Som du måske har bemærket fra min tidligere blog, har de sidste par måneder været travle med at få Postgres-XL up-to-date med den seneste 9.5-udgivelse af PostgreSQL. Da vi havde en rimelig stabil version af Postgres-XL 9.5, flyttede vi vores opmærksomhed til at måle ydeevnen af denne helt nye version af Postgres-XL. Vores valg af benchmark er i høj grad påvirket af det igangværende arbejde med AXLE-projektet, finansieret af EU under tilskudsaftale 318633. Da vi bruger TPC BENCHMARK™ H til at måle ydeevnen af alt andet arbejde udført under dette projekt, besluttede vi at bruge samme benchmark til at evaluere Postgres-XL. Det passer også til Postgres-XL, fordi TPC-H forsøger at måle OLAP-arbejdsbelastninger, noget Postgres-XL burde gøre godt.
1. Postgres-XL-klyngeopsætning
Da benchmark var besluttet, var en anden stor udfordring at finde de rigtige ressourcer til test. Vi havde ikke adgang til en stor klynge af fysiske maskiner. Så vi gjorde, hvad de fleste ville gøre. Vi besluttede at bruge Amazon AWS til at opsætte Postgres-XL-klyngen. AWS tilbyder en bred vifte af instanser, hvor hver instanstype tilbyder forskellig computer- eller IO-kraft.
Denne side på AWS viser forskellige tilgængelige instanstyper, tilgængelige ressourcer og deres priser for forskellige regioner. Det skal bemærkes, at priserne og tilgængeligheden kan variere fra region til region, så det er vigtigt, at du tjekker alle regioner ud. Da Postgres-XL kræver lav latenstid og høj gennemstrømning mellem dets komponenter, er det også vigtigt at instansiere alle forekomster i samme region. Til vores 3TB TPC-H besluttede vi at gå efter en 16-datanode-klynge af i2.xlarge AWS-instanser. Disse instanser har 4 vCPU, 30 GB RAM og 800 GB SSD hver, tilstrækkelig lagerplads til at opbevare alle de distribuerede tabeller, replikerede tabeller (som tager mere plads med stigende størrelse af klyngen), indekserne på dem og stadig efterlade nok ledig plads i midlertidig tablespace til CREATE INDEX og andre forespørgsler.
2. Benchmark-opsætning
2.1 TPC Benchmark™ H
Benchmarken indeholder 22 forespørgsler med det formål at undersøge store mængder data, udføre forespørgsler med en høj grad af kompleksitet og give svar på forretningskritiske spørgsmål. Vi vil gerne bemærke, at den komplette TPC Benchmark™ H-specifikation omhandler en række forskellige tests såsom belastning, effekt og gennemløb tests. Til vores test har vi kun kørt individuelle forespørgsler og ikke hele testpakken. TPC Benchmark™ H består af et sæt forretningsforespørgsler designet til at udøve systemfunktioner på en måde, der er repræsentativ for komplekse forretningsanalyseapplikationer. Disse forespørgsler har fået en realistisk kontekst, der skildrer en engrosleverandørs aktivitet for at hjælpe læseren med at forholde sig intuitivt til benchmarkets komponenter.
2.2 Databaseenheder, relationer og karakteristika
Komponenterne i TPC-H-databasen er defineret til at bestå af otte separate og individuelle tabeller (Basistabellerne). Forholdet mellem kolonnerne i disse tabeller er illustreret i det følgende diagram. 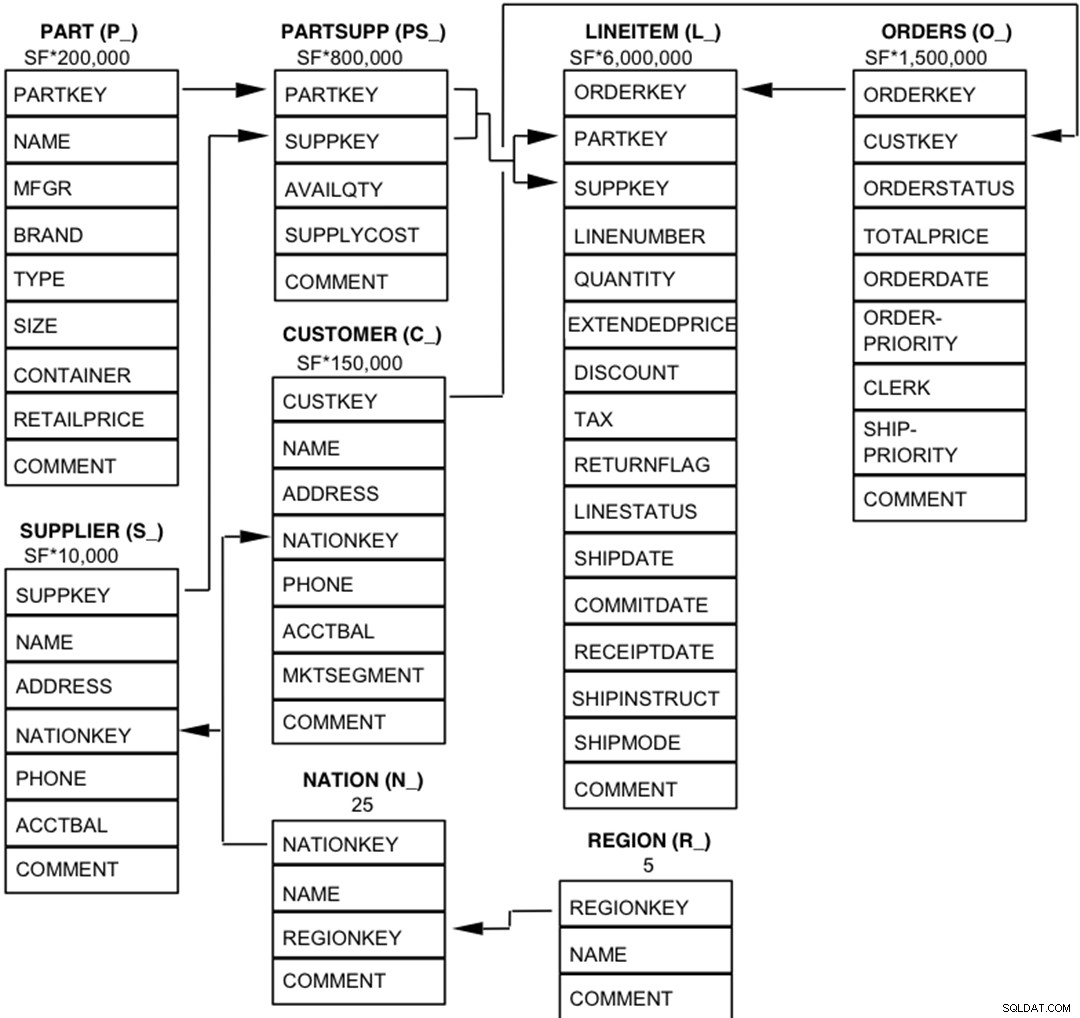 Legend :
Legend :
- Parenteserne efter hvert tabelnavn indeholder præfikset for kolonnenavnene for den pågældende tabel;
- Pilene peger i retning af en-til-mange-relationerne mellem tabeller
- Antallet/formlen under hvert tabelnavn repræsenterer tabellens kardinalitet (antal rækker). Nogle er faktoriseret af SF, Skalafaktoren, for at opnå den valgte databasestørrelse. Kardinaliteten for LINEITEM-tabellen er omtrentlig
2.3 Datadistribution for Postgres-XL
Vi analyserede alle 22 forespørgsler i benchmark og kom frem til følgende datadistributionsstrategi for forskellige tabeller i benchmark.
| Tabelnavn | Distributionsstrategi |
| LINEITEM | HASH (l_orderkey) |
| ORDRER | HASH (o_orderkey) |
| DEL | HASH (p_partkey) |
| DELSUPP | HASH (ps_partkey) |
| KUNDE | REPLICATED |
| LEVERANDØR | REPLICATED |
| NATION | REPLICATED |
| REGION | REPLICATED |
Bemærk, at LINEITEM og ORDERS, som er de største tabeller i benchmark, ofte er sammenføjet på ORDREKEY. Så det giver god mening at samle disse tabeller på ORDREKEY. På samme måde er PART og PARTSUPP ofte sammenføjet på PARTKEY, og de er derfor samlet på PARTKEY-kolonnen. Resten af tabellerne er replikeret for at sikre, at de kan sammenføjes lokalt, når det er nødvendigt.
3. Benchmark-resultater
3.1 Belastningstest
Vi sammenlignede resultater opnået ved at køre en 3TB TPC-H Load Test på PostgreSQL 9.6 med 16-node Postgres-XL klyngen. Følgende diagrammer viser ydeevneegenskaberne for Postgres-XL.
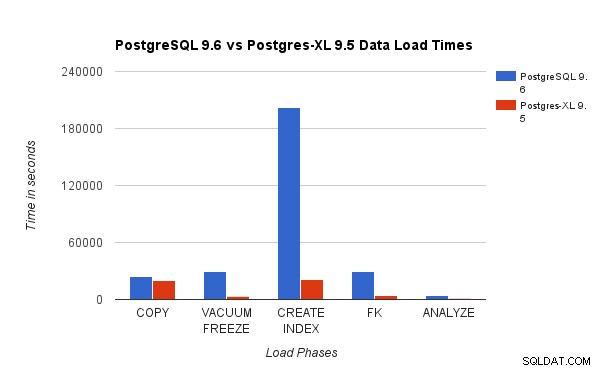 Ovenstående diagram viser den tid, det tager at gennemføre forskellige faser af en Load Test med PostgreSQL og Postgres-XL. Som det kan ses, klarer Postgres-XL sig lidt bedre til COPY og meget bedre for alle andre tilfælde. Bemærk :Vi observerede, at koordinatoren kræver meget regnekraft i COPY-fasen, især når mere end én COPY-stream kører samtidigt. For at løse det blev koordinatoren kørt på en computeroptimeret AWS-instans med 16 vCPU. Alternativt kunne vi også have kørt flere koordinatorer og fordelt beregningsbelastning mellem dem.
Ovenstående diagram viser den tid, det tager at gennemføre forskellige faser af en Load Test med PostgreSQL og Postgres-XL. Som det kan ses, klarer Postgres-XL sig lidt bedre til COPY og meget bedre for alle andre tilfælde. Bemærk :Vi observerede, at koordinatoren kræver meget regnekraft i COPY-fasen, især når mere end én COPY-stream kører samtidigt. For at løse det blev koordinatoren kørt på en computeroptimeret AWS-instans med 16 vCPU. Alternativt kunne vi også have kørt flere koordinatorer og fordelt beregningsbelastning mellem dem.
3.2 Power Test
Vi sammenlignede også forespørgselskørselstiderne for 3TB benchmark på PostgreSQL 9.6 og Postgres-XL 9.5. Følgende diagram viser ydeevnekarakteristika for udførelse af forespørgsler på de to opsætninger.
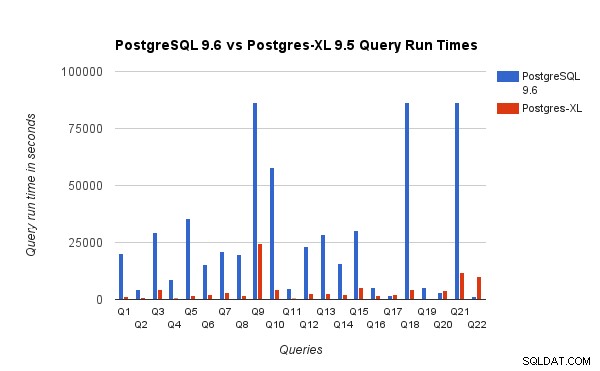 Vi observerede, at forespørgsler i gennemsnit kørte omkring 6,4 gange hurtigere på Postgres-XL og mindst 25 % af forespørgslerne viste næsten lineær forbedring i ydeevne, med andre ord præsterede de næsten 16 gange hurtigere på denne 16-node Postgres-XL-klynge. Desuden viste mindst 50 % af forespørgslerne 10 gange forbedring i ydeevne. Vi analyserede yderligere forespørgselsydelserne og konkluderede, at forespørgsler, der er godt opdelt på tværs af alle tilgængelige datanoder, således at der er minimal udveksling af data mellem noder og uden gentagne fjernudførelseskald, skaleres meget godt i Postgres-XL. Sådanne forespørgsler har typisk en Remote Subquery Scan node øverst, og undertræet under noden udføres på en eller flere noder parallelt. Det er også almindeligt at have nogle andre noder såsom en Limit node eller en Aggregate node oven på Remote Subquery Scan noden. Selv sådanne forespørgsler fungerer meget godt på Postgres-XL. Forespørgsel Q1 er et eksempel på en forespørgsel, der bør skaleres meget godt med Postgres-XL. På den anden side kan forespørgsler, der kræver masser af udveksling af tuples mellem datanode-datanode og/eller koordinator-datanode, muligvis ikke klare sig godt i Postgres-XL. På samme måde kan forespørgsler, der kræver mange krydsknudeforbindelser, også vise dårlig ydeevne. For eksempel vil du bemærke, at ydeevnen af Q22 er dårlig sammenlignet med en enkelt node PostgreSQL-server. Da vi analyserede forespørgselsplanen for Q22, observerede vi, at der er tre niveauer af indlejrede Remote Subquery Scan noder i forespørgselsplanen, hvor hver node åbner lige mange forbindelser til datanoderne. Ydermere har Nest Loop Anti Join en indre relation med en fjernunderforespørgselsscanning på øverste niveau, og derfor skal den for hver tuple af den ydre relation udføre en ekstern underforespørgsel. Dette resulterer i dårlig udførelse af forespørgselsudførelse.
Vi observerede, at forespørgsler i gennemsnit kørte omkring 6,4 gange hurtigere på Postgres-XL og mindst 25 % af forespørgslerne viste næsten lineær forbedring i ydeevne, med andre ord præsterede de næsten 16 gange hurtigere på denne 16-node Postgres-XL-klynge. Desuden viste mindst 50 % af forespørgslerne 10 gange forbedring i ydeevne. Vi analyserede yderligere forespørgselsydelserne og konkluderede, at forespørgsler, der er godt opdelt på tværs af alle tilgængelige datanoder, således at der er minimal udveksling af data mellem noder og uden gentagne fjernudførelseskald, skaleres meget godt i Postgres-XL. Sådanne forespørgsler har typisk en Remote Subquery Scan node øverst, og undertræet under noden udføres på en eller flere noder parallelt. Det er også almindeligt at have nogle andre noder såsom en Limit node eller en Aggregate node oven på Remote Subquery Scan noden. Selv sådanne forespørgsler fungerer meget godt på Postgres-XL. Forespørgsel Q1 er et eksempel på en forespørgsel, der bør skaleres meget godt med Postgres-XL. På den anden side kan forespørgsler, der kræver masser af udveksling af tuples mellem datanode-datanode og/eller koordinator-datanode, muligvis ikke klare sig godt i Postgres-XL. På samme måde kan forespørgsler, der kræver mange krydsknudeforbindelser, også vise dårlig ydeevne. For eksempel vil du bemærke, at ydeevnen af Q22 er dårlig sammenlignet med en enkelt node PostgreSQL-server. Da vi analyserede forespørgselsplanen for Q22, observerede vi, at der er tre niveauer af indlejrede Remote Subquery Scan noder i forespørgselsplanen, hvor hver node åbner lige mange forbindelser til datanoderne. Ydermere har Nest Loop Anti Join en indre relation med en fjernunderforespørgselsscanning på øverste niveau, og derfor skal den for hver tuple af den ydre relation udføre en ekstern underforespørgsel. Dette resulterer i dårlig udførelse af forespørgselsudførelse.
4. Et par AWS-lektioner
Mens vi benchmarkede Postgres-XL, lærte vi et par lektioner om at bruge AWS. Vi troede, at de vil være nyttige for alle, der ønsker at bruge/teste Postgres-XL på AWS.
- AWS tilbyder flere forskellige typer forekomster. Du skal omhyggeligt evaluere din arbejdsbelastning og mængden af krævet lagerplads, før du vælger en specifik instanstype.
- De fleste lageroptimerede forekomster har midlertidige diske knyttet til dem. Du behøver ikke betale noget ekstra for disse diske, de er knyttet til instansen og yder ofte bedre end EBS. Men du skal montere dem eksplicit for at kunne bruge dem. Husk dog, at de data, der er gemt på disse diske, ikke er permanente og vil blive slettet, hvis instansen stoppes. Så sørg for, at du er klar til at håndtere den situation. Da vi mest brugte AWS til benchmarking, besluttede vi at bruge disse flygtige diske.
- Hvis du bruger EBS, skal du sørge for at vælge passende Provisioned IOPS. For lav værdi vil forårsage meget langsom IO, men en meget høj værdi kan øge din AWS-regning betydeligt, især når du har at gøre med et stort antal noder.
- Sørg for, at du starter forekomsterne i den samme zone for at reducere latens og forbedre gennemløbet for forbindelser mellem dem.
- Sørg for at konfigurere forekomster, så de bruger privat netværk til at tale med hinanden.
- Se på spot-forekomster. De er relativt billigere. Da AWS kan afslutte spotforekomster efter eget ønske, hvis f.eks. spotprisen bliver mere end din maks. budpris, skal du være forberedt på det. Postgres-XL kan blive delvist eller helt ubrugelig afhængigt af hvilke noder der afsluttes. AWS understøtter et koncept med launch_group. Hvis flere forekomster er grupperet i den samme startgruppe hvis AWS beslutter at afslutte en instans, vil alle instanser blive afsluttet.
5. Konklusion
Vi er i stand til at vise, gennem forskellige benchmarks, at Postgres-XL kan skaleres rigtig godt til et stort sæt af komplekse forespørgsler fra den virkelige verden. Disse benchmarks hjælper os med at demonstrere Postgres-XLs evne som en effektiv løsning til OLAP-arbejdsbelastninger. Vores eksperimenter viser også, at der er nogle præstationsproblemer med Postgres-XL, især for meget store klynger, og når planlæggeren træffer et dårligt valg af en plan. Vi observerede også, at når der er et meget stort antal samtidige forbindelser til en datanode, forværres ydeevnen. Vi vil fortsætte med at arbejde på disse præstationsproblemer. Vi vil også gerne teste Postgres-XLs kapacitet som en OLTP-løsning ved at bruge passende arbejdsbelastninger.