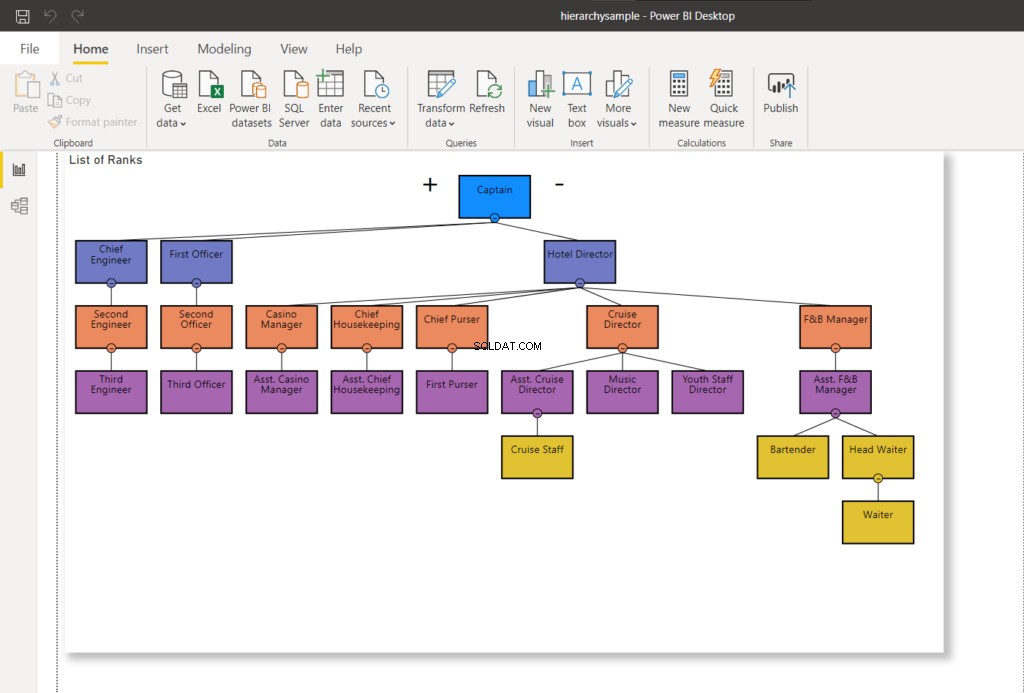
-- Flytning af en node uden underordnet nodeDECLARE @NodeToMove HIERARCHYIDDECLARE @OldParent HIERARCHYIDDECLARE @NewParent HIERARCHYIDSELECT @NodeToMove =r.RankNodeFROM dbo.Ranks rWHERE @RankId -Parent-personalet =24Parent-personalet =. GetAncestor(1)SELECT @NewParent =r.RankNodeFROM dbo.Ranks rWHERE r.RankId =19 -- den assisterende krydstogtdirektørUPDATE dbo.RanksSET RankNode =@NodeToMove.GetReparentedValue(@OldParent,@NewParent)WHERENo RankNoMove = Når noden er opdateret, vil en ny hex-værdi blive brugt til noden. Opdaterer min Power BI-forbindelse til SQL Server – det ændrer hierarkidiagrammet som vist nedenfor:
I figur 8 rapporterer krydstogtpersonalet ikke længere til krydstogtdirektøren – det ændres til at rapportere til assisterende krydstogtdirektør. Sammenlign det med figur 7 ovenfor.
Lad os nu gå videre til næste fase og flytte hovedtjeneren til den assisterende F&B Manager.
Flyt en node med børn
Der er en udfordring i denne del.
Sagen er, at den tidligere kode ikke fungerer med en node med kun et barn. Vi husker, at flytning af en node kræver opdatering af en eller flere underordnede noder.
Ydermere slutter det ikke der. Hvis den nye forælder har et eksisterende barn, støder vi muligvis ind i duplikerede nodeværdier.
I dette eksempel er vi nødt til at se det problem i øjnene:Asst. F&B Manager har en Bartender-undernode.
Parat? Her er koden:
-- Flyt en node med mindst én childDECLARE @NodeToMove HIERARCHYIDDECLARE @OldParent HIERARCHYIDDECLARE @NewParent HIERARCHYIDSELECT @NodeToMove =r.RankNodeFROM dbo.Ranks rWHERE r.RankId @RankId @NokId-warent =22Ode SELECT .GetAncestor(1) -- overtjenerens gamle forælder --> asst chief housekeeping SELECT @NewParent =r.RankNodeFROM dbo.Ranks rWHERE r.RankId =14 -- den assisterende f&b managerDECLARE children_cursor CURSOR FOR SELECT RankNode FROM RankNode FROM dbo.RanksNo dbo. .GetAncestor(1) =@OldParent; DECLARE @ChildId hierarchyid; ÅBN children_cursor FETCH NEXT FROM children_cursor INTO @ChildId; WHILE @@FETCH_STATUS =0 BEGIN START:ERKLÆR @NewId hierarchyid; SELECT @NewId =@NewParent.GetDescendant(MAX(RankNode), NULL) FRA dbo.Ranks r WHERE RankNode.GetAncestor(1) =@NewParent; -- sørg for -- at få et nyt id i tilfælde af at der er en --sibling UPDATE dbo.Ranks SET RankNode =RankNode.GetReparentedValue(@ChildId, @NewId) WHERE RankNode.IsDescendantOf(@ChildId) =1; HVIS @@fejl <> 0 GÅ TIL START -- Ved fejl, prøv igen FETCH NEXT FROM children_cursor INTO @ChildId; END CLOSE children_cursor; DEALLOCATE children_cursor; I ovenstående kodeeksempel starter iterationen som behovet for at overføre noden ned til barnet på det sidste niveau.
Når du har kørt det, vil rangeringen tabel vil blive opdateret. Og igen, hvis du vil se ændringerne visuelt, skal du opdatere Power BI-rapporten. Du vil se ændringerne, der ligner den nedenfor:
Fordele ved at bruge SQL Server HierarchyID vs. Forælder/Barn
For at overbevise nogen om at bruge en funktion, skal vi kende fordelene.
Derfor vil vi i dette afsnit sammenligne udsagn ved at bruge de samme tabeller som dem fra begyndelsen. Den ene vil bruge hierarchyID, og den anden vil bruge forældre/barn-tilgangen. Resultatsættet vil være det samme for begge tilgange. Vi forventer, at den til denne øvelse er den fra Figur 6 ovenfor.
Nu hvor kravene er præcise, lad os undersøge fordelene grundigt.
Enklere at kode
Se koden nedenfor:
-- List alle besætningen under Hotel Director ved hjælp af hierarchyIDSELECTa.CrewName,a.DateHired,b.Rank,b.RankLevel,c.VesselName,d.RANK AS ReportsToFROM dbo.Crew aINNER JOIN DBO. Vessel c ON a.VesselId =c.VesselIdINNER JOIN dbo.Ranks b ON a.RankId =b.RankIdINNER JOIN dbo.Ranks d ON d.RankNode =b.RankNode.GetAncestor(1)Hvor a.VesselId.RankNode .IsDescendantOf(0x78)=1 Denne prøve behøver kun en hierarki-id-værdi. Du kan ændre værdien efter behag uden at ændre forespørgslen.
Sammenlign nu sætningen for forældre/barn-tilgangen, der producerer det samme resultatsæt:
-- List alle besætningen under hoteldirektøren ved hjælp af forælder/barnSELECTa.CrewName,a.DateHired,b.Rank,b.RankLevel,c.VesselName,d.Rank AS ReportsToFROM dbo.Crew aINNER JOIN dbo.Vessel c ON a.VesselId =c.VesselIdINNER JOIN dbo.Ranks b ON a.RankId =b.RankIdINNER JOIN dbo.Ranks d ON b.RankParentId =d.RankIdWHERE a.VesselId =1AND (b.)RankID =1AND (b.) ELLER (b.RankParentID =4 ELLER b.RankParentId>=7) Hvad synes du? Kodeeksemplerne er næsten de samme på nær et punkt.
HVOR klausul i den anden forespørgsel vil ikke være fleksibel at tilpasse, hvis der kræves et andet undertræ.
Gør den anden forespørgsel generisk nok, og koden bliver længere. Yikes!
Hurtigere udførelse
Ifølge Microsoft er "undertræsforespørgsler betydeligt hurtigere med hierarchyID" sammenlignet med forælder/barn. Lad os se, om det er sandt.
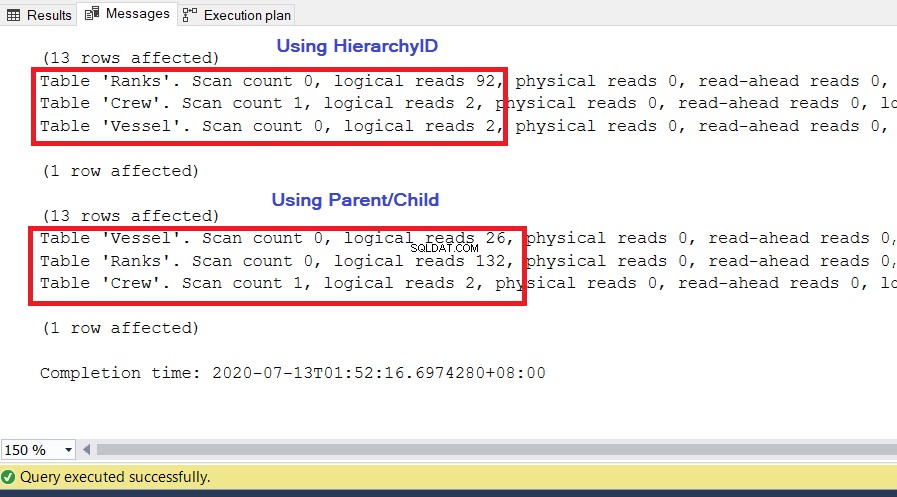
Vi bruger de samme forespørgsler som tidligere. En væsentlig metrik til brug for ydeevne er de logiske læsninger fra SET STATISTICS IO . Den fortæller, hvor mange 8KB sider SQL Server skal bruge for at få det resultatsæt, vi ønsker. Jo højere værdien er, jo større er antallet af sider, som SQL Server får adgang til og læser, og jo langsommere kører forespørgslen. Udfør SET STATISTICS IO ON og genudfør de to forespørgsler ovenfor. Den laveste værdi af de logiske læsninger vil være vinderen.
ANALYSE
Som du kan se i figur 10, har I/O-statistikkerne for forespørgslen med hierarchyID lavere logiske læsninger end deres modstykker til forældre/underordnede. Bemærk følgende punkter i dette resultat:
- Fartøjet tabel er den mest bemærkelsesværdige af de tre borde. Brug af hierarchyID kræver kun 2 * 8KB =16KB sider, der skal læses af SQL Server fra cachen (hukommelsen). I mellemtiden kræver brug af forælder/barn 26 * 8KB =208KB sider – væsentligt højere end ved brug af hierarchyID.
- Rangene tabel, som inkluderer vores definition af hierarkier, kræver 92 * 8KB =736KB. På den anden side kræver brug af forældre/barn 132 * 8KB =1056KB.
- Besætningen tabel har brug for 2 * 8KB =16KB, hvilket er det samme for begge tilgange.
Kilobytes sider kan være en lille værdi for nu, men vi har kun nogle få poster. Det giver os dog en idé om, hvor belastende vores forespørgsel vil være på enhver server. For at forbedre ydeevnen kan du udføre en eller flere af følgende handlinger:
- Tilføj passende indeks(er)
- Omstrukturer forespørgslen
- Opdater statistik
Hvis du gjorde ovenstående, og de logiske aflæsninger faldt uden at tilføje flere poster, ville ydeevnen stige. Så længe du laver de logiske læsninger lavere end for den, der bruger hierarchyID, vil det være gode nyheder.
Men hvorfor henvise til logiske læsninger i stedet for forløbet tid?
Kontrollerer den forløbne tid for begge forespørgsler ved hjælp af SET STATISTICS TIME ON afslører et lille antal millisekunders forskelle for vores lille sæt data. Din udviklingsserver kan også have en anden hardwarekonfiguration, SQL Server-indstillinger og arbejdsbelastning. En forløbet tid på mindre end et millisekund kan snyde dig, hvis din forespørgsel yder så hurtigt, som du forventer eller ej.
GRAVER VIDERE
INDSTILL STATISTIK IO TIL afslører ikke de ting, der sker "bag kulisserne." I dette afsnit finder vi ud af, hvorfor SQL Server ankommer med disse tal ved at se på eksekveringsplanen.
Lad os starte med udførelsesplanen for den første forespørgsel.
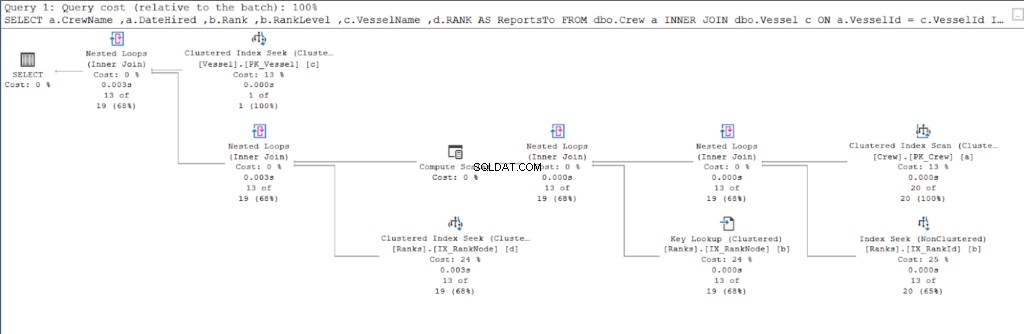
Se nu på udførelsesplanen for den anden forespørgsel.
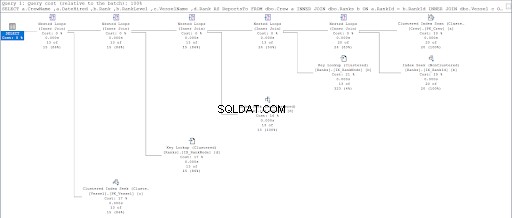
Ved at sammenligne figur 11 og 12 ser vi, at SQL Server har brug for yderligere indsats for at producere resultatsættet, hvis du bruger forældre/barn-tilgangen. HVOR klausulen er ansvarlig for denne komplikation.
Fejlen kan dog også skyldes borddesignet. Vi brugte den samme tabel til begge tilgange:Rangene bord. Så jeg prøvede at duplikere Rangene tabel, men brug forskellige grupperede indekser, der er passende for hver procedure.
Resultatet var, at brugen af hierarchyID stadig havde færre logiske læsninger sammenlignet med modstykket til forældre/barn. Endelig beviste vi, at Microsoft havde ret i at hævde det.
Konklusion
Her er det centrale aha-moment for hierarchyID:
- HierarchyID er en indbygget datatype designet til en mere optimeret repræsentation af træer, som er den mest almindelige type hierarkiske data.
- Hvert element i træet er en node, og hierarki-id-værdier kan være i hexadecimal- eller strengformat.
- HierarchyID kan anvendes til data fra organisationsstrukturer, projektopgaver, geografiske data og lignende.
- Der er metoder til at krydse og manipulere hierarkiske data, såsom GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () og mere.
- Den konventionelle måde at forespørge hierarkiske data på er at hente de direkte efterkommere af en node eller få undertræerne under en node.
- Brugen af hierarchyID til at forespørge på undertræer er ikke kun nemmere at kode. Den yder også bedre end forældre/barn.
Forældre/barn-design er slet ikke dårligt, og dette indlæg er ikke for at mindske det. At udvide mulighederne og introducere nye ideer er dog altid en stor fordel for en udvikler.
Du kan selv prøve de eksempler, vi har tilbudt her. Modtag effekterne og se, hvordan du kan anvende det til dit næste projekt, der involverer hierarkier.
Hvis du kan lide opslaget og dets ideer, kan du sprede budskabet ved at klikke på deleknapperne for det foretrukne sociale medie.