Databasen er en kritisk og vital del af enhver virksomhed eller organisation. De voksende tendenser forudsiger, at 82 % af virksomhederne forventer, at antallet af databaser vil stige i løbet af de næste 12 måneder. En stor udfordring for enhver DBA er at finde ud af, hvordan man tackler massiv datavækst, og dette bliver et meget vigtigt mål. Hvordan kan du øge databasens ydeevne, sænke omkostningerne og eliminere nedetid for at give dine brugere den bedst mulige oplevelse? Er datakomprimering en mulighed? Lad os komme i gang og se, hvordan nogle af de eksisterende funktioner kan være nyttige til at håndtere sådanne situationer.
I denne artikel skal vi lære, hvordan datakomprimeringsløsningen kan hjælpe os med at optimere datastyringsløsningen. I denne vejledning dækker vi følgende emner:
- En oversigt over komprimering
- Fordele ved komprimering
- En oversigt over data er komprimeringsteknikker
- Diskussion af forskellige typer datakomprimering
- Fakta om datakomprimering
- Implementeringsovervejelser
- og mere...
Kompression
Kompressionen er en teknik og dermed en ressourcefølsom operation, men med hardware-afvejninger. Man skal tænke på at implementere datakomprimering for følgende fordele:
- Effektiv pladsstyring
- Effektiv omkostningsreduktionsteknik
- Let af databasesikkerhedskopiering
- Effektiv N/W-båndbreddeudnyttelse
- Sikker og hurtigere gendannelse eller gendannelse
- Bedre ydeevne – reducerer systemets hukommelsesfodaftryk
Bemærk: Hvis SQL Server er CPU- eller hukommelsesbegrænset, passer komprimering muligvis ikke til dit miljø.
Datakomprimering gælder for:
- Dynge
- Klyngede indekser
- Ikke-klyngede indekser
- Partitioner
- Indekserede visninger
Bemærk: Store objekter komprimeres ikke (f.eks. LOB og BLOB)
Bedst egnet til følgende applikationer:
- Logtabeller
- Revisionstabeller
- Faktatabeller
- Rapportering
Introduktion
Datakomprimering er en teknologi, der har eksisteret siden SQL Server 2008. Ideen med datakomprimering er, at du selektivt kan vælge tabeller, indekser eller partitioner i en database. I/O er fortsat en flaskehals i at flytte information mellem ind og ud af databasen. Datakomprimering udnytter denne type og hjælper med at øge effektiviteten af en database. Da vi ved, at netværkshastighederne er så meget langsommere end behandlingshastigheden, er det muligt at finde effektivitetsgevinster ved at bruge processorkraften til at komprimere data i en database, så de rejser hurtigere. Og brug så processorkraft igen for at komprimere dataene i den anden ende. Generelt reducerer datakomprimering den plads, som dataene optager. Teknikken til datakomprimering er tilgængelig for enhver database, og den understøttes af alle udgaver af SQL Server 2016 SP1. Før dette var det kun tilgængeligt på SQL Server Enterprise eller Developer-udgaver, ikke på Standard eller Express.
Funktionsunderstøttelse

Datakomprimeringstyper
Der er to typer datakomprimering tilgængelige i SQL Server, rækkeniveau og sideniveau.
Kompressionen på rækkeniveau arbejder bag kulisserne og konverterer alle datatyper med fast længde til typer med variabel længde. Antagelsen her er, at data ofte lagres i en fast længdetype, såsom char 100, og de fylder faktisk ikke hele 100 tegn for hver post. Små gevinster kan opnås ved at fjerne denne ekstra plads fra bordet. Selvfølgelig, hvis dine datatabeller ikke bruger tekst og numeriske felter med fast længde, eller hvis de gør det, og du faktisk gemmer det fuldt tilladte antal tegn og cifre, vil komprimeringsgevinsterne under rækkeniveauskemaet være minimale i bedste fald.
Konceptet med komprimering er udvidet til alle datatyper med fast længde, inklusive char, int og float. SQL Server giver mulighed for at spare plads ved at gemme dataene, som om det var en type med variabel størrelse; dataene vises og opfører sig som en fast længde.
For eksempel, hvis du har gemt værdien 100 i en int kolonnen, behøver SQL Serveren ikke bruge alle 32 bit, i stedet bruger den blot 8 bit (1 byte).
Komprimering på sideniveau tager tingene til et andet niveau. For det første anvender den automatisk komprimering på rækkeniveau på datafelter med fast længde, så du automatisk får disse gevinster som standard. Oven i det anvender den noget, der kaldes præfikskomprimering, og en anden teknik kaldet ordbogskomprimering.
Rækkekomprimering
Rækkekomprimering er et indre niveau af komprimering, der gemmer de faste tegnstrenge ved at bruge format med variabel længde ved ikke at gemme de tomme tegn. Følgende trin udføres i komprimeringen på rækkeniveau.
- Alle numeriske datatyper såsom int , flyde , decimal, og penge konverteres til datatyper med variabel længde. For eksempel er 125 gemt i kolonnen og kolonnens datatype et heltal. Så ved vi, at der bruges 4 bytes til at gemme heltalsværdien. Men 125 kan gemmes i 1 byte, fordi 1 byte kan gemme værdier fra 0 til 255. Så 125 kan gemmes som en lille int , sådan at 3 bytes kan gemmes.
- Char og Nchar datatyper gemmes som datatyper med variabel længde. For eksempel er "SQL" gemt i et char (20) type kolonne. Men efter komprimering vil kun 3 bytes bruge. Efter datakomprimeringen gemmes intet blankt tegn med denne type data.
- Recordens metadata er reduceret.
- NULL- og 0-værdier er optimeret, og der forbruges ingen plads.
Sidekomprimering
Sidekomprimering er et avanceret niveau af datakomprimering. Som standard implementerer en sidekomprimering også komprimeringen på rækkeniveau. Sidekomprimering er kategoriseret i to typer
- Prefikskomprimering og
- Ordbogskomprimering.
Prefikskomprimering
Ved præfikskomprimering for hver side, for hver kolonne på siden, hentes en fælles værdi fra alle rækker og gemmes under overskriften i hver kolonne. Nu i hver række er en reference til den værdi gemt i stedet for fælles værdi.
Ordbogskomprimering
Ordbogskomprimering ligner præfikskomprimering, men fælles værdier hentes fra alle kolonner og gemmes i den anden række efter overskriften. Ordbogskomprimering leder efter nøjagtige værdimatches på tværs af alle kolonner og rækker på hver side.
Vi kan udføre række- og sideniveaukomprimering for følgende databaseobjekter.
- En tabel gemt i en bunke.
- En hel tabel gemt som et klynget indeks.
- Indekseret visning.
- Ikke-klynget indeks.
- Partitionerede indekser og tabeller.
Bemærk: Vi kan udføre datakomprimering enten på oprettelsestidspunktet som CREATE TABLE, CREATE INDEX eller efter oprettelsen ved hjælp af ALTER-kommandoen med REBUILD-indstillingen som ALTER TABLE …. GENBYG MED.
Demo
WideWorldImporters databasen bruges gennem hele demoen. Også en DW i realtid databasen tages i betragtning til komprimeringsoperationen.
Lad os gennemgå trinene i detaljer:
1. For at se komprimeringsindstillinger for objekter i databasen skal du køre følgende T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Følgende output viser komprimeringstypen som PAGE, ROW, og for flere tabeller er det INGEN. Det betyder, at den ikke er konfigureret til komprimering.
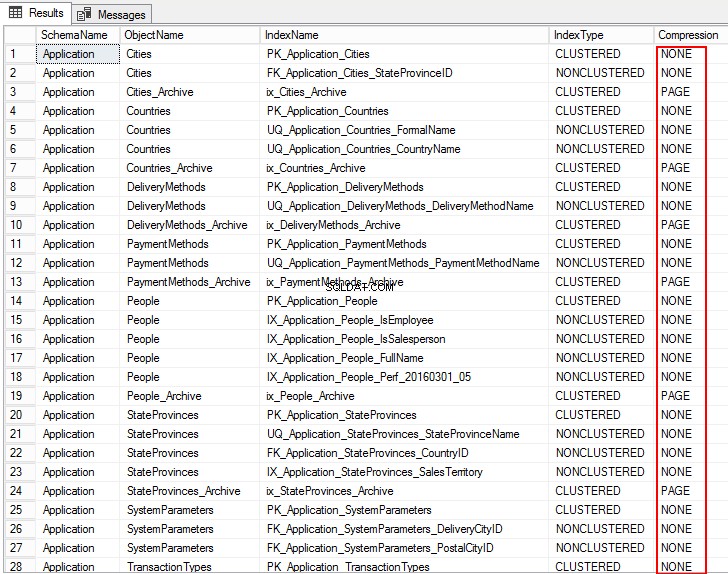
2. For at estimere komprimering skal du køre følgende systemlagrede procedure sp_estimate_data_compression_savings . I dette tilfælde udføres den lagrede procedure på PurchaseOrderLines-tabellerne.
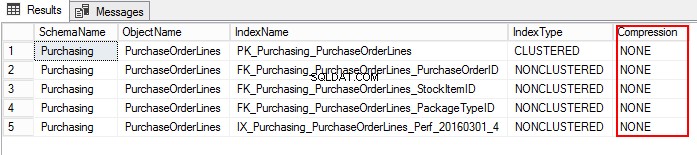
3. Lad os finde ud af PurchaseOrderLines-komprimeringsindstillingen ved at køre følgende T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

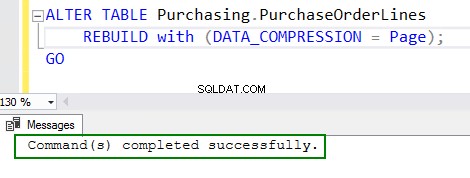
4. Aktiver komprimering ved at køre ALTER table-kommandoen:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
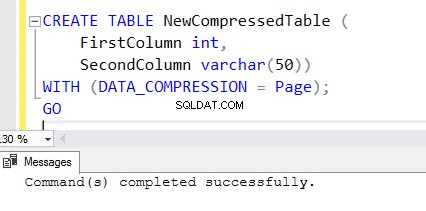
5. For at oprette en ny tabel med komprimeringsaktiveret funktion skal du tilføje WITH-sætningen i slutningen af CREATE TABLE-sætningen. Du kan se nedenstående CREATE TABLE-sætning, der bruges til at oprette NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakta om datakomprimering
Lad os gennemgå nogle af de faktiske oplysninger om komprimering
- Kompression kan ikke anvendes på systemtabeller
- En tabel kan ikke aktiveres til komprimering, når rækkestørrelsen overstiger 8060 bytes.
- Komprimerede data er cachelagret i bufferpuljen; det betyder hurtigere svartider
- Aktivering af komprimering kan få forespørgselsplanerne til at ændre sig, fordi dataene gemmes ved hjælp af et andet antal sider og antal rækker pr. side.
- Ikke-klyngede indekser arver ikke komprimeringsegenskaber
- Når et klynget indeks oprettes på en heap, arver det klyngede indeks komprimeringstilstanden for heapen, medmindre en alternativ komprimeringstilstand er angivet.
- Kompressionerne på ROW- og PAGE-niveau kan aktiveres og deaktiveres, offline eller online.
- Hvis heap-indstillingen ændres, skal alle ikke-klyngede indekser genopbygges.
- Diskpladskravene for at aktivere eller deaktivere række- eller sidekomprimeringen er de samme som for at oprette eller genopbygge et indeks.
- Når partitioner opdeles ved at bruge ALTER PARTITION-sætningen, arver begge partitioner datakomprimeringsattributten for den oprindelige partition.
- Når to partitioner flettes, arver den resulterende partition destinationspartitionens datakomprimeringsattribut.
- For at skifte en partition skal partitionens datakomprimeringsegenskab matche tabellens komprimeringsegenskab.
- Columnstore-tabeller og -indekser gemmes altid med Columnstore-komprimeringen.
- Datakomprimering er inkompatibel med sparsomme kolonner, så tabellen kan ikke komprimeres.
Scenarie i realtid
Lad os gennemgå datakomprimeringsteknikken og forstå nøgleparametrene for datakomprimering.
For at kontrollere den plads, der bruges af hver tabel, skal du køre følgende T-SQL. Outputtet af forespørgslen giver os detaljerede oplysninger om brugen af hver tabel. Dette ville være den afgørende faktor for implementeringen af datakomprimeringen.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
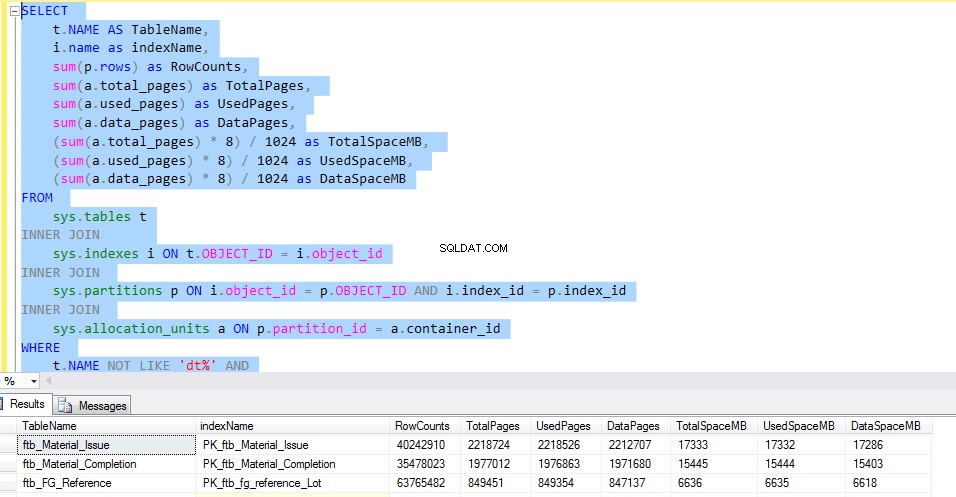
Lad os overveje ftb_material_Issue faktatabel. Faktatabellen har numeriske BIGINT-datatyper.
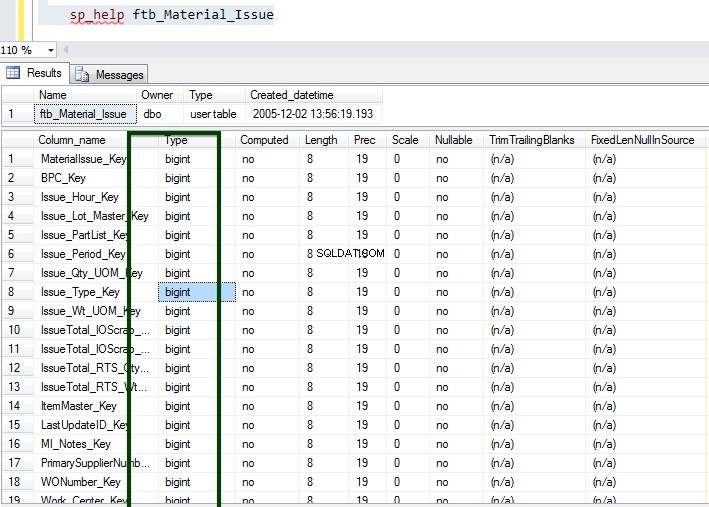
Kør nu den lagrede procedure sp_spaceused for at forstå detaljerne i tabellen. Du kan lære mere om kommandoen sp_spaceused her.
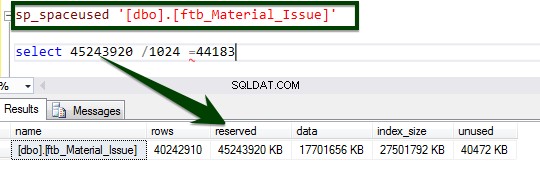
Aktiver komprimering på tabelniveau ved at køre følgende T-SQL. Følgende T-SQL blev udført på serveren, og det tog 34 minutter og 14 sekunder at komprimere siden på tabelniveau.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
Du kan se CPU- og I/O-udsving under udførelsen af ALTER-tabelkommandoen.
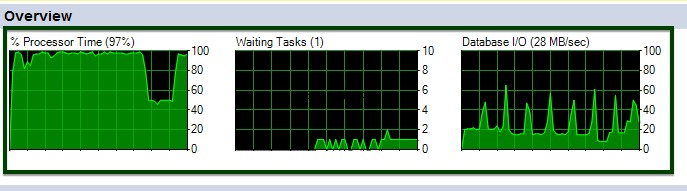
Lad os nu sammenligne før v/s efter datakomprimering. Bordstørrelsen omkring ~45 GB er bragt ned til ~15 GB.
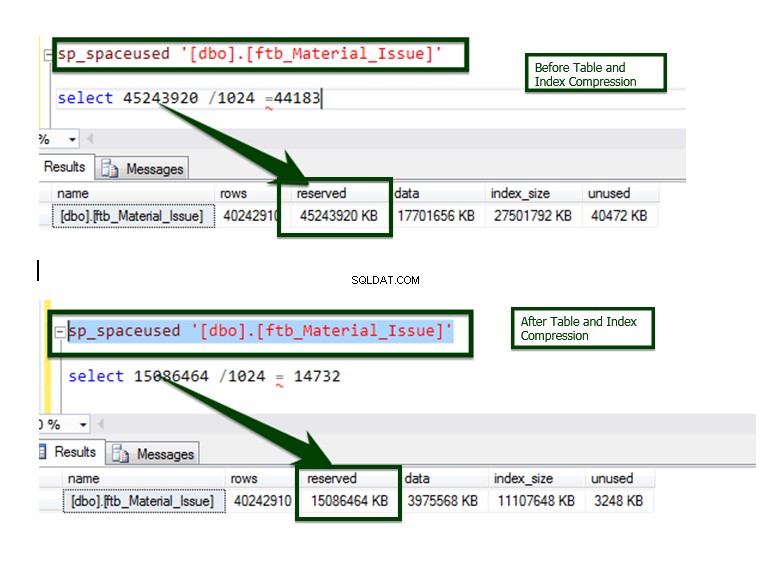
Processen er implementeret på de fleste af objekterne ved hjælp af et automatiseret script, og her er det endelige resultat af sammenligningen.
Datasammenligning mellem før og efter indekskomprimeringsoperationen.

Oversigt
Datakomprimering er en meget effektiv teknik til at reducere størrelsen af data; reducerede data kræver færre I/O-processer. Tilføjelse af komprimering til databasen øger belastningen af CPU-krav. Du skal sikre dig, at du har den tilgængelige behandlingskapacitet til at imødekomme disse ændringer på en effektiv måde. Så det er bedre at lave lidt research først og se de typer gevinster, der kan forventes, før du anvender ændringerne for at aktivere datakomprimering. Det er meget fordelagtigt i cloud-databaseopsætningen, hvor omkostningerne er involveret.
Iscenesætter kompressionerne (udfør dem ikke alle på én gang) og komprimer i perioder med lav aktivitet. Datakomprimering og backup-komprimering eksisterer fint side om side og kan resultere i yderligere lagerpladsbesparelser, så forsæt og forkæl dig selv.
Ikke alene reducerer komprimering fysiske filstørrelser, men det reducerer også disk I/O, hvilket i høj grad kan forbedre ydeevnen af mange databaseapplikationer sammen med databasesikkerhedskopiering.
Beslutningen om at implementere komprimering er lettere, hvis vi kender den underliggende infrastruktur og forretningskrav. Vi kan helt sikkert bruge den tilgængelige systemprocedure til at forstå og estimere kompressionsbesparelser. Denne lagrede procedure giver ikke sådanne detaljer, som fortæller dig, hvordan komprimeringen vil påvirke dit system positivt eller negativt. Det er tydeligt, at der er afvejninger til enhver form for komprimering. Hvis du har de samme mønstre af enorme data, så er komprimering nøglen til at spare plads. Med voksende CPU-kraft og hvert system bundet til strukturer med flere kerner, kan komprimering passe til mange systemer. Jeg vil anbefale at teste dine systemer. Test for at sikre, at ydeevnen ikke påvirkes negativt. Hvis et indeks har mange opdateringer og sletninger, kan CPU-omkostningerne til at komprimere og dekomprimere data opveje I/O- og RAM-besparelserne ved datakomprimering. Ikke alle databaser eller tabeller vil automatisk være en god kandidat til at anvende komprimering på, så det er bedst at lave lidt research først for at se den slags gevinster, der kan forventes, før du anvender ændringerne for at aktivere datakomprimering på dine databaser. Du skal teste komprimering for at se, om det fungerer godt i dit miljø, fordi det muligvis ikke fungerer godt i databaser med tunge indsættelser.
Referencer
Udgaver og understøttede funktioner i SQL Server 2016
Datakomprimering
Implementering af rækkekomprimering
Sidekomprimeringsimplementering