En Oracle-udvikler, der ofte bruger regulære udtryk i kode, kan før eller siden stå over for et fænomen, der i sandhed er mystisk. Langsigtede søgninger efter roden til problemet kan føre til vægttab, appetit og fremkalde forskellige former for psykosomatiske lidelser – alt dette kan forebygges ved hjælp af regexp_replace-funktionen. Den kan have op til 6 argumenter:
REGEXP_REPLACE (
- kildestreng,
- skabelon,
- erstatter_streng,
- startpositionen for matchsøgningen med en skabelon (standard 1),
- en placering af skabelonens forekomst i en kildestreng (som standard er 0 lig med alle forekomster),
- modifikator (indtil videre er det en dark horse)
)
Returnerer den ændrede kildestreng, hvor alle forekomster af skabelonen er erstattet af den værdi, der sendes i parameteren substituting_string. Ofte bruges en kort version af funktionen, hvor de første 3 argumenter er angivet, hvilket er nok til at løse mange problemer. Jeg vil gøre det samme. Antag, at vi skal maskere alle strengtegnene med stjerner i 'MASK:små bogstaver'-strengen. For at angive omfanget af små bogstaver, skal "[a-z]"-mønsteret passe.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Forventning
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Virkelighed
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Hvis denne begivenhed ikke er blevet gengivet i din database, så er du heldig indtil videre. Men oftere begynder du at grave i kode, konverterer strenge fra et sæt tegn til et andet, og til sidst kommer en fortvivlelse.
Definition af et problem
Spørgsmålet opstår - hvad er så specielt ved bogstavet 'A', at det ikke er blevet erstattet, fordi resten af de store bogstaver ikke skulle erstattes også. Måske er der andre rigtige bogstaver bortset fra denne. Det er nødvendigt at se på hele alfabetet af store bogstaver.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Men
Hvis det sjette argument for funktionen ikke er eksplicit angivet, f.eks. er 'i' ufølsomhed for store og små bogstaver eller 'c' er forskel på store og små bogstaver, når en kildestreng sammenlignes med en skabelon, regulært udtryk bruger som standard parameteren NLS_SORT for sessionen/databasen. For eksempel:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Denne parameter angiver sorteringsmetoden i ORDER BY. Hvis vi taler om at sortere simple individuelle tegn, så svarer et bestemt binært tal (NLSSORT-kode) til hver af dem, og sorteringen foregår faktisk efter værdien af disse tal.
For at illustrere dette, lad os tage de første og sidste par tegn i alfabetet, både små og store bogstaver, og sætte dem i et betinget uordnet tabelsæt og kalde det ABC. Lad os derefter sortere dette sæt efter SYMBOL-feltet og vise dets NLSSORT-kode i HEX-formatet ud for hvert symbol.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
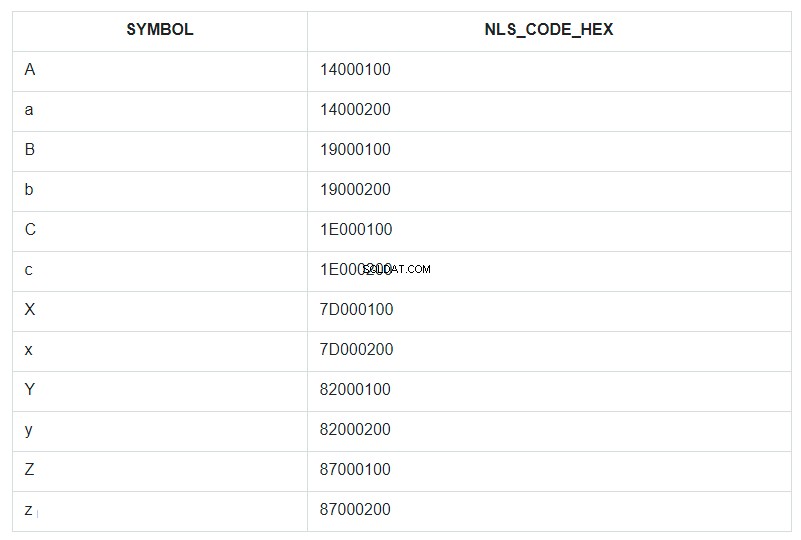
I forespørgslen er ORDER BY angivet for SYMBOL-feltet, men faktisk gik sorteringen i databasen efter værdierne fra feltet NLS_CODE_HEX.
Gå nu tilbage til intervallet fra skabelonen og se på tabellen – hvad er lodret mellem symbolet 'a' (kode 14000200) og 'z' (kode 87000200)? Alt undtagen det store bogstav 'A'. Det er alt, der er blevet erstattet med en stjerne. Og koden 14000100 af bogstavet 'A' er ikke inkluderet i erstatningsintervallet fra 14000200 til 87000200.
Kur
Angiv eksplicit modifikatoren for store og små bogstaver
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Nogle kilder siger, at modifikator 'c' er indstillet som standard, men vi har lige set, at dette ikke er helt sandt. Og hvis nogen ikke så det, så er NLS_SORT-parameteren for dens session/database højst sandsynligt sat til BINARY, og sorteringen udføres i overensstemmelse med rigtige tegnkoder. Faktisk, hvis du ændrer sessionsparameteren, vil problemet blive løst.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Test blev udført i Oracle 12c.
Du er velkommen til at efterlade dine kommentarer og passe på.