Ansible er simpelthen fantastisk, og PostgreSQL er helt sikkert fantastisk, lad os se, hvordan de fungerer fantastisk sammen!

=====================Meddelelse i bedste sendetid! =====================
PGConf Europe 2015 finder sted den 27.-30. oktober i Wien i år.
Jeg antager, at du muligvis er interesseret i konfigurationsstyring, serverorkestrering, automatiseret implementering (det er derfor, du læser dette blogindlæg, ikke?), og du kan lide at arbejde med PostgreSQL (helt sikkert) på AWS (valgfrit), så vil du måske deltage i mit foredrag "Managing PostgreSQL with Ansible" den 28. oktober, 15-15:50.
Tjek venligst den fantastiske tidsplan og gå ikke glip af chancen for at deltage i Europas største PostgreSQL-begivenhed!
Håber vi ses der, ja jeg kan godt lide at drikke kaffe efter samtaler 🙂
====================Meddelelse i bedste sendetid! =====================
Hvad er Ansible, og hvordan virker det?
Ansibles motto er "senkel, agentløs og kraftfuld open source IT-automatisering ” ved at citere fra Ansible docs.
Som det kan ses af nedenstående figur, angiver Ansibles hjemmeside, at Ansibles vigtigste anvendelsesområder er:klargøring, konfigurationsstyring, app-implementering, kontinuerlig levering, sikkerhed og compliance, orkestrering. Oversigtsmenuen viser også, på hvilke platforme vi kan integrere Ansible, dvs. AWS, Docker, OpenStack, Red Hat, Windows.
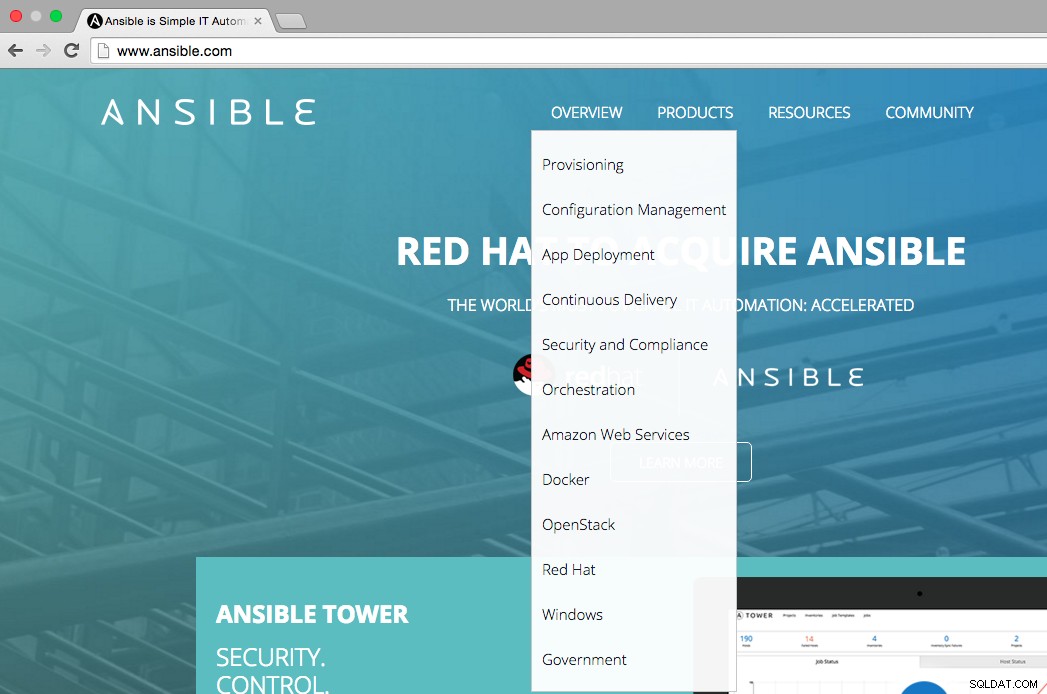
Lad os tjekke de vigtigste anvendelsesmuligheder for Ansible for at forstå, hvordan det fungerer, og hvor nyttigt det er for it-miljøer.
Provisionering
Ansible er din loyale ven, når du vil automatisere alt i dit system. Det er agentløst, og du kan simpelthen administrere dine ting (dvs. servere, belastningsbalancere, switche, firewalls) via SSH. Uanset om dine systemer kører på bare-metal- eller cloud-servere, vil Ansible være der og hjælpe dig med at klargøre dine instanser. Dets idempotente egenskaber sikrer, at du altid vil være i den tilstand, du ønskede (og forventede) at være.
Konfigurationsstyring
Noget af det sværeste er ikke at gentage sig selv i gentagne driftsopgaver og her kommer Ansible igen i tankerne som en frelser. I de gode gamle dage, hvor tiderne var dårlige, skrev sysadmins mange mange scripts og oprettede forbindelse til mange mange servere for at anvende dem, og det var åbenbart ikke det bedste i deres liv. Som vi alle ved, er manuelle opgaver tilbøjelige til at fejle, og de fører til heterogene omgivelser i stedet for et homogent og mere overskueligt og gør helt klart vores liv mere stressende.
Med Ansible kan du skrive simple playbooks (ved hjælp af meget informativ dokumentation og støtte fra dets enorme fællesskab), og når du først har skrevet dine opgaver, kan du kalde en lang række moduler (f.eks. AWS, Nagios, PostgreSQL, SSH, APT, File moduler). Som et resultat kan du fokusere på mere kreative aktiviteter end at administrere konfigurationer manuelt.
App-implementering
Når du har artefakterne klar, er det super nemt at implementere dem på en række servere. Da Ansible kommunikerer over SSH, er der ingen grund til at trække fra et lager på hver server eller besvær med ældgamle metoder som at kopiere filer over FTP. Ansible kan synkronisere artefakter og sikre, at kun nye eller opdaterede filer overføres og forældede filer fjernes. Dette fremskynder også filoverførsler og sparer en masse båndbredde.
Udover at overføre filer hjælper Ansible også med at gøre servere klar til produktionsbrug. Før overførsel kan den sætte overvågning på pause, fjerne servere fra belastningsbalancere og stoppe tjenester. Efter implementeringen kan den starte tjenester, tilføje servere til belastningsbalancere og genoptage overvågning.
Alt dette behøver ikke at ske på én gang for alle servere. Ansible kan arbejde på et undersæt af servere ad gangen for at levere nul-downtime-implementeringer. For eksempel på et enkelt tidspunkt kan det implementere 5 servere på én gang, og så kan det implementere til næste 5 servere, når de er færdige.
Efter implementering af dette scenarie, kan det udføres hvor som helst. Udviklere eller medlemmer af QA-teamet kan lave implementeringer på deres egne maskiner til testformål. For at rulle en implementering tilbage af en eller anden grund, er alle Ansible-behov placeringen af de sidst kendte arbejdsartefakter. Det kan derefter nemt geninstallere dem på produktionsservere for at sætte systemet tilbage i en stabil tilstand.
Kontinuerlig levering
Kontinuerlig levering betyder at anvende en hurtig og enkel tilgang til udgivelser. For at nå dette mål er det afgørende at bruge de bedste værktøjer, der muliggør hyppige udgivelser uden nedetider og kræver så lidt menneskelig indgriben som muligt. Da vi har lært om Ansibles applikationsimplementeringsfunktioner ovenfor, er det ret nemt at udføre implementeringer uden nedetid. Det andet krav til kontinuerlig levering er færre manuelle processer, og det betyder automatisering. Ansible kan automatisere enhver opgave fra levering af servere til at konfigurere tjenester, så de bliver produktionsklare. Efter at have oprettet og testet scenarier i Ansible, bliver det trivielt at sætte dem foran et kontinuerligt integrationssystem og lade Ansible gøre sit arbejde.
Sikkerhed og overholdelse
Sikkerhed anses altid for at være det vigtigste, men at holde systemerne sikre er noget af det sværeste at opnå. Du skal være sikker på sikkerheden af dine data samt sikkerheden af din kundes data. For at være sikker på dine systemers sikkerhed er det ikke nok at definere sikkerhed. Du skal være i stand til at anvende denne sikkerhed og konstant overvåge dine systemer for at sikre, at de forbliver kompatible med denne sikkerhed.
Ansible er nem at bruge, uanset om det handler om at opsætte firewall-regler, låse brugere og grupper ned eller anvende tilpassede sikkerhedspolitikker. Det er sikkert i sin natur, da du gentagne gange kan anvende den samme konfiguration, og det vil kun foretage de nødvendige ændringer for at sætte systemet tilbage i overensstemmelse.
Orkestrering
Ansible sikrer, at alle givne opgaver er i den rigtige rækkefølge og etablerer en harmoni mellem alle de ressourcer, den administrerer. Orkestrering af komplekse multi-tier-implementeringer er nemmere med Ansibles konfigurationsstyring og implementeringsfunktioner. Når man for eksempel overvejer implementeringen af en softwarestak, er bekymringer som at sikre, at alle databaseservere er klar, før applikationsservere aktiveres eller netværket konfigureres, før man tilføjer servere til belastningsbalanceren, ikke længere komplicerede problemer.
Ansible hjælper også med orkestrering af andre orkestreringsværktøjer såsom Amazons CloudFormation, OpenStack's Heat, Docker's Swarm osv. På denne måde, i stedet for at lære forskellige platforme, sprog og regler; brugere kan kun koncentrere sig om Ansibles YAML-syntaks og kraftfulde moduler.
Hvad er et Ansible-modul?
Moduler eller modulbiblioteker giver Ansible midler til at kontrollere eller administrere ressourcer på lokale eller eksterne servere. De udfører en række funktioner. For eksempel kan et modul være ansvarlig for at genstarte en maskine, eller det kan blot vise en meddelelse på skærmen.
Ansible giver brugerne mulighed for at skrive deres egne moduler og leverer også ud-af-boksen kerne- eller ekstramoduler.
Hvad med Ansible-spillebøger?
Ansible lader os organisere vores arbejde på forskellige måder. I sin mest direkte form kan vi arbejde med Ansible-moduler ved at bruge "ansible ” kommandolinjeværktøj og inventarfilen.
Beholdning
Et af de vigtigste begreber er beholdningen . Vi har brug for en inventarfil for at lade Ansible vide, hvilke servere den skal forbinde ved hjælp af SSH, hvilke forbindelsesoplysninger den kræver, og eventuelt hvilke variabler der er knyttet til disse servere.
Inventarfilen er i et INI-lignende format. I inventarfilen kan vi angive mere end én vært og gruppere dem under mere end én værtsgruppe.
Vores eksempel på lagerfil hosts.ini er som følgende:
[dbservere]db.example.com Her har vi en enkelt vært kaldet "db.example.com" i en værtsgruppe kaldet "dbservers". I inventarfilen kan vi også inkludere brugerdefinerede SSH-porte, SSH-brugernavne, SSH-nøgler, proxyoplysninger, variabler osv.
Da vi har en inventarfil klar, for at se oppetider på vores databaseservere, kan vi påkalde Ansibles "kommando ”-modul og udfør “oppetid ” kommando på disse servere:
ansible dbservers -i hosts.ini -m kommando -a "uptime" Her instruerede vi Ansible om at læse værter fra hosts.ini-filen, forbinde dem ved hjælp af SSH, udføre "oppetid ” kommando på hver af dem, og udskriv derefter deres output til skærmen. Denne type moduludførelse kaldes en ad-hoc-kommando .
Output af kommandoen vil være som:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m kommando -a "uptime"db.example.com | succes | rc=0>>21:16:24 op 93 dage, 9:17, 4 brugere, belastningsgennemsnit:0,08, 0,03, 0,05 Men hvis vores løsning indeholder mere end et enkelt trin, bliver det svært kun at administrere dem ved at bruge ad-hoc-kommandoer.
Her kommer Ansible playbooks. Det giver os mulighed for at organisere vores løsning i en playbook-fil ved at integrere alle trin ved hjælp af opgaver, variabler, roller, skabeloner, handlere og en opgørelse.
Lad os tage et kort kig på nogle af disse udtryk for at forstå, hvordan de kan hjælpe os.
Opgaver
Et andet vigtigt begreb er opgaver. Hver Ansible-opgave indeholder et navn, et modul, der skal kaldes, modulparametre og eventuelt forud-/efterbetingelser. De giver os mulighed for at kalde Ansible-moduler og videregive information til på hinanden følgende opgaver.
Variabler
Der er også variabler. De er meget nyttige til at genbruge oplysninger, vi har givet eller indsamlet. Vi kan enten definere dem i inventaret, i eksterne YAML-filer eller i playbooks.
Playbook
Ansible spillebøger er skrevet ved hjælp af YAML-syntaksen. Den kan indeholde mere end én skuespil. Hvert spil indeholder navn på værtsgrupper, der skal oprettes forbindelse til, og opgaver, det skal udføre. Den kan også indeholde variabler/roller/handlere, hvis de er defineret.
Nu kan vi se på en meget simpel spillebog for at se, hvordan den kan struktureres:
---- hosts:dbservers gather_facts:no vars:who:World tasks:- name:say hello debug:msg="Hej {{ who }}" - name:retrieve the uptime command:uptime I denne meget enkle afspilningsbog fortalte vi Ansible, at den skulle fungere på servere defineret i værtsgruppen "dbservers". Vi lavede en variabel kaldet "hvem", og derefter definerede vi vores opgaver. Bemærk, at i den første opgave, hvor vi udskriver en fejlretningsmeddelelse, brugte vi "who"-variablen og fik Ansible til at udskrive "Hello World" på skærmen. I den anden opgave bad vi Ansible om at oprette forbindelse til hver vært og derefter udføre kommandoen "oppetid" der.
Ansible PostgreSQL-moduler
Ansible leverer en række moduler til PostgreSQL. Nogle af dem er placeret under kernemoduler, mens andre kan findes under ekstramoduler.
Alle PostgreSQL-moduler kræver, at Python psycopg2-pakken er installeret på den samme maskine med PostgreSQL-serveren. Psycopg2 er en PostgreSQL-databaseadapter i Python-programmeringssproget.
På Debian/Ubuntu-systemer kan psycopg2-pakken installeres ved hjælp af følgende kommando:
apt-get install python-psycopg2 Nu vil vi undersøge disse moduler i detaljer. For eksempel vil vi arbejde på en PostgreSQL-server på værten db.example.com på port 5432 med postgres bruger og en tom adgangskode.
postgresql_db
Dette kernemodul opretter eller fjerner en given PostgreSQL-database. I Ansible-terminologi sikrer det, at en given PostgreSQL-database er til stede eller fraværende.
Den vigtigste mulighed er den nødvendige parameter "navn ”. Det repræsenterer navnet på databasen i en PostgreSQL-server. En anden væsentlig parameter er "tilstand ”. Det kræver en af to værdier:nuværende eller fraværende . Dette giver os mulighed for at oprette eller fjerne en database, der er identificeret ved værdien givet i navnet parameter.
Nogle arbejdsgange kan også kræve specifikation af forbindelsesparametre såsom login_host , port , login_user , og login_adgangskode .
Lad os oprette en database kaldet "module_test ” på vores PostgreSQL-server ved at tilføje nedenstående linjer til vores playbook-fil:
- postgresql_db:name=module_test state=present login_host=db.example.com port=5432 login_user=postgres Her oprettede vi forbindelse til vores testdatabaseserver på db.example.com med brugeren; postgres . Det behøver dog ikke at være postgres bruger, da brugernavnet kan være hvad som helst.
Det er lige så nemt at fjerne databasen som at oprette den:
- postgresql_db:name=module_test state=absent login_host=db.example.com port=5432 login_user=postgres Bemærk værdien "fraværende" i parameteren "tilstand".
postgresql_ext
PostgreSQL er kendt for at have meget nyttige og kraftfulde udvidelser. For eksempel er en nylig udvidelse tsm_system_rows som hjælper med at hente det nøjagtige antal rækker i tabelsampling. (For yderligere information kan du tjekke mit tidligere indlæg om tabelsampling metoder.)
Dette ekstramodul tilføjer eller fjerner PostgreSQL-udvidelser fra en database. Det kræver to obligatoriske parametre:db og navn . db parameter refererer til databasenavnet og navnet parameter refererer til udvidelsesnavnet. Vi har også staten parameter, der skal tilstede eller fraværende værdier og samme forbindelsesparametre som i postgresql_db-modulet.
Lad os starte med at oprette den udvidelse, vi talte om:
- postgresql_ext:db=module_test name=tsm_system_rows state=present login_host=db.example.com port=5432 login_user=postgres postgresql_user
Dette kernemodul gør det muligt at tilføje eller fjerne brugere og roller fra en PostgreSQL-database.
Det er et meget kraftfuldt modul, fordi samtidig med at det sikrer, at en bruger er til stede i databasen, tillader det samtidig ændring af privilegier eller roller.
Lad os starte med at se på parametrene. Den enkelte obligatoriske parameter her er "navn ”, som refererer til en bruger eller et rollenavn. Ligesom i de fleste Ansible-moduler er "tilstanden ” parameter er vigtig. Den kan have en af nuværende eller fraværende værdier, og dens standardværdi er til stede .
Ud over tilslutningsparametre som i tidligere moduler er nogle af andre vigtige valgfrie parametre:
- db :Navn på databasen, hvor tilladelser vil blive givet
- adgangskode :Brugerens adgangskode
- privat :Privilegier i "priv1/priv2" eller tabelprivilegier i formatet "table:priv1,priv2,..."
- rolle_attr_flag :Rolleegenskaber. Mulige værdier er:
- [NEJ]SUPERBRUGER
- [NEJ]KREATEROLE
- [NEJ]SKABEBRUGER
- [NEJ]OPRETTET DB
- [NEJ]ARV
- [NEJ]LOG PÅ
- [INGEN]REPLIKATION
For at oprette en ny bruger kaldet ada med adgangskode lovelace og et forbindelsesprivilegium til databasen module_test , kan vi tilføje følgende til vores spillebog:
- postgresql_user:db=module_test name=ada password=lovelace state=present priv=CONNECT login_host=db.example.com port=5432 login_user=postgres Nu hvor vi har brugeren klar, kan vi tildele hende nogle roller. For at tillade "ada" at logge ind og oprette databaser:
- postgresql_user:name=ada role_attr_flags=LOGIN,CREATEDB login_host=db.example.com port=5432 login_user=postgres Vi kan også give globale eller tabelbaserede privilegier såsom "INSERT ”, “OPDATERING ”, “VÆLG ”, og “SLET ” ved hjælp af privat parameter. Et vigtigt punkt at overveje er, at en bruger ikke kan fjernes, før alle tildelte privilegier er tilbagekaldt først.
postgresql_privs
Dette kernemodul giver eller tilbagekalder privilegier på PostgreSQL-databaseobjekter. Understøttede objekter er:tabel , sekvens , funktion , database , skema , sprog , tablespace , og gruppe .
Påkrævede parametre er "database"; navn på databasen, der skal tildeles/tilbagekaldes rettigheder på, og "roller"; en kommasepareret liste over rollenavne.
De vigtigste valgfrie parametre er:
- type :Type af det objekt, der skal indstilles privilegier på. Kan være en af:tabel, sekvens, funktion, database, skema, sprog, tablespace, gruppe . Standardværdien er tabel .
- objs :Databaseobjekter at sætte privilegier på. Kan have flere værdier. I så fald adskilles objekter med et komma.
- privat :Kommasepareret liste over privilegier, der skal tildeles eller tilbagekaldes. Mulige værdier inkluderer:ALLE , VÆLG , OPDATERING , INDSÆT .
Lad os se, hvordan dette fungerer ved at give alle privilegier på "offentlige " skema til "ada ”:
- postgresql_privs:db=module_test privs=ALL type=schema objs=public role=ada login_host=db.example.com port=5432 login_user=postgres postgresql_lang
En af de meget kraftfulde funktioner i PostgreSQL er dens understøttelse af stort set ethvert sprog, der skal bruges som et proceduresprog. Dette ekstramodul tilføjer, fjerner eller ændrer proceduresprog med en PostgreSQL-database.
Den enkelte obligatoriske parameter er "lang "; navnet på det proceduresprog, der skal tilføjes eller fjernes. Andre vigtige muligheder er "db "; navnet på den database, hvor sproget er tilføjet eller fjernet fra, og "trust "; mulighed for at gøre sproget tillid til eller ikke-pålideligt for den valgte database.
Lad os aktivere PL/Python-sproget for vores database:
- postgresql_lang:db=module_test lang=plpython2u state=present login_host=db.example.com port=5432 login_user=postgres Slå det hele sammen
Nu hvor vi ved, hvordan en Ansible-spillebog er opbygget, og hvilke PostgreSQL-moduler, der er tilgængelige for os at bruge, kan vi nu kombinere vores viden i en Ansible-spillebog.
Den endelige form for vores playbook main.yml er som følgende:
---- værter:dbservere sudo:ja sudo_bruger:postgres gather_facts:ja vars:dbnavn:modul_test dbuser:postgres opgaver:- navn:sørg for at databasen er til stede postgresql_db:> state=present db={{ dbname }} login_user={{ dbuser }} - navn:sørg for, at tsm_system_rows-udvidelsen er til stede postgresql_ext:> name=tsm_system_rows state=present db={{ dbname }} login_user={{ dbuser }} - navn:sørg for, at brugeren har adgang til databasen postgresql_user:> name=ada password=lovelace state=nuværende priv=CONNECT db={{ dbname }} login_user={{ dbuser }} - navn:sørg for, at brugeren har de nødvendige rettigheder postgresql_user:> name=ada role_attr_flags=LOGIN, CREATEDB login_user={{ dbuser }} - navn:sørg for, at brugeren har skemarettigheder postgresql_privs:> privs=ALL type=schema objs=public role=ada db={{ dbname }} login_user={{ dbuser }} - navn:sikre postgresen ql-plpython-9.4-pakken er installeret apt:name=postgresql-plpython-9.4 state=seneste sudo_user:root - navn:sørg for, at PL/Python-sproget er tilgængeligt postgresql_lang:> lang=plpython2u state=nuværende db={{ dbname }} login_user={{ dbuser }} Nu kan vi køre vores playbook ved at bruge kommandoen "ansible-playbook":
eksempel@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.ymlPLAY [dbservers] *************** ************************************************** INDSALT FAKTA * ************************************************** ************* ok:[db.example.com]OPGAVE:[sørg for, at databasen er til stede] ******************** ******************** ændret:[db.example.com]OPGAVE:[sørg for, at udvidelsen tsm_system_rows er til stede] *********** *************ændret:[db.example.com]OPGAVE:[sørg for, at brugeren har adgang til databasen] ****************** **************ændret:[db.example.com]OPGAVE:[sørg for, at brugeren har de nødvendige rettigheder] ****************** *************ændret:[db.example.com]OPGAVE:[sørg for, at brugeren har skemarettigheder] ****************** ***************ændret:[db.example.com]OPGAVE:[sørg for, at postgresql-plpython-9.4-pakken er installeret] ************* ***ændret:[db.example.com]OPGAVE:[sørg for, at PL/Python-sproget er tilgængeligt] ************************** **ændret:[db.eksamen ple.com]PLAY RECAP ********************************************* ************************db.example.com :ok=8 ændret=7 unreachable=0 failed=0 Du kan finde inventaret og playbook-filen på mit GitHub-lager, der er oprettet til dette blogindlæg. Der er også en anden spillebog kaldet "remove.yml", der fortryder alt, hvad vi gjorde i hovedspillebogen.
For mere information om Ansible:
- Tjek deres velskrevne dokumenter.
- Se Ansible quick start-video, som er en virkelig nyttig tutorial.
- Følg deres webinar tidsplan, der er nogle fede kommende webinarer på listen.