
I denne artikel vil vi undersøge, hvornår og hvordan man bruger SQL PARTITION BY-udtrykket og sammenligne det med at bruge GROUP BY-udtrykket.
Forstå vinduesfunktionen
Databasebrugere bruger aggregerede funktioner såsom MAX(), MIN(), AVERAGE() og COUNT() til at udføre dataanalyse. Disse funktioner fungerer på en hel tabel og returnerer enkelte aggregerede data ved hjælp af GROUP BY-sætningen. Nogle gange kræver vi aggregerede værdier over et lille sæt rækker. I dette tilfælde hjælper Window-funktionen kombineret med aggregatfunktionen med at opnå det ønskede output. Window-funktionen bruger OVER()-sætningen, og den kan inkludere følgende funktioner:
- Partition af: Dette opdeler rækkerne eller forespørgselsresultatsættet i små partitioner.
- Bestil efter: Dette arrangerer rækkerne i stigende eller faldende rækkefølge for partitionsvinduet. Standardrækkefølgen er stigende.
- Række eller område: Du kan yderligere begrænse rækkerne i en partition ved at angive start- og slutpunkter.
I denne artikel vil vi fokusere på at udforske SQL PARTITION BY-sætningen.
Forberedelse af eksempeldata
Antag, at vi har en tabel [SalesLT].[Ordrer], der gemmer kundeordreoplysninger. Den har en kolonne [By], der angiver kundens by, hvor ordren blev afgivet.
CREATE TABLE [SalesLT].[Orders] ( orderid INT, orderdate DATE, customerName VARCHAR(100), City VARCHAR(50), amount MONEY ) INSERT INTO [SalesLT].[Orders] SELECT 1,'01/01/2021','Mohan Gupta','Alwar',10000 UNION ALL SELECT 2,'02/04/2021','Lucky Ali','Kota',20000 UNION ALL SELECT 3,'03/02/2021','Raj Kumar','Jaipur',5000 UNION ALL SELECT 4,'04/02/2021','Jyoti Kumari','Jaipur',15000 UNION ALL SELECT 5,'05/03/2021','Rahul Gupta','Jaipur',7000 UNION ALL SELECT 6,'06/04/2021','Mohan Kumar','Alwar',25000 UNION ALL SELECT 7,'07/02/2021','Kashish Agarwal','Alwar',15000 UNION ALL SELECT 8,'08/03/2021','Nagar Singh','Kota',2000 UNION ALL SELECT 9,'09/04/2021','Anil KG','Alwar',1000 Go
Lad os sige, at vi ønsker at kende den samlede ordreværdi efter sted (by). Til dette formål bruger vi funktionen SUM() og GROUP BY som vist nedenfor.
SELECT City AS CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] GROUP BY city ORDER BY city
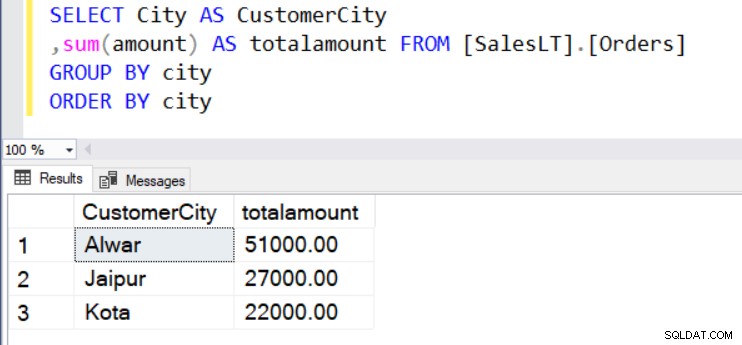
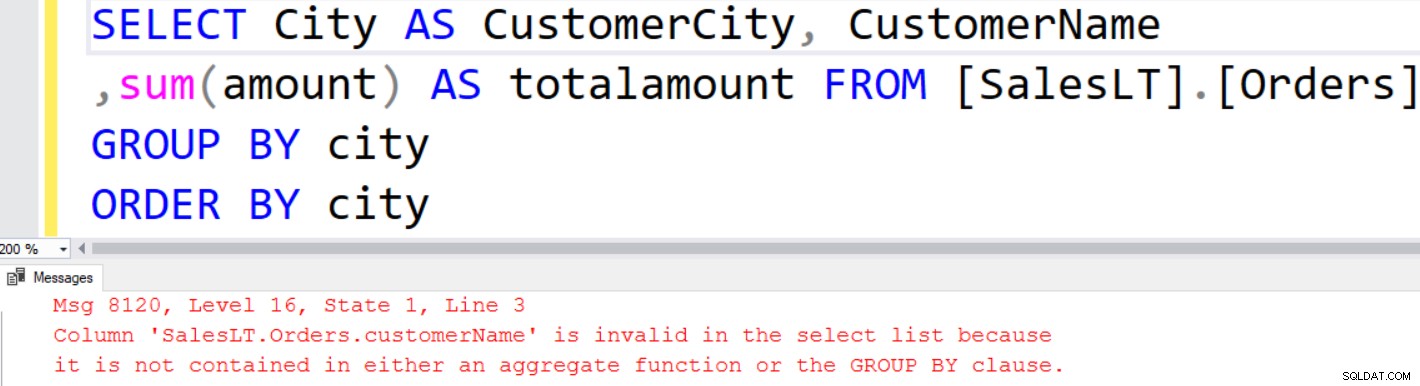
I resultatsættet kan vi ikke bruge de ikke-aggregerede kolonner i SELECT-sætningen. For eksempel kan vi ikke vise [CustomerName] i outputtet, fordi det ikke er inkluderet i GROUP BY-sætningen.
SQL Server giver følgende fejlmeddelelse, hvis du forsøger at bruge den ikke-aggregerede kolonne i kolonnelisten.
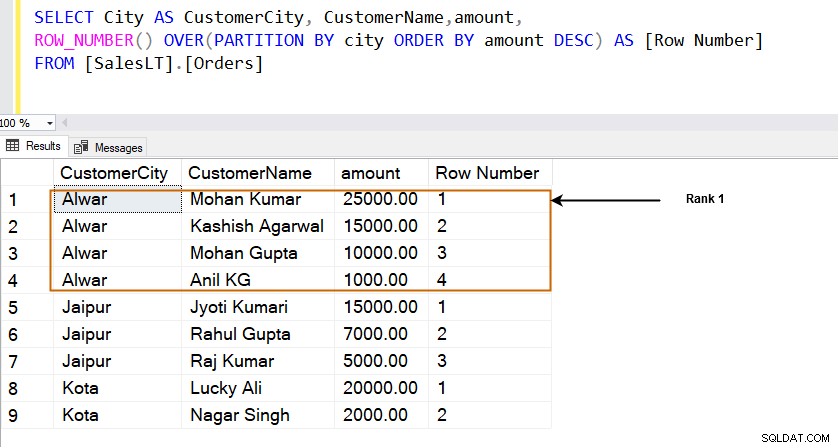
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount FROM [SalesLT].[Orders]
Som vist nedenfor opretter PARTITION BY-sætningen et mindre vindue (sæt af datarækker), udfører aggregeringen og viser den. Du kan også se ikke-aggregerede kolonner i dette output.
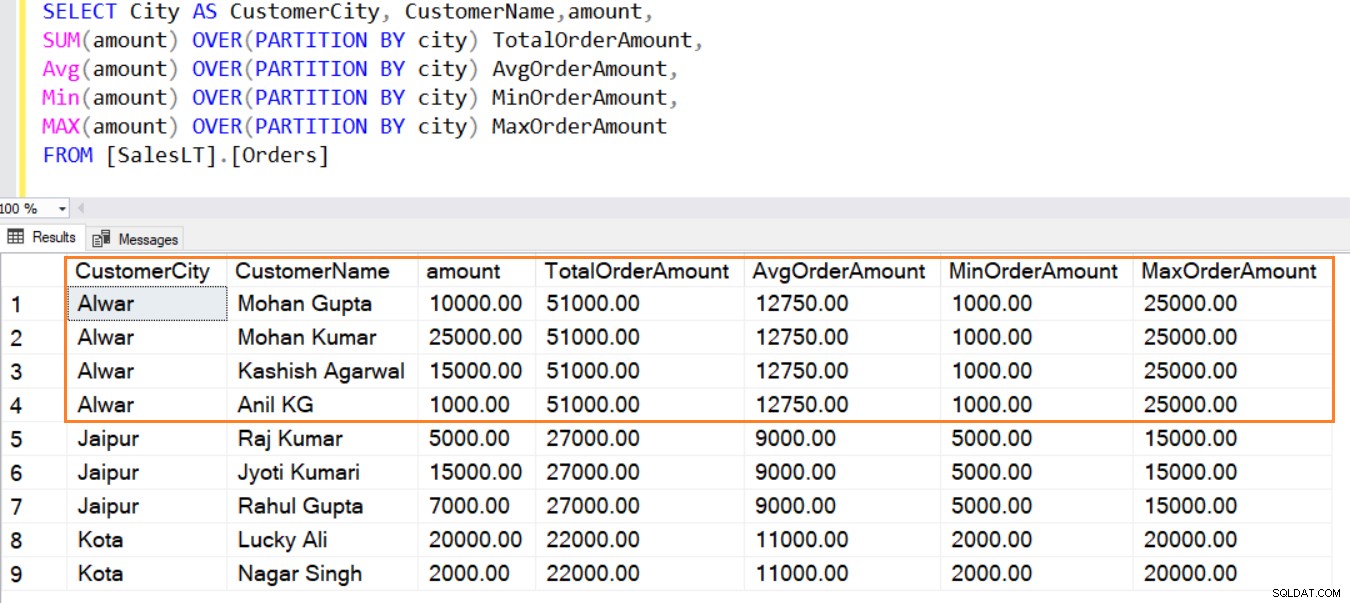
På samme måde kan du bruge funktionerne AVG(), MIN(), MAX() til at beregne gennemsnit, minimum og maksimum beløb fra rækkerne i et vindue.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount, Avg(amount) OVER(PARTITION BY city) AvgOrderAmount, Min(amount) OVER(PARTITION BY city) MinOrderAmount, MAX(amount) OVER(PARTITION BY city) MaxOrderAmount FROM [SalesLT].[Orders]
Brug af SQL PARTITION BY-udtrykket med funktionen ROW_NUMBER()
Tidligere fik vi de aggregerede værdier i et vindue ved hjælp af PARTITION BY-sætningen. Antag, at vi i stedet for totalen kræver den kumulative total i en partition.
En kumulativ total fungerer på følgende måder.
| Række | Akumuleret total |
| 1 | Ranger 1+2 |
| 2 | Ranger 2+3 |
| 3 | Ranger 3+4 |
Rækkerangeringen beregnes ved hjælp af funktionen ROW_NUMBER(). Lad os først bruge denne funktion og se rækkerne.
- ROW_NUMBER()-funktionen bruger OVER- og PARTITION BY-sætningen og sorterer resultaterne i stigende eller faldende rækkefølge. Den begynder at rangordne rækker fra 1 i henhold til sorteringsrækkefølgen.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number] FROM [SalesLT].[Orders]
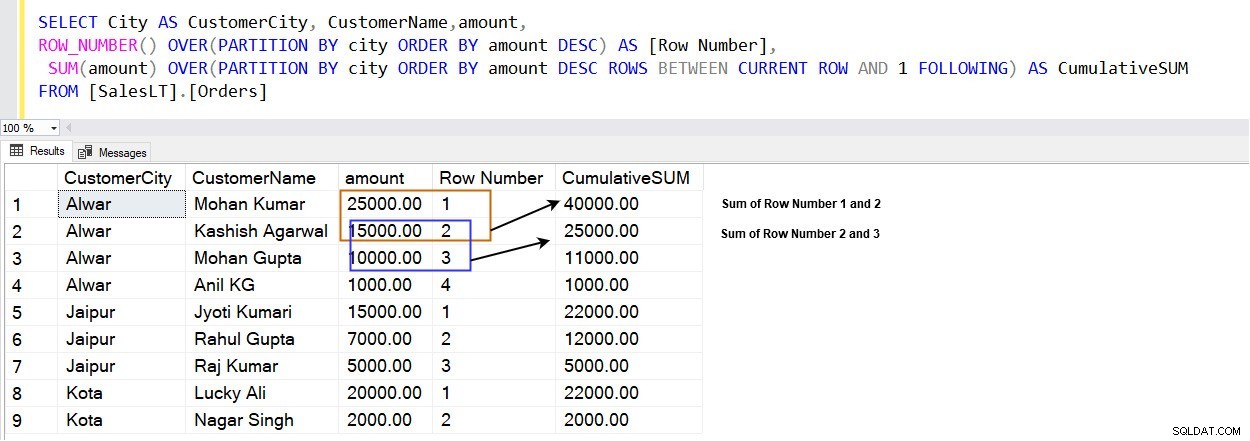
For eksempel, i [Alwar]-byen er rækken med det højeste beløb (25000,00) i række 1. Som vist nedenfor rangerer den rækker i vinduet specificeret af PARTITION BY-sætningen. For eksempel har vi tre forskellige byer [Alwar], [Jaipur] og [Kota], og hvert vindue (by) får sine rækker.
For at beregne den kumulative total, bruger vi følgende argumenter.
- AKTUELT RÆKKE:Det angiver start- og slutpunktet i det angivne område.
- 1 følgende:Det angiver antallet af rækker (1), der skal følges fra den aktuelle række.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS CumulativeSUM FROM [SalesLT].[Orders]
Følgende billede viser, at du får en kumulativ total i stedet for en samlet total i et vindue specificeret af PARTITION BY-klausulen.
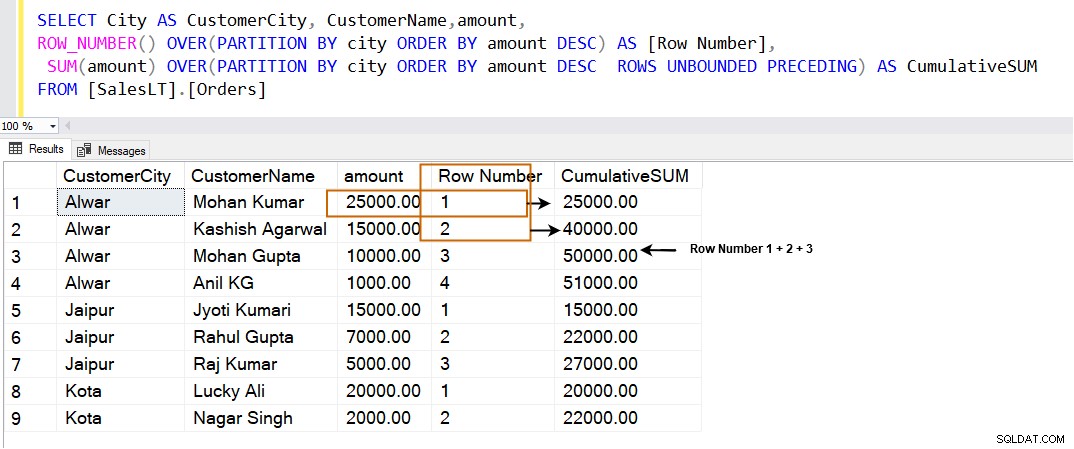
Hvis vi bruger ROWS UNBOUNDED PRECEDING i SQL PARTITION BY-udtrykket beregner den den kumulative total på følgende måde. Den bruger de aktuelle rækker sammen med de rækker, der har de højeste værdier i det angivne vindue.
| Række | Akumuleret total |
| 1 | Ranger 1 |
| 2 | Ranger 1+2 |
| 3 | Ranger 1+2+3 |
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS UNBOUNDED PRECEDING) AS CumulativeSUM FROM [SalesLT].[Orders]
Sammenligning af GROUP BY- og SQL PARTITION BY-sætningen
| GRUPPER EFTER | OPDELING AF |
| Det returnerer én række pr. gruppe efter beregning af de samlede værdier. | Det returnerer alle rækker fra SELECT-sætningen sammen med yderligere kolonner med aggregerede værdier. |
| Vi kan ikke bruge den ikke-aggregerede kolonne i SELECT-sætningen. | Vi kan bruge påkrævede kolonner i SELECT-sætningen, og det giver ingen fejl for den ikke-aggregerede kolonne. |
| Det kræver brug af HAVING-sætningen til at filtrere poster fra SELECT-sætningen. | PARTITION-funktionen kan have yderligere prædikater i WHERE-sætningen bortset fra de kolonner, der bruges i SELECT-sætningen. |
| GROUP BY bruges i almindelige aggregater. | PARTITION BY bruges i vinduesbaserede aggregater. |
| Vi kan ikke bruge det til at beregne rækkenumre eller deres rækker. | Den kan beregne rækkenumre og deres rækker i det mindre vindue. |
Bruger det
Det anbefales at bruge SQL PARTITION BY-udtrykket, mens du arbejder med flere datagrupper for de aggregerede værdier i den enkelte gruppe. På samme måde kan den bruges til at se originale rækker med den ekstra kolonne med aggregerede værdier.