Dette er den anden del af materialet dedikeret til SQL Server Semantic Search . I den forrige artikel udforskede vi det grundlæggende. Nu vil vi fokusere på at sammenligne dokumenter gemt på Windows filsystem og den sammenlignende analyse med Semantisk søgning i SQL Server.
Udførelse af navnebaserede dokumenter sammenlignende analyse
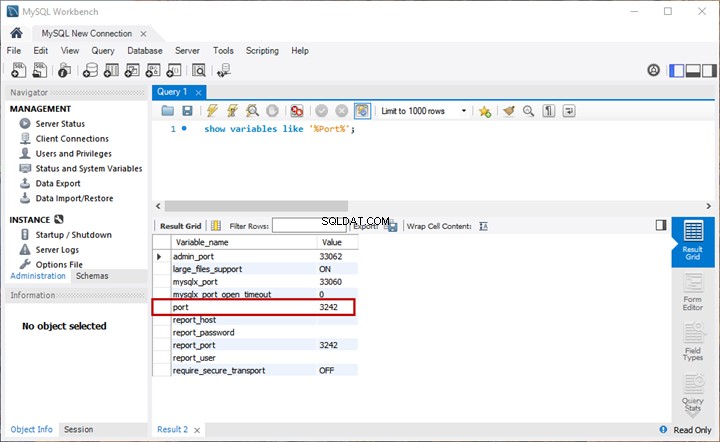
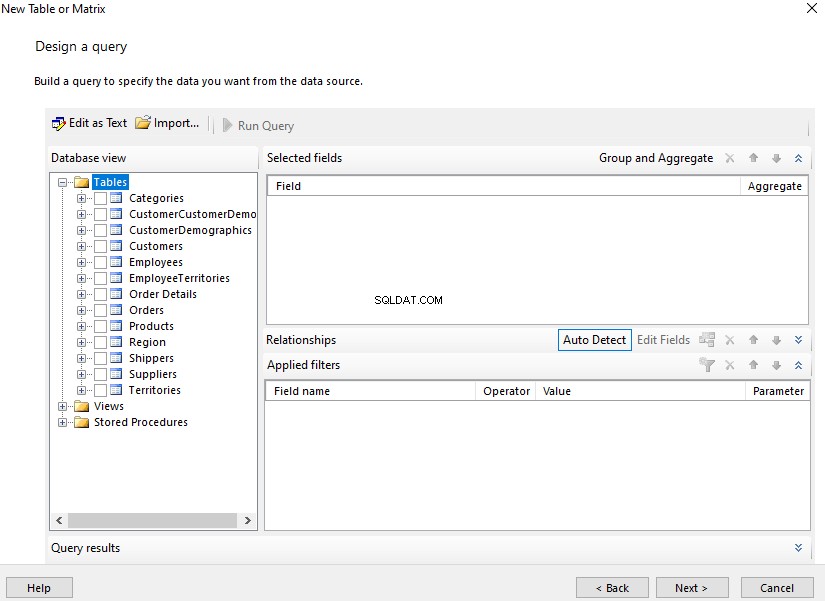
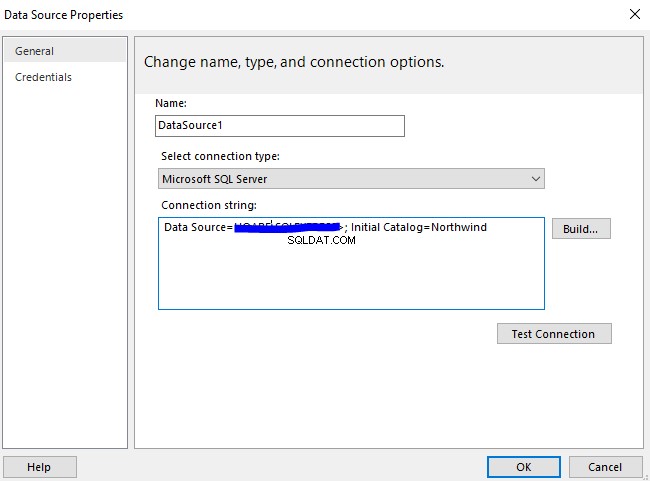
Vi skal udføre en sammenlignende analyse af dokumenter baseret på deres standardnavngivning. Lad os på dette tidspunkt foretage en hurtig kontrol ved at forespørge på EmployeesFilestreamSample database, vi har oprettet tidligere:
-- Se lagrede dokumenter administreret af File Table for at kontrollereSELECT stream_id ,[name] ,file_type ,creation_timeFROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore Resultaterne skal vise os gemte dokumenter:
Semantisk søgetjekliste
Vi har allerede databasen og to eksempler på MS Word-dokumenter på filsystemet ved hjælp af File Table (du kan eventuelt henvise til del 1 for at opdatere viden, hvis det er nødvendigt). Men det ikke automatisk kvalificere vores dokumenter til scenariet Semantisk søgning.
Semantisk søgning kan aktiveres på en af følgende måder:
- Hvis du allerede har konfigureret Fuld tekstsøgning , kan du aktivere Semantisk søgning i et enkelt trin.
- Du kan konfigurere den semantiske søgning direkte, men før du også skal konfigurere fuldtekstsøgningen.
Fuldtekstsøgningstest før opsætning af semantisk søgning
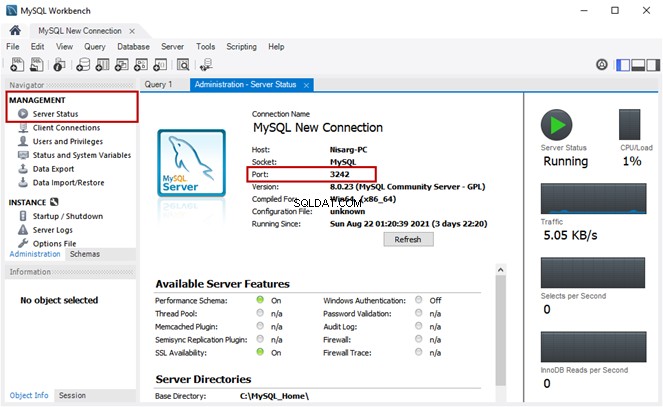
Hvis en fuldtekstforespørgsel virker, behøver vi kun at aktivere Semantisk søgning. For at kontrollere det, kør en fuldtekst-forespørgsel mod den ønskede tabel:
-- Søger efter ord Medarbejder ved hjælp af fuldtekstsøgning mod EmployeesDocumentStore-filtabelVÆLG [navn] FRA [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(navn,'Medarbejder') Udgangen:
Derfor skal vi først opfylde kravene til fuld tekstsøgning og derefter aktivere semantisk søgning.
Aktivering af semantisk søgning til brug
Mindst to af følgende punkter er nødvendige for at bruge semantisk søgning:
- Unikt indeks
- Et fuldtekstkatalog
- Et fuldtekstindeks
Udfør følgende T-SQL-script for at oprette et unikt indeks:
-- Opret unikt indeks påkrævet til semantisk søgning OPRET UNIK INDEX UQ_Stream_Id ON EmployeesDocumentStore(stream_id) GO Opret et fuldtekstkatalog baseret på det nyoprettede unikke indeks. Og opret derefter et fuldtekstindeks som vist nedenfor:
- At få semantisk søgning klar til at blive brugt med filtablecreate fuldtekstkatalog Medarbejderefiletablecatalog med Accent_Sensitivity =ON; Opret fuldtekst indeks på medarbejdereDocumentStore (navnesprog 1033 statistic KEY INDEX UQ_Stream_IdON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM; Resultaterne:
Fuldtekstsøgningstest efter opsætning af semantisk søgning
Lad os køre den samme fuldtekstforespørgsel for at søge efter ordet medarbejder i de gemte dokumenter:
-- Søger (efter Semantisk søgning opsætning) ord Medarbejder ved hjælp af fuldtekstsøgning mod EmployeesDocumentStore File TableSELECT [navn] FRA [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(navn,'Medarbejder') Udgangen:
Det er fint, at fuldtekstforespørgsler arbejder mod filtabellen, mens vi gør den klar til semantisk søgning.
Tilføj flere MS Word-dokumenter
Vi går til EmployeesDocumentStore Filtabel, og klik på Udforsk FileTable Directory :
Opret og gem et nyt dokument kaldet Sadaf Contract Employee :
Tilføj derefter følgende tekst til det nyoprettede dokument. Den første linje skal være titlen på dokumentet!
Sadaf kontraktansat (titel)
Sadaf er en meget effektiv forretningsanalytiker, der udfører kontaktbaseret arbejde. Hun er fuldt ud i stand til at håndtere forretningskrav og omdanne dem til tekniske specifikationer, som udviklerne kan arbejde videre med. Hun er en meget erfaren forretningsanalytiker.
Tilføj et andet dokument kaldet Mike Permanent Employee :
Opdater dokumentet med følgende tekst:
Mike Permanent Employee (Titel på dokumentet)
Mike er en frisk programmør, hvis ekspertise omfatter webudvikling. Han er en hurtig lærende og glad for at arbejde på ethvert projekt. Han har stærke problemløsningsevner, men han har mindre forretningskendskab. Han kræver assistance fra andre udviklere eller forretningsanalytikere for at forstå problemet og opfylde kravene.
Han er god, når han arbejder på små projekter, men han kæmper, hvis han får et stort eller komplekst projekt.
Vi har fire dokumenter gemt på Windows-filsystemet, der administreres af File Table. Disse dokumenter bør bruges af semantisk søgning (inklusive fuldtekstsøgning).
Vigtigt:Selvom vi lige har gemt fire MS Word-dokumenter i mappen som et eksempel, kan du forestille dig vigtigheden af at bruge Semantisk søgning, når hundredvis af sådanne dokumenter vedligeholdes af en SQL Server-database, og du skal forespørge på disse dokumenter for at finde værdifuld information.
Standardnavngivningen af dokumenter betyder meget for en vellykket implementering af denne tilgang.
Simpel optælling af dokumenter
Vi kan sammenligne disse dokumenter og definere forskellene og lighederne baseret på deres standardnavngivning ved hjælp af Semantisk søgning. For eksempel kan en simpel forespørgsel fortælle os det samlede antal dokumenter, der er gemt i Windows-mappen:
-- Henter det samlede antal gemte dokumenter VÆLG COUNT(*) AS Total_Documents FROM EmployeesDocumentStore 
Sammenligning af faste og kontraktbaserede medarbejdere
Denne gang bruger vi Semantisk søgning til at sammenligne antallet af fastansatte og kontraktbaserede medarbejdere i vores organisation:
-- Oprettelse af en oversigtstabelvariabelDECLARE @Documents TABLE(DocumentType VARCHAR(100),DocumentsCount INT)INSERT INTO @Documents -- Lagring af det samlede antal lagrede dokumenter i oversigtstabelSELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStoreINSERT INTO @Documents -- Lagring af det samlede antal fastansatte dokumenter gemt i oversigtstabelVÆLG 'Total Permanent Employees',COUNT(*) FROM semantikkeyphrasetable (EmployeesDocumentStore, *)WHERE keyphrase @'PermanentINSERTenttor' samlet antal fastansatte dokumenter gemt VÆLG 'Total Contract Employees',COUNT(*) FROM semantikkeyphrasetable (EmployeesDocumentStore, *)WHERE keyphrase ='Kontrakt'SELECT DocumentType,DocumentsCount FROM @Documents Udgangen:
Lad os køre en simpel (dokumentnavn-baseret) semantisk søgning for at se søgesætningen og dens relative score for hvert dokument:
-- Hent nøglesætning og relativ score for alle dokumenter.VÆLG * FRA semantisk nøglesætning, der kan indstilles (EmployeesDocumentStore, NAME) ORDER BY score Udgangen:
Lad os tilføje flere detaljer til dokumentnavnene. Vi omdøber dem som følger:
- Asif fastansat – erfaren projektleder
- Mike Permanent Employee – Frisk programmør
- Peter fastansat – Frisk projektleder
- Sadaf kontraktansat – erfaren forretningsanalytiker
Sådan finder du nye medarbejdere (dokumenter)
Find dokumenterne relateret til nye medarbejdere baseret på deres titler (standardnavn):
-- Få dokumentnavn-baseret scoring for at finde nye medarbejdere til et nyt projektSELECT (VÆLG navn fra EmployeesDocumentStore hvor path_locator=document_key) som DocumentName,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) hvor keyphrase='fresh 'bestil efter DocumentName desc Resultaterne:
Sådan finder du erfarne medarbejdere (dokumenter)
Antag, at vi hurtigt vil gennemgå alle detaljer om erfarne medarbejdere til det komplekse projekt, der venter. Brug følgende semantiske søgeforespørgsel:
-- Får dokumentnavn-baseret scoring for at finde alle erfarne medarbejdereSELECT (VÆLG navn fra EmployeesDocumentStore hvor path_locator=document_key) som DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) hvor keyphrase='oplevet' rækkefølge efter Dokumentnavn Udgangen:
Sådan finder du alle projektledere (dokumenter)
Til sidst, hvis vi hurtigt vil gennemgå dokumenterne for alle projektledere, har vi brug for følgende semantiske søgeforespørgsel:
-- Får dokumentnavn-baseret scoring for at finde alle projektledereSELECT (VÆLG navn fra EmployeesDocumentStore hvor path_locator=document_key) som DocumentName ,keyphrase,score FRA semantickkeyphrasetable(EmployeesDocumentStore, NAME)where keyphrase='Project' Resultaterne:
Efter implementering af gennemgangen kan du med succes gemme ustrukturerede data, såsom MS Word-dokumenter, i en Windows-mappe ved hjælp af File Table.
Navnebaseret analysegennemgang
Indtil videre har vi lært, hvordan man udfører en navnebaseret analyse af dokumenter gemt i en filtabel ved hjælp af semantisk søgning. Vi skal dog have følgende betingelser opfyldt:
- Standardnavngivning skal være på plads.
- Navne skal give de nødvendige oplysninger til analyse.
Disse forhold er også begrænsninger for den navnebaserede analyse. Men det betyder ikke, at vi ikke kan gøre meget ved det.
Vores fokus er fortsat på den navn/kolonne-baserede tilgang til semantisk søgning.
Se navnekolonnerne for dokumenterne
Lad os se nogle af hovedkolonnerne i tabellen Dokumenter inklusive navnet kolonne:
BRUG EmployeesFilestreamSample-- Se navnekolonnen med filtyperne for de lagrede dokumenter i Filtabel til analyseVÆLG navn,filtype FRA dbo.EmployeesDocumentStore Udgangen:
Forstå funktionen SEMANTICKEYPHRASETABLE
SQL Server tilbyder SEMANTICKEYPHRASETABLE funktion til at analysere dokumentet med semantisk søgning. Syntaksen er som følger:
SEMANTICKEYPHRASETABLE ( tabel, { column | (column_list) | * } [ , source_key ] ) Denne funktion giver os nøglesætninger forbundet med dokumentet. Vi kan bruge dem til at analysere dokumenter baseret på deres navne eller indhold. I vores tilfælde skal vi ikke kun bruge denne funktion, men også forstå, hvordan vi bruger den korrekt.
Funktionen kræver følgende data:
- Navnet på den filtabell, der skal bruges til analyse af semantisk søgning.
- Navnet på den kolonne, der skal bruges til analyse af semantisk søgning.
Derefter returnerer den følgende data:
- Kolonne_id – kolonnenummeret
- Dokumentnøgle – den primære standardnøgle til File Table-dokumentet
- Søgesætning – er en sætning, som Semantisk søgning beslutter at indeksere til analyse. Det gælder både for dokumentets navn og indhold alt efter hvilken kolonne vi ønsker at se nøglesætningerne for
- Score – bestemmer styrken af en nøglesætning, der er knyttet til et dokument, såsom hvordan et dokument bedst genkendes af dets nøglesætning. Scoren kan være mellem 0,0 og 1,0.
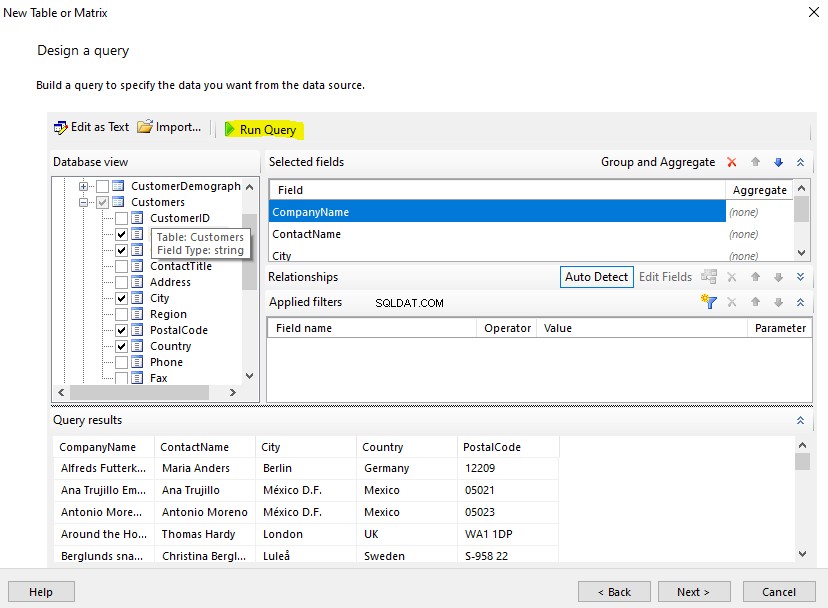
Analyse af alle dokumenter ved hjælp af SEMANTICKEYPHRASETABLE-funktionen
Vi bruger SEMANTICKEYPHRASETABLE funktion til den navnebaserede analyse af de dokumenter, der er gemt i Windows-mappen, der administreres af filtabellen.
Udfør følgende T-SQL-script:
BRUG EmployeesFilestreamSample-- Se nøglesætninger og deres score for navnekolonnenVÆLG * FRA SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)order by score desc Udgangen:
Vi har en liste over alle nøglesætninger knyttet til alle dokumenter og deres score. column_id 3 i den øverste række er navnet kolonne. Derudover kaldte vi også funktionen ved at angive denne kolonne (navn):
Du kan finde dokumentnøglen : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 kører følgende script (selvom det er klart, at dette dokument er det, hvor navnet indeholder nøglesætningen sadaf ):
BRUG EmployeesFilestreamSample-- Finder dokumentnavnet ved dets nøgle (path_locator)SELECT name,path_locator FRA dbo.EmployeesDocumentStoreWHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C80163F202code
Udgangen:
nøglesætningen sadaf har fået den bedste score :1.0 .
I tilfældet med standarddokumentnavngivningen med tilstrækkelig information til den semantiske søgningsanalyse er vores nøglesætning sadaf er det bedste match for det pågældende dokumentnavn.
Analyse af specifikt dokument ved hjælp af SEMANTICKEYPHRASETABLE-funktionen
Vi kan indsnævre vores semantiske søgningsanalyse baseret på navnet kolonne. For eksempel behøver vi kun at se navnkolonnen- baseret nøglesætninger i et bestemt dokument. Vi kan angive dokumentnøglen i SEMANTICKEYPHRASETABLE Funktion.
Først identificerer vi dokumentnøglen for det dokument, hvor vi ønsker at se alle nøglesætninger. Kør følgende T-SQL-script:
-- Find dokumentnøgle for dokumentet, hvor navnet indeholder PeterSELECT-navn, sti_locator som dokumentnøgle Fra EmployeesDocumentStoreWHERE navn som '%Peter%' Dokumentnøglen er 0xFF6A92952500812FF013376870181CFA6D7C070220
Lad os nu se dette dokument vedrørende alle nøglesætninger, der kan definere dokumentnavnet:
-- Se alle nøglesætningerne og deres score for et dokument relateret til Peter permanent medarbejderSELECT column_id,name,keyphrase,score FRA SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA0Nøgle_6701700INCu20d20100000000000000002 score desc Resultaterne:
Nøglesætningen medarbejder får den højeste score i dette dokument. Vi kan se, at alle ord i kolonnen er nøglesætninger, der bestemmer dokumentets betydning.
Forstå funktionen SEMANTICSIMILARITYTABLE
Denne funktion hjælper os med at sammenligne ét dokument med alle andre dokumenter baseret på nøglesætninger. Syntaksen for denne funktion er som følger:
SEMANTISK LIGNENDE TABEL ( tabel, { kolonne | (kolonne_liste) | * }, kildenøgle ) Det kræver navnet på tabellen, kolonnen og dokumentnøglen for at matche andre dokumenter. For eksempel kan vi sige, at to dokumenter ligner hinanden, hvis de har en god score for søgesætninger.
Sammenligning af dokumenter ved hjælp af SEMANTICSIMILARITYTABLE-funktionen
Lad os sammenligne et dokument med andre dokumenter ved hjælp af SEMANTICSIMILARITYTABLE Funktion.
Sammenligning af alle projektlederes dokumenter
Vi skal se alle dokumenter relateret til projektledere. Fra ovenstående eksempler ved vi, at dokumentnøglen for det angivne dokument er 0xFF6A92952500812FF013376870181CFA6D7C070220 . Derfor kan vi bruge denne nøgle til at finde andre matches inklusive projektledere:
meget .path_locator=SST.matched_document_keyorder by score descUdgangen:
Det mest nært beslægtede dokument er Asif Permanent Employee – Erfaren projektleder.docx . Det giver mening, da begge medarbejdere er fastansatte, og begge er projektledere.
Sammenligning af erfarne forretningsanalytikers dokumenter
Nu skal vi sammenligne dokumenterne relateret til erfaren forretningsanalytiker s og find det nærmeste match ved hjælp af Semantisk søgning. Vi er begrænset til den dokumentnavn-baserede analyse:
BRUG EmployeesFilestreamSample-- Finder dokumentnøgle til erfarne forretningsanalytiker, vælg navn, sti_locator som dokumentnøgle fra EmployeesDocumentStorewhere-navn som '%erfaren forretningsanalytiker%'-- Se alle dokumenter, der er tæt relateret til erfaren forretningsanalytikerSELECT SST.source_column_id,SST. matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SSTINNER JOIN JOIN dbo.ElocedStore Udgangen:
Som vi kan se fra resultaterne ovenfor, var det tætteste match for dokumentet relateret til den erfarne forretningsanalytiker er dokumentet for den erfarne projektleder fordi de begge er erfarne . Ikke desto mindre indikerer scoren på 0,3, at der ikke er meget til fælles mellem disse to dokumenter.
Konklusion
Tillykke! Vi har med succes lært, hvordan man gemmer dokumenter i Windows-mapper og analyserer dem ved hjælp af semantisk søgning. Vi undersøgte også de funktioner, der skal bruges i praksis. Nu kan du anvende den nye viden og prøve følgende øvelser til
Følg med for yderligere materialer!