PostgreSQL er et fantastisk projekt, og det udvikler sig med en fantastisk hastighed. Vi vil fokusere på udviklingen af fejltolerance-egenskaber i PostgreSQL gennem dens versioner med en række blogindlæg. Dette er det andet indlæg i serien, og vi vil tale om replikering og dens betydning for fejltolerance og pålidelighed af PostgreSQL.
Hvis du gerne vil være vidne til udviklingen fra begyndelsen, så tjek venligst det første blogindlæg i serien:Evolution of Fault Tolerance in PostgreSQL
PostgreSQL-replikering
Databasereplikering er det udtryk, vi bruger til at beskrive den teknologi, der bruges til at vedligeholde en kopi af et sæt data på en fjernbetjening system. At beholde en pålidelig kopi af et kørende system er en af de største bekymringer ved redundans, og vi kan alle godt lide at vedligeholde, brugervenlige og stabile kopier af vores data.
Lad os se på den grundlæggende arkitektur. Typisk omtales individuelle databaseservere som noder . Hele gruppen af databaseservere involveret i replikering er kendt som en cluster . En databaseserver, der tillader en bruger at foretage ændringer, er kendt som en master eller primær , eller kan beskrives som en kilde til ændringer. En databaseserver, der kun tillader skrivebeskyttet adgang er kendt som en Hot Standby . (Begrebet Hot Standby er forklaret i detaljer under titlen Standby Modes. )
Nøgleaspektet ved replikering er, at dataændringer fanges på en master og derefter overføres til andre noder. I nogle tilfælde kan en node sende dataændringer til andre noder, hvilket er en proces kendt som cascading eller relæ . Masteren er således en afsendende node, men ikke alle afsendende noder behøver at være mastere. Replikering kategoriseres ofte efter, om mere end én masterknude er tilladt, i hvilket tilfælde det vil blive kendt som multimaster-replikering .
Lad os se, hvordan PostgreSQL håndterer replikering over tid, og hvad er det nyeste inden for fejltolerance i henhold til replikationsbetingelserne.
PostgreSQL-replikeringshistorik
Historisk (omkring år 2000-2005) var Postgres kun koncentreret i enkelt node-fejltolerance/gendannelse, som for det meste opnås af WAL, transaktionsloggen. Fejltolerance håndteres delvist af MVCC (multi-version concurrency system), men det er hovedsageligt en optimering.
Write-ahead-logning var og er stadig den største fejltolerancemetode i PostgreSQL. Dybest set bare at have WAL-filer, hvor du skriver alt og kan genoprette i form af fejl ved at afspille dem igen. Dette var nok til enkeltknudearkitekturer, og replikering anses for at være den bedste løsning til at opnå fejltolerance med flere noder.
Postgres-samfundet har længe troet, at replikering er noget, som Postgres ikke burde levere og skulle håndteres af eksterne værktøjer, det er derfor, værktøjer som Slony og Londiste blev eksisterende. (Vi vil dække trigger-baserede replikeringsløsninger ved de næste blogindlæg i serien.)
Efterhånden blev det klart, at én servertolerance ikke er nok, og flere mennesker efterspurgte korrekt fejltolerance af hardwaren og korrekt måde at skifte på, noget indbygget i Postgres. Det var her den fysiske (dengang fysiske streaming) replikering kom til live.
Vi gennemgår alle replikeringsmetoderne senere i indlægget, men lad os se de kronologiske begivenheder i PostgreSQL-replikeringshistorien efter større udgivelser:
- PostgreSQL 7.x (~2000)
- Replikering bør ikke være en del af kernepostgres
- Londiste – Slony (triggerbaseret logisk replikering)
- PostgreSQL 8.0 (2005)
- Point-in-Time Recovery (WAL)
- PostgreSQL 9.0 (2010)
- Streaming replikering (fysisk)
- PostgreSQL 9.4 (2014)
- Logisk afkodning (udtræk af ændringssæt)
Fysisk replikering
PostgreSQL løste det centrale replikeringsbehov med, hvad de fleste relationelle databaser gør; tog WAL og gjorde det muligt at sende det over netværket. Derefter anvendes disse WAL-filer i en separat Postgres-instans, der kører skrivebeskyttet.
Den skrivebeskyttede standby-instans anvender blot ændringerne (af WAL) og de eneste skriveoperationer kommer igen fra den samme WAL-log. Dette er dybest set, hvordan streaming replikering mekanismen virker. I begyndelsen var replikering oprindeligt at sende alle filer –logforsendelse- , men senere udviklede det sig til streaming.
Ved logforsendelse sendte vi hele filer via archive_command . Logikken er ret simpel der:du sender arkivet og loggen det til et sted – som hele 16 MB WAL-filen – og så ansøger det til et sted, og så henter du den næste og anvend den og det går sådan. Senere blev det streaming over netværk ved at bruge libpq-protokollen i PostgreSQL version 9.0.
Den eksisterende replikering er mere korrekt kendt som Physical Streaming Repplication, da vi streamer en række fysiske ændringer fra en node til en anden. Det betyder, at når vi indsætter en række i en tabel genererer vi ændringsposter for indsættelsen plus alle indeksposterne .
Når vi VACUUM en tabel genererer vi også ændringsposter.
Fysisk streamingreplikering registrerer også alle ændringer på byte-/blokniveau , hvilket gør det meget svært at gøre andet end bare at afspille alt igen
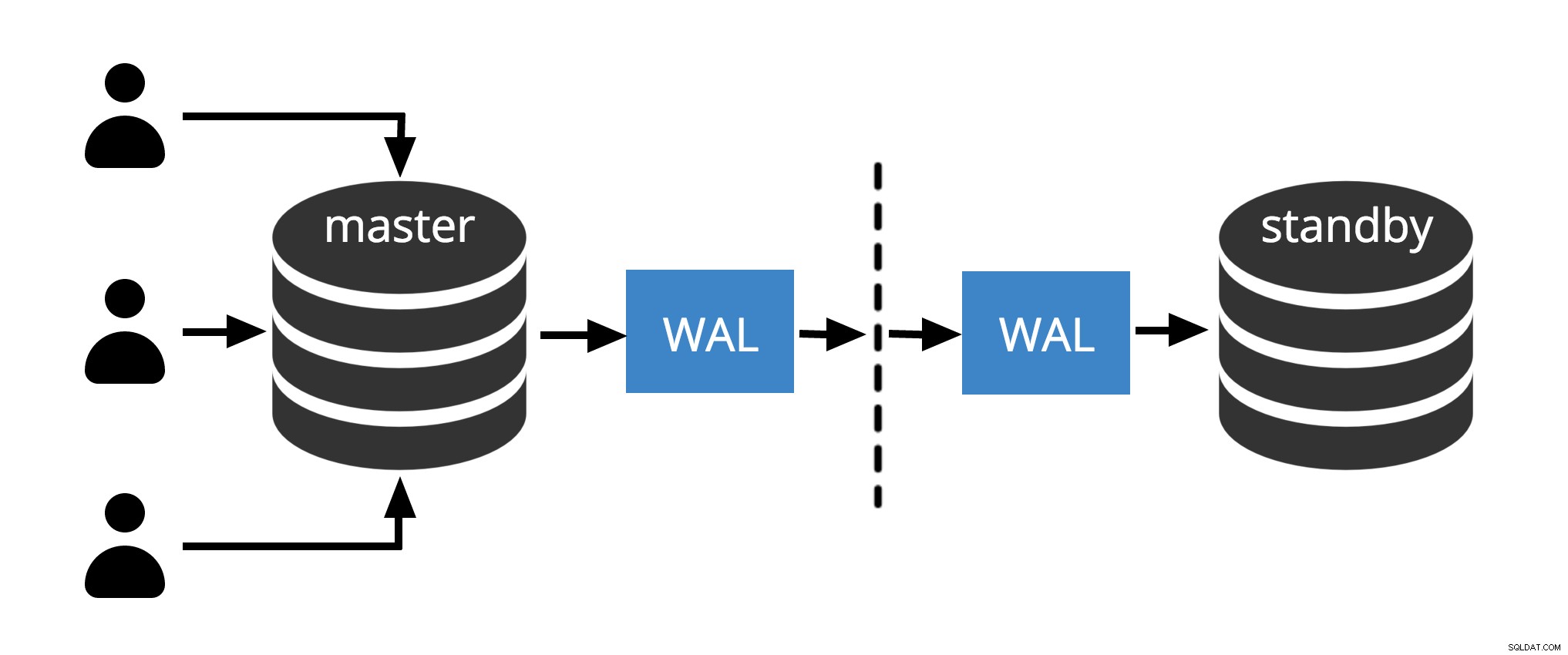
Fig.1 Fysisk replikering
Fig. 1 viser, hvordan fysisk replikation fungerer med kun to noder. Klientudfør forespørgsler på masterknudepunktet, ændringerne skrives til en transaktionslog (WAL) og kopieres over netværket til WAL på standbyknuden. Gendannelsesprocessen på standby-noden læser derefter ændringerne fra WAL og anvender dem på datafilerne ligesom under gendannelse af nedbrud. Hvis standby er i hot standby tilstand, kan klienter udstede skrivebeskyttede forespørgsler på noden, mens dette sker.
Bemærk: Fysisk replikering refererer simpelthen til at sende WAL-filer over netværket fra master til standby-knude. Filer kan sendes med forskellige protokoller som scp, rsync, ftp... forskellen mellem Fysisk replikering og Physical Streaming Replikation is Streaming Replication bruger en intern protokol til at sende WAL-filer (afsender og modtagerprocesser )
Standbytilstande
Flere noder giver høj tilgængelighed. Af den grund har moderne arkitekturer normalt standby-noder. Der er forskellige tilstande til standby noder (varm og varm standby). Listen nedenfor forklarer de grundlæggende forskelle mellem forskellige standby-tilstande og viser også tilfældet med multi-master-arkitektur.
Varm standby
Kan aktiveres med det samme, men kan ikke udføre nyttigt arbejde, før den aktiveres. Hvis vi kontinuerligt feeder serien af WAL-filer til en anden maskine, der er blevet indlæst med den samme basis-backup-fil, har vi et varmt standby-system:på ethvert tidspunkt kan vi hente den anden maskine frem, og den vil have en næsten aktuel kopi af databasen. Varm standby tillader ikke skrivebeskyttede forespørgsler. Fig.2 repræsenterer blot dette faktum.
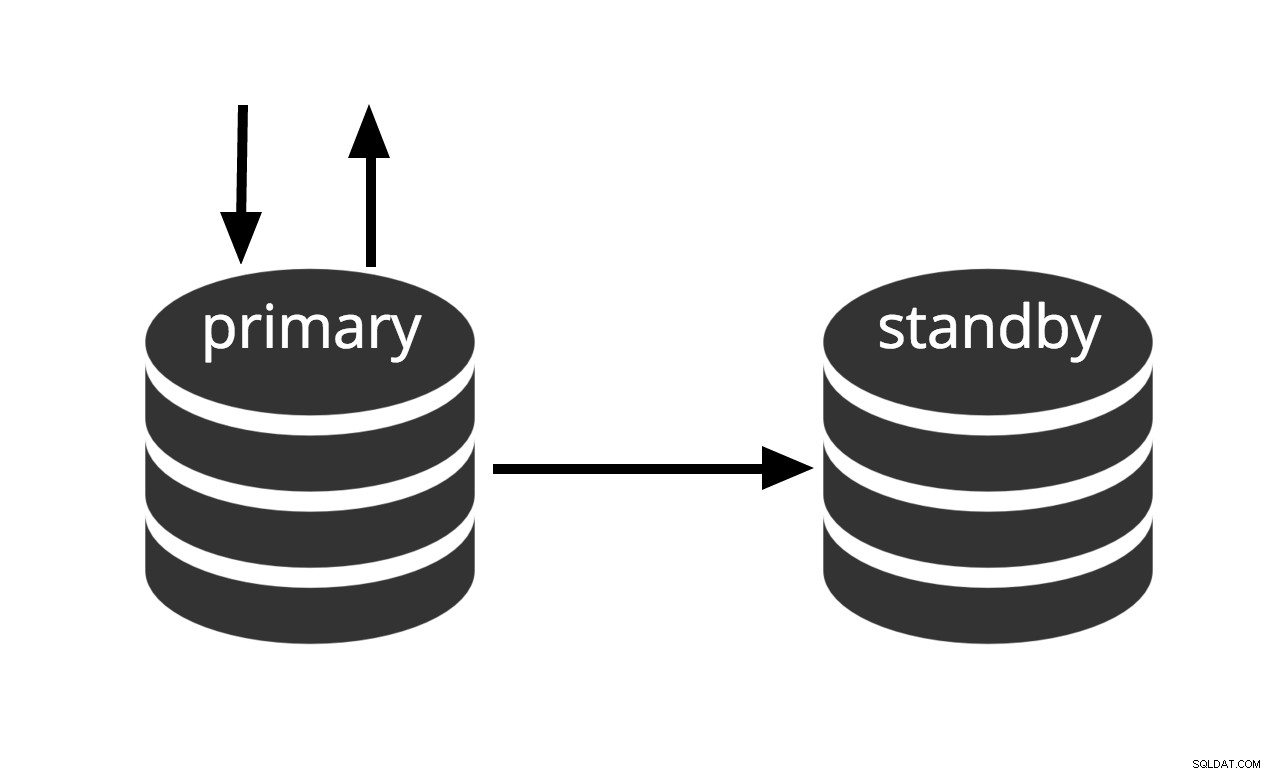
Fig.2 Varm Standby
Gendannelsesydelsen for en varm standby er tilstrækkelig god til, at standbyen typisk kun vil være få øjeblikke fra fuld tilgængelighed, når den først er blevet aktiveret. Som et resultat kaldes dette en varm standby-konfiguration, som tilbyder høj tilgængelighed.
Varm standby
Hot standby er det udtryk, der bruges til at beskrive evnen til at oprette forbindelse til serveren og køre skrivebeskyttede forespørgsler, mens serveren er i arkivgendannelse eller standbytilstand. Dette er nyttigt både til replikeringsformål og til at gendanne en sikkerhedskopi til en ønsket tilstand med stor præcision.
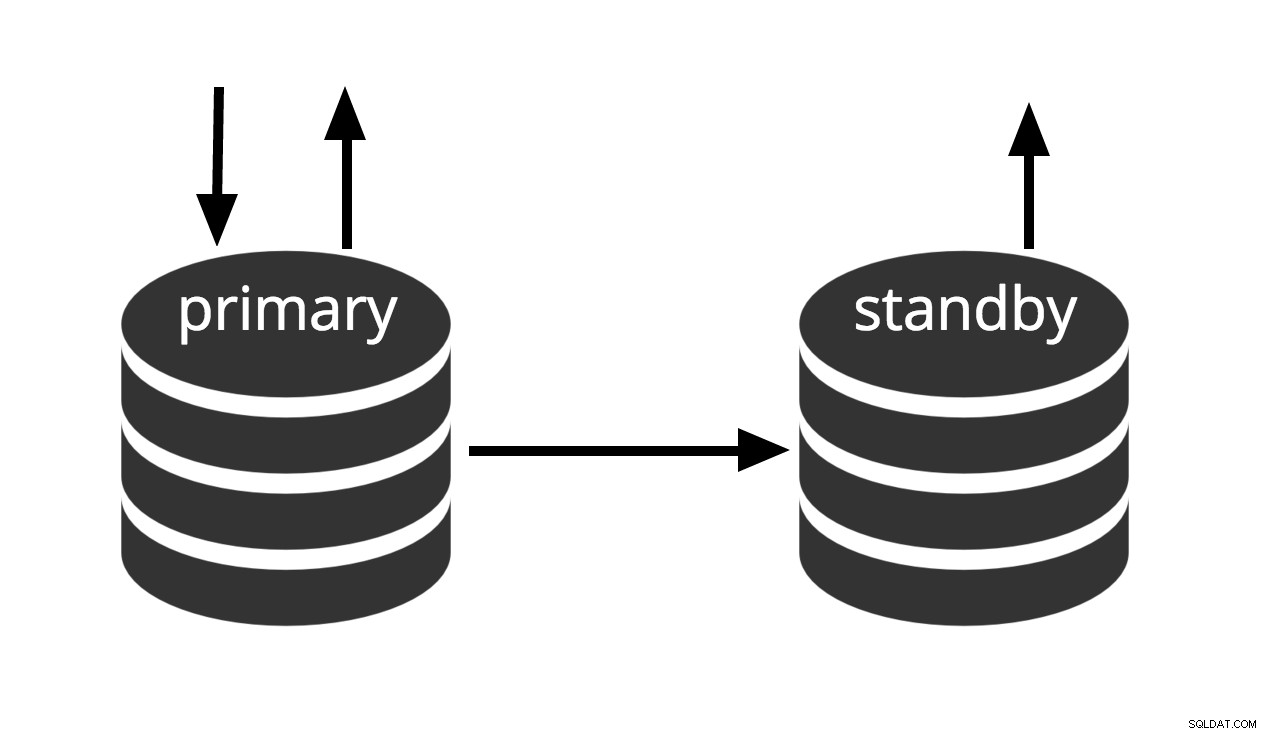 Fig.3 Hot Standby
Fig.3 Hot Standby
Udtrykket hot standby refererer også til serverens evne til at gå fra gendannelse til normal drift, mens brugere fortsætter med at køre forespørgsler og/eller holder deres forbindelser åbne. Fig.3 viser, at standbytilstand tillader skrivebeskyttede forespørgsler.
Multi-Master
Alle noder kan udføre læse/skrive arbejde. (Vi dækker multi-master arkitekturer ved de næste blogindlæg i serien.)
WAL Level parameter
Der er en sammenhæng mellem opsætning af wal_level parameter i postgresql.conf filen, og hvad er denne indstilling egnet til. Jeg oprettede en tabel til at vise relationen til PostgreSQL version 9.6.

Failover og Switchover
I single-master replikering, hvis masteren dør, skal en af standbyerne træde i stedet (promovering ). Ellers vil vi ikke kunne acceptere nye skrivetransaktioner. Udtrykket betegnelser, master og standby, er således blot roller, som enhver node kan tage på et tidspunkt. For at flytte masterrollen til en anden node udfører vi en procedure ved navn Switchover .
Hvis mesteren dør og ikke kommer sig, er den mere alvorlige rolleændring kendt som en failover . På mange måder kan disse ligne hinanden, men det hjælper at bruge forskellige udtryk for hver begivenhed. (Ved at kende vilkårene for failover og switchover vil det hjælpe os med forståelsen af tidslinjeproblemerne i næste blogindlæg.)
Konklusion
I dette blogindlæg diskuterede vi PostgreSQL-replikering og dens betydning for at give fejltolerance og pålidelighed. Vi dækkede fysisk streamingreplikering og talte om standbytilstande til PostgreSQL. Vi nævnte Failover og Switchover. Vi fortsætter med PostgreSQL-tidslinjer ved næste blogindlæg.
Referencer
PostgreSQL-dokumentation
Logisk replikering i PostgreSQL 5432…MeetUs-præsentation af Petr Jelinek
PostgreSQL 9 Administration Kogebog – Anden udgave