Databasereplikering er teknologien til at distribuere data fra den primære server til sekundære servere. Replikering fungerer på Master-slave-konceptet, hvor Master-databasen distribuerer data til en eller flere slaveservere. Replikering kan konfigureres mellem flere SQL Server-instanser på den samme server, ELLER den kan konfigureres mellem flere databaseservere i samme eller geografisk adskilte datacentre.
Der er to hovedfordele ved at bruge SQL Server-replikering:
- Ved brug af replikering kan vi få næsten realtidsdata, som kan bruges til rapporteringsformål. Når du f.eks. vil adskille den skriveintensive OLTP-belastning på én server og læseintensiv belastning på en anden server, kan du konfigurere replikering for at holde data synkroniseret på begge servere.
- Den anden fordel er, at du kan planlægge replikeringen til at køre på et bestemt tidspunkt. Hvis du f.eks. ønsker, at rapportserveren skal indeholde data for fuldført dag, kan du planlægge replikeringsøjebliksbilledet i overensstemmelse hermed. Vi behøver ikke at skrive yderligere logik for at håndtere aktuelle data.
Replikering giver masser af fleksibilitet. Ved hjælp af replikering kan vi filtrere rækkerne ud, og vi kan også replikere delmængden af data i enhver tabel. Vi kan ændre de replikerede data eller replikere kun opdatere og indsætte og ignorere sletningerne. Vi kan også replikere dataene fra et andet databasesystem som Oracle.
Replikationskomponenter
Der er syv kernekomponenter i SQL Server Replication. Følgende er listen:
- Udgiver.
- Distributør.
- Abonnent.
- Artikler.
- Publikation.
- Push-abonnement.
- Træk abonnement.
Følgende er detaljerne:
Artikler
En artikel er et databaseobjekt, såsom en SQL-tabel eller en lagret procedure. Som jeg nævnte ovenfor, kan vi ved hjælp af replikering filtrere data, eller vi kan replikere den valgte tabelkolonne, og derfor betragtes tabelkolonner eller rækker som artikler.
Publikation
Artikler kan ikke kopieres, før de bliver en del af publikationen. Udgivelse er gruppen af artikler/databaseobjekter. Det repræsenterer også det datasæt, der vil blive replikeret af SQL Server.
Udgiver
Publisher indeholder en masterdatabase, som har de data, der skal publiceres. Det bestemmer, hvilke data der skal distribueres på tværs af alle abonnenter.
Distributør
Distributøren er broen mellem udgiver og abonnent. Distributør samler alle de offentliggjorte data og opbevarer dem, indtil de sendes på tværs af alle abonnenter. Det er en bro mellem udgiver og abonnent. Det understøtter flere udgivere og abonnentkoncept. Det er ikke obligatorisk at konfigurere distributør på en separat SQL-instans eller en separat server. Hvis vi ikke konfigurerer det, kan udgiveren fungere som distributør. Organisationer, der har replikering i stor skala, kan konfigurere distributør på et separat system.
Abonnenter
Abonnenten er slutningen af kilden eller destinationen, hvortil data eller replikeret publikation vil blive transmitteret. I replikering er der én udgiver, den kan have flere abonnenter.
Push-abonnement
I et push-abonnement opdaterer udgiveren dataene til abonnenten. I et Push-abonnement er abonnenten passiv. Udgiveren sender artikler eller publikationer til alle sine abonnenter. Baseret på organisationens krav kan du i oprettelse af replikeringsguiden på skærmen vælge det abonnement, der skal bruges. Transaktionsreplikering og peer-to-peer-replikering bruger Push-abonnementet til at opretholde realtidstilgængeligheden af data.
Træk abonnement
I et Pull-abonnement anmoder alle abonnenter om de nye data eller opdaterede data fra sin udgiver. I et pull-abonnement kan vi kontrollere, hvilke data eller dataændringer, der er nødvendige for abonnenter. Det er nyttigt, når vi ikke har brug for de ændrede data med det samme.
Replikeringstyper
SQL Server understøtter tre replikeringstyper:
- Transaktionsreplikering.
- Snapshot-replikering.
- Flet replikering.
Transaktionel replikering
Transaktionel replikering, eventuelle skemaændringer, dataændringer, der forekommer på udgiverdatabasen, vil blive replikeret på abonnentdatabasen. Når der sker en opdatering, sletning eller indsæt i udgiverdatabasen, spores ændringerne, og disse ændringer sendes til abonnentdatabaserne. Transaktionel replikering sender kun en begrænset mængde data over et netværk. Desuden er ændringer næsten i realtid, så de kan bruges til at oprette DR-webstedet, eller det kan bruges til at udskalere rapporteringsoperationerne. Transaktionel replikering er ideel til følgende situationer:
- Når du vil konfigurere et system, hvor ændringer foretaget på udgiver skal anvendes på abonnenter med det samme.
- Udgiveren har høj lav INSERT, UPDATES og DELETES.
- Når du vil konfigurere heterogen replikeringsbetydning, udgiver eller abonnenter for ikke-SQL Server-databaser, såsom Oracle.
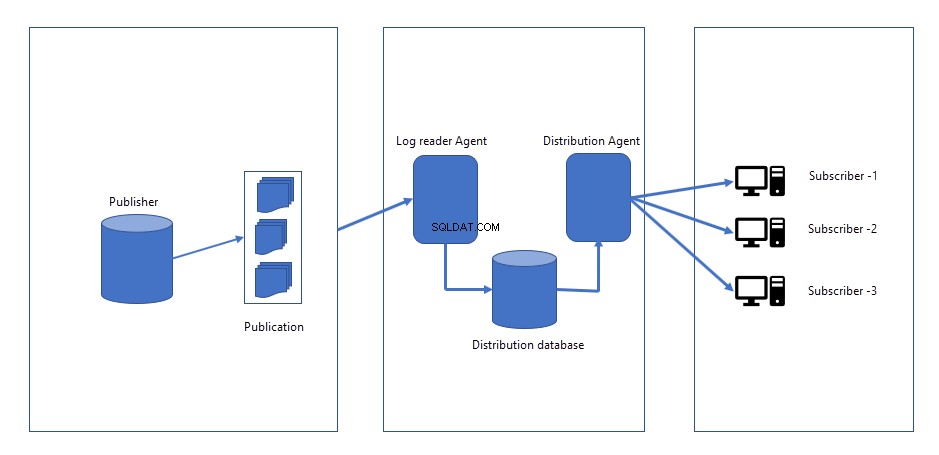
Når der foretages ændringer i udgiverdatabasen, logges ændringer i en logfil på udgiverdatabasen. Distributør-/udgiverwebsted, to job oprettes.
- Snapshot Agent :Snapshot agent job genererer snapshot af skema, data for de objekter, som vi ønsker at replikere eller publicere. Filer af snapshottet kan gemmes på Publisher-serveren eller netværksplaceringen. Når vi starter replikationen for første gang, opretter den et øjebliksbillede og anvender det på alle abonnenter. Snapshot-agenten forbliver inaktiv, indtil den udløses manuelt eller er planlagt til at køre på et bestemt tidspunkt.
- Loglæseragent :Loglæseragentjob kører kontinuerligt. Den læser ændringerne (INSERT, UPDATES og DELETES), der er sket fra udgiverdatabasens transaktionslog og sender dem til en distributionsagent.
- Distributionsagent :Når ændringer er hentet fra loglæseragenten, sender distributionsagenten alle ændringerne til abonnenterne.
Når vi konfigurerer transaktionsreplikering, udfører den følgende aktiviteter
- Det starter ved at tage det første øjebliksbillede af publikationsdata og databaseobjekter og øjebliksbillede anvendt på abonnenter.
- Loglæseragent overvåger løbende udgiverens T-log, og hvis der sker ændringer, sender den dem til distributøren eller direkte til abonnenter.
Følgende billede repræsenterer, hvordan transaktionsreplikering fungerer:
Fordele:
- Transaktionsreplikering kan bruges som en standby SQL-server, eller den kan bruges til belastningsbalancering eller adskillelse af rapporteringssystem og OLTP-system.
- Udgiverserver replikerer data til abonnentserver med lav forsinkelse.
- Ved brug af transaktionsreplikering kan replikering på objektniveau implementeres.
- Transaktionel replikering kan anvendes, når du har færre data at beskytte, og du bør have en hurtig datagendannelsesplan.
Ulempe:
- Når replikeringen er etableret, gælder skemaændringerne på udgiveren ikke på abonnentserveren. Vi skal foretage disse ændringer manuelt ved at generere et nyt øjebliksbillede og anvende det på abonnenter.
- Hvis vi ændrer serverne, skal vi omkonfigurere replikeringen.
- Hvis transaktionsreplikering bruges som en DR-opsætning, skal vi failover manuelt.
Snapshot-replikering
Snapshot-replikering genererer et komplet billede/snapshot af publikationen efter en defineret tidsplan og sender snapshot-filerne til abonnenter. Når snapshot-replikering forekommer, vil destinationsdata blive erstattet med et nyt snapshot. Snapshot-replikering er den bedste mulighed, når data er mindre flygtige. For eksempel er mastertabeller som City, Zipcode, Pincode bedste kandidater til snapshot-replikering.
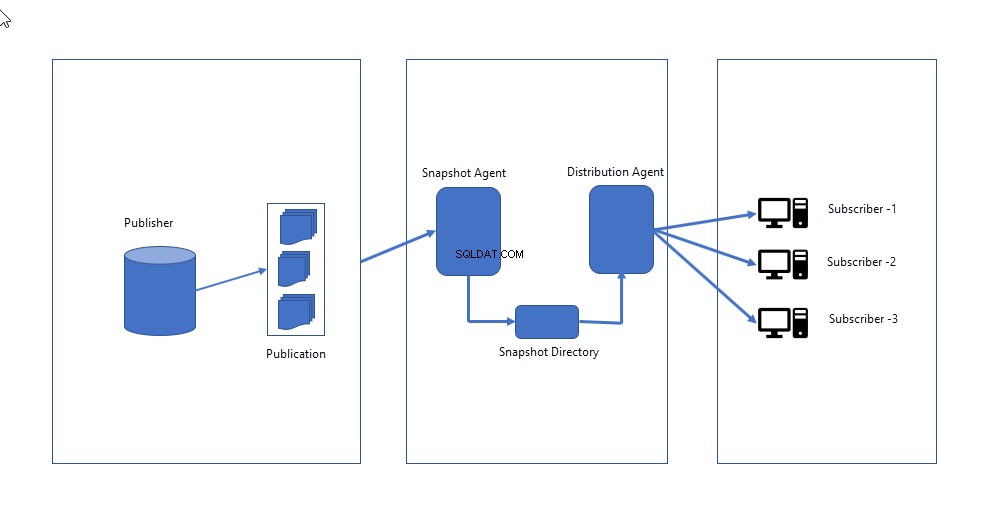
Mens du konfigurerer snapshot-replikering, defineres følgende vigtige komponenter:
- Snapshot Agent :Det skaber et komplet billede af skema og data defineret i publikationen og sender det til distributøren. Snapshot-agenten forbliver inaktiv, indtil den udløses manuelt ELLER planlagt til at køre på et bestemt tidspunkt.
- Distributøragent :Den sender snapshotfilerne til abonnenter og anvender skema og data ved at erstatte det eksisterende.
Snapshot-replikering udfører følgende aktiviteter:
- På den definerede tidsplan placerer snapshot-agenten en delt lås på skemaet og de data, der skal publiceres.
- Hele snapshot af offentliggjorte data kopieret til distributørenden. Snapshot-agent opretter tre filer
- Fil til oprettet databaseskema over offentliggjorte data.
- BCP-fil til eksport af data i SQL-tabeller
- Indeks filer til eksport af indeksdata.
- Når filer er oprettet, frigiver snapshot-agenten delte låse på offentliggjorte data og data.
- Distributoragenter starter og erstatter abonnentskemaet og dataene ved hjælp af filer oprettet af snapshot-agenten.
Følgende billede illustrerer, hvordan snapshot-replikering fungerer.
Fordele
- Snapshot-replikering er meget enkel at konfigurere. Hvis data ikke ændres ofte, er snapshot-replikering en meget passende mulighed.
- Du kan kontrollere, hvornår data skal sendes. For eksempel en mastertabel, der har en stor mængde data, men som ændres sjældnere, end du kan replikere dataene, når trafikken er lav.
Ulempe
- Snapshot genereret af snapshot-agenten indeholder ændrede og uændrede publicerede data, derfor kan det øjebliksbillede, der sendes over netværket, producere latens og påvirke andre operationer.
- Efterhånden som data stiger, øges størrelsen af øjebliksbilledet, og det tager mere tid at oprette og distribuere øjebliksbilledet til abonnenter.
Flet replikering
Fletreplikering kan bruges, når vi skal administrere ændringer på flere servere, og disse ændringer skal konsolideres.
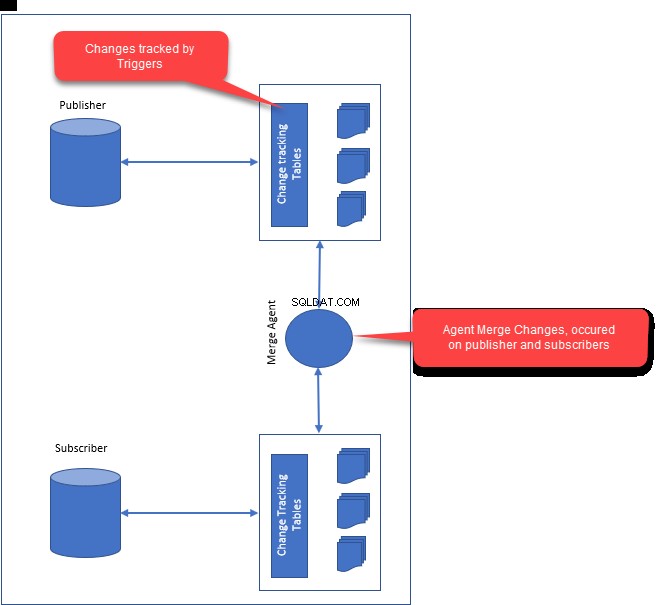
Når vi konfigurerer fletreplikering, oprettes følgende komponenter:
- Snapshot Agent :Snapshot-agent genererer det første øjebliksbillede af publikationsdata og databaseobjekter. Når øjebliksbilledet er oprettet, vil det blive distribueret til alle abonnenter.
- Flet agent :Merge agent er ansvarlig for at løse konflikterne mellem udgiver og abonnenter. Eventuelle konflikter løses gennem fletteagenten, som bruger konfliktløsning. Afhængigt af hvordan du har konfigureret konfliktløsningen, løses konflikterne af fletteagenten.
Når vi konfigurerer fletreplikering, udfører den følgende aktiviteter:
- Den starter ved at tage et øjebliksbillede af publikationsdata og databaseobjekter og et øjebliksbillede anvendt på abonnenter.
- Mens du konfigurerer flettereplikering, opretter det triggere på udgiver og abonnent. Udløsere er ansvarlige for at holde styr på efterfølgende ændringer og tabelændringer på udgiver og abonnenter.
- Når udgiver og abonnenter opretter forbindelse til netværket, vil ændringer af datarækker og skemaændringer blive synkroniseret med hinanden. Mens ændringer af udgiver og abonnenter flettes, løser fletteagent konflikterne baseret på betingelserne defineret i fletteagenten.
Fletreplikering bruges i server-til-klient-miljøer, og den er ideel til de situationer, hvor abonnenter skal hente data fra udgiveren, foretage ændringer offline og derefter synkronisere ændringer med udgiveren og andre abonnenter.
Der kan være praktiske situationer, hvor den samme række ændres af forskellige udgivere og abonnenter. På det tidspunkt vil fletteagenten se på, hvilken konfliktløsning der er defineret og foretage ændringer i overensstemmelse hermed.
SQL Server identificerer entydigt en kolonne ved hjælp af en globalt unik identifikator for hver række i en offentliggjort tabel. Hvis tabellen allerede har en unik identifikatorkolonne, bruger SQL Server automatisk denne kolonne. Ellers tilføjer den en rækkeguidekolonne i tabellen og opretter et indeks baseret på kolonnen.
Triggere vil blive oprettet på de offentliggjorte tabeller på både udgivere og abonnenter. De bruges til at spore ændringerne baseret på række- eller kolonneændringerne.
Følgende billede illustrerer, hvordan fletreplikering fungerer:
Fordele:
- Dette er den eneste måde at konsolidere ændringer på flere serverdata.
Ulempe:
- Det tager meget tid at replikere og synkronisere begge ender.
- Der er lav konsistens, da mange parter skal synkroniseres.
- Der kan være konflikter under fletning af replikering, hvis de samme rækker er berørt i mere end én abonnent og udgiver. Det kan løses ved hjælp af konfliktløsningen, men det gør replikeringsopsætningen mere kompliceret.
T-SQL-kode til at gennemgå replikeringskonfigurationen
Jeg har konfigureret snapshot-replikeringen og transaktionsreplikeringen på to forekomster af min maskine. Ved hjælp af SQL Dynamic Management (DMV'er) kan vi kontrollere konfigurationen af replikering. For at gennemgå konfigurationen af replikering kan vi bruge T-SQL-kode. Scriptkode udfylder følgende:
- Abonnentdatabasenavn.
- Udgivernavn.
- Abonnementstype.
- Udgiverdatabase.
- Navn på replikeringsagent.
Nedenfor er scriptet:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Følgende er output:

Oversigt
I denne artikel har jeg forklaret:
- Grundlaget og fordelene ved replikering og dets komponenter.
- Transaktionsreplikering.
- Snapshot-replikering.
- Flet replikering.