I databaseprogrammering er der fire grundlæggende handlinger:opret , læs , opdatering , og slet – CRUD operationer. De er det første trin i databaseprogrammering.
Udtrykket CRUD dukkede første gang op i James Martins bog 'Managing the Database Environment.' Siden da er dette udtryk blevet populært. I denne artikel skal vi udforske CRUD-operationen i form af SQL Server, fordi operationssyntaksen kan afvige fra andre relationelle og NoSQL-databaser.
Forberedelser
Hovedideen med relationelle databaser er lagring af data i tabeller. Tabeldataene kan læses, indsættes, slettes. På denne måde manipulerer CRUD-operationer tabeldataene.
| C | C REATE | Indsæt række/rækker i en tabel |
| R | R EAD | Læs (vælg) række/rækker fra en tabel |
| U | U PDATE | Rediger række/rækker i tabellen |
| D | D ELETE | Slet række/rækker fra tabellen |
For at illustrere CRUD-operationerne har vi brug for en datatabel. Lad os skabe en. Den vil kun indeholde tre kolonner. Den første kolonne vil gemme landenavne, den anden vil gemme disse landes kontinent, og den sidste kolonne vil gemme befolkningen i disse lande. Vi kan oprette denne tabel ved hjælp af T-SQL-sætningen og give den navnet TblCountry .
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
Lad os nu gennemgå CRUD-operationerne udført på TblCountry tabel.
C – OPRET
For at tilføje nye rækker til en tabel bruger vi INSERT INTO kommando. I denne kommando skal vi angive navnet på måltabellen og vil angive kolonnenavnene i parentes. Udsagnsstrukturen skal slutte med VALUES:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES ('Germany','Europe',8279000 )
For at tilføje flere rækker til tabellen kan vi bruge følgende type INSERT-sætning:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Bemærk, at INTO søgeord er valgfrit, og du behøver ikke bruge det i indsæt-sætningerne.
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Du kan også bruge følgende format til at indsætte flere rækker i tabellen:
INSERT INTO TblCountry
SELECT 'Germany','Europe',8279000
UNION ALL
SELECT 'Japan','Asia',126800000
UNION ALL
SELECT 'Moroco','Africa',35740000
Nu kopierer vi data direkte fra kildetabellen til destinationstabellen. Denne metode er kendt som INSERT INTO … SELECT erklæring.
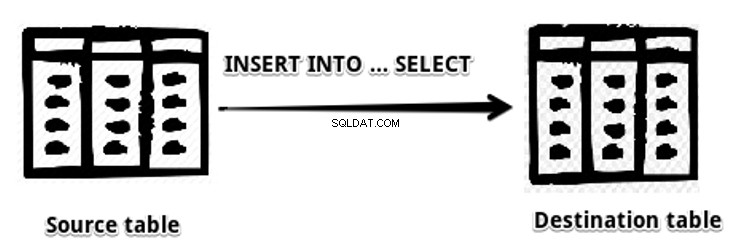
INSERT INTO … SELECT kræver, at datatyperne for kilde- og destinationstabellerne matches. I den følgende INSERT INTO … SELECT-sætning indsætter vi dataene for SourceCountryTbl tabellen i TblCountry tabel.
Først indsætter vi nogle syntetiske data i SourceCountryTbl tabel for denne demonstration.
DROP TABLE IF EXISTS [SourceCountryTbl]
CREATE TABLE [dbo].[SourceCountryTbl]
(
[SourceCountryName] VARCHAR(50),
[SourceContinentNames] VARCHAR(50) NULL,
[SourceCountryPopulation] BIGINT NULL
)
INSERT INTO [SourceCountryTbl]
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
Nu vil vi udføre INSERT INTO … SELECT-sætningen.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl
Ovenstående indsæt-sætning tilføjede alle SourceCountryTbl data til TblCountry bord. Vi kan også tilføje Hvor klausul for at filtrere select-sætningen.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl WHERE TargetCountryName='UK'
SQL Server giver os mulighed for at bruge tabelvariabler (objekter, der hjælper med at gemme midlertidige tabeldata i det lokale scope) med INSERT INTO … SELECT-sætningerne. I den følgende demonstration vil vi bruge tabelvariablen som en kildetabel:
DECLARE @SourceVarTable AS TABLE
([TargetCountryName] VARCHAR(50),
[TargetContinentNames] VARCHAR(50) NULL,
[TargetCountryPopulation] BIGINT NULL
)
INSERT INTO @SourceVarTable
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
INSERT INTO TblCountry
SELECT * FROM @SourceVarTable
Tip :Microsoft annoncerede en funktion i SQL Server 2016, som er parallel indsættelse . Denne funktion giver os mulighed for at udføre INSERT-operationer i parallelle tråde.
Hvis du tilføjer TABLOCK tip i slutningen af din insert-sætning, kan SQL Server vælge en parallel med behandlingsudførelsesplanen i henhold til din servers maksimale grad af parallelitet eller omkostningstærsklen for parallelitetsparametre.
Parallel insert-behandling vil også reducere udførelsestiden for insert-sætningen. Men TABLOCK hint får låsen på det indsatte bord under indsættelsesoperationen. For mere information om den parallelle indsats, kan du henvise til Real World Parallel INSERT...SELECT.
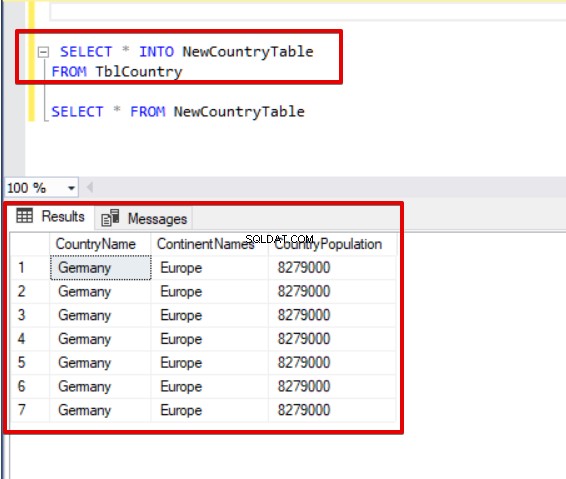
En anden praktisk sætning er SELECT INTO. Denne metode giver os mulighed for at kopiere data fra en tabel til en nyoprettet tabel. I den følgende erklæring, NewCountryTable eksisterede ikke før udførelsen af forespørgslen. Forespørgslen opretter tabellen og indsætter alle data fra TblCountry tabel.
SELECT * INTO NewCountryTable
FROM TblCountry
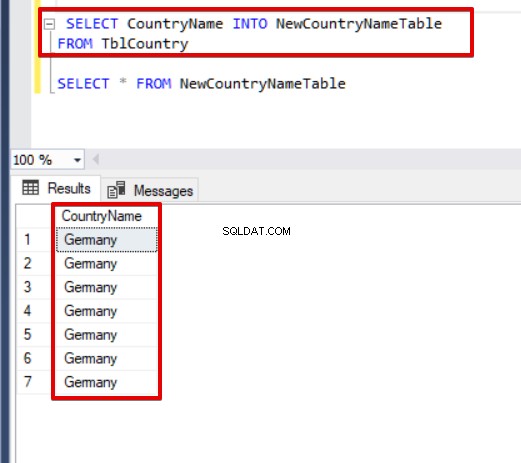
Samtidig kan vi oprette en ny tabel for bestemte kolonner i kildetabellen.
I nogle tilfælde skal vi returnere og bruge indsatte værdier fra INSERT-sætningen. Siden SQL Server 2005 giver INSERT-sætningen os mulighed for at hente de pågældende værdier fra INSERT-sætningen.
Nu vil vi slippe og oprette vores testtabel og tilføje en ny identitetskolonne. Vi tilføjer også en standardbegrænsning til denne kolonne. Derved, hvis vi ikke indsætter nogen eksplicit værdi i denne kolonne, vil den automatisk skabe en ny værdi.
I det følgende eksempel vil vi erklære en tabel med én kolonne og indsætte output fra SeqID kolonneværdi til denne tabel ved hjælp af OUTPUT-kolonnen:
DROP TABLE IF EXISTS TblCountry
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL ,
SeqID uniqueidentifier default(newid())
)
DECLARE @OutputID AS TABLE(LogID uniqueidentifier)
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
OUTPUT INSERTED.SeqId INTO @OutputID
VALUES
('Germany','Europe',8279000 )
SELECT * FROM @OutPutId
R – Læs
Læs operation henter data fra en tabel og returnerer et resultatsæt med tabellens poster. Hvis vi ønsker at hente data fra mere end én tabel, kan vi bruge JOIN-operatoren og skabe en logisk relation mellem tabeller.
SELECT-sætningen spiller en enkelt primær rolle i læsningen operation. Den er baseret på tre komponenter:
- Kolonne – vi definerer de kolonner, som vi ønsker at hente data fra
- Tabel – vi angiv den tabel, som vi ønsker at hente data fra
- Filtrer – vi kan filtrere de data, vi ønsker at læse. Denne del er valgfri.
Den enkleste form for select-sætningen er som følger:
SELECT column1, column2,...,columnN
FROM table_name
Nu vil vi gennemgå eksemplerne. I første omgang har vi brug for en prøvetabel at læse. Lad os skabe det:
DROP TABLE IF EXISTS TblCountry
GO
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
GO
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Læsning af alle kolonner i tabellen
Stjerne (*)-operatoren bruges i SELECT-sætningerne, fordi den returnerer alle kolonner i tabellen:
SELECT * FROM TblCountry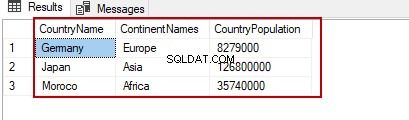
Tip :Stjernen (*)-operatøren kan påvirke ydeevnen negativt, fordi den forårsager mere netværkstrafik og bruger flere ressourcer. Hvis du ikke har brug for at få alle data fra alle kolonner returneret, skal du undgå at bruge stjernen (*) i SELECT-sætningen.
Læsning af bestemte kolonner i tabellen
Vi kan også læse særlige kolonner i tabellen. Lad os gennemgå eksemplet, der kun returnerer CountryName og CountryPopulation kolonner:
SELECT CountryName,CountryPopulation FROM TblCountry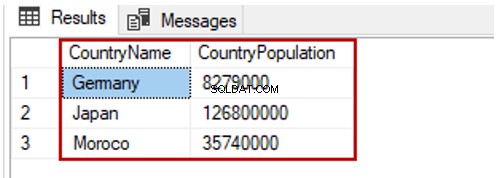
Brug af alias i SELECT-sætningerne
I SELECT-sætningerne kan vi give midlertidige navne til tabellen eller kolonnerne. Disse midlertidige navne er aliaser. Lad os omskrive de to foregående forespørgsler med tabel- og kolonnealiasser.
I den følgende forespørgsel er TblC alias vil angive tabelnavnet:
SELECT TblC.* FROM TblCountry TblC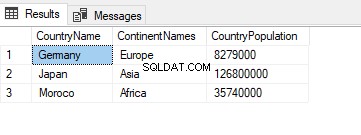
I det følgende eksempel vil vi give aliaser for kolonnenavnene. Vi ændrer CountryName til CName , og Landsbefolkning – til CPop .
SELECT TblC.CountryName AS [CName], CountryPopulation AS [CPop] FROM TblCountry TblC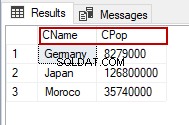
Formålet med aliaset er:
- Gør forespørgslen mere læsbar, hvis tabel- eller kolonnenavnene er komplekse.
- Sørg for at bruge en forespørgsel til tabellen mere end én gang.
- Forenkle skrivningen af forespørgsler, hvis tabellen eller kolonnenavnet er langt.
Filtrering af SELECT-udsagn
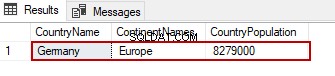
SELECT-sætninger giver os mulighed for at filtrere resultatsættene gennem WHERE-sætningen. For eksempel ønsker vi at filtrere SELECT-sætningen efter CountryName kolonne og returnerer kun data fra Tyskland til resultatsættet. Følgende forespørgsel udfører læseoperationen med et filter:
SELECT TblC.* FROM TblCountry TblC
WHERE TblC.CountryName='Germany'
Sortering af SELECT-udsagnsresultater
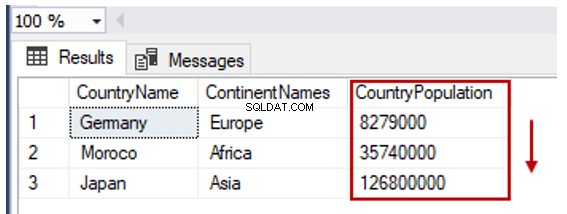
ORDER BY-sætningen hjælper os med at sortere resultatsættet af SELECT-sætningen efter den eller de specificerede kolonner. Vi kan udføre stigende eller faldende sortering ved hjælp af ORDER BY-klausulen.
Vi sorterer TblCountry tabel i henhold til landenes befolkning i stigende rækkefølge:
SELECT TblC.* FROM TblCountry TblC
ORDER BY TblC.CountryPopulation ASC
Tip :Du kan bruge kolonneindekset i ORDER BY-sætningen, og kolonneindeksnumre starter med 1.
Vi kan også skrive den forrige forespørgsel. Tallet tre (3) angiver Landets befolkning kolonne:
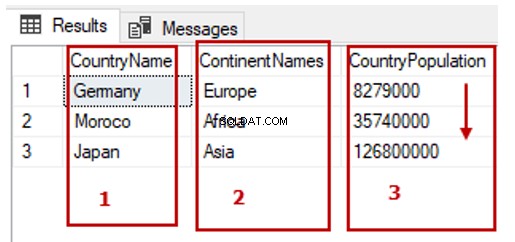
SELECT TblC.* FROM TblCountry TblC
ORDER BY 3 ASC
U – Opdatering
UPDATE-sætningen ændrer de eksisterende data i tabellen. Denne sætning skal indeholde SET-sætningen, så vi kan definere målkolonnen for at ændre dataene.
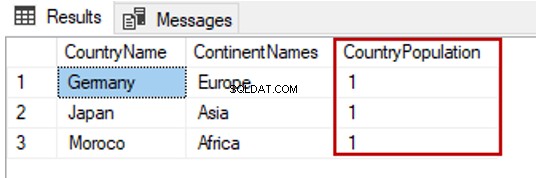
Følgende forespørgsel vil ændre alle rækker i Landbefolkningen kolonneværdi til 1.
UPDATE TblCountry SET CountryPopulation=1
GO
SELECT TblC.* FROM TblCountry TblC
I UPDATE-sætningerne kan vi bruge WHERE-sætningen til at ændre en bestemt række eller rækker i tabellen.
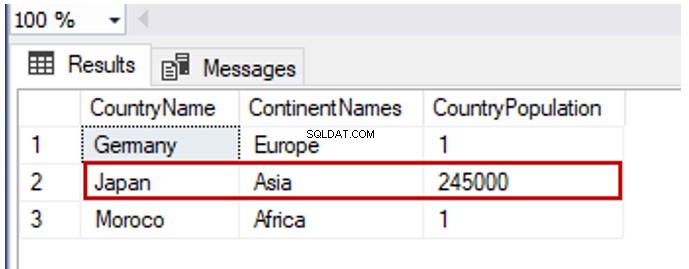
Lad os ændre Japan række af Landbefolkning til 245.000:
UPDATE TblCountry SET CountryPopulation=245000
WHERE CountryName = 'Japan'
GO
SELECT TblC.* FROM TblCountry TblC
UPDATE-sætningen er en forening af delete- og insert-sætningerne. Så vi kan returnere de indsatte og slettede værdier gennem OUTPUT-sætningen.
Lad os lave et eksempel:
UPDATE TblCountry SET CountryPopulation=22
OUTPUT inserted.CountryPopulation AS [Insertedvalue],
deleted.CountryPopulation AS [Deletedvalue]
WHERE CountryName = 'Germany'
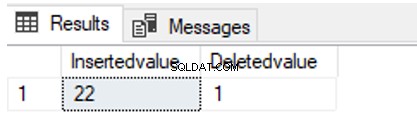
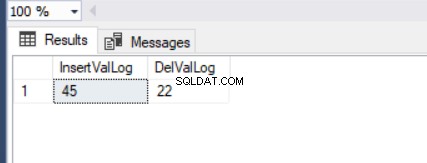
Som du kan se, har vi ændret CountryPopulation værdi fra 1 til 22. Så kan vi finde ud af de indsatte og slettede værdier. Derudover kan vi indsætte disse værdier i en tabelvariabel (en speciel variabeltype, der kan bruges som tabel).
Vi skal indsætte de indsatte og slettede værdier i tabelvariablen:
DECLARE @LogTable TABLE(InsertValLog INT , DelValLog INT)
UPDATE TblCountry SET CountryPopulation=45
OUTPUT inserted.CountryPopulation ,
deleted.CountryPopulation INTO @LogTable
WHERE CountryName = 'Germany'
SELECT * FROM @LogTable
@@ROWCOUNT er en systemvariabel, der returnerer antallet af berørte rækker i den sidste sætning. Således kan vi bruge denne variabel til at afsløre nogle ændrede rækker i opdateringssætningen.
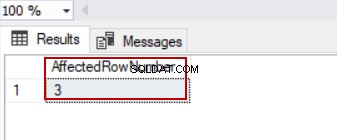
I det følgende eksempel vil opdateringsforespørgslen ændre 3 rækker, og @@ROWCOUNT systemvariablen returnerer 3.
UPDATE TblCountry SET CountryPopulation=1
SELECT @@ROWCOUNT AS [AffectedRowNumber]
D – Slet
Slet-sætningen fjerner eksisterende række/rækker fra tabellen.
Lad os først se, hvordan man bruger WHERE-sætningen i DELETE-sætningerne. Det meste af tiden ønsker vi at filtrere slettede rækker.
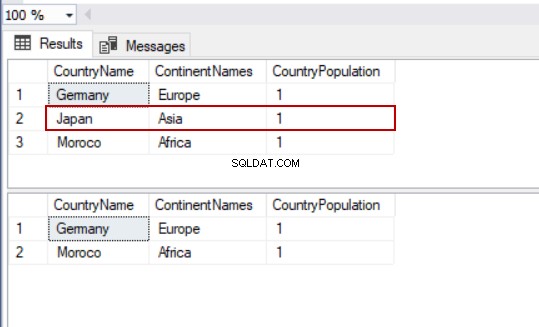
Nedenstående eksempel illustrerer, hvordan man fjerner en bestemt række:
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry WHERE CountryName='Japan'
SELECT TblC.* FROM TblCountry TblC
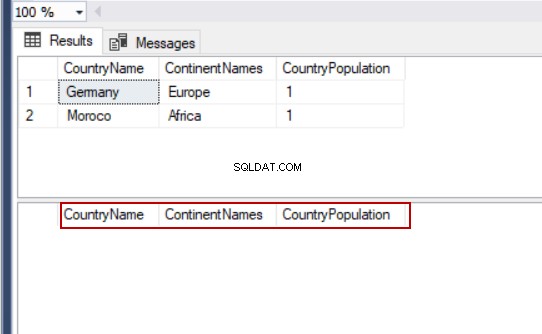
Selvom vi med DELETE-sætningen kan fjerne alle poster fra tabellen. DELETE-sætningen er dog meget grundlæggende, og vi bruger ikke WHERE-betingelsen.
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry
SELECT TblC.* FROM TblCountry TblC
Alligevel sletter DELETE-sætningen under visse omstændigheder i databasedesignet ikke rækken/rækkerne, hvis den overtræder fremmednøgler eller andre begrænsninger.
For eksempel i AdventureWorks database, kan vi ikke slette rækker i Produktkategorien tabel fordi ProductCategoryID er angivet som en fremmednøgle i den tabel.
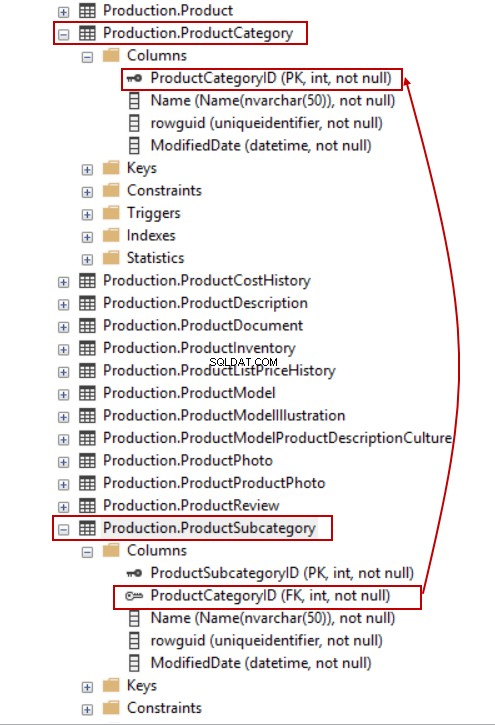
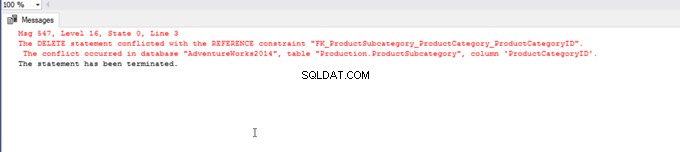
Lad os prøve at slette en række fra ProductCategory tabel – uden tvivl vil vi stå over for følgende fejl:
DELETE FROM [Production].[ProductCategory]
WHERE ProductCategoryID=1
Konklusion
Derfor har vi udforsket CRUD-operationerne i SQL. INSERT-, SELECT-, UPDATE- og DELETE-sætningerne er de grundlæggende funktioner i SQL-databasen, og du skal mestre dem, hvis du vil lære SQL-databaseprogrammering. CRUD-teorien kunne være et godt udgangspunkt, og en masse øvelse vil hjælpe dig med at blive ekspert.