Jeg har en 50 % løsning til dig.
Problemet
SSIS virkelig bekymrer sig om metadata, så variationer i dem har en tendens til at resultere i undtagelser. DTS var langt mere tilgivende i denne forstand. Det store behov for konsistente metadata gør brugen af den flade filkilde besværlig.
Forespørgselsbaseret løsning
Hvis problemet er komponenten, lad os ikke bruge den. Det, jeg godt kan lide ved denne tilgang, er, at det konceptuelt er det samme som at forespørge i en tabel - rækkefølgen af kolonner betyder ikke noget, og tilstedeværelsen af ekstra kolonner betyder ikke noget.
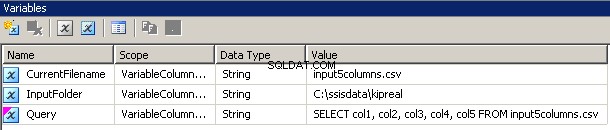
Variabler
Jeg oprettede 3 variabler, alle af typen streng:CurrentFileName, InputFolder og Query.
- InputFolder er fast forbundet til kildemappen. I mit eksempel er det
C:\ssisdata\Kipreal - CurrentFileName er navnet på en fil. Under designtiden var det
input5columns.csvmen det vil ændre sig under kørslen. - Forespørgsel er et udtryk
"SELECT col1, col2, col3, col4, col5 FROM " + @[Bruger::CurrentFilename]
Forbindelsesadministrator
Opsæt en forbindelse til inputfilen ved hjælp af JET OLEDB-driveren. Efter at have oprettet det som beskrevet i den linkede artikel, omdøbte jeg det til FileOLEDB og indstillede et udtryk på ConnectionManager for "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB. 4.0;Udvidede egenskaber=\"tekst;HDR=Ja;FMT=CSVDebegrænset;\";"
Kontrol flow
Mit kontrolflow ligner en dataflowopgave indlejret i en Foreach-filtæller
Foreach File Enumerator
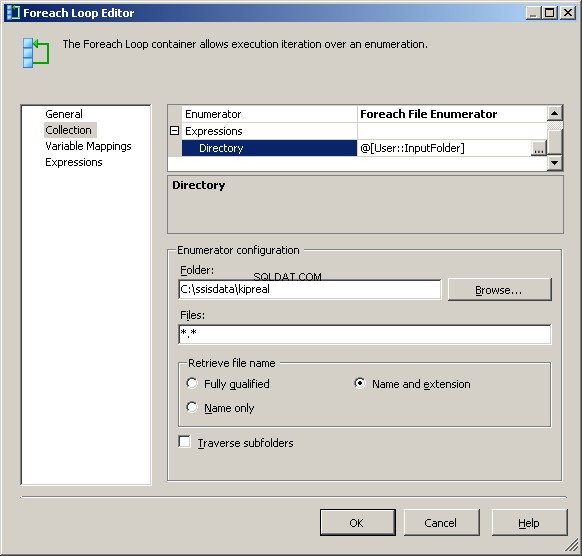
My Foreach File Enumerator er konfigureret til at fungere på filer. Jeg sætter et udtryk på mappen for @[Bruger::InputFolder] Bemærk, at på dette tidspunkt, hvis værdien af denne mappe skal ændres, vil den blive opdateret korrekt i både forbindelseshåndteringen og filtælleren. I "Hent filnavn" skal du i stedet for standardindstillingen "Fuldt kvalificeret" vælge "Navn og udvidelse"
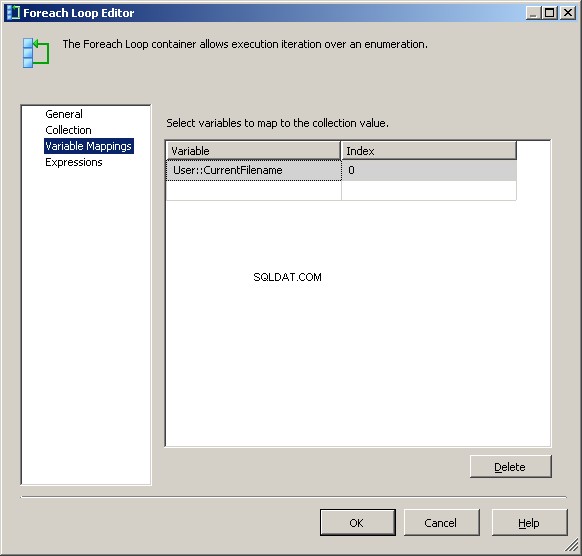
På fanen Variable Mappings skal du tildele værdien til vores @[User::CurrentFileName] variabel
På dette tidspunkt vil hver iteration af løkken ændre værdien af @[User::Query for at afspejle det aktuelle filnavn.
Dataflow
Dette er faktisk det nemmeste stykke. Brug en OLE DB-kilde, og tilslut den som angivet.
Brug FileOLEDB-forbindelseshåndteringen og skift dataadgangstilstanden til "SQL-kommando fra variabel." Brug @[User::Query] variabel derinde, klik på OK, og du er klar til at arbejde. 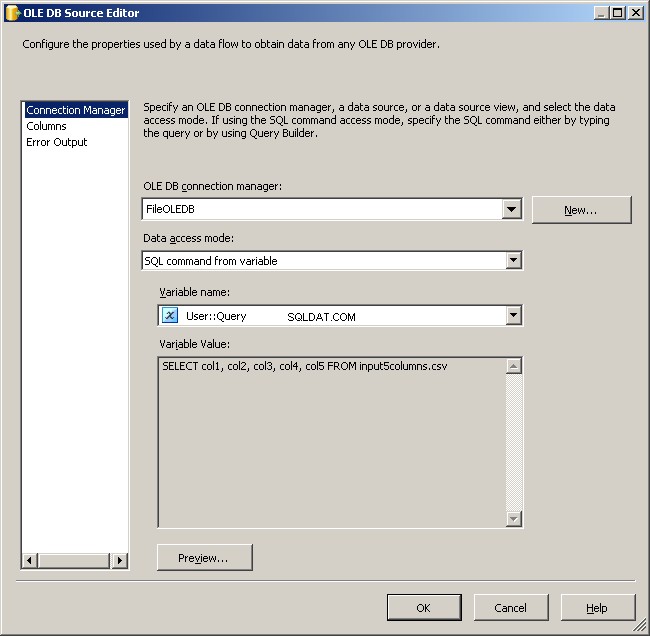
Eksempel på data
Jeg oprettede to eksempelfiler input5columns.csv og input7columns.csv Alle kolonnerne af 5 er i 7, men 7 har dem i en anden rækkefølge (col2 er ordensposition 2 og 6). Jeg negerede alle værdierne i 7 for at gøre det klart, hvilken fil der bliver opereret på.
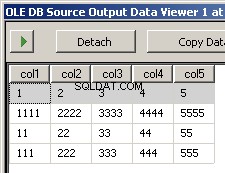
col1,col3,col2,col5,col41,3,2,5,41111,3333,2222,5555,444411,33,22,55,44111,333,222,555,444 og
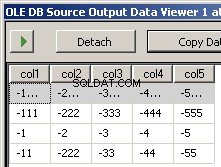
col1,col3,col7,col5,col4,col6,col2-1111,-3333,-7777,-5555,-4444,-6666,-2222-111,-333,-777,-555 ,-444,-666,-222-1,-3,-7,-5,-4,-6,-2-11,-33,-77,-55,-44,-666,-222
Kørsel af pakken resulterer i disse to skærmbilleder
Hvad mangler
Jeg kender ikke en måde at fortælle den forespørgselsbaserede tilgang, at det er OK, hvis en kolonne ikke eksisterer. Hvis der er en unik nøgle, formoder jeg, at du kan definere din forespørgsel til kun at have de kolonner, der skal være der og derefter udføre opslag mod filen for at prøve at få de kolonner, der burde at være der og ikke fejle opslaget, hvis kolonnen ikke eksisterer. Temmelig kludgey dog.