Introduktion til SQL Server-indekser
Microsoft SQL Server betragtes som et af de relationelle databasestyringssystemer (RDBMS ), hvor dataene er logisk organiseret i rækker og kolonner, der er gemt i databeholdere kaldet tabeller. Fysisk er tabellerne gemt som 8 KB sider der kan organiseres i Heap- eller B-Tree Clustered-tabeller. I bunken tabel, er der ingen sorteringsrækkefølge, der styrer rækkefølgen af data inde i datasiderne og rækkefølgen af sider i den tabel, da der ikke er defineret et Clustered index på den tabel for at håndhæve sorteringsmekanismen. Hvis et Clustered indeks er defineret på én kolonne i gruppen af tabelkolonner, vil dataene blive sorteret inde på datasiderne baseret på værdierne i Clustered index key-kolonnerne, og siderne vil blive linket sammen baseret på disse indeksnøgleværdier. Denne sorterede tabel kaldes en Klyngetabel .
I SQL Server betragtes indekset som en vigtig og effektiv nøgle i ydelsesjusteringsprocessen. Formålet med at oprette et indeks er at fremskynde adgangen til basistabellen og hente de anmodede data uden at skulle scanne alle tabelrækkerne for at returnere de anmodede data. Du kan tænke på databaseindekset som et bogindeks, der hjælper dig med hurtigt at finde ordene i bogen, uden at skulle læse hele bogen for at finde det ord. Antag for eksempel, at du skal hente oplysninger om en specifik kunde ved hjælp af et kunde-id. Hvis der ikke er defineret et indeks for kolonnen Kunde-id i denne tabel, kontrollerer SQL Server Engine alle tabelrækkerne, én efter én, for at hente kunden med det angivne ID. Hvis der er defineret et indeks for kunde-id-kolonnen i denne tabel, vil SQL Server Engine søge efter de anmodede kunde-id-værdier i det sorterede indeks i stedet for i basistabellen for at hente information om kunden, hvilket reducerer antallet af scannede rækker for at hente dataene.
I SQL Server er indekset logisk opbygget som 8K sider, eller indeksnoder, i form af et B-træ. B-Tree-strukturen indeholder tre niveauer:et rodniveau der inkluderer én indeksside øverst i B-træet, et Løvniveau der er placeret i bunden af B-træet og indeholder datasider og et Mellemniveau som inkluderer alle noder, der er placeret mellem rod- og bladniveauet, med indeksnøgleværdier og peger til de følgende sider. Denne B-træform giver en hurtig måde at navigere på datasiderne fra venstre mod højre og fra toppen til bunden, baseret på indeksnøglen.
I SQL Server er der to hovedtyper af indekser, et Clustered index, hvor de faktiske data lagres på bladniveausiderne i indekset, med mulighed for kun at oprette ét klynget indeks for hver tabel, da dataene inde i datasiderne og rækkefølgen af siderne vil blive sorteret baseret på det klyngede indeks nøgle. Hvis du definerer en primær nøglebegrænsning i din tabel, oprettes der automatisk et klyngeindeks, hvis der ikke tidligere var defineret et klyngeindeks for den pågældende tabel. Den anden type indekser er et Ikke-klyngede indeks som inkluderer en sorteret kopi af indeksnøglekolonnerne og en pegepind til resten af kolonnerne i basistabellen eller det klyngede indeks med mulighed for at oprette op til 999 ikke-klyngede indekser for hver tabel.
SQL Server giver os andre specielle typer indekser, såsom et Unikt indeks der oprettes automatisk, når en unik begrænsning er defineret for at håndhæve unikheden af specifikke kolonneværdier, et sammensat indeks hvor mere end én nøglekolonne vil deltage i indeksnøglen, et dækkende indeks hvor alle kolonner, der anmodes om af en specifik forespørgsel, vil deltage i indeksnøglen, et filtreret indeks det er et optimeret ikke-klynget indeks med et filterprædikat til kun at indeksere en lille del af tabelrækkerne, et rumligt indeks der er oprettet på de kolonner, der lagrer geografiske data, et XML-indeks, der er oprettet på XML-binære store objekter (BLOB'er) i XML-datatypekolonner, et Columnstore-indeks hvor data er organiseret i søjleformet dataformat, et Fuldtekstindeks der er oprettet af SQL Server Full-Text Engine og et Hash-indeks der bruges i hukommelsesoptimerede tabeller.
Som jeg plejede at kalde SQL Server-indekset, er dette et tveægget sværd , hvor SQL Server Query Optimizer kan drage fordel af indekset, der er designet godt til at forbedre ydeevnen af dine applikationer ved at fremskynde datahentningsprocessen. I modsætning hertil vil et indeks, der er designet på en dårlig måde, ikke blive valgt af SQL Server Query Optimizer, og det vil forringe ydeevnen af dine applikationer ved at sænke dataændringsoperationerne og opbruge din lagerplads uden at udnytte det i dataene genfindingsprocesser. Derfor er det bedre først at følge de bedste praksisser og retningslinjer for oprettelse af indeks, kontrollere effekten af oprettelse på udviklingsmiljøet og finde et kompromis mellem hastigheden af datahentningsoperationer og omkostningerne ved at tilføje det indeks på dataændringsoperationerne og pladskravene for det indeks, før det anvendes på produktionsmiljøet.
Før du opretter et indeks, skal du studere de forskellige aspekter, der påvirker oprettelsen og brugen af indekset. Dette inkluderer typen af databasens arbejdsbyrde, Online Transaction Processing (OLTP) eller Online Analytical Processing (OLAP), tabellens størrelse , egenskaberne for tabelkolonnerne , sorteringsrækkefølgen af kolonnerne i forespørgslen, indekstypen der svarer til forespørgslen og lageregenskaberne såsom FILLFACTOR og PAD_INDEX muligheder, der styrer procentdelen af plads på hvert bladniveau og siderne på mellemniveau, der skal udfyldes med data.
SQL Server Index Fragmentation
Dit arbejde som DBA er ikke begrænset til at skabe det rigtige indeks. Når indekset er oprettet, bør du overvåge indeksbrug og statistik, for eksempel skal du vide, om dette indeks bruges dårligt eller slet ikke bruges. Således kan du levere den korrekte løsning til at vedligeholde disse indekser eller erstatte dem med mere effektive. På denne måde vil du bevare den højeste anvendelige ydeevne for dit system. Du kan spørge dig selv:Hvorfor bruger SQL Server Query Optimizer ikke længere mit indeks, selvom det gjorde det før?
Svaret er hovedsageligt relateret til de løbende data- og skemaændringer, der udføres på basistabellen, og som bør afspejles i indekserne. Over tid, og med alle disse ændringer, bliver indekssider usorterede, hvilket får indekset til at blive fragmenteret. En anden grund til fragmenteringen er et forsøg på at indsætte en ny værdi eller opdatere den nuværende værdi, og den nye værdi passer ikke ind i den ledige plads, der er ledig i øjeblikket. I dette tilfælde vil siden blive delt op i to sider, hvor den nye side bliver oprettet fysisk efter sidste side. Og du kan forestille dig at læse fra et fragmenteret indeks og antallet af sider, der skal scannes, og selvfølgelig antallet af I/O-operationer udført for at hente flere poster på grund af afstanden mellem disse sider. Og på grund af disse ekstra omkostninger ved at bruge dette fragmenterede indeks, vil SQL Server Query Optimizer ignorere dette indeks.
Forskellige måder at få indeksfragmentering på
SQL Server giver os forskellige måder at få procentdelen af indeksfragmentering på. Den første måde er at kontrollere procentdelen af indeksfragmentering i indekset Egenskaber vinduet under Fragmentering fanen, som vist nedenfor:
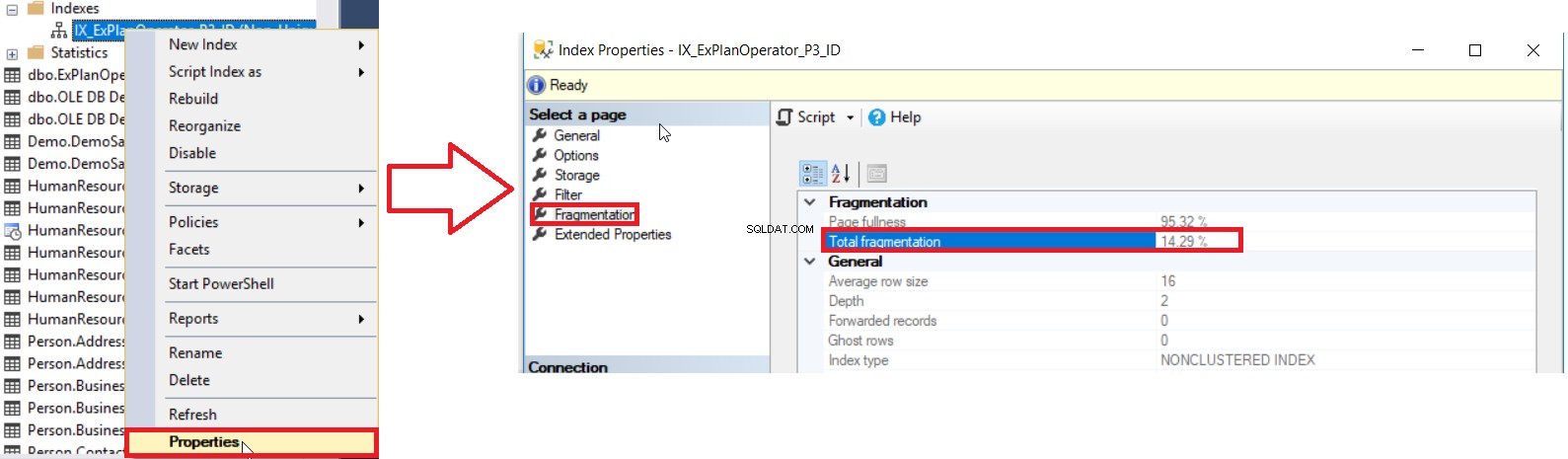
Men for at kontrollere fragmenteringsniveauet for flere indekser, skal du først udføre UI-metodekontrollen for alle indekserne, et efter et, hvilket er en tidsspildende operation. Den anden tilgængelige metode til at kontrollere fragmenteringsniveauet for alle databaseindekserne er at forespørge sys.dm_db_index_physical_stats DMF og forbinde det med sys.indexes DMV for at hente alle oplysninger om disse indekser, idet der tages hensyn til, at disse statistikker vil blive opdateret, når SQL Server-tjenesten genstartes ved hjælp af en forespørgsel, der ligner følgende:
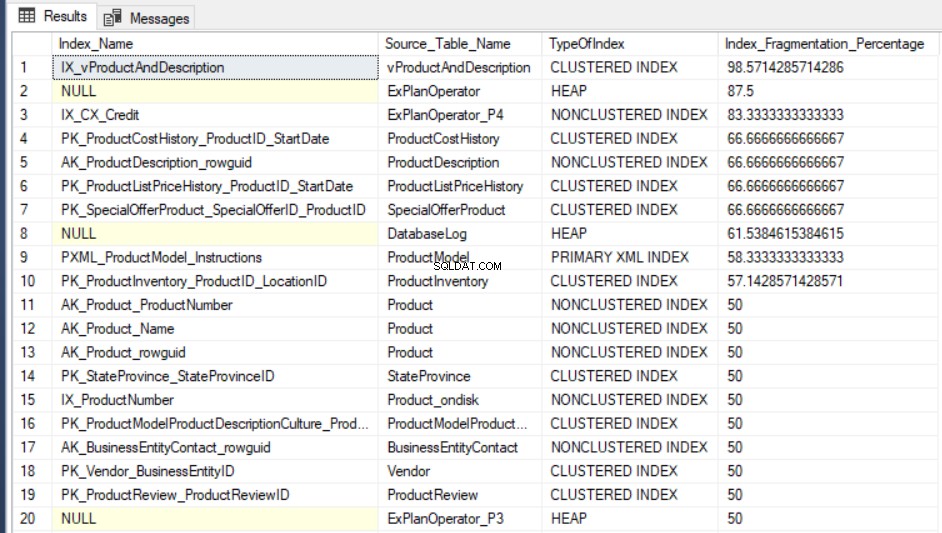
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Outputresultatet af forespørgsler på AdventureWorks2016CTP3 testdatabasen ligner følgende:
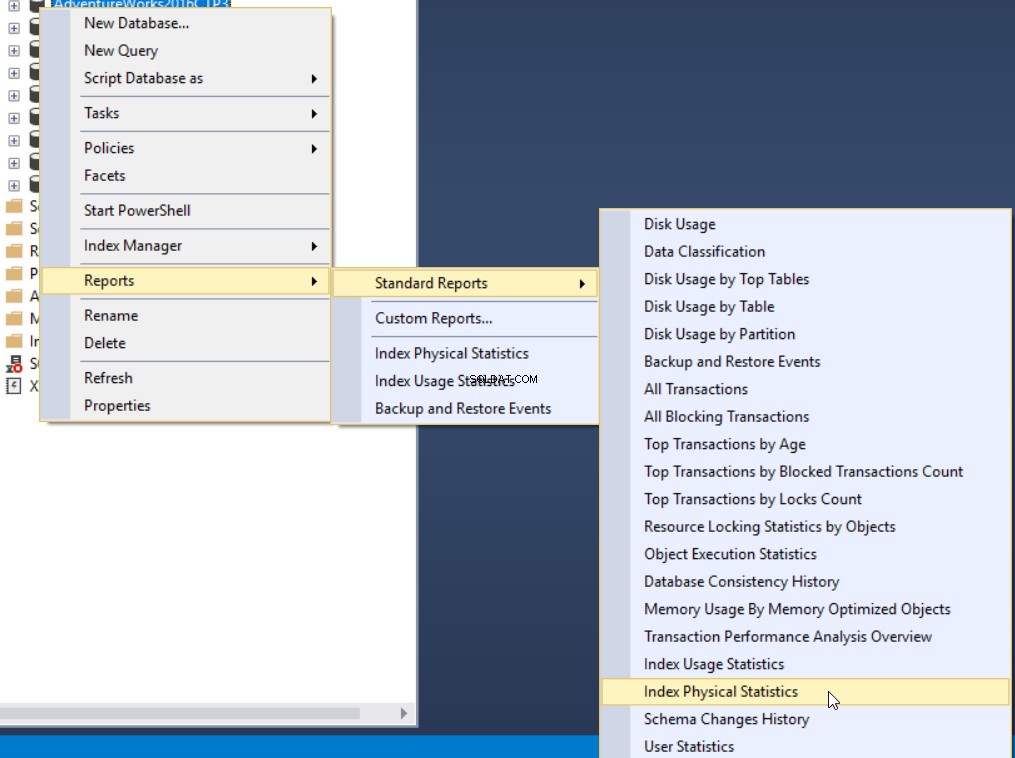
Den tredje metode til at få fragmenteringsprocenten er at bruge den indbyggede SQL Server-standardrapport kaldet Index Physical Statistics. Denne rapport returnerer nyttige oplysninger om indekspartitionerne, fragmenteringsprocenten, antallet af sider på hver indekspartition og anbefalinger til, hvordan man løser indeksfragmenteringsproblemet ved at genopbygge eller omorganisere indekset. For at se rapporten skal du højreklikke på din database, vælge indstillingen Rapporter, Standardrapporter og vælge Indeks fysisk statistik som nedenfor:
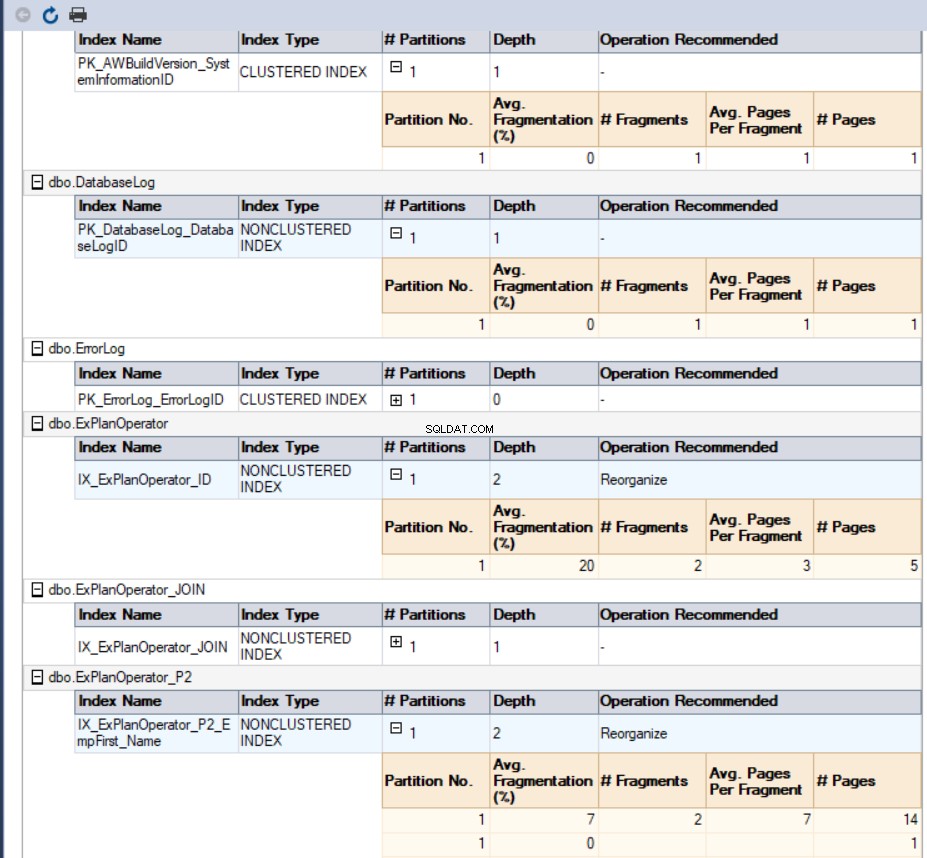
I vores tilfælde vil den genererede rapport se sådan ud:
Den sidste og nemmeste måde at hente fragmenteringsprocenten af alle databaseindekser på er dbForge Index Manager-værktøjet. dbForge Index Manager tool er et tilføjelsesprogram, der kan føjes til dit SQL Server Management Studio for at analysere SQL Server-databaseindekserne, hvilket giver dig en meget nyttig rapport med status for de valgte databaseindekser og vedligeholdelsesforslag til at løse disse indeksfragmenteringsproblemer.
Når du har installeret tilføjelsesprogrammet dbForge Index Manager til din SSMS, kan du køre det ved at højreklikke på databasen, der skal scannes, vælge Index Manager , derefter Administrer indeksfragmentering som vist nedenfor:
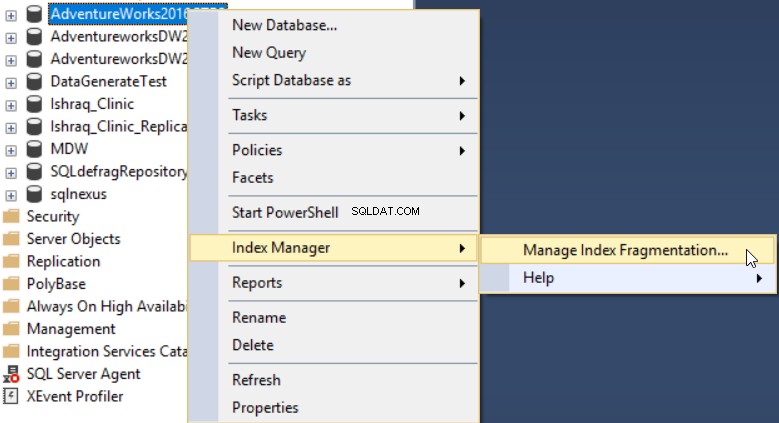
Værktøjet dbForge Index Manager giver dig mulighed for at få et overordnet billede af fragmenteringen af de valgte databaseindekser med anbefalinger til de korrekte handlinger for at løse dette problem, som vist nedenfor:

Værktøjet dbForge Index Manager giver dig også mulighed for at skifte mellem databaser og giver dig en ny rapport efter scanning af denne database som vist nedenfor:
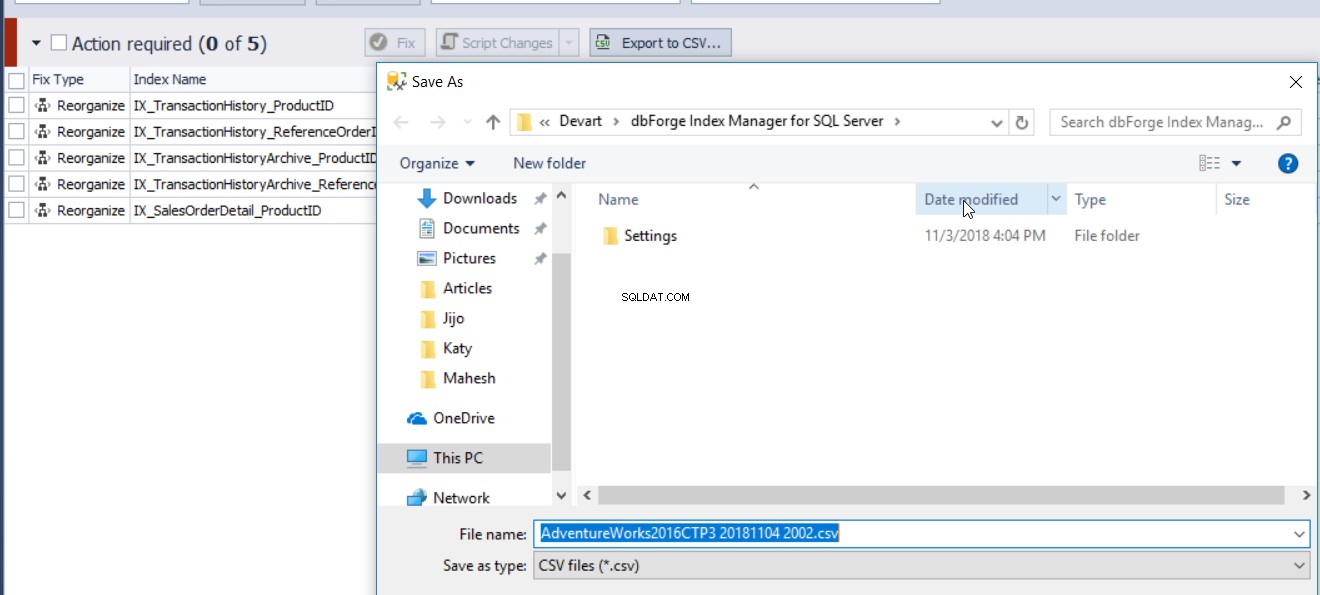
Indeksfragmenteringsrapporten genereret af dbForge Index Manager-værktøjet kan eksporteres til en CSV-fil for at analysere indeksernes fragmenteringsstatus, som vist nedenfor:
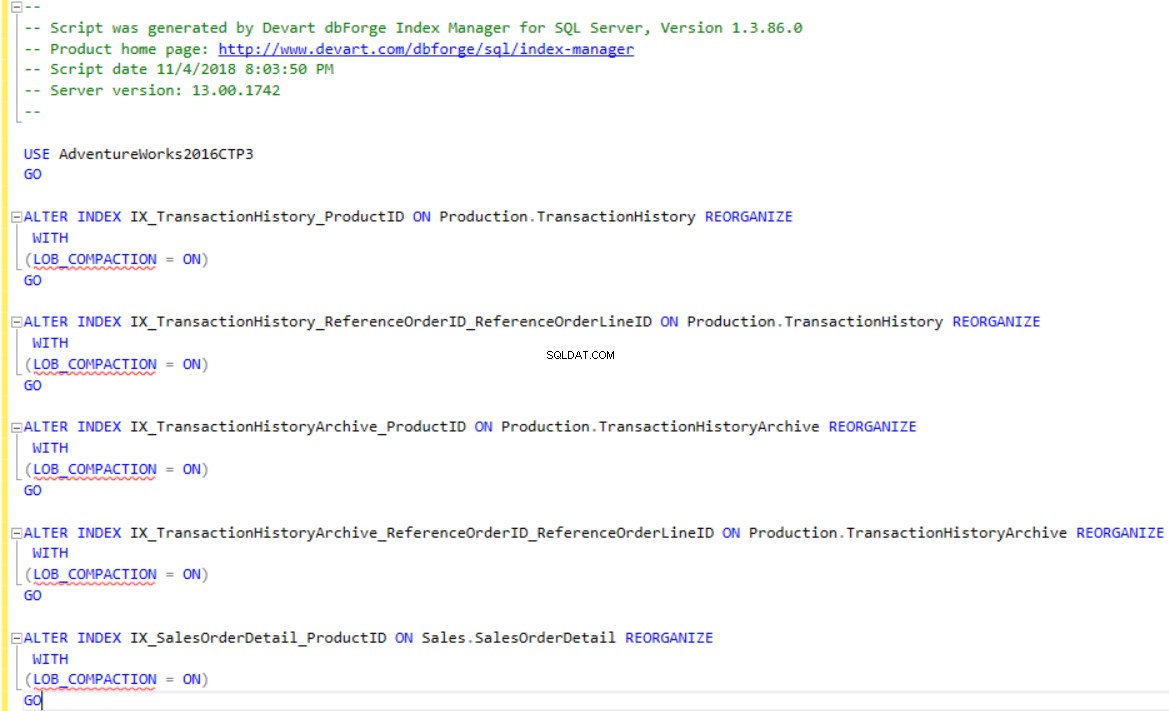
dbForge Index Manager giver dig mulighed for at generere T-SQL-scripts for at genopbygge eller omorganisere indekserne i henhold til værktøjsanbefalingen. Brug Scriptændringer mulighed for at vise eller gemme scriptet for de indekser, der er fragmenteret, som vist nedenfor:
Værktøjet dbForge Index Manager giver dig mulighed for at rette indeksfragmenteringsproblemet direkte ved at klikke på Ret knap, der udfører den anbefalede handling direkte på de valgte indekser og viser rettelsesstatus på Resultatet kolonne som vist nedenfor:

Hvis du klikker på Genanalysere knappen, vil den scanne indeksfragmenteringen på databasen igen efter at have udført rettelseshandlingen med succes. Det, der er anført her i denne artikel, er blot en introduktion til, hvordan dbForge Index Manager-værktøjet vil hjælpe os med at identificere og rette indeksfragmenteringsproblemer. Min anbefaling til dig er at downloade det og tjekke, hvad dette værktøj kan tilbyde dig.
Nyttige links:
- Grundlæggende oplysninger om indeks
- Typer af indekser
- Klyngede og ikke-klyngede indekser beskrevet
- Klyngede indeksstrukturer
Nyttigt værktøj:
dbForge Index Manager – praktisk SSMS-tilføjelse til at analysere status for SQL-indekser og løse problemer med indeksfragmentering.