Introduktion
I denne artikel vil vi diskutere, hvordan forskellige typer indekser i SQL Server-hukommelsesoptimerede tabeller påvirker ydeevnen. Vi vil undersøge eksempler på, hvordan forskellige indekstyper kan påvirke ydeevnen af hukommelsesoptimerede tabeller.
For at gøre emnediskussionen lettere, vil vi gøre brug af et ret stort eksempel. For overskuelighedens skyld vil dette eksempel indeholde forskellige replikaer af en enkelt tabel, mod hvilke vi vil køre forskellige forespørgsler. Disse replikaer vil bruge forskellige indekser eller slet ingen indekser (undtagen selvfølgelig de primære nøgler – PK'er).
Bemærk, at det egentlige formål med denne artikel ikke er at sammenligne ydeevne mellem diskbaserede og hukommelsesoptimerede tabeller i SQL Server i sig selv. Dens formål er at undersøge, hvordan indekser påvirker ydeevnen i hukommelsesoptimerede tabeller. For at få et fuldstændigt billede af eksperimenterne er der også angivet timings for de tilsvarende diskbaserede tabelforespørgsler, og hastighedsstigningerne beregnes ved at bruge den mest optimale konfiguration af diskbaserede tabeller som basislinjer.
Scenarie
Eksempeldata for vores scenarie er baseret på en enkelt tabel defineret som følgende:
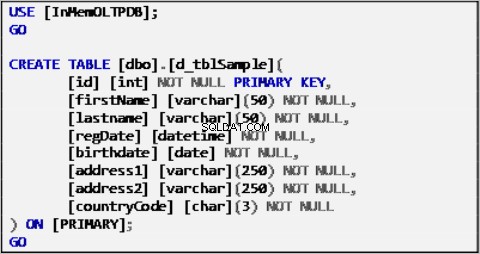
Fortegnelse 1:Eksempeldatakildetabel.
Tabellen ovenfor var udfyldt med eksempeldata og vil fungere som datakilde for resten af tabellerne.
Så baseret på ovenstående tabel opretter vi følgende 9 tabelvarianter og udfylder dem med de samme eksempeldata:
- 3 diskbaserede tabeller:
- d_tblSample1
- Klynget indeks i kolonnen "id" – primær nøgle (PK)
- d_tblSample2
- Klynget indeks i kolonnen "id" (PK)
- Ikke-klynget indeks i kolonnen "countryCode"
- d_tblSample3
- Klynget indeks i kolonnen "id" (PK)
- Ikke-klyngede indekser i kolonnen "regDate"
- Ikke-klyngede indekser i kolonnen "countryCode"
- d_tblSample1
- 3 hukommelsesoptimerede tabeller (sæt 1:Hash-indekser):
- m1_tblSample1
- Ikke-klyngede hash-indeks i kolonnen "id" – primær nøgle (PK)
- m1_tblSample2
- Ikke-klynget hash-indeks i "id"-kolonnen (PK)
- Hash-indeks i kolonnen "countryCode"
- m1_tblSample3
- Ikke-klynget hash-indeks i "id"-kolonnen (PK)
- Hash-indeks i kolonnen "regDate"
- Hash-indeks i kolonnen "countryCode"
- 3 hukommelsesoptimerede tabeller (sæt 2:Ikke-klyngede indekser):
- m2_tblSample1
- Ikke-klynget indeks i kolonnen "id" – primær nøgle (PK)
- m2_tblSample2
- Ikke-klynget indeks i kolonnen "id" (PK)
- Ikke-klynget indeks i kolonnen "countryCode"
- m2_tblSample3
- Ikke-klynget indeks i kolonnen "id" (PK)
- Ikke-klynget indeks i kolonnen "regDate"
- Ikke-klynget indeks i kolonnen "countryCode"
- m2_tblSample1
- m1_tblSample1
I nedenstående lister kan du finde definitionerne for ovenstående tabeller.
Scenarielogikken er, at vi udfører forskellige databaseoperationer mod variationer af den samme tabel (men med forskellige indekser), og observerer, hvordan ydeevnen påvirkes i hvert enkelt tilfælde.
Definitioner
Diskbaserede tabeller
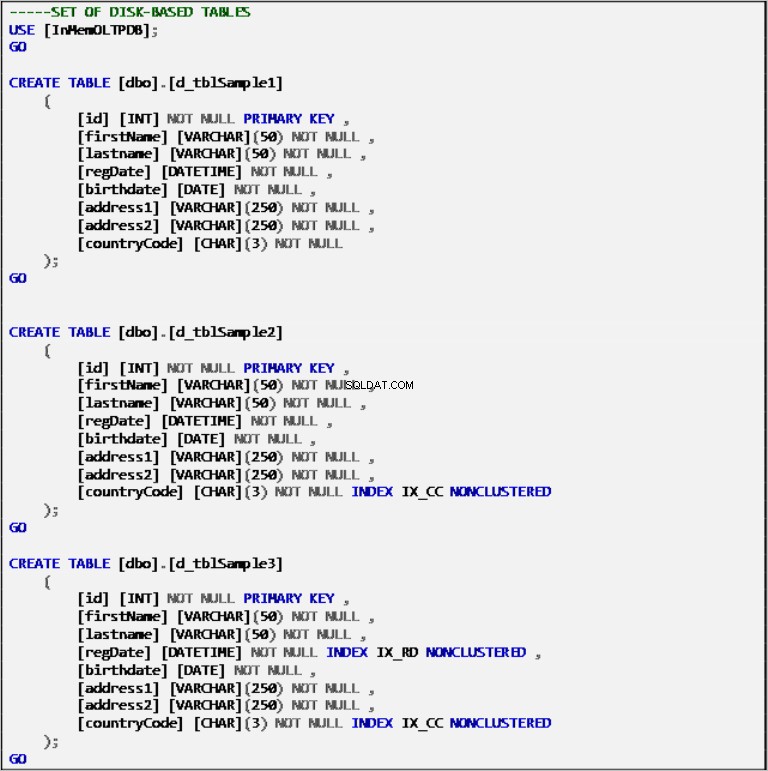
Liste 2:Disk-baserede tabeller Definition.
Hukommelsesoptimerede tabeller (sæt 1:Hash-indekser)

Liste 3:Hukommelsesoptimerede tabeller – sæt 1 (hash-indekser).
Hukommelsesoptimerede tabeller (sæt 2:Ikke-klyngede indekser)

Fortegnelse 4:Hukommelsesoptimerede tabeller – sæt 2 (ikke-klyngede indekser).
Derefter udfylder vi alle ovenstående tabeller med de samme eksempeldata, hvilket er i alt 5 millioner poster i hver tabel.
Her er outputtet af tællekommandoen for hvert sæt tabeller:
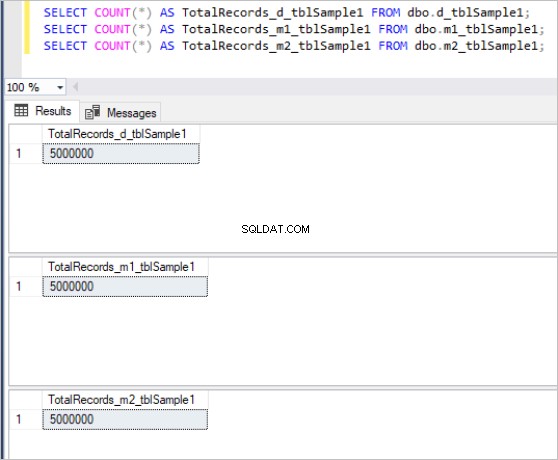
Figur 1:Samlet antal poster for første sæt tabeller.
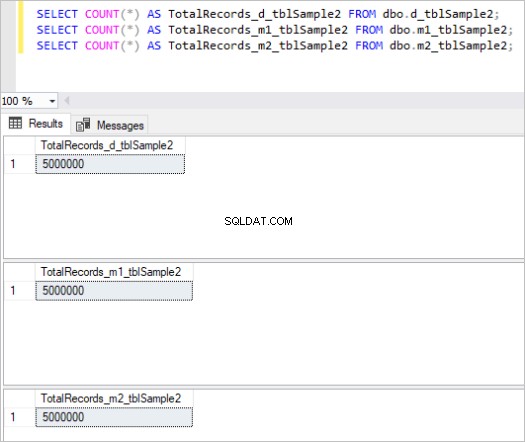
Figur 2:Samlet antal poster for andet sæt tabeller.
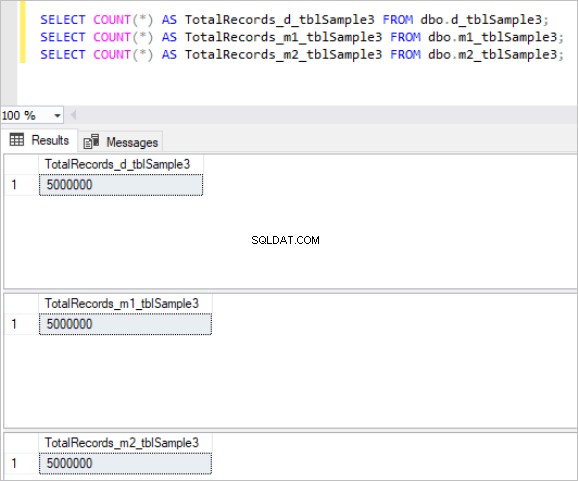
Figur 3:Samlet antal poster for tredje sæt tabeller.
Forespørgsler og scenarieudførelser
Nu skal vi køre et sæt forespørgsler mod ovenstående tabeller og se, hvordan hver tabel klarer sig.
Disse forespørgsler udfører følgende handlinger:
- Forespørgsel 1:Aggregation (GROUP BY)
- Forespørgsel 2:Indekssøgning på lighedsprædikater
- Forespørgsel 3:Indekssøgning om ligheds- og ulighedsprædikater
Planen er at udføre forespørgslerne som beskrevet nedenfor:
Forespørgsel 1 – Udførelse i forhold til følgende tabeller:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (intet indeks på målkolonner)
- m2_tblSample1 (intet indeks på målkolonner)
Forespørgsel 2 – Udførelse i forhold til følgende tabeller:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (intet indeks på målkolonner)
- m2_tblSample1 (intet indeks på målkolonner)
Forespørgsel 3 – Udførelse i forhold til følgende tabeller:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (intet indeks på målkolonner)
- m2_tblSample1 (intet indeks på målkolonner)
Bemærk :Selvom definitionen for d_tblSample1 disk-baseret tabel er inkluderet i ovenstående tabeldefinitioner, den bruges ikke i forespørgslerne i denne artikel. Årsagen er, at der i hvert scenarie bruges den mest optimale mulige konfiguration for den diskbaserede tabel, da vi ønsker, at vores baseline skal være så hurtig som muligt, når vi sammenligner den med ydeevnen af hukommelsesoptimerede tabeller. Til dette formål skal d_tblSample1 tabellen er kun præsenteret til informationsformål.
Nedenfor kan du finde T-SQL-scripts til de tre forespørgsler sammen med mekanismerne til måling af eksekveringstid.

Fortegnelse 5:Forespørgsel 1 – Aggregation (med indekser).
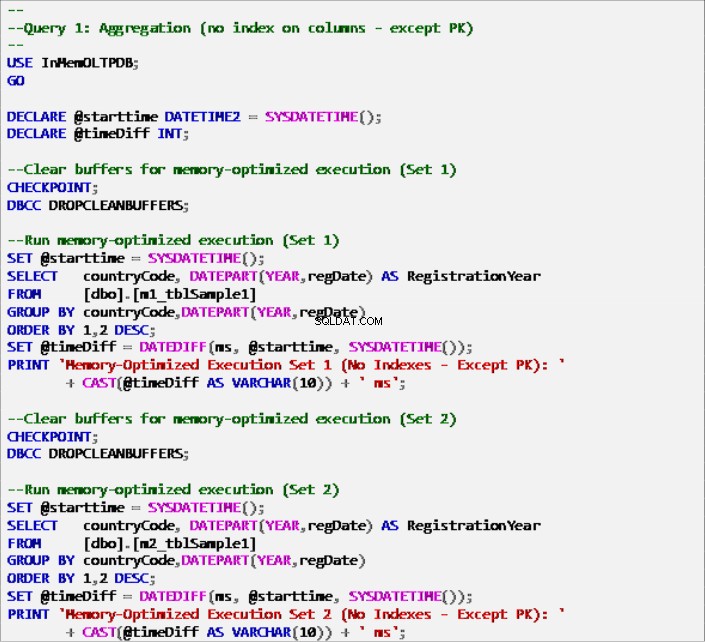
Fortegnelse 6:Forespørgsel 1 – Aggregation (uden indekser – undtagen primærnøgle).
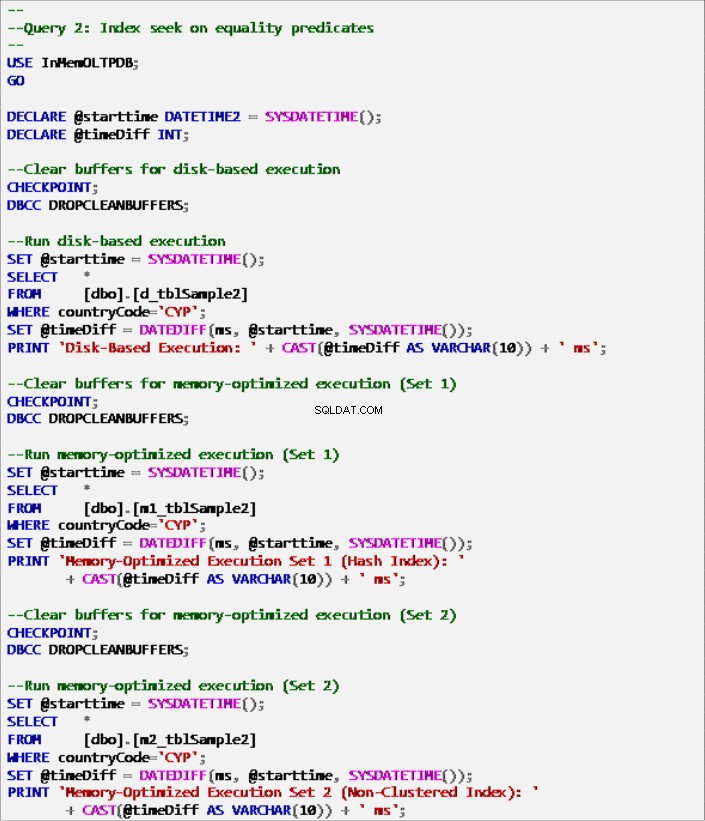
Optegnelse 7:Forespørgsel 2 – Indekssøgning på ligestillingsprædikater (med indekser).

Fortegnelse 8:Forespørgsel 2 – Indekssøgning på ligestillingsprædikater (uden indeks – undtagen primærnøgle).
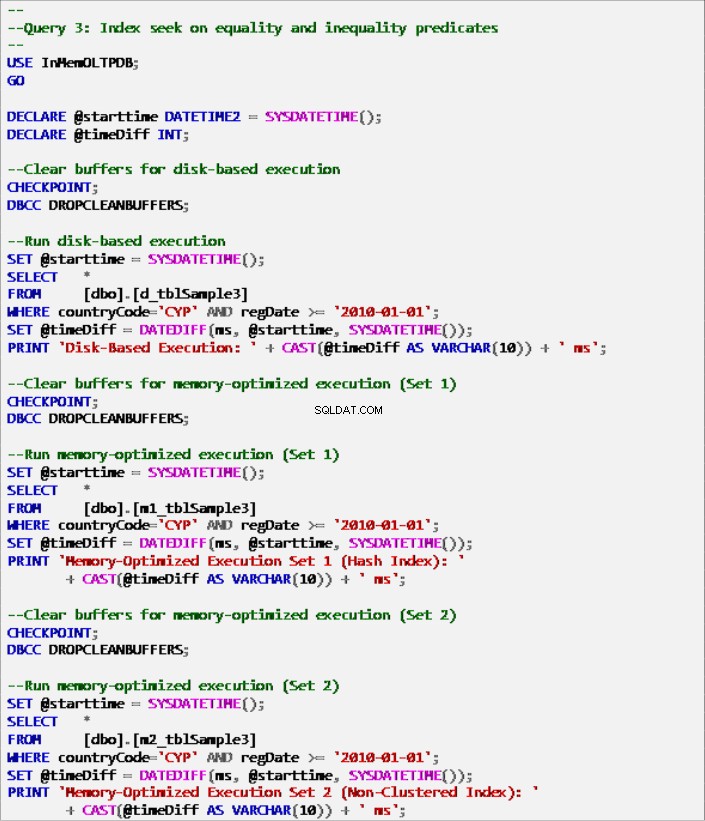
Fortegnelse 9:Forespørgsel 3 – Indekssøgning om ligheds- og ulighedsprædikater (med indekser).

Optegnelse 10:Forespørgsel 3 – Indekssøgning om ligheds- og ulighedsprædikater (uden indeks – undtagen primærnøgle).
Skærmbillederne nedenfor viser output fra hver forespørgselsudførelse:
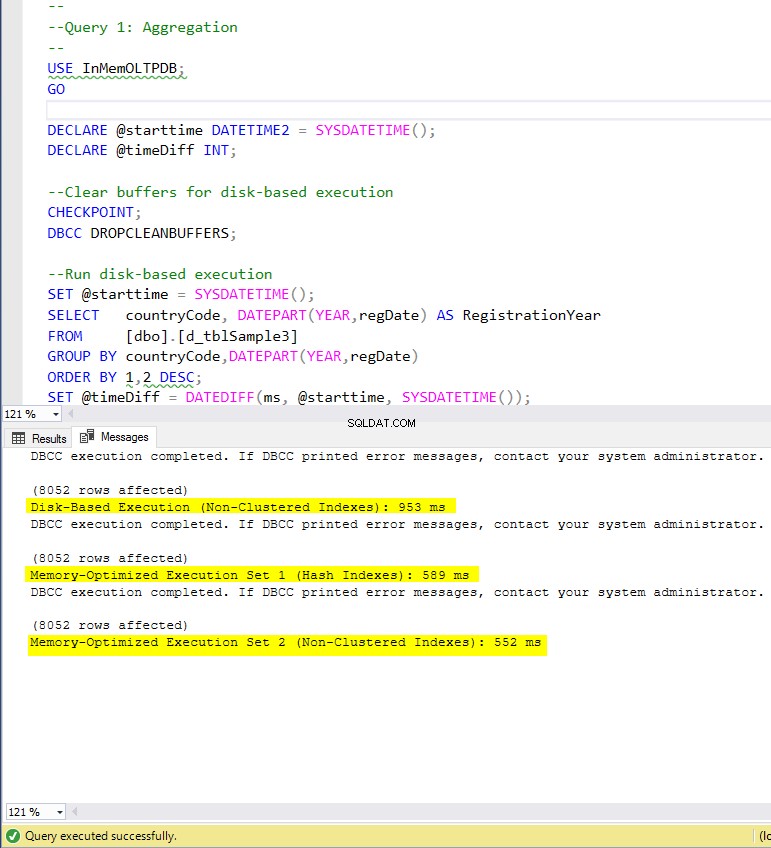
Figur 4:Forespørgsel 1 Eksekveringstid (med indekser).
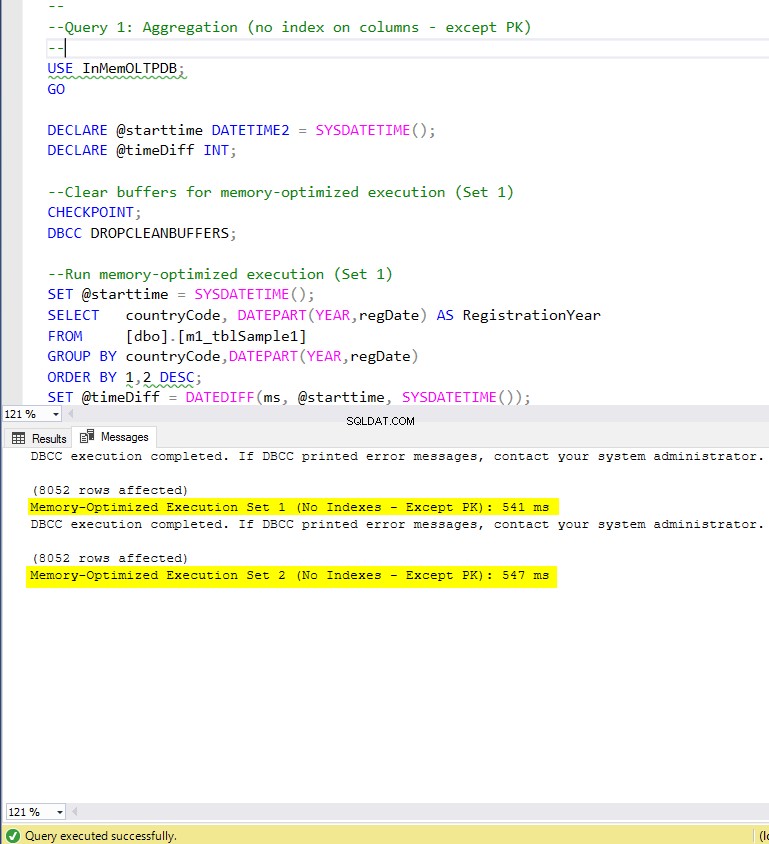
Figur 5:Udførelsestid for forespørgsel 1 (uden indekser – undtagen PK).
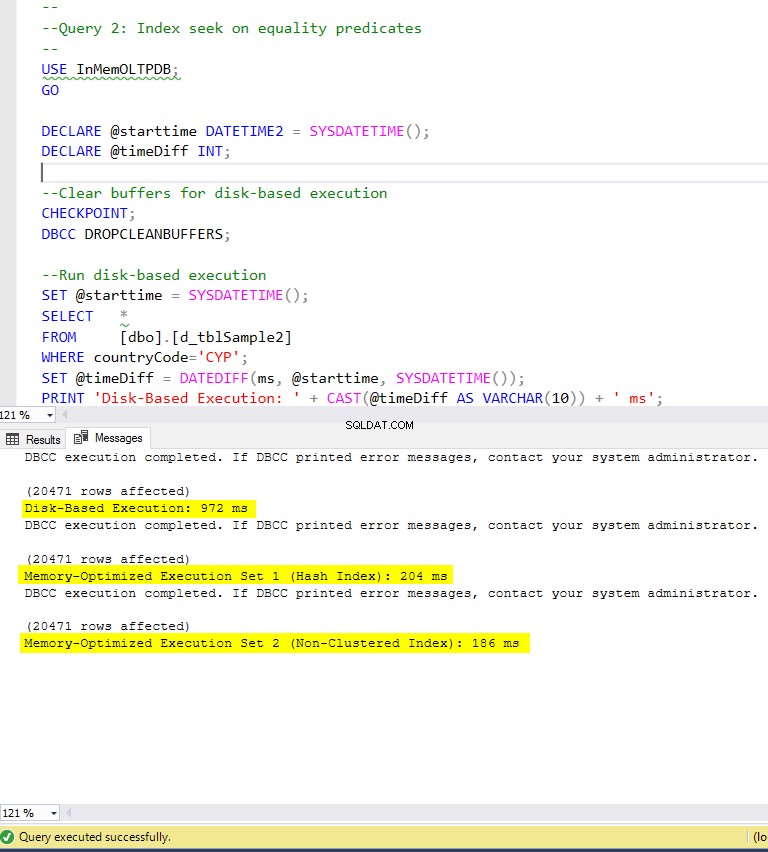
Figur 6:Forespørgsel 2-udførelsestid (med indekser).
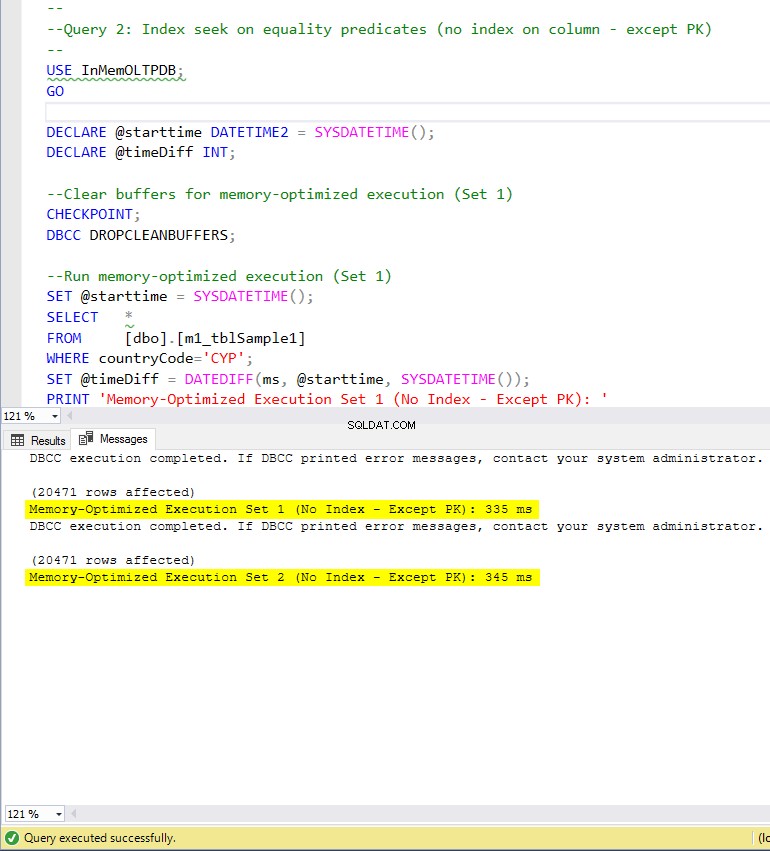
Figur 7:Forespørgsel 2-udførelsestid (uden indekser – undtagen PK).
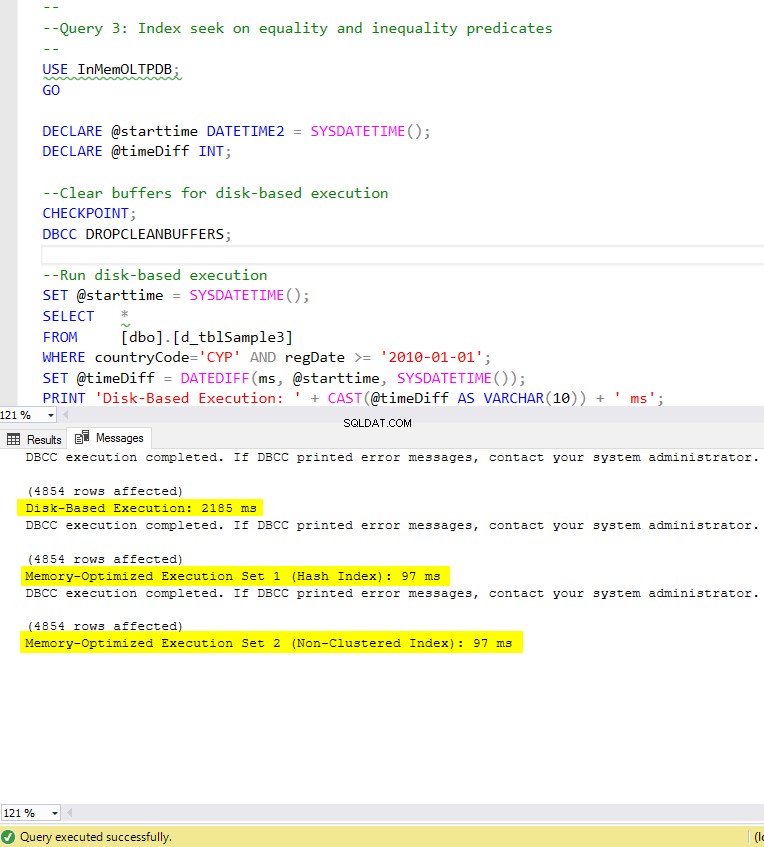
Figur 8:Forespørgsel 3-udførelsestid (med indekser).
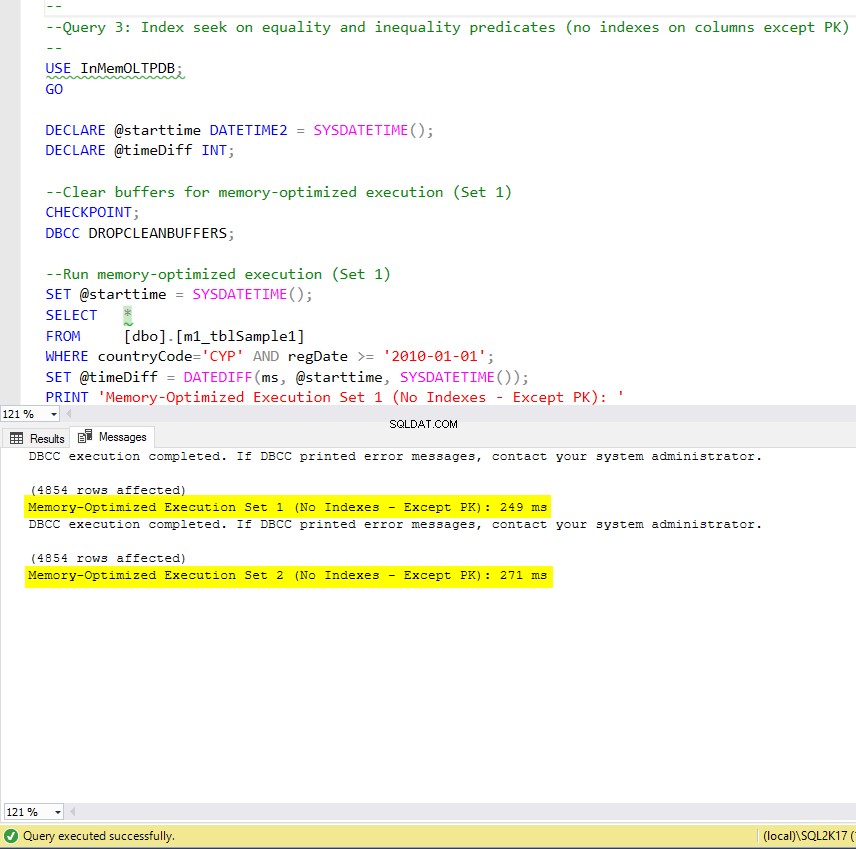
Figur 9:Forespørgsel 3-udførelsestid (uden indekser – undtagen PK).
Lad os nu opsummere resultaterne opnået ovenfor. Følgende tabel viser de målte udførelsestider for alle ovenstående forespørgsler og tabel/indekskombinationer.
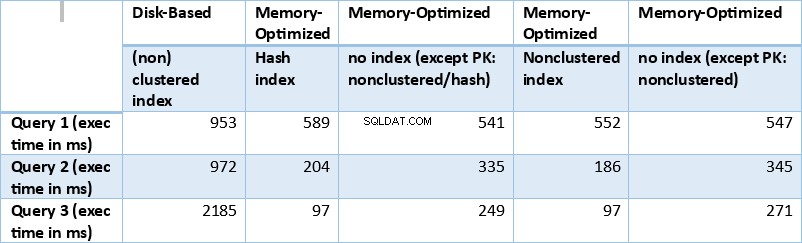
Tabel 1:Oversigt over udførelsestider (ms) for alle forespørgsler.
Diskussion
Hvis vi undersøger udførelsesresultaterne opsummeret i tabellen ovenfor, kan vi nå frem til visse konklusioner. Lad os plotte hvert forespørgselsresultat ind i en graf. Graferne nedenfor illustrerer udførelsestiderne samt hastigheden af de hukommelsesoptimerede tabeller i forhold til de diskbaserede tabeller.
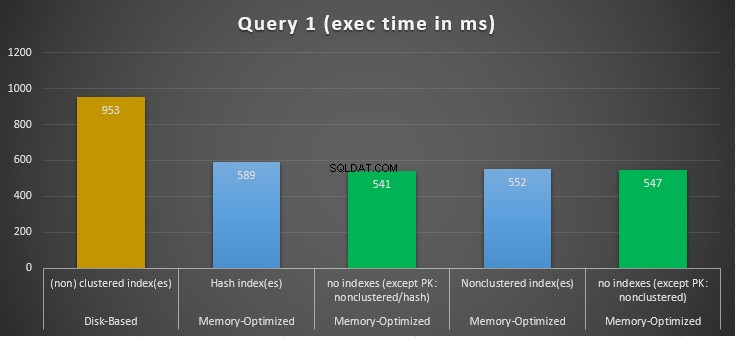
Figur 10:Forespørgsel 1 sammenligning af eksekveringstider.
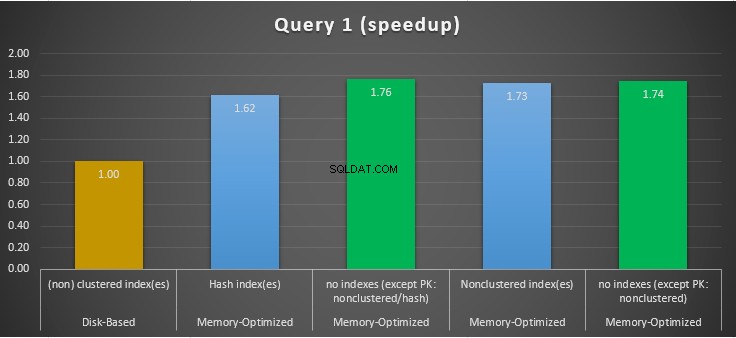
Figur 11:Forespørgsel 1 Speedup-sammenligning.
Med hensyn til forespørgsel 1, som var en GROUP BY aggregering, kan vi se, at begge versioner (indekser vs ingen indekser) af hukommelsesoptimerede tabeller, udfører næsten det samme med en speedup over den diskbaserede tabel (aktiveret med indekser) mellem 1,62 og 1,76 gange hurtigere.
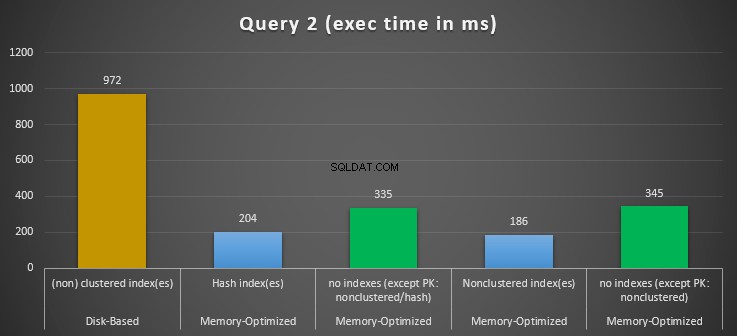
Figur 12:Forespørgsel 2 sammenligning af eksekveringstider.
Figur 13:Forespørgsel 2 Speedup-sammenligning.
Med hensyn til forespørgsel 2, som involverede en indekssøgning på lighedsprædikater, kan vi se, at de hukommelsesoptimerede tabeller med indeks klarede sig meget bedre end de hukommelsesoptimerede tabeller uden indekser. Desuden observerer vi, at den hukommelsesoptimerede tabel med ikke-klyngede indeks i kolonnen brugt som prædikat klarede sig bedre end den med hash-indekset.
Så for forespørgsel 2 er vinderen den hukommelsesoptimerede tabel med det ikke-klyngede indeks, der har en samlet speedup på 5,23 gange hurtigere end disk-baseret udførelse.
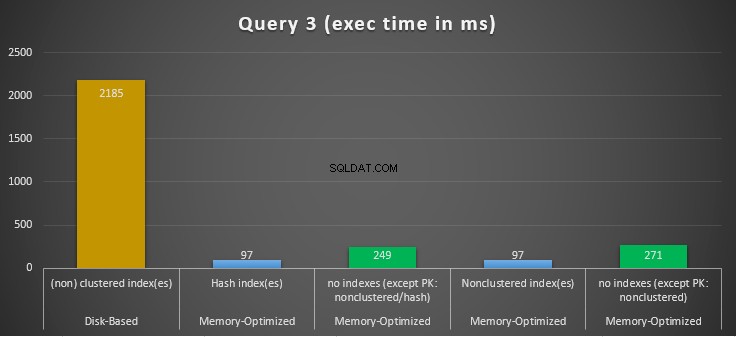
Figur 14:Forespørgsel 3 sammenligning af eksekveringstider.
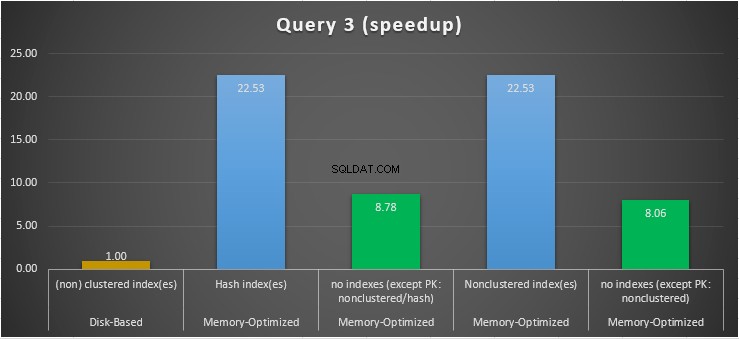
Figur 15:Forespørgsel 3 Speedup-sammenligning.
Med hensyn til forespørgsel 3, som involverede en indekssøgning på ligheds- og ulighedsprædikater kombineret, kan vi se, at de hukommelsesoptimerede tabeller med indekser klarede sig langt bedre end de hukommelsesoptimerede tabeller uden indekser. Desuden observerer vi, at den hukommelsesoptimerede tabel med ikke-klyngede indeks i kolonnen brugt som prædikat udførte det samme som den med hash-indekset.
Til dette formål kan vi se, at begge hukommelsesoptimerede tabeller, der gør brug af indekser i de kolonner, der bruges som prædikater, klarede sig hurtigere end dem uden indekser og opnåede en fremskyndelse på 22,53 gange hurtigere over disk-baseret udførelse.
Konklusion
I denne artikel undersøgte vi brugen af indekser i hukommelsesoptimerede tabeller i SQL Server. Vi brugte som basislinje for hver forespørgsel den bedst mulige diskbaserede tabelkonfiguration, og derefter sammenlignede vi ydeevnen af tre forespørgsler med de diskbaserede tabeller og 4 variationer af hukommelsesoptimerede tabeller. To ud af fire hukommelsesoptimerede tabeller brugte indekser (hash/ikke-klyngede) og de to andre brugte ingen indekser, undtagen dem der blev brugt til primærnøglerne.
Den overordnede konklusion er, at du altid skal undersøge, hvordan indekser påvirker ydeevnen, ikke kun for hukommelsesoptimerede tabeller, men også for diskbaserede, og når du identificerer, at de forbedrer ydeevnen, for at bruge dem. Resultaterne af denne artikels eksempler viser, at hvis du gør brug af de rigtige indekser i hukommelsesoptimerede tabeller, kan du opnå meget bedre ydeevne for forespørgsler svarende til dem, der er brugt i denne artikel sammenlignet med blot at bruge hukommelsesoptimerede tabeller uden indekser .
Referencer og yderligere læsning:
- Microsoft Docs:Hukommelsesoptimerede tabeller
- Microsoft Docs:Retningslinjer for brug af indekser på hukommelsesoptimerede tabeller
- Microsoft Docs:Indekser på hukommelsesoptimerede tabeller
Nyttigt værktøj:
dbForge Index Manager – praktisk SSMS-tilføjelse til at analysere status for SQL-indekser og løse problemer med indeksfragmentering.