Introduktion
I denne artikel skal vi tale om at bruge nvarchar datatype. Vi vil undersøge, hvordan SQL Server gemmer denne datatype på disken, og hvordan den behandles i RAM. Vi vil også undersøge, hvordan størrelsen af nvarchar kan påvirke ydeevnen.
Faktisk datastørrelse:nchar vs nvarchar
Vi bruger nvarchar når størrelsen af kolonnedataindtastninger sandsynligvis vil variere betydeligt. Lagerstørrelsen (i bytes) er dobbelt så stor som den faktiske længde af indtastede data + 2 bytes. Dette giver os mulighed for at spare disklager i forhold til at bruge nchar datatype. Lad os overveje følgende eksempel. Vi laver to tabeller. En tabel indeholder nvarchar kolonne, en anden tabel indeholder nchar kolonner. Størrelsen af kolonnen er 2000 tegn (4000 bytes).
OPRET TABEL dbo.testnvarchar ( col1 NVARCHAR(2000) NULL);GOINSERT INTO dbo.testnvarchar (col1) SELECT REPLICATE('&', 10)GO
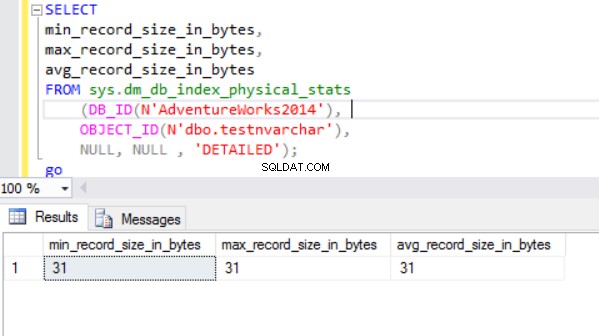
OPRET TABEL dbo.testnchar ( col1 NCHAR(2000) NULL);GOINSERT INTO dbo.testnchar (col1) SELECT REPLICATE('&', 10)GO Den faktiske rækkestørrelse er:
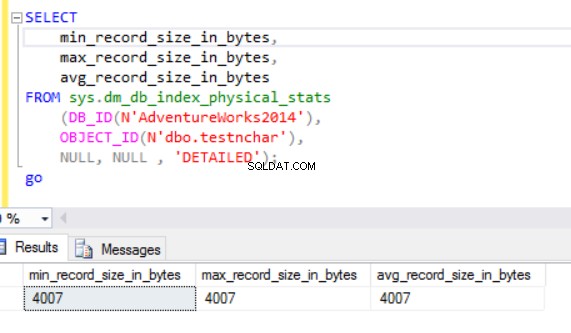
Som vi kan se, er den faktiske rækkestørrelse af nvarchar-datatypen meget mindre end nchar-datatypen. I tilfælde af nchar-datatypen bruger vi ~4000 bytes til at gemme 10 symboler tegnstreng. Vi bruger ~20 bytes til at gemme den samme tegnstreng i tilfælde af nvarchar-datatypen.
SQL Server-motoren behandler data til RAM (bufferpulje). Hvad med rækkestørrelsen i hukommelsen?
Faktisk datastørrelse:HDD vs RAM
Lad os udføre følgende forespørgsel:
VÆLG col1 FRA dbo.testnchar;

Der er ingen forskel mellem disk- og RAM-udnyttelse i tilfælde af tegnstrengen med fast længde.
VÆLG col1 FRA dbo.testnvarchar;

Vi kan se, at SQL Server Engine anmodede om hukommelsen for kun halvdelen af den erklærede rækkestørrelse (2000 bytes i stedet for faktiske 20 bytes) og flere bytes for yderligere information. Fra den ene side reducerer vi forbruget af diskplads, men fra en anden side kan vi puste den ønskede RAM op. Dette er en bivirkning af brugen af de forskellige karakterdatatyper. Denne bivirkning kan i nogle tilfælde have stor indflydelse på ressourcerne.
FORMAT():RAM anmodet vs anvendt RAM
Vi bruger FORMAT-funktionen, som returnerer en formateret værdi med det angivne format og valgfri kultur. Returværdien er nvarchar eller null. Længden af returværdien bestemmes af formatet . FORMAT(getdate(), 'ååååMMdd','da-US') vil resultere i '20170412'. Vi har brug for 16 bytes for at gemme dette resultat i kolonnen på disken (resultatet bliver nvarchar(8)). Hvad er datastørrelsen i RAM for de bestemte data?
Lad os udføre følgende forespørgsel. Vi bruger følgende miljø:
- AdventureWorks2014
- MS SQL 2016-udviklingsudgave
- dbo.Customer (19.820.000 poster) indeholder data fra Sales.Customer (19.820 poster er blevet uploadet 1000 gange)):
;WITH rsAS(SELECT c.customerid ,c.modifieddate ,p.LastName FROM [dbo].[Customer] c LEFT OUTER JOIN [person].[person] p ON p.BusinessEntityID =c.PersonID)SELECT kunde-id ,Efternavn ,FORMAT([modificeret dato], 'ååååMMdd', 'da-US') AS md ,' ' AS code INTO #tmpFROM rs
Forespørgselsudførelsesplanen er ret enkel:

Den første operation er "Clustered index scan" på dbo.Customer-tabel. ~19 000 000 optegnelser er blevet læst. Estimeret datastørrelse er 435 Mb.
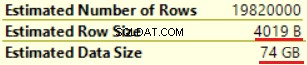
Den næste operation er "Compute Scalar" (beregning af FORMAT()-funktionen). Resultatet er ret uventet, da vi formaterer 16 bytes tegnstreng. Rækkestørrelsen steg dramatisk fra 23 bytes til 4019 bytes. Det samme med den estimerede datastørrelse - fra 435 MB til 74 GB. Vi kan se, at FORMAT() returnerer NVARCHAR(4000).
MS SQL Server 2016 har den store evne til at vise overdreven hukommelsesbevilling. Vi kan se advarslen i den sidste operation (T-SQL SELECT INTO):
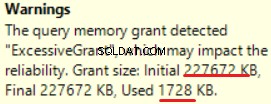
Dette er "overbevilget" af hukommelsen:mere end 90 % af den tildelte hukommelse bruges ikke.
Forespørgselstidsstatistikken er:
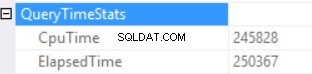
Den lange eksekveringstid afhænger af en ikke-effektiv udførelse af skalarfunktioner og bagsideeffekt af en Excessive Memory Grant – Hash Match (Right Outer Join). Vi har en kumulativ effekt af to forskellige årsager:multipel skalarfunktionsudførelse og overdreven hukommelsestildeling.
SQL Server-motoren kan ikke tildele mere end 25 % af den tilladte hukommelse pr. forespørgsel. Vi kan ændre dette beløb i virksomhedsudgaven af MS SQL Server ved hjælp af ressourceregulatoren. Den tildelte hukommelse består af to dele:påkrævet og yderligere. En nødvendig hukommelse bruges til de interne behov – til sortering og hash join-operationer. Yderligere hukommelse er baseret på den estimerede datastørrelse. Hvis både påkrævet og ekstra hukommelse overstiger grænsen på 25 %, giver SQL Server-motoren yderligere 25 % af den tilgængelige hukommelse. Læs indlægget om SQL Server-hukommelsesbevilling for detaljer.
Lad os udføre den samme forespørgsel uden FORMAT()-funktionen.
;WITH rsAS(SELECT c.customerid ,c.modifieddate ,p.LastName FROM [dbo].[Customer] c LEFT OUTER JOIN [person].[person] p ON p.BusinessEntityID =c.PersonID)SELECT kunde-id ,Efternavn ,' ' SOM kode INTO #tmpFROM rs
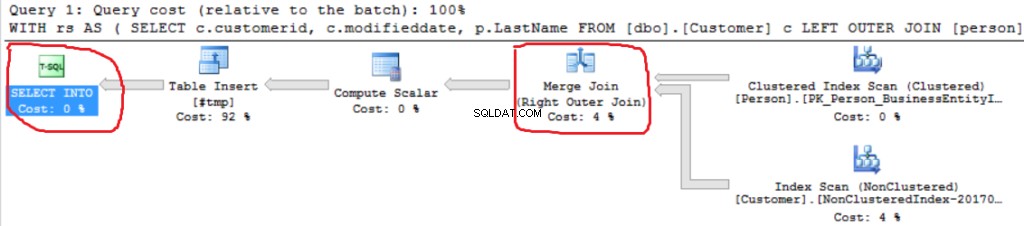
Vi kan se en anden Right Outer Join-implementering (Merge Join i stedet for Hash Join).
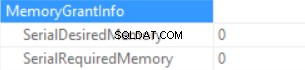
Memory Grant info er (hvis ingen sortering og Hash Join SQL Server ikke kan give nogen hukommelse):
Forespørgselstiden Statistikken er (tiden reduceres forudsigeligt:ingen skalarfunktionsudførelse, den estimerede datastørrelse er mindre end i det forrige eksempel):

Så vi puster den "bevilgede hukommelse" op til 222 MB (og bruger mindre end 2 MB af den) ved at bruge FORMAT()-funktionen. Datamængden i eksemplet er lille.
Langtidsudførelsesforespørgsel
Overvej den rigtige SQL-forespørgsel fra et produktionsmiljø. Denne forespørgsel er blevet udført under en batchindlæsningsproces (ikke et klassisk transaktionsscenarie). Vi bruger MS SQL Server startet på Amazon Web Services (AWS, Amazon Relational Database Service). DB-instanskarakteristika er 160 GB RAM (ikke mere end ~30 GB RAM kan tildeles pr. forespørgsel) og 40 vCPU. SQL-forespørgslen var næsten den samme som eksemplet ovenfor (forskellen er i antal tabeller og datastørrelse):CTE inkluderet join mellem 6 tabeller. "Hovedtabellen" (en tabel i FROM-klausulen) indeholder ~175'000'000 poster, og datastørrelsen er 20 GB. Opslagstabellerne (højre tabel i JOIN-sætningen) er små (i sammenligning med hovedtabellen). SQL-forespørgslen indeholder to kald af FORMAT()-funktionen (to kolonner fra "master table"-tabellen er parameteren for denne funktion).
Produktionsforespørgsel ser sådan ud:
"Billedet" af udførelsesplanen er nedenfor (udførelsesplanen er enkel:sekventielle sammenføjninger og sortering (DISTINKT nøgleord) øverst):

Lad os udforske oplysningerne i detaljer.
Den første operation er "Tabelscanning" (alt er korrekt, ingen overraskelser):

Operationen "Scalar compute" øger dramatisk den estimerede rækkestørrelse såvel som den estimerede rækkestørrelse (fra 19 GB op til 1,3 TB). To kald af FORMAT()-funktionen føjede ca. 8000 bytes til den estimerede rækkestørrelse (men den faktiske datastørrelse er mindre).

En af JOIN-operationerne (Hash Match, Right Outer Join) bruger ikke-unikke kolonner fra den højre tabel. Det er ligegyldigt, hvis der er tale om nogle få poster. Dette er ikke vores tilfælde. Som et resultat stiger estimeret datastørrelse op til ~2,4TB.

Der er også en advarsel (ikke nok RAM til at behandle denne handling):
SQL-forespørgslen indeholder en "Distinct Sort"-operation på toppen, som ligner kirsebæret på toppen af en kage. Vi kan se den samme advarsel der.
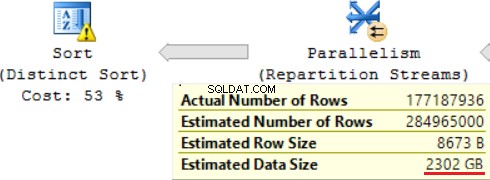
Et resultat af at bruge en skalarfunktion er lang tid til udførelse af forespørgsler:24 timer. En af årsagerne til dette problem er et forkert estimat af den anmodede datastørrelse baseret på "Estimeret datastørrelse". Uden at bruge FORMAT()-funktionen udfører MS SQL Server denne forespørgsel på 2 timer.
Konklusion
Udviklere bør være forsigtige, når de bruger nvarchar og varchar datatyper. Valg af redundante datatyper for kolonner kan føre til oppustning af den nødvendige hukommelse. Som følge heraf vil RAM blive spildt, databasens ydeevne vil blive forringet.