Gør IKKE brug indekser undtagen en unik enkelt numerisk nøgle.
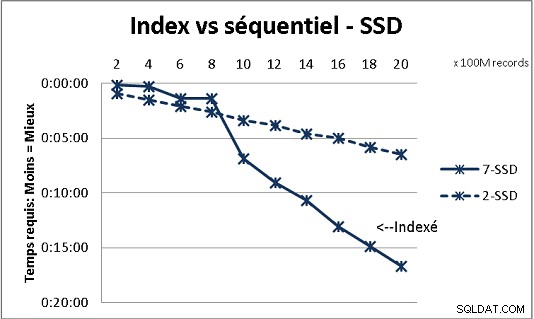
Det passer ikke med al DB-teori, vi modtog, men test med store mængder data viser det. Her er et resultat af 100 millioner belastninger ad gangen for at nå 2 milliarder rækker i en tabel, og hver gang en masse forskellige forespørgsler på den resulterende tabel. Første grafik med 10 gigabit NAS (150MB/s), anden med 4 SSD i RAID 0 (R/W @ 2GB/s).
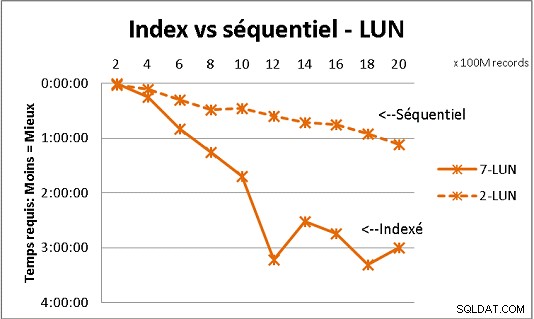
Hvis du har mere end 200 millioner rækker i en tabel på almindelige diske, er det hurtigere, hvis du glemmer indekser. På SSD'er er grænsen på 1 mia.
Jeg har også gjort det med partitioner for bedre resultater, men med PG9.2 er det svært at drage fordel af dem, hvis du bruger lagrede procedurer. Du skal også sørge for at skrive/læse til kun 1 partition ad gangen. Men skillevægge er vejen at gå for at holde dine borde under væggen med 1 milliard rækker. Det hjælper også meget at multibehandle dine belastninger. Med SSD, enkelt proces lader mig indsætte (kopiere) 18.000 rækker/s (med noget behandlingsarbejde inkluderet). Med multiprocessing på 6 CPU vokser den til 80.000 rækker/s.
Se dit CPU- og IO-brug, mens du tester for at optimere begge dele.