Fokus i denne artikel vil være på at bruge JOINs. Vi vil starte med at tale lidt om, hvordan JOINs kommer til at ske, og hvorfor du skal JOIN data. Derefter vil vi tage et kig på de JOIN-typer, vi har til rådighed, og hvordan man bruger dem.
DELTAG I GRUNDLÆGGENDE
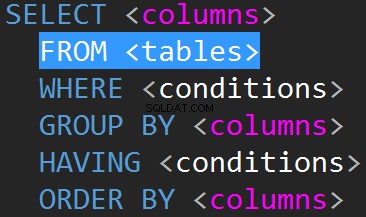
JOINs i TSQL vil typisk blive udført på FROM-linjen.
Før vi kommer til noget andet, bliver det virkelig store spørgsmål - "Hvorfor skal vi lave JOINs, og hvordan skal vi faktisk udføre vores JOINs?"
Som det viser sig, vil hver database, vi nogensinde arbejder med, få sine data opdelt i flere tabeller. Der er mange forskellige årsager til dette:
- Opretholdelse af dataintegritet
- Spar gemt plads
- Redigering af data hurtigere
- Gør forespørgsler mere fleksible
Derfor vil enhver database, som du skal arbejde med, have brug for, at disse data bliver sat sammen, for at det rent faktisk giver mening.
For eksempel har du separate tabeller for ordrer og for kunder. Spørgsmålet, der bliver - "Hvordan forbinder vi egentlig alle data sammen?" Det er præcis, hvad JOINs kommer til at gøre.
SÅDAN FUNGERER JOINS
Forestil dig tilfældet, når vi har to separate borde, og disse tabeller vil blive bragt sammen ved at skabe en søm.
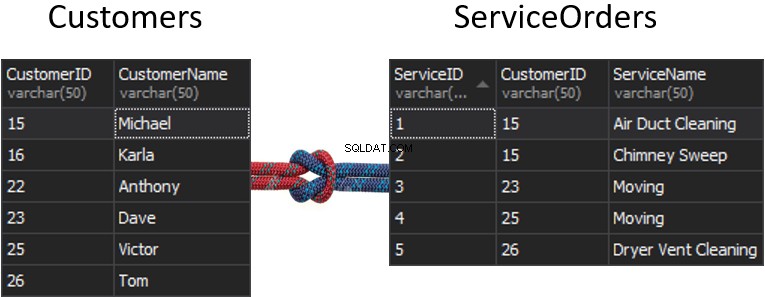
Hvad skal der ske med sømmen, hvis vi får en kolonne fra hver tabel, der skal bruges til at matche, og det vil afgøre, hvilke rækker der skal returneres eller ikke? For eksempel har vi Kunder til venstre og Serviceordrer til højre. Hvis vi ønsker at få alle kunderne og deres ordrer, er vi nødt til at SAMMEN disse to borde. Til dette skal vi vælge en kolonne, der fungerer som en søm, og selvfølgelig er den kolonne, vi skal bruge, Kunde-ID.
Forresten er kunde-id'et kendt som en Primær nøgle for den venstre tabel, som unikt identificerer hver enkelt række inde i Kunder-tabellen.
I tabellen ServiceOrders har vi også kolonnen CustomerID, som er kendt som en Foreign Key . En fremmednøgle er simpelthen en kolonne, der er designet til at pege på en anden tabel. I vores tilfælde peger det tilbage på kundetabellen. Derfor er det sådan, vi vil bringe alle disse data sammen ved at give den søm.
I disse tabeller har vi følgende matchninger:2 ordrer til 15 og 1 ordre til 23, 25 og 26. 16 og 22 er udeladt.
En stor ting at bemærke her er, at vi kan JOINDER flere borde . Faktisk er det ret almindeligt at JOINER flere tabeller sammen, for at få nogen form for information. Hvis du tager et kig på den mest almindelige database, kan det være, at du skal SAMMEN fire, fem, seks og flere tabeller for at få den information, du leder efter. Det vil være nyttigt at have et databasediagram.
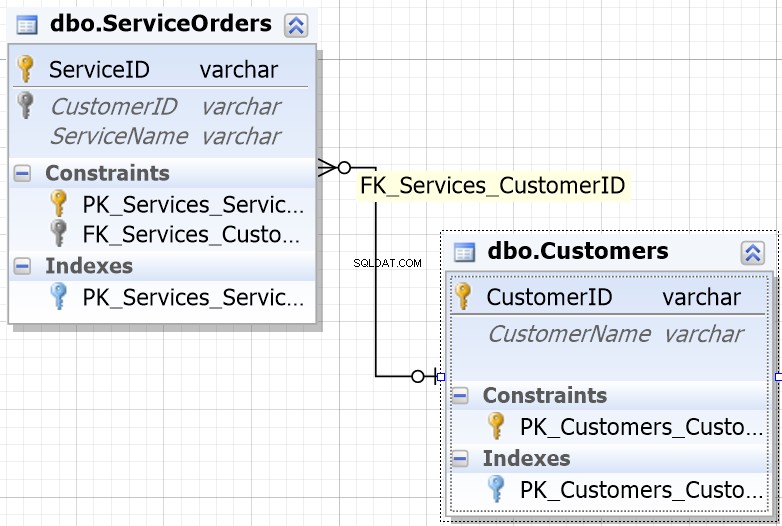
For at hjælpe dig i de fleste databasemiljøer vil du bemærke, at de kolonner, der er designet til at blive JOINed, har samme navn.
TILSLUT SYNTAX
Den tredje revision af SQL-databaseforespørgselssproget (SQL-92) regulerer JOIN-syntaksen:
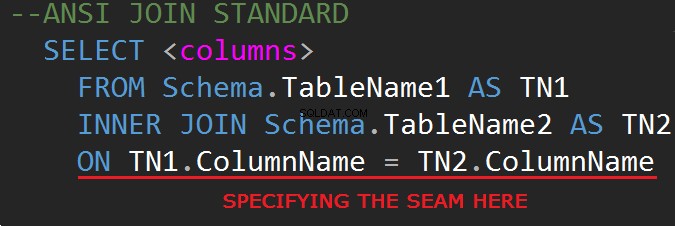
Det er muligt at lave JOINs på WHERE-linjen:
En relation har normalt en simpel grafisk fortolkning i form af en tabel.
Bedste praksis og konventioner
- Alias tabelnavne.
- Brug todelt navngivning til kolonner
- Placer hver JOIN på en separat linje
- Placer tabeller i en logisk rækkefølge
JOIN TYPER
SQL Server giver følgende typer JOINs:
- INDRE JOIN
- YDRE JOIN
- DELTAG SELV
- KRYDSJOIN
For mere information om emnet, er du velkommen til at tjekke denne artikel om typerne af joinforbindelser i SQL Server og lære, hvor nemt det er at skrive sådanne forespørgsler ved hjælp af SQL Complete.
INDRE JOIN
Den første type JOINs, som vi måske ønsker at udføre, er INNER JOIN. Normalt henviser forfattere til denne type SQL Server JOINs som en almindelig eller simpel JOIN. De udelader bare det INDERSTE præfiks. Denne type JOIN kombinerer to tabeller sammen og returnerer kun rækker fra begge sider, der matcher .
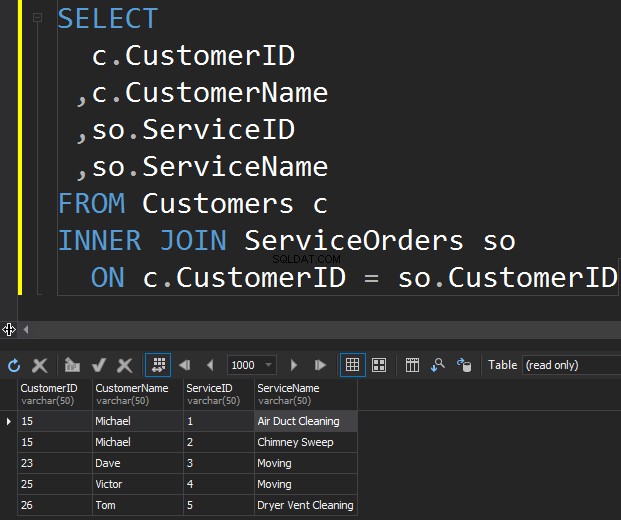
Vi ser ikke Klara og Anthony her, fordi deres kunde-ID ikke stemmer overens i begge tabeller. Jeg vil også fremhæve det faktum, at JOIN-operationen returnerer en kunde, hver gang den matcher ordren . Der er to ordrer til Michael og en ordre til Dave, Victor og Tom hver.
Oversigt:
- INNER JOIN returnerer kun rækker, når der er mindst én række i begge tabeller, der matcher JOIN-betingelsen.
- INNER JOIN eliminerer de rækker, der ikke stemmer overens med en række fra den anden tabel
YDRE JOIN
Ydre JOINs er forskellige, fordi de returnerer rækker fra tabeller eller visninger, selvom de ikke matcher. Denne type JOIN er nyttig, hvis du skal hente alle kunder, der aldrig har afgivet en ordre. Eller for eksempel hvis du leder efter et produkt, der aldrig er blevet bestilt.
Den måde, vi laver vores OUTER JOINs på, er ved at angive VENSTRE eller HØJRE, eller FULD.
Der er ingen forskelle mellem følgende klausuler:
- LEFT OUTER JOIN =LEFT JOIN
- RIGHT YDRE JOIN =RIGHT JOIN
- FULD YDRE JOIN =FULD JOIN
Jeg vil dog anbefale at skrive hele klausulen, fordi det gør koden mere læsbar.
Brug af LEFT OUTER JOIN
Der er ingen forskel på VENSTRE eller HØJRE bortset fra, at vi blot peger på den tabel, som vi ønsker at få de ekstra rækker fra. I det følgende eksempel listede vi kunder og deres ordrer. Vi bruger VENSTRE til at få alle kunder, som aldrig har afgivet ordrer. Vi beder SQL Server om at få os ekstra rækker fra den venstre tabel.
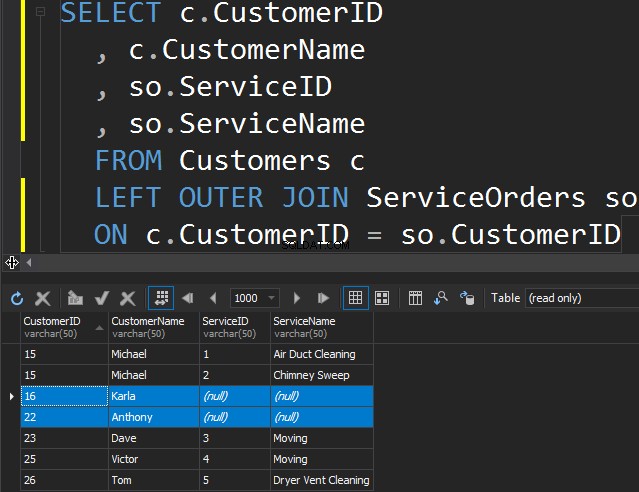
Bemærk, at Karla og Anthony ikke har afgivet nogen ordre, og som følge heraf får vi NULL-værdier for ServiceName og ServiceID. SQL Server ved ikke, hvad den skal placere derinde, og den placerer NULLs.
Brug af RIGHT OUTER JOIN
For at få den mindre populære service fra ServiceOrders-tabellen skal vi bruge den RIGTIGE retning.
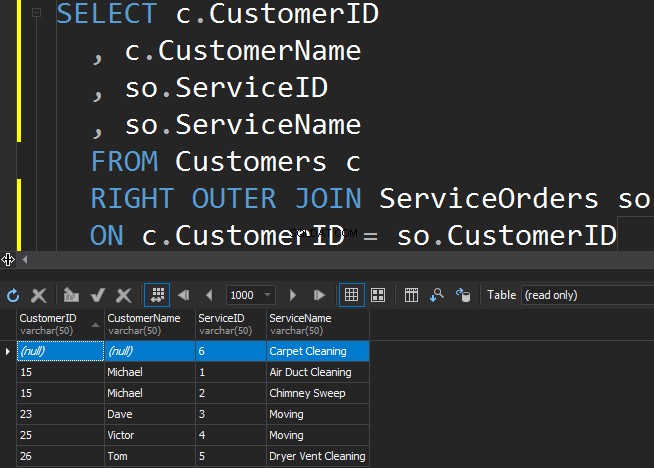
Vi ser, at i dette tilfælde returnerede SQL Server ekstra rækker fra den rigtige tabel, og tæpperens er aldrig blevet bestilt.
Brug af FULD YDRE JOIN
Denne type JOIN giver dig mulighed for at få de ikke-matchende oplysninger ved at inkludere ikke-matchende rækker fra begge tabeller.
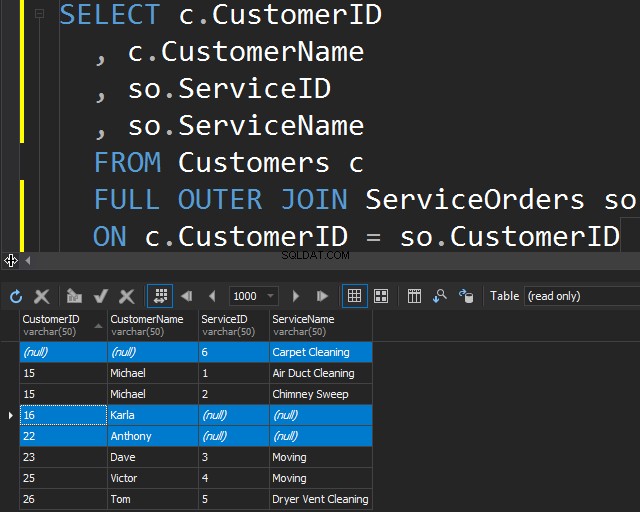
Dette kan også være nyttigt, hvis du skal foretage en dataoprydning.
Oversigt:
FULD YDRE JOIN
- Returnerer rækker fra begge tabeller, selvom de ikke matcher JOIN-sætningen
VENSTRE eller HØJRE
- Ingen forskel undtagen i rækkefølgen af tabeller i FROM-sætningen
- Retning peger på en tabel for at hente ikke-matchende rækker fra
DELTAG SELV
Den næste type JOINs, vi har, er SELF JOIN. Dette er sandsynligvis den næstmindst almindelige type JOIN, som du nogensinde kommer til at udføre. EN SELV JOIN er, når du slutter dig til et bord på sig selv. Generelt er dette et tegn på dårligt design. For at bruge den samme tabel to gange i en enkelt forespørgsel, skal tabellen have alias. Aliaset hjælper forespørgselsprocessoren med at identificere, om kolonner skal præsentere data fra højre eller venstre side. Derudover skal du eliminere rækker, der marcherer sig selv. Dette gøres typisk med en non-equi join.
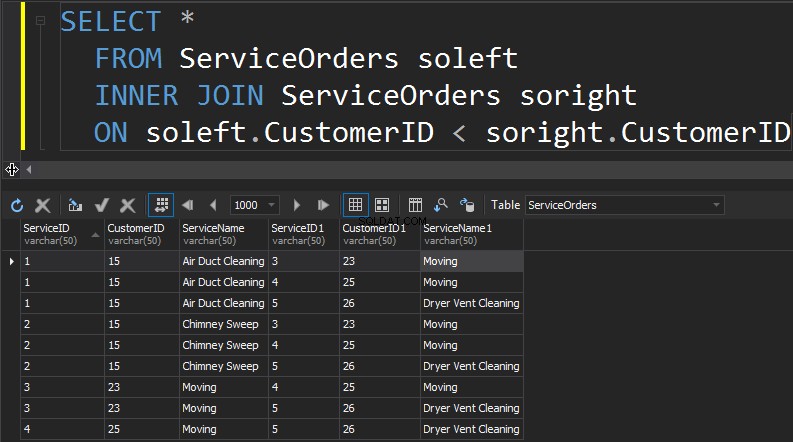
Oversigt:
- Slutter et bord til sig selv
- Generelt et tegn på dårligt design og normalisering
- Tabeller skal have alias
- Behov for at filtrere rækker, der matcher dem selv
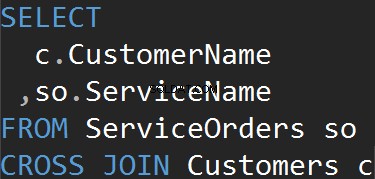
KRYDS JOINDER
Denne type JOINs har ikke ON udmelding. Hver enkelt række fra hvert bord kommer til at matche. Dette er også kendt som Cartesian Product (i tilfælde af at en CROSS JOIN ikke har en WHERE-klausul). Du vil næppe bruge denne JOIN-type i virkelige scenarier, men det er en god måde at generere testdata på.
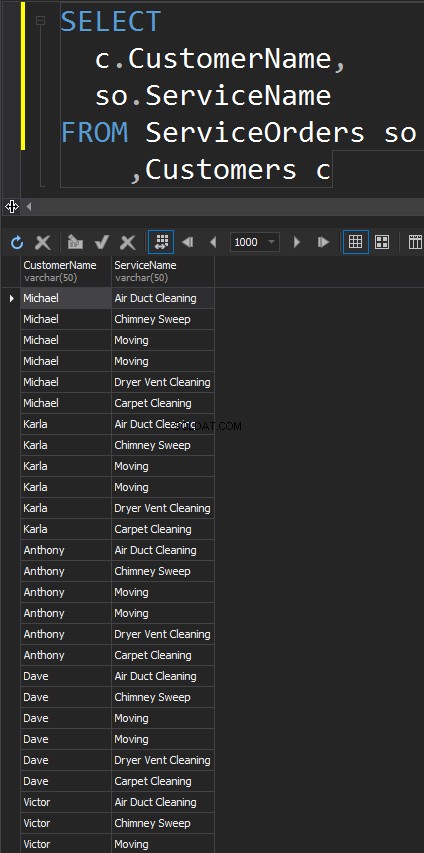
Resultatet er et datasæt, hvor antallet af rækker i venstre tabel ganget med antallet af rækker i højre tabel. Til sidst ser vi, at hver enkelt kunde matcher hver enkelt service.
Vi får det samme resultat, når vi eksplicit bruger CROSS JOIN-sætningen.
Oversigt:
- Alle rækker matcher fra hver tabel
- Ingen ON-erklæring
- Kan bruges til at generere testdata
DELTAG ALGORITHMER
I den første del af artiklen har vi diskuteret logisk JOIN-operatører SQL Server bruger under forespørgselsparsing og -binding. De er:
- INDRE JOIN
- YDRE JOIN
- KRYDSJOIN
De logiske operatorer er konceptuelle og adskiller sig fra de fysiske TILtræder. Ellers bliver logiske JOINs reelt ikke tilsluttet særlige tabelkolonner. En enkelt logisk JOIN kan svare til mange fysiske JOINs. SQL Server erstatter logiske JOINs til fysiske JOINs under optimering. SQL Server har følgende fysiske JOIN-operatorer:
- NESTED LOOP
- FLET
- HASH
En bruger skriver eller bruger ikke disse typer JOINS. De er en del af SQL Server-motoren, og SQL Server bruger dem internt til at implementere logiske JOINs. Når du udforsker eksekveringsplanen, bemærker du måske, at SQL Server erstatter logiske JOIN-operatorer med en af tre fysiske operatorer.
Nested Loop Join
Lad os starte fra den enkleste operatør, som er Nested Loop. Algoritmen sammenligner hver enkelt række i en tabel (ydre tabel) med hver række i den anden tabel (indre tabel) på udkig efter rækker, der opfylder JOIN-prædikatet.
Følgende pseudo-kode beskriver den indre indlejrede join-loop-algoritme:

Følgende pseudo-kode beskriver den ydre indlejrede join-loop-algoritme:
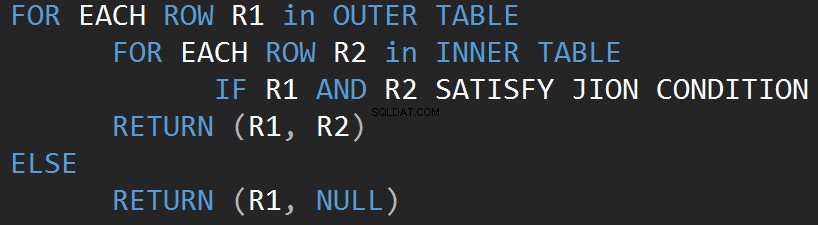
Størrelsen af inputtet påvirker direkte algoritmeomkostningerne. Inputtet vokser, omkostningerne vokser også. Denne type JOIN-algoritme er effektiv i tilfælde af lille input. SQL Server estimerer et JOIN-prædikat for hver række i begge input.
Betragt følgende forespørgsel som et eksempel, der henter kunder og deres ordrer.
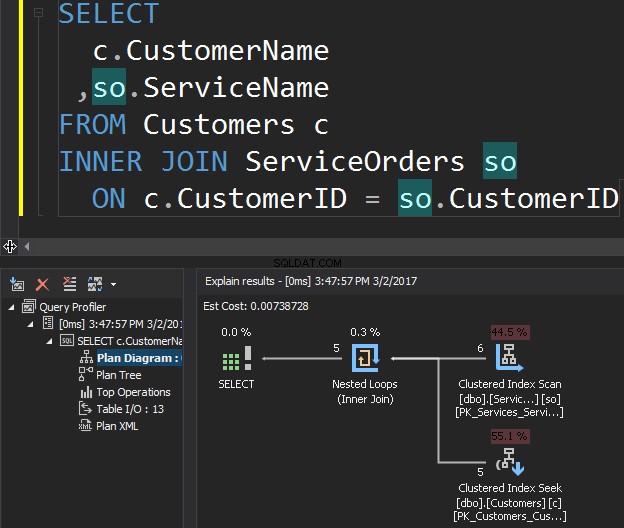
Operatoren Clustered Index Scan er det ydre input og Clustered Index Seek er det indre input . Nested Loop-operatøren finder faktisk matchning. Operatøren leder efter hver post i det ydre input og finder matchende rækker i det indre input. SQL Server udfører Clustered Index Scan-operationen (ydre input) kun én gang for at få alle relevante poster. Clustered Index Seek udføres for hver post fra det ydre input. For at bekræfte dette skal du navigere markøren til operatørikonet og undersøge værktøjstippet.
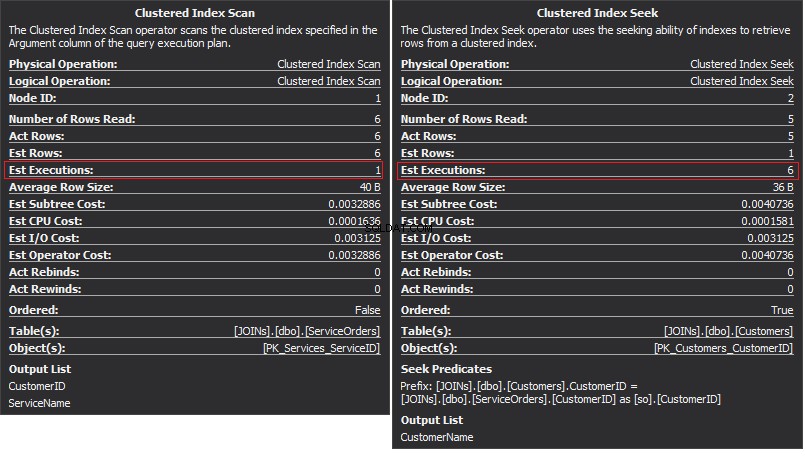
Lad os tale om kompleksiteten. Antag N er rækkenummeret for den ydre udgang. M er det samlede rækkenummer i Salgsordrer bord. Derfor er kompleksiteten af forespørgslen O(NLogM) hvor LogM er kompleksiteten af hver søgning i det indre input. Optimizeren vil vælge denne operator hver gang, når det ydre input er lille, og det indre input indeholder et indeks i kolonnen, der fungerer som sømmen. Derfor er indekser og statistik essentielle for denne JOIN-type, ellers kan SQL Server ved et uheld komme til at tro, at der ikke er så mange rækker i en af inputs. Det er bedre at udføre en tabelscanning i stedet for at udføre indekssøgning 100.000 gange. Især når den indre inputstørrelse er mere end 100K.
Oversigt:
Indlejrede sløjfer
- Kompleksitet:O(NlogM)
- Anvendes normalt, når et bord er lille
- Den større tabel indeholder et indeks, som gør det muligt at søge efter det ved hjælp af join-nøglen
Flet tilmelding
Nogle udviklere forstår ikke helt Hash og Merge JOINs og forbinder dem ofte med dårligt ydende forespørgsler.
I modsætning til Nested Loop, der accepterer et hvilket som helst JOIN-prædikat, kræver Merge Join mindst én equi join. Derudover skal begge input sorteres på JOIN-tasterne.
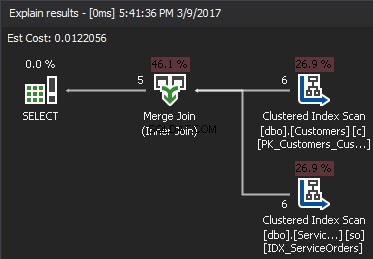
Pseudokoden for MERGE JOIN-algoritmen:
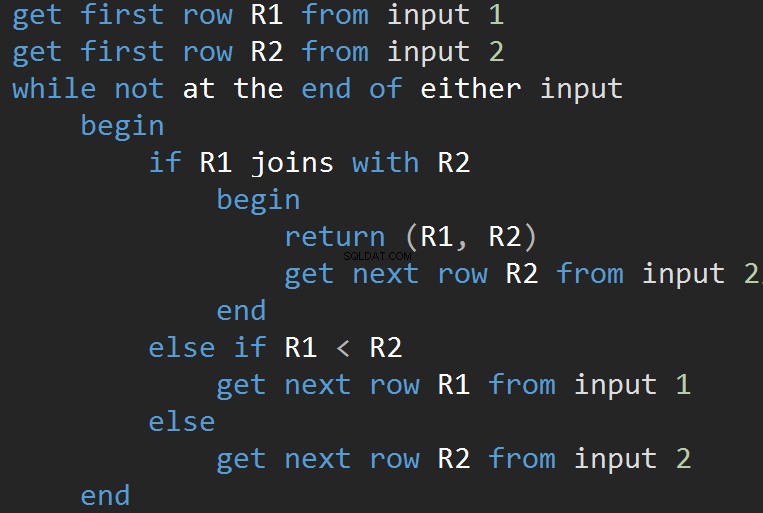
Algoritmen sammenligner to sorterede input. En række ad gangen. I tilfælde af at der er lighed mellem to rækker, forbinder algoritmeudgangene rækker og fortsætter. Hvis ikke, kasserer algoritmen den mindste af de to input og fortsætter. I modsætning til Nested Loop er prisen her proportional med summen af antallet af inputrækker. Med hensyn til kompleksitet – O(N+M). Derfor er denne type JOINs ofte bedre til store input.
Følgende animation demonstrerer, hvordan MERGE JOIN-algoritmen faktisk forbinder tabelrækker.
Oversigt
- Kompleksitet:O(N+M)
- Begge input skal sorteres på join-nøglen
- Der bruges en ligestillingsoperatør
- Fremragende til store borde
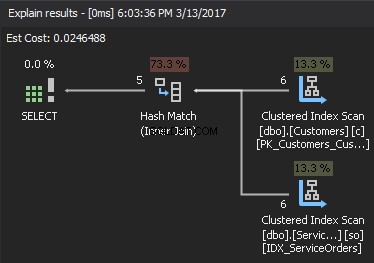
Hash Join
Hash Join er velegnet til store borde uden brugbart indeks. På det første trin – byggefase Algoritmen opretter et hash-indeks i hukommelsen på input til venstre. Det andet trin kaldes probefasen . Algoritmen går gennem input fra højre side og finder match ved hjælp af det indeks, der blev oprettet under byggefasen. Hvis man siger sandheden, er det ikke et godt tegn, når optimeringsværktøjet vælger denne type JOIN-algoritme.
Der er to vigtige begreber, der ligger til grund for denne type JOINs:Hash-funktion og Hash-tabel.
En hash-funktion er enhver funktion, der kan bruges til at kortlægge data af variabel størrelse til data af fast størrelse.
En hash-tabel er en datastruktur, der bruges til at implementere et associativt array, en struktur, der kan kortlægge nøgler til værdier. En hash-tabel bruger en hash-funktion til at beregne et indeks i et array af buckets eller slots, hvorfra den ønskede værdi kan findes.
Baseret på den tilgængelige statistik vælger SQL Server det mindste input som build-input og bruger det til at bygge en hash-tabel i hukommelsen. Hvis der ikke er nok hukommelse, bruger SQL Server fysisk diskplads i TempDB. Når hash-tabellen er oprettet, får SQL Server dataene fra sonde-inputtet (større tabel) og sammenligner dem med hash-tabellen ved hjælp af en hash-match-funktion. Som et resultat returnerer den matchede rækker.
Hvis vi ser på udførelsesplanen, er det højre øverste element byg-input , og det nederste højre element er sondeindgangen . Hvis begge input er ekstremt store, er omkostningerne for høje.
For at vurdere kompleksiteten, antag følgende:
hc – kompleksiteten af oprettelsen af hashtabellen
hm – kompleksiteten af hash-match-funktionen
N – mindre bord
M – større bord
J – kompleksitetstillæg til dynamisk beregning og oprettelse af hashfunktionen
Kompleksiteten vil være:O(N*hc + M*hm + J)
Optimizeren bruger statistik til at bestemme værdikardinalitet. Derefter opretter den dynamisk en hash-funktion, der deler data op i mange buckets med lige store størrelser. Det er ofte svært at estimere kompleksiteten af processen til oprettelse af hash-tabel, såvel som kompleksiteten af hver hash-match på grund af dynamisk karakter. Udførelsesplanen kan endda vise forkerte estimater, fordi optimizer udfører alle disse dynamiske operationer i løbet af udførelsestiden. I nogle tilfælde kan udførelsesplanen vise, at Nested Loop er dyrere end Hash Join, men faktisk udføres Hash Join langsommere på grund af den forkerte omkostningsestimat.
Oversigt
- Kompleksitet:O(N*hc +M*hm +J)
- Sidste udvej-tilslutningstype
- Bruger en hash-tabel og en dynamisk hash-matchfunktion til at matche rækker
Nyttige produkter:
SQL Complete – skriv, forskønne, refaktorér din kode nemt og øg din produktivitet.