Hvilke problemer vil vi overveje?
Hvis serveren giver besked "der er ikke mere plads på E-drevet" - er der ingen dyb analyse nødvendig. Vi vil ikke overveje fejl, hvis løsning er tydelig fra teksten i meddelelsen, og som Google straks sender et link til MSDN med løsningen for.
Lad os undersøge de problemer, som ikke er indlysende for Google, såsom for eksempel et pludseligt fald i ydeevne eller fravær af forbindelse. Overvej de vigtigste værktøjer til tilpasning og analyse. Lad os se, hvor logfilerne og andre nyttige oplysninger er placeret. Faktisk vil jeg prøve at samle alle de nødvendige oplysninger i én artikel for en hurtig start.
Først og fremmest
Vi starter med de mest hyppige spørgsmål og overvejer dem separat.
Hvis din database pludselig, uden tilsyneladende grund, begyndte at arbejde langsomt, men du ikke havde ændret noget - først og fremmest, opdater statistikken og genopbygg indekserne.
På internettet er der masser af metoder som denne, eksempler på scripts er givet. Jeg vil antage, at alle disse metoder er for professionelle. Nå, jeg vil beskrive den enkleste måde:du behøver kun en mus til at implementere det.
Forkortelser
- SSMS er en applikation af Microsoft SQL Server Management Studio. Fra 2016-versionen er den tilgængelig gratis på MS-webstedet som en selvstændig applikation. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler er en applikation af "SQL Server Profiler" installeret med SSMS.
- Performance Monitor er et snap-in til kontrolpanelet, der giver dig mulighed for at overvåge ydeevnetællerne, logge og se historikken for målinger.
Statistikopdatering ved hjælp af en "serviceplan":
- kør SSMS;
- opret forbindelse til en påkrævet server;
- udvid træet i Object Inspector:Management\Maintenance Plans (Service Plans);
- højreklik på noden, og vælg "Vedligeholdelsesplan Wizard";
- i guiden skal du markere de nødvendige opgaver:genopbygge indeks og opdatere statistik
- du kan markere begge opgaver på én gang eller lave to vedligeholdelsesplaner med én opgave i hver (se de "vigtige bemærkninger" nedenfor);
- Yderligere kontrollerer vi en påkrævet DB (eller flere databaser). Vi gør dette for hver opgave (hvis der vælges to opgaver, vil der være to dialogbokse med valg af database);
- Næste, Næste, Udfør.
Efter disse handlinger vil en "vedligeholdelsesplan" blive oprettet (ikke udført). Du kan køre det manuelt ved at højreklikke på det og vælge "Udfør". Alternativt kan du konfigurere lanceringen via SQL Agent.
Vigtige bemærkninger:
- Opdatering af statistik er en ikke-blokerende handling. Du kan udføre det i en arbejdstilstand.
- Genopbygning af indeks er en blokerende handling. Du kan kun køre den uden for arbejdstiden. Der er en undtagelse - Enterprise-udgaven af serveren tillader udførelse af en "online genopbygning". Denne mulighed kan aktiveres i opgaveindstillingerne. Bemærk venligst, at der er et flueben i alle udgaver, men det virker kun i Enterprise.
- Selvfølgelig skal disse opgaver udføres regelmæssigt. Jeg foreslår en nem måde at bestemme, hvor ofte du gør dette:
– Med de første problemer, udfør vedligeholdelsesplanen;
– Hvis det hjalp, vent, indtil problemerne opstår igen (normalt indtil næste månedlige afslutning/lønberegning/ osv. af bulktransaktioner);
– Den resulterende periode for en normal operation vil være dit referencepunkt;
– Konfigurer f.eks. udførelsen af vedligeholdelsesplanen dobbelt så ofte.
Serveren er langsom – hvad skal du gøre?
De ressourcer, der bruges af serveren
Som ethvert andet program har serveren brug for processortid, data på disken, mængden af RAM og netværksbåndbredde.
Task Manager hjælper dig med at vurdere manglen på en given ressource i den første tilnærmelse, uanset hvor forfærdeligt det kan lyde.
CPU Indlæs
Selv en skoledreng kan tjekke udnyttelsen i Manageren. Vi skal bare sikre os, at hvis processoren er indlæst, så er det sqlserver.exe-processen.
Hvis dette er dit tilfælde, skal du gå til analysen af brugeraktivitet for at forstå, hvad der præcist forårsagede belastningen (se nedenfor).
Disk Loa d
Mange mennesker ser kun på CPU-belastningen, men glemmer, at DBMS er et datalager. Datamængderne vokser, processorydelsen stiger, mens HDD-hastigheden stort set er den samme. Med SSD'er er situationen bedre, men det er dyrt at gemme terabyte på dem.
Det viser sig, at jeg ofte støder på situationer, hvor disksystemet bliver flaskehalsen i stedet for CPU'en.
For diske er følgende metrics vigtige:
- gennemsnitlig kølængde (udestående I/O-operationer, antal);
- læse-skrivehastighed (i Mb/s).
Serverversionen af Task Manager viser som regel begge dele (afhængigt af systemversionen). Hvis ikke, skal du køre snap-in'en Performance Monitor (systemmonitor). Vi er interesserede i følgende tællere:
- Fysisk (logisk) disk/gennemsnitlig læse- (skrive)tid
- Fysisk (logisk) disk/gennemsnitlig diskkølængde
- Fysisk (logisk) disk/diskhastighed
For flere detaljer kan du læse producentens manualer, for eksempel her:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Kort sagt:
- Køen bør ikke overstige 1. Korte bursts er tilladt, hvis de hurtigt aftager. Bursts kan være forskellige afhængigt af dit system. For et simpelt RAID-spejl af to HDD'er - køen på mere end 10-20 er et problem. For et sejt bibliotek med super caching så jeg byger på op til 600-800, som blev løst øjeblikkeligt uden at forårsage forsinkelser.
- Den normale vekselkurs afhænger også af typen af et disksystem. Den sædvanlige (desktop) HDD sender med 50-100 MB/s. Et godt diskbibliotek – med 500 MB/s og mere. For små tilfældige operationer er hastigheden mindre. Dette kan være dit referencepunkt.
- Disse parametre skal betragtes som en helhed. Hvis dit bibliotek transmitterer 50MB/s og en kø på 50 operationer står i kø - er der naturligvis noget galt med hardwaren. Hvis køen står i kø, når transmissionen er tæt på et maksimum – højst sandsynligt er det ikke diskene, der skal bebrejdes – de kan bare ikke gøre mere – skal vi se efter en måde at reducere belastningen på.
- Indlæsningen skal kontrolleres separat på diske (hvis der er flere af dem) og sammenlignes med placeringen af serverfiler. Task Manager kan vise de mest aktivt brugte filer. Dette kan bruges til at sikre, at belastningen er forårsaget af DBMS.
Hvad kan forårsage disksystemproblemer:
- problemer med hardware
- cachen brændte ud, ydeevnen faldt dramatisk;
- disksystemet bruges af noget andet;
- Mangel på RAM. Bytte. Сaching faldt, ydeevne faldt (se afsnittet om RAM nedenfor).
- Brugerbelastningen er øget. Det er nødvendigt at evaluere brugernes arbejde (problematisk forespørgsel/ny funktionalitet/stigning i antallet af brugere/stigning i mængden af data/osv).
- Databasedatafragmentering (se indeksgenopbygningen ovenfor), systemfilfragmentering.
- Disksystemet har nået sine maksimale muligheder.
I tilfælde af den sidste mulighed – smid ikke hardwaren ud med det samme. Nogle gange kan du få lidt mere ud af systemet, hvis du griber problemet klogt an. Kontroller placeringen af systemfilerne for overholdelse af de anbefalede krav:
- Bland ikke OS-filer med databasedatafiler. Gem dem på forskellige fysiske medier, så systemet ikke konkurrerer med DBMS til I/O.
- Databasen består af to filtyper:data (*.mdf, *.ndf) og logfiler (*.ldf).
Datafiler bruges som regel mest til læsning. Logs tjener til skrivning (hvor skrivningen er fortløbende). Det anbefales derfor at gemme logfiler og data på forskellige fysiske medier, så logningen ikke afbryder datalæsningen (som regel har skriveoperationen forrang frem for læsning). - MS SQL kan bruge "midlertidige tabeller" til forespørgselsbehandling. De er gemt i tempdb systemdatabasen. Hvis du har en høj belastning af filer i denne database, kan du prøve at gengive den på fysisk adskilte medier.
Opsummering af problemet med filplacering, brug princippet om "del og hersk". Evaluer, hvilke filer der er adgang til, og prøv at distribuere dem til forskellige medier. Brug også funktionerne i RAID-systemer. For eksempel er RAID-5-læsninger hurtigere end skrivninger – hvilket er godt for datafiler.
Lad os undersøge, hvordan man henter information om brugerens ydeevne:hvem laver hvad, og hvor mange ressourcer der forbruges
Jeg opdelte opgaver med revision af brugeraktivitet i følgende grupper:
- Opgaver med at analysere en bestemt anmodning.
- Opgaver med at analysere belastning fra applikationen under specifikke forhold (f.eks. når en bruger klikker på en knap i en tredjepartsapplikation, der er kompatibel med databasen).
- Opgaver med at analysere den aktuelle situation.
Lad os overveje hver af dem i detaljer.
Advarsel
Ydeevneanalysen kræver en dyb forståelse af strukturen og principperne for driften af databaseserveren og operativsystemet. Derfor vil læsning af kun disse artikler ikke gøre dig til en professionel.
De overvejede kriterier og tællere i rigtige systemer afhænger meget af hinanden. For eksempel er en høj HDD-belastning ofte forårsaget af mangel på RAM. Selvom du foretager nogle målinger, er dette ikke nok til at vurdere problemerne rimeligt.
Formålet med artiklerne er at introducere det væsentlige om simple eksempler. Du bør ikke betragte mine anbefalinger som en guide. Jeg anbefaler, at du bruger dem som træningsopgaver, der kan forklare tankestrømmen.
Jeg håber, at du vil lære, hvordan du rationaliserer dine konklusioner om serverens ydeevne i tal.
I stedet for at sige "serveren sænker farten", vil du angive specifikke værdier af specifikke indikatorer.
Analyser et P artikulær R equest
Det første punkt er ret simpelt, lad os dvæle ved det kort. Vi vil overveje nogle mindre indlysende problemer.
Ud over forespørgselsresultater giver SSMS mulighed for at hente yderligere oplysninger om forespørgselsudførelsen:
- Du kan få forespørgselsplanen ved at klikke på knapperne "Vis estimeret eksekveringsplan" og "Inkluder faktisk eksekveringsplan". Forskellen mellem dem er, at estimeringsplanen er bygget uden en forespørgselsudførelse. Således vil oplysningerne om antallet af behandlede rækker blive estimeret. I selve planen vil der være både estimerede og faktiske data. Stærke uoverensstemmelser mellem disse værdier indikerer, at statistikken ikke er relevant. Analysen af planen er dog et emne for en anden artikel – indtil videre vil vi ikke gå dybere.
- Vi kan få målinger af processoromkostninger og diskdrift af serveren. For at gøre dette er det nødvendigt at aktivere indstillingen SET. Du kan gøre det enten i dialogboksen 'Forespørgselsindstillinger' som denne:
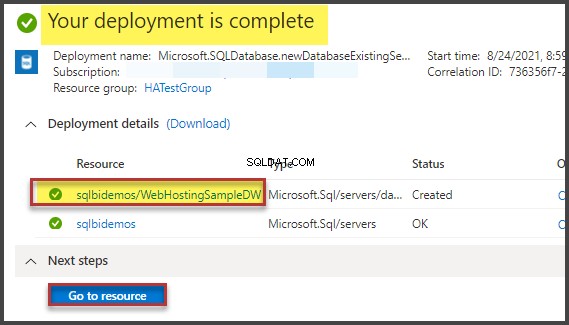
Eller med de direkte SET-kommandoer i forespørgslen:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDSom et resultat vil vi få data om den tid, der bruges på kompilering og eksekvering, samt antallet af diskoperationer.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Jeg vil gerne henlede din opmærksomhed på kompileringstiden, logiske læsninger 96 og fysiske læsninger 5. Når du udfører den samme forespørgsel for anden gang og senere, kan fysiske læsninger falde, og rekompilering er muligvis ikke påkrævet. På grund af denne kendsgerning sker det ofte, at forespørgslen udføres hurtigere under den anden og efterfølgende gange end den første gang. Årsagen er, som du forstår, i cachelagring af data og kompilerede forespørgselsplaner.
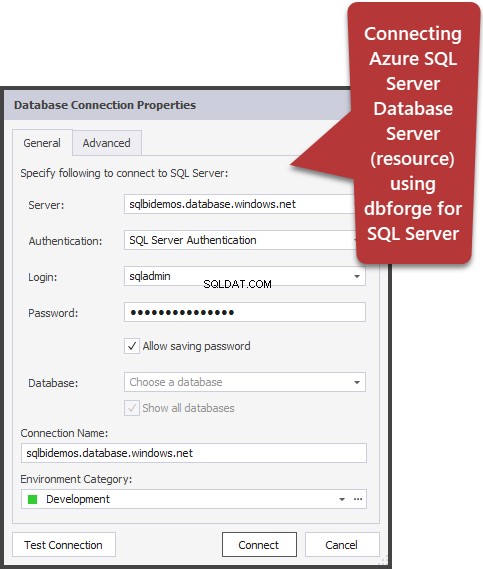
- Knappen «Inkluder klientstatistik» viser oplysningerne om netværksudveksling, mængden af udførte operationer og den samlede eksekveringstid, inklusive omkostningerne ved netværksudveksling og behandling af en klient. Eksemplet viser, at det tager længere tid at udføre forespørgslen for første gang:
- I SSMS 2016 er der knappen «Inkluder Live Query Statistics»-knappen. Den viser billedet som i tilfældet med forespørgselsplanen, men indeholder de ikke-tilfældige cifre i de behandlede rækker, som ændres på skærmen, mens forespørgslen udføres. Billedet er meget tydeligt – blinkende pile og løbende tal, kan du med det samme se, hvor tiden er spildt. Knappen virker også til SQL Server 2014 og nyere.
For at opsummere:
- Tjek CPU-omkostningerne ved at bruge SET STATISTICS TIME ON.
- Diskhandlinger:INDSTILL STATISTIK IO TIL. Glem ikke, at logisk læsning er en læseoperation, der udføres i diskcachen uden fysisk adgang til disksystemet. "Fysisk læsning" tager meget mere tid.
- Evaluer mængden af netværkstrafik ved hjælp af «Inkluder klientstatistikker».
- Analyser algoritmen til at udføre forespørgslen ved hjælp af eksekveringsplanen ved hjælp af «Inkluder faktisk eksekveringsplan» og «Inkluder statistikker for live-forespørgsler».
Analyser applikationsbelastningen
Her vil vi bruge SQL Server Profiler. Efter lancering og forbindelse til serveren er det nødvendigt at vælge loghændelser. For at gøre dette skal du køre profilering med en standard sporingsskabelon. På Generelt fanen i Brug skabelonen skal du vælge Standard (standard) og klik på Kør .
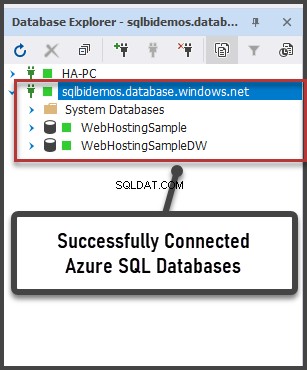
Den mere komplicerede måde er at tilføje/slippe filtre eller begivenheder til/fra den valgte skabelon. Disse muligheder kan findes på den anden fane i dialogmenuen. For at se hele rækken af mulige begivenheder og kolonner at vælge, skal du vælge Vis alle begivenheder og Vis alle kolonner afkrydsningsfelter.

Vi skal bruge følgende begivenheder:
- Lagrede procedurer \ RPC:Completed
- TSQL \ SQL:BatchCompleted
Disse hændelser overvåger alle eksterne SQL-kald til serveren. De vises efter afslutningen af forespørgselsbehandlingen. Der er lignende hændelser, der holder styr på SQL Server-starten:
- Lagrede procedurer \ RPC:Starter
- TSQL \ SQL:BatchStarting
Vi har dog ikke brug for disse procedurer, da de ikke indeholder information om de serverressourcer, der er brugt på udførelse af forespørgslen. Det er indlysende, at sådanne oplysninger først er tilgængelige efter afslutningen af eksekveringsprocessen. Således vil kolonner med data om CPU, Læser, Skriver i *Starthændelser være tomme.
Følgende begivenheder kan også interessere os, men vi vil ikke aktivere dem indtil videre:
- Stored Procedures \ SP:Starting (*Completed) overvåger det interne opkald til den lagrede procedure, ikke fra klienten, men inden for den aktuelle anmodning eller anden procedure.
- Stored Procedures \ SP:StmtStarting (*Completed) sporer starten af hver sætning i den lagrede procedure. Hvis der er en cyklus i proceduren, vil antallet af hændelser for kommandoerne i cyklussen svare til antallet af iterationer i cyklussen.
- TSQL \ SQL:StmtStarting (*Completed) overvåger starten af hver sætning i SQL-batchen. Hvis der er flere kommandoer i din forespørgsel, vil hver af dem indeholde én hændelse. Det fungerer således for de kommandoer, der findes i forespørgslen.
Disse hændelser er praktiske til at overvåge udførelsesprocessen.
Af C olumner
Hvilke kolonner der skal vælges fremgår tydeligt af knappens navn. Vi skal bruge følgende:
- TextData, BinaryData indeholder forespørgselsteksten.
- CPU, læsning, skrivning, varighed viser ressourceforbrugsdata.
- StartTime, EndTime er tidspunktet for at starte og afslutte udførelsesprocessen. De er praktiske til sortering.
Tilføj andre kolonner baseret på dine præferencer.
Kolonnefiltrene... knappen åbner dialogboksen til konfiguration af hændelsesfiltre. Hvis du er interesseret i den pågældende brugers aktivitet, kan du indstille filteret efter SID-nummeret eller brugernavnet. Desværre bliver overvågningen af den pågældende bruger mere kompliceret i tilfælde af at forbinde appen gennem app-serveren med træk af forbindelser.
Du kan bruge filtre til kun at vælge komplicerede forespørgsler (Varighed>X), forespørgsler, der forårsager intensiv skrivning (Writes>Y), samt valg af forespørgselsindhold osv.
Hvad har vi ellers brug for fra profileren? Selvfølgelig, udførelsesplanen!
Det er nødvendigt at tilføje hændelsen «Performance \ Showplan XML Statistics Profile» til sporingen. Mens vi udfører vores forespørgsel, får vi følgende billede:
Forespørgselsteksten:
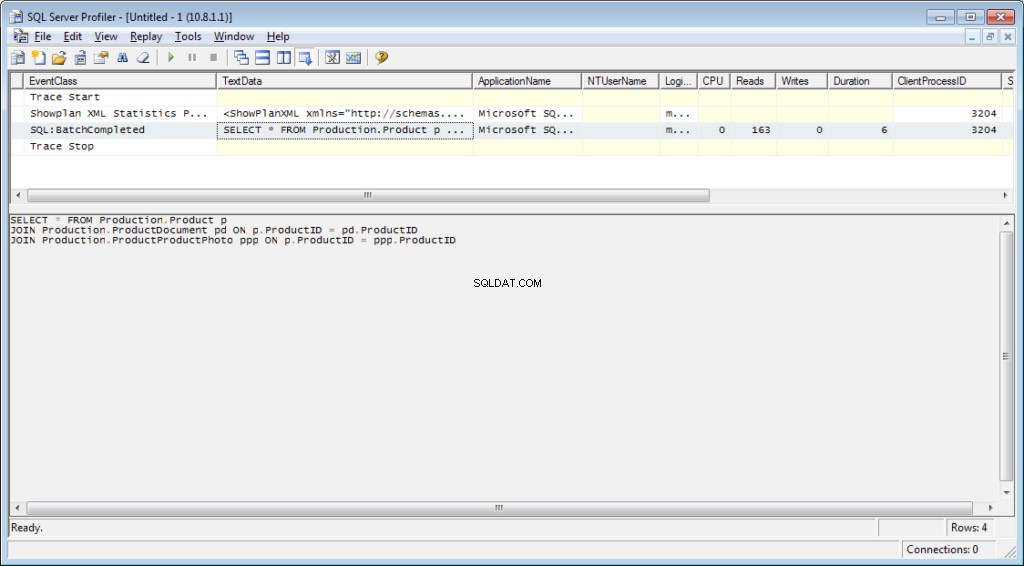
Udførelsesplanen:
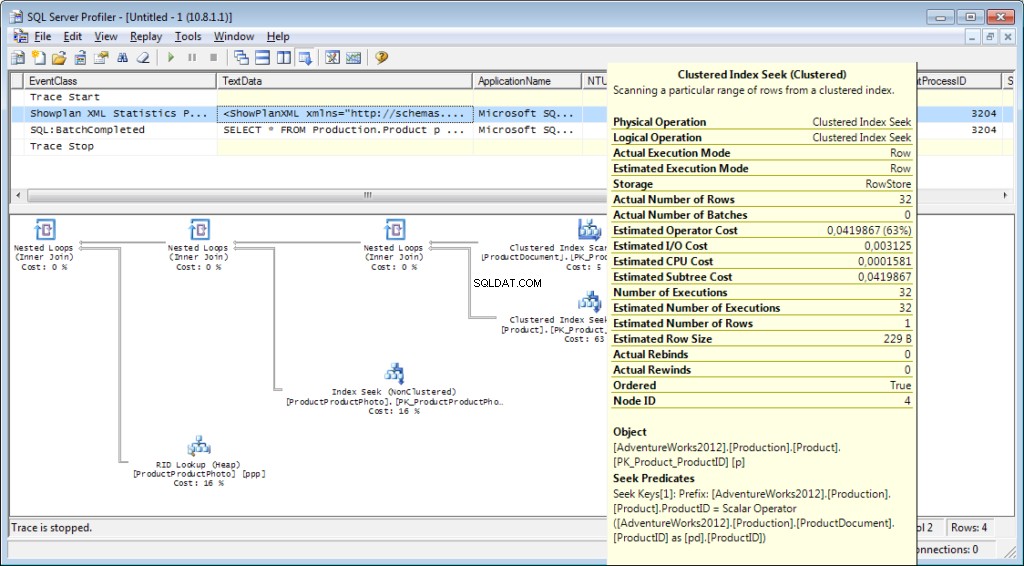
Og det er ikke alt
Det er muligt at gemme et spor til en fil eller en databasetabel. Sporingsindstillinger kan gemmes som en personlig skabelon til en hurtig løbetur. Du kan køre sporingen uden en profiler ved blot at bruge en T-SQL-kode og procedurerne sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Du kan finde et eksempel her. Denne tilgang kan f.eks. være nyttig til automatisk at begynde at gemme et spor til en fil på en tidsplan. Du kan få et sneaky peak på profileren for at se, hvordan du bruger disse kommandoer. Du kan køre to spor og i et af dem spore, hvad der sker, når det andet starter. Tjek, at der ikke er noget filter ved "ApplicationName"-kolonnen på selve profileren.
Listen over begivenheder, der overvåges af profileren, er meget stor og er ikke begrænset til modtagelse af forespørgselstekster. Der er begivenheder, der sporer fuldscanning, genkompilering, autogrow, deadlock og meget mere.
Analyse af brugeraktivitet på serveren
Der er forskellige situationer. En forespørgsel kan hænge på 'udførelse' i lang tid, og det er uklart, om den bliver gennemført eller ej. Jeg vil gerne analysere den problematiske forespørgsel separat; vi skal dog først fastslå, hvad forespørgslen er. Det er nytteløst at fange det med en profiler – vi har allerede misset startbegivenheden, og det er ikke klart, hvor længe vi skal vente på, at processen er afsluttet.
Lad os finde ud af det
Du har måske hørt om 'Activity Monitor'. Dens højere udgaver har virkelig rig funktionalitet. Hvordan kan det hjælpe os? Activity Monitor indeholder mange nyttige og interessante funktioner. Vi får alt, hvad vi har brug for fra systemvisninger og funktioner. Monitor i sig selv er nyttig, fordi du kan indstille profileren på den og se, hvilke forespørgsler den udfører.
Vi skal bruge:
- dm_exec_sessions giver oplysninger om sessioner for tilsluttede brugere. I vores artikel er de nyttige felter dem, der identificerer en bruger (login_name, login_time, host_name, program_name, …) og felter med informationen om brugte ressourcer (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests giver oplysninger om forespørgsler, der udføres i øjeblikket.
- session_id er en identifikator for sessionen, der skal linkes til den forrige visning.
- start_tid er tidspunktet for visningen.
- kommando er et felt, der indeholder en type af den udførte kommando. For brugerforespørgsler er det vælg/opdater/slet/
- sql_handle, statement_start_offset, statement_end_offset giver information til at hente forespørgselstekst:handle, samt start- og slutpositionen i forespørgslens tekst, hvilket betyder den del, der aktuelt udføres (i det tilfælde, hvor din forespørgsel indeholder flere kommandoer).
- plan_handle er et håndtag af den genererede plan.
- blocking_session_id angiver nummeret på den session, der forårsagede blokering, hvis der er blokeringer, der forhindrer udførelsen af forespørgslen
- wait_type, wait_time, wait_resource er felter med oplysninger om årsagen til og varigheden af ventetiden. For nogle typer ventetider, for eksempel datalås, er det nødvendigt yderligere at angive en kode for den blokerede ressource.
- percent_complete er fuldførelsesprocenten. Desværre er det kun tilgængeligt for kommandoer med en klart forudsigelig fremgang (for eksempel sikkerhedskopiering eller gendannelse).
- cpu_time, reads, writes, logical_reads, granted_query_memory er ressourceomkostninger.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) er funktioner til at hente teksten og udførelsesplanen. Nedenfor vil vi se på et eksempel på dets brug.
- dm_exec_query_stats er en opsummerende statistik over udførelse af forespørgsler. Den viser forespørgslen, antallet af dens eksekveringer og mængden af brugte ressourcer.
Vigtige bemærkninger
Ovenstående liste er kun en lille del. En komplet liste over alle systemvisninger og funktioner er beskrevet i dokumentationen. Der er også et smukt billede, der viser et diagram over forbindelser mellem hovedobjekterne.
Forespørgselsteksten, dens plan og udførelsesstatistikker er data, der er gemt i procedurecachen. De er tilgængelige under udførelsen. Så er tilgængelighed ikke garanteret og afhænger af cachebelastningen. Ja, cachen kan renses manuelt. Nogle gange anbefales det, når eksekveringsplanerne 'flippede ud'. Alligevel er der mange nuancer.
"Kommando"-feltet er meningsløst for brugeranmodninger, da vi kan få den fulde tekst. Det er dog meget vigtigt for at få information om systemprocesser. Som regel udfører de nogle interne opgaver og har ikke SQL-teksten. For sådanne processer er informationen om kommandoen den eneste antydning af aktivitetstypen.
I kommentarerne til den forrige artikel var der et spørgsmål om, hvad serveren er involveret i, når den ikke burde virke. Svaret vil sandsynligvis være i betydningen af dette felt. I min praksis gav "kommando"-feltet altid noget ganske forståeligt for aktive systemprocesser:autoshrink / autogrow / checkpoint / logwriter / etc.
Sådan bruges det
Vi vil gå til den praktiske del. Jeg vil give flere eksempler på dets brug. Servermulighederne er ikke begrænsede – du kan tænke på dine egne eksempler.
Eksempel 1. Hvilken proces bruger CPU/læser/skriver/hukommelse
Først skal du tage et kig på de sessioner, der bruger flere ressourcer, for eksempel CPU. Du kan finde disse oplysninger i sys.dm_exec_sessions. Data om CPU, inklusive læsninger og skrivninger, er dog kumulative. Det betyder, at tallet indeholder totalen for hele forbindelsestiden. Det er klart, at den bruger, der oprettede forbindelse for en måned siden og ikke blev afbrudt, vil have en højere værdi. Det betyder ikke, at de overbelaster systemet.
En kode med følgende algoritme kan løse dette problem:
- Foretag et valg, og gem det i en midlertidig tabel
- Vent et stykke tid
- Foretag et valg for anden gang
- Sammenlign disse resultater. Deres forskel vil angive omkostninger brugt på trin 2.
- For nemheds skyld kan forskellen divideres med varigheden af trin 2 for at opnå de gennemsnitlige "omkostninger pr. sekund".
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Jeg bruger to tabeller i koden:#tmp – til det første valg, og #tmp1 – til det andet. Under den første kørsel opretter og udfylder scriptet #tmp og #tmp1 med et interval på et sekund og udfører derefter andre opgaver. Med de næste kørsler bruger scriptet resultaterne af den tidligere udførelse som sammenligningsgrundlag. Således vil varigheden af trin 2 være lig med varigheden af din ventetid mellem scriptkørslerne.
Prøv at udføre det, selv på produktionsserveren. Scriptet vil kun oprette "midlertidige tabeller" (tilgængelige i den aktuelle session og slettes, når de er deaktiveret) og har ingen tråd.
De, der ikke kan lide at udføre en forespørgsel i MS SSMS, kan pakke den ind i en applikation skrevet på deres foretrukne programmeringssprog. Jeg viser dig, hvordan du gør dette i MS Excel uden en enkelt kodelinje.
I menuen Data skal du oprette forbindelse til serveren. Hvis du bliver bedt om at vælge en tabel, skal du vælge en tilfældig. Klik på Næste og Udfør, indtil du ser dialogboksen Dataimport. I det vindue skal du klikke på Egenskaber. I Egenskaber er det nødvendigt at erstatte en kommandotype med SQL-værdien og indsætte vores ændrede forespørgsel i kommandotekstfeltet.
Du bliver nødt til at ændre forespørgslen en lille smule:
- Tilføj «SET NOCOUNT ON»
- Erstat midlertidige tabeller med variable tabeller
- Forsinkelsen varer inden for 1 sek. Felter med gennemsnitsværdier er ikke påkrævet
Den ændrede forespørgsel til Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Resultat:
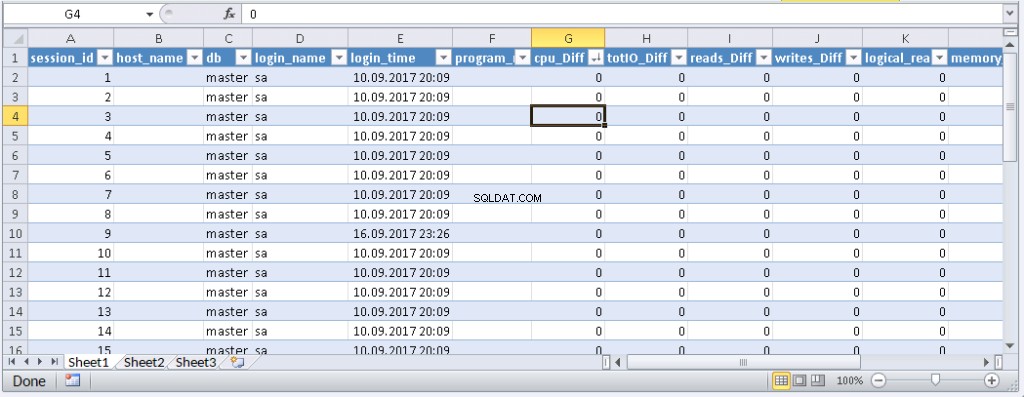
Når data vises i Excel, kan du sortere dem efter behov. For at opdatere oplysningerne skal du klikke på 'Opdater'. I projektmappeindstillingerne kan du sætte "automatisk opdatering" i et bestemt tidsrum og "opdater ved starten". Du kan gemme filen og videregive den til dine kolleger. Derfor har vi skabt et praktisk og enkelt værktøj.
Eksempel 2. Hvad bruger en session ressourcer på?
Nu skal vi afgøre, hvad problemsessionerne rent faktisk gør. For at gøre dette skal du bruge sys.dm_exec_requests og funktioner til at modtage forespørgselstekst og forespørgselsplan.
Forespørgslen og udførelsesplanen efter sessionsnummeret
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Indsæt sessionsnummeret i forespørgslen, og kør det. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.