For et par år siden (på pgconf.eu 2014 i Madrid) præsenterede jeg en tale kaldet "Performance Archaeology", som viste, hvordan ydeevnen ændrede sig i de seneste PostgreSQL-udgivelser. Jeg holdt den snak, da jeg synes, at det langsigtede synspunkt er interessant og kan give os indsigter, der kan være meget værdifulde. For folk, der rent faktisk arbejder med PostgreSQL-kode som mig, er det en nyttig guide til fremtidig udvikling, og for PostgreSQL-brugere kan det hjælpe med at evaluere opgraderinger.
Så jeg har besluttet at gentage denne øvelse og skrive et par blogindlæg, der analyserer ydeevnen for en række PostgreSQL-versioner. I 2014-talen startede jeg med PostgreSQL 7.4, som på det tidspunkt var omkring 10 år gammel (udgivet i 2003). Denne gang starter jeg med PostgreSQL 8.3, som er omkring 12 år gammel.
Hvorfor ikke starte med PostgreSQL 7.4 igen? Der er omkring tre hovedårsager til, hvorfor jeg besluttede at starte med PostgreSQL 8.3. For det første generel dovenskab. Jo ældre versionen er, jo sværere kan det være at bygge med nuværende compilerversioner osv. For det andet tager det tid at køre ordentlige benchmarks, især med større mængder data, så tilføjelse af en enkelt større version kan nemt tilføje et par dages maskintid. Det virkede bare ikke det værd. Og endelig introducerede 8.3 en række vigtige ændringer – autovakuumforbedringer (aktiveret som standard, samtidige arbejdsprocesser, …), fuldtekstsøgning integreret i kerne, spredte kontrolpunkter og så videre. Så jeg synes, det giver god mening at starte med PostgreSQL 8.3. Som blev udgivet for omkring 12 år siden, så denne sammenligning vil faktisk dække en længere periode.
Jeg har besluttet at benchmarke tre grundlæggende arbejdsbelastningstyper - OLTP, analytics og fuldtekstsøgning. Jeg tror, at OLTP og analytics er ret indlysende valg, da de fleste applikationer er en blanding af disse to grundlæggende typer. Fuldtekstsøgningen giver mig mulighed for at demonstrere forbedringer i specielle typer indekser, som også bruges til at indeksere populære datatyper som JSONB, typer brugt af PostGIS osv.
Hvorfor gøre dette overhovedet?
Er det faktisk besværet værd? Vi laver jo benchmarks under udvikling hele tiden for at vise, at et plaster hjælper og/eller at det ikke forårsager regression, vel? Problemet er, at disse normalt kun er "delvise" benchmarks, der sammenligner to bestemte commits, og normalt med et ret begrænset udvalg af arbejdsbelastninger, som vi mener kan være relevante. Hvilket giver god mening – du kan simpelthen ikke køre et fuldt batteri af arbejdsbelastninger for hver commit.
En gang imellem (normalt kort efter en udgivelse af en ny PostgreSQL major-version) kører folk tests, der sammenligner den nye version med den foregående, hvilket er rart, og jeg opfordrer dig til at køre sådanne benchmarks (det være sig en form for standard benchmark, eller noget specifikt for din ansøgning). Men det er svært at kombinere disse resultater til en længerevarende visning, fordi disse tests bruger forskellige konfigurationer og hardware (normalt en nyere til den nyere version) og så videre. Så det er svært at foretage klare domme om ændringer generelt.
Det samme gælder applikationens ydeevne, som selvfølgelig er det "ultimate benchmark". Men folk opgraderer muligvis ikke til alle større versioner (nogle gange kan de springe et par versioner over, f.eks. fra 9.5 til 12). Og når de opgraderer, kombineres det ofte med hardwareopgraderinger osv. For ikke at nævne, at applikationer udvikler sig over tid (nye funktioner, yderligere kompleksitet), mængden af data og antallet af samtidige brugere vokser osv.
Det er, hvad denne blog-serie forsøger at vise - langsigtede tendenser i PostgreSQL-ydelse for nogle grundlæggende arbejdsbelastninger, så vi - udviklerne - får en varm og uklar fornemmelse af det gode arbejde gennem årene. Og for at vise brugerne, at selvom PostgreSQL er et modent produkt på dette tidspunkt, er der stadig betydelige forbedringer i hver ny større version.
Det er ikke mit mål at bruge disse benchmarks til sammenligning med andre databaseprodukter eller at producere resultater for at opfylde nogen officiel rangordning (som TPC-H). Mit mål er simpelthen at uddanne mig selv som PostgreSQL-udvikler, måske identificere og undersøge nogle problemer og dele resultaterne med andre.
Retfærdig sammenligning?
Jeg tror ikke, at sådanne sammenligninger af versioner udgivet over 12 år ikke kan være helt fair, fordi enhver software er udviklet i en bestemt kontekst - hardware er et godt eksempel for et databasesystem. Hvis du ser på de maskiner, du brugte for 12 år siden, hvor mange kerner havde de, hvor meget RAM? Hvilken type opbevaring brugte de?
En typisk mellemklasseserver i 2008 havde måske 8-12 kerner, 16 GB RAM og et RAID med et par SAS-drev. En typisk mellemklasseserver i dag kan have et par snesevis af kerner, hundredvis af GB RAM og SSD-lagerplads.
Softwareudvikling er organiseret efter prioritet - der er altid flere potentielle opgaver, end du har tid til, så du skal vælge opgaver med det bedste cost/benefit-forhold for dine brugere (især dem, der finansierer projektet, direkte eller indirekte). Og i 2008 var nogle optimeringer sandsynligvis ikke relevante endnu – de fleste maskiner havde ikke ekstreme mængder RAM, så optimering til store delte buffere var f.eks. ikke det værd endnu. Og mange af CPU-flaskehalsene blev overskygget af I/O, fordi de fleste maskiner havde "spinningsrust"-lagring.
Bemærk:Selvfølgelig var der kunder, der brugte ret store maskiner selv dengang. Nogle brugte community Postgres med forskellige tweaks, andre besluttede at køre med en af de forskellige Postgres gafler med yderligere muligheder (f.eks. massiv parallelisme, distribuerede forespørgsler, brug af FPGA osv.). Og dette påvirkede selvfølgelig også samfundsudviklingen.
Efterhånden som de større maskiner blev mere almindelige i årenes løb, havde flere mennesker råd til maskiner med store mængder RAM og høje kernetal, hvilket ændrede cost/benefit-forholdet. Flaskehalsene blev undersøgt og rettet, hvilket gjorde det muligt for nyere versioner at yde bedre.
Dette betyder, at et benchmark som dette altid er lidt uretfærdigt - det vil favorisere enten den ældre eller nyere version, afhængigt af opsætningen (hardware, konfiguration). Jeg har forsøgt at vælge hardware og konfigurationsparametre, så det ikke er så dårligt for ældre versioner.
Pointen, jeg prøver at gøre, er, at dette ikke betyder, at de ældre PostgreSQL-versioner var lort - det er sådan softwareudvikling fungerer. Du adresserer de flaskehalse, som dine brugere sandsynligvis vil støde på, ikke de flaskehalse, de kan støde på om 10 år.
Hardware
Jeg foretrækker at lave benchmarks på fysisk hardware, jeg har direkte adgang til, fordi det giver mig mulighed for at kontrollere alle detaljer, jeg har adgang til alle detaljer, og så videre. Så jeg har brugt den maskine, jeg har på vores kontor - ikke noget fancy, men forhåbentlig god nok til dette formål.
- 2x E5-2620 v4 (16 kerner, 32 tråde)
- 64 GB RAM
- Intel Optane 900P 280 GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (midlertidig tablespace)
- kerne 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Jeg har også brugt en anden – meget mindre – maskine med kun 4 kerner og 8 GB RAM, som generelt viser de samme forbedringer/regressioner, bare mindre udtalte.
pgbench
Som et benchmarkingværktøj har jeg brugt den velkendte pgbench, ved at bruge den nyeste version (fra PostgreSQL 13) til at teste alle versioner. Dette eliminerer mulig skævhed på grund af optimeringer udført i pgbench over tid, hvilket gør resultaterne mere sammenlignelige.
Benchmark tester en række forskellige cases, der varierer en række parametre, nemlig:
skala
- lille – data passer ind i delte buffere, viser låseproblemer osv.
- medium – data større end delte buffere, men passer ind i RAM, normalt CPU-bundet (eller muligvis I/O til læse-skrive-arbejdsbelastninger)
- stor – data større end RAM, primært I/O-bundet
tilstande
- skrivebeskyttet – pgbench -S
- læse-skrive – pgbench -N
kundeantal
- 1, 4, 8, 16, 32, 64, 128, 256
- Antallet af pgbench-tråde (-j) justeres tilsvarende
Resultater
OK, lad os se på resultaterne. Jeg vil først præsentere resultater fra NVMe-lageret, og derefter vil jeg vise nogle interessante resultater ved hjælp af SATA RAID-lageret.
NVMe SSD / skrivebeskyttet
For det lille datasæt (der fuldt ud passer ind i delte buffere), ser de skrivebeskyttede resultater således ud:
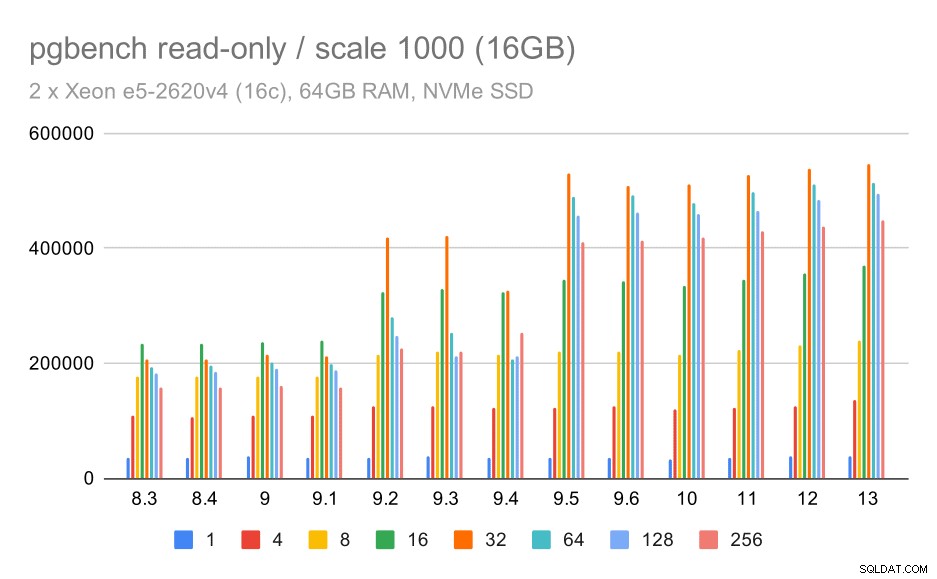
pgbench-resultater / skrivebeskyttet på lille datasæt (skala 100, dvs. 1,6 GB)
Det er klart, at der var en betydelig stigning i gennemløbet i 9.2, som indeholdt en række præstationsforbedringer, for eksempel fast-path til låsning. Gennemstrømningen for en enkelt klient falder faktisk en smule – fra 47.000 tps til kun omkring 42.000 tps. Men for højere klienttal er forbedringen i 9.2 ret klar.
pgbench-resultater / skrivebeskyttet på medium datasæt (skala 1000, dvs. 16 GB)
For det mellemstore datasæt (som er større end delte buffere, men stadig passer ind i RAM) ser der også ud til at være en vis forbedring i 9.2, selvom det ikke er så tydeligt som ovenfor, efterfulgt af en meget tydeligere forbedring i 9.5, sandsynligvis takket være forbedringer af låseskalerbarhed .
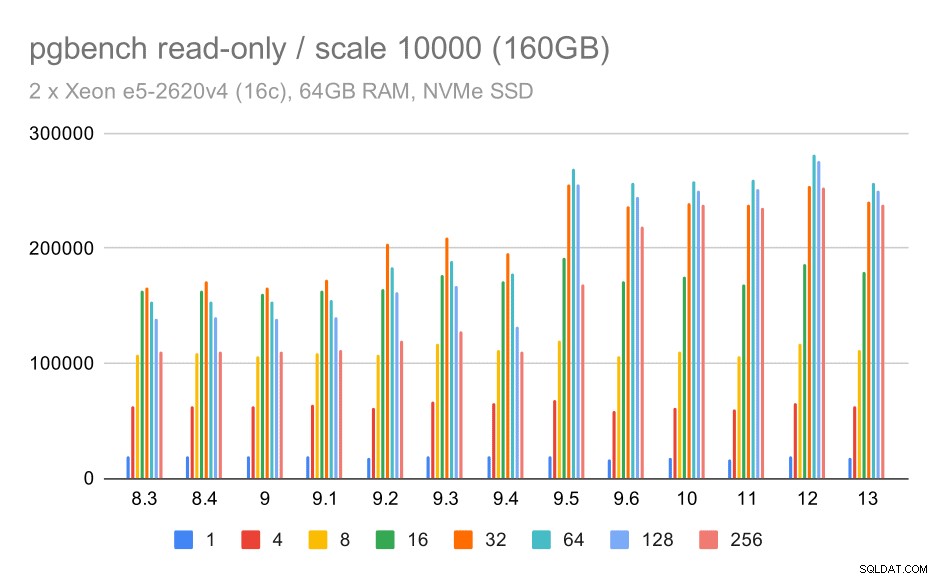
pgbench-resultater / skrivebeskyttet på stort datasæt (skala 10000, dvs. 160 GB)
På det største datasæt, som for det meste handler om evnen til effektivt at udnytte lageret, er der også en vis speedup – højst sandsynligt også takket være 9.5-forbedringerne.
NVMe SSD / læs-skriv
Læs-skriv-resultaterne viser også nogle forbedringer, dog ikke så udtalt. På det lille datasæt ser resultaterne således ud:
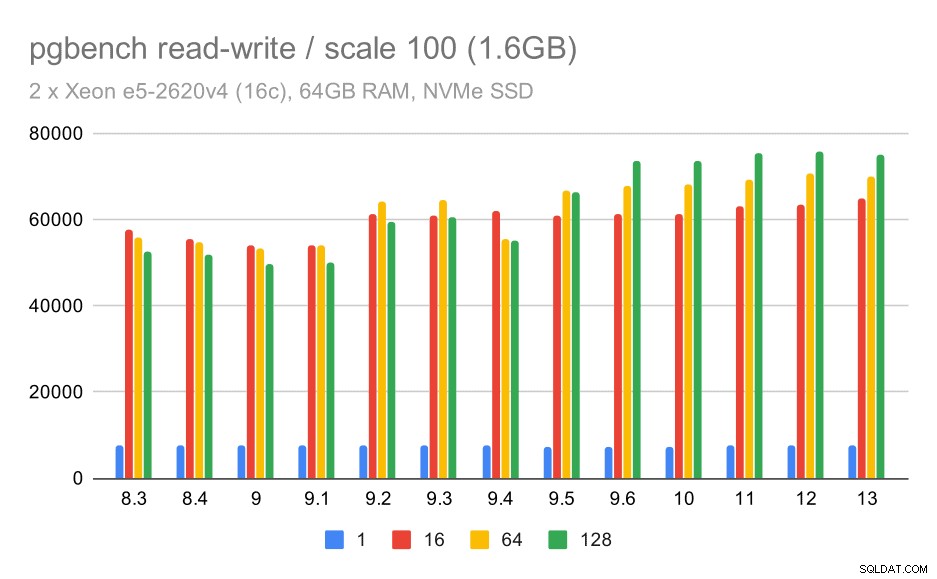
pgbench-resultater / læs-skriv på lille datasæt (skala 100, dvs. 1,6 GB)
Så en beskeden forbedring fra omkring 52.000 til 75.000 tps med tilstrækkeligt antal klienter.
For det mellemstore datasæt er forbedringen meget tydeligere – fra omkring 27.000 til 63.000 tps, dvs. gennemløbet mere end fordobles.
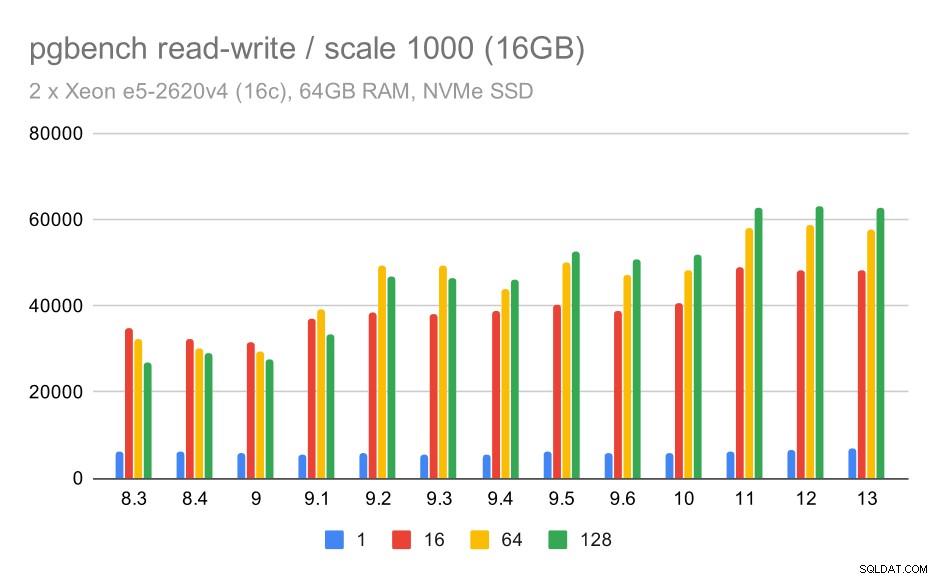
pgbench-resultater / læs-skriv på medium datasæt (skala 1000, dvs. 16 GB)
For det største datasæt ser vi en lignende overordnet forbedring, men der ser ud til at være en vis regression mellem 9,5 og 11.
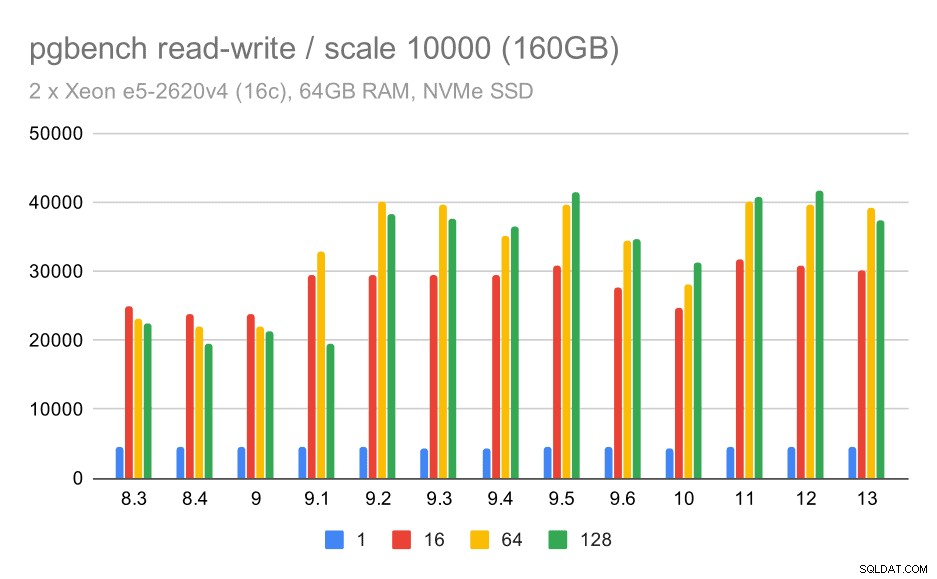
pgbench-resultater / læs-skriv på stort datasæt (skala 10000, dvs. 160 GB)
SATA RAID / skrivebeskyttet
For SATA RAID-lageret er de skrivebeskyttede resultater ikke så pæne. Vi kan ignorere de små og mellemstore datasæt, som lagersystemet er irrelevant for. For det store datasæt er gennemløbet noget støjende, men det ser faktisk ud til at falde over tid - især siden PostgreSQL 9.6. Jeg ved ikke, hvad der er årsagen til dette (intet i 9.6 release notes skiller sig ud som en klar kandidat), men det virker som en form for regression.
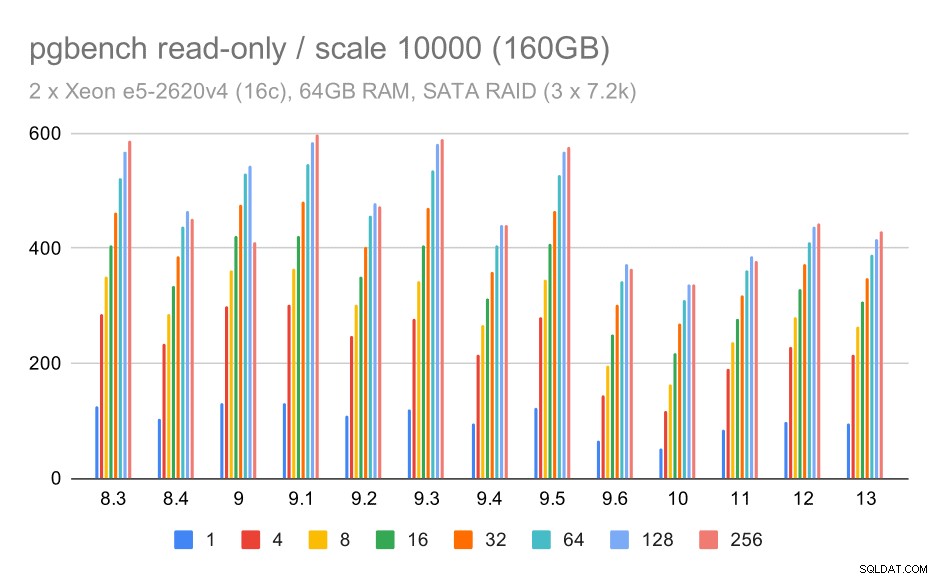
pgbench-resultater på SATA RAID / skrivebeskyttet på store datasæt (skala 10000, dvs. 160 GB)
SATA RAID / læse-skrive
Læse-skrive-adfærden virker dog meget pænere. På det lille datasæt stiger gennemløbet fra omkring 600 tps til mere end 6000 tps. Jeg vil vædde på, at dette er takket være forbedringer af gruppeforpligtelse i 9.1 og 9.2.
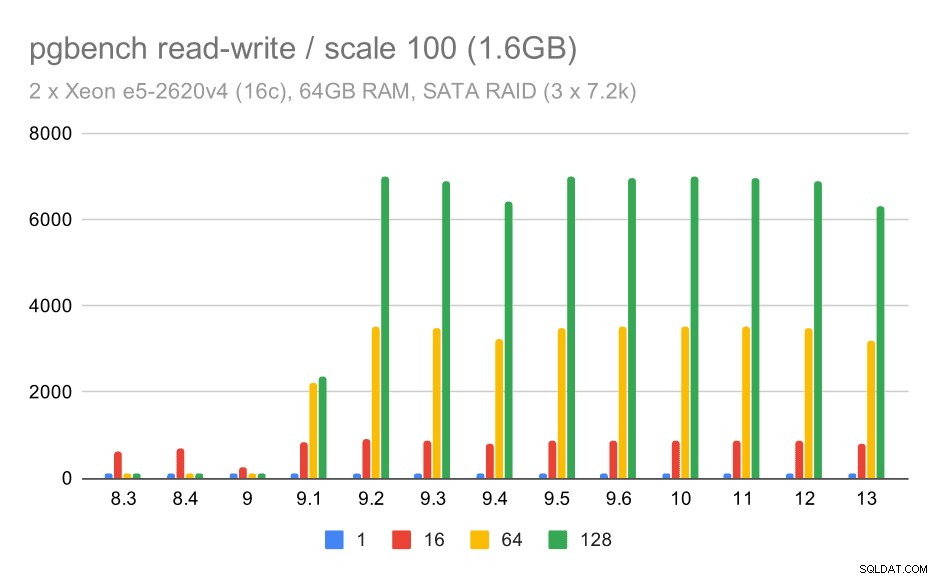
pgbench-resultater på SATA RAID / læse-skrive på lille datasæt (skala 100, dvs. 1,6 GB)
For mellemstore og store skalaer kan vi se lignende – men mindre – forbedringer, fordi lageret også skal håndtere I/O-anmodningerne for at læse og skrive datablokkene. For den mellemstore skala skal vi kun lave skrivningerne (da dataene passer ind i RAM), for den store skala skal vi også lave læsningerne - så den maksimale gennemstrømning er endnu lavere.
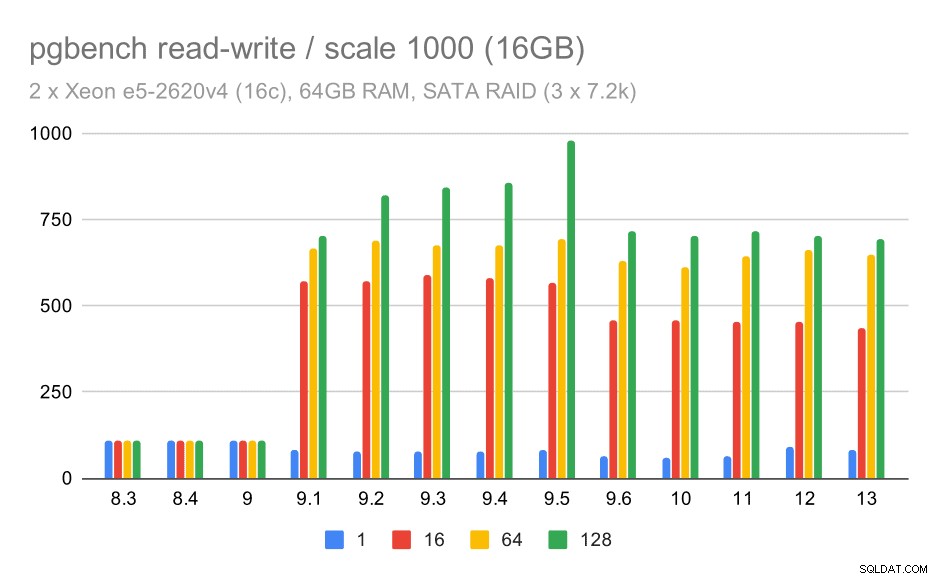
pgbench-resultater på SATA RAID / læse-skrive på medium datasæt (skala 1000, dvs. 16 GB)
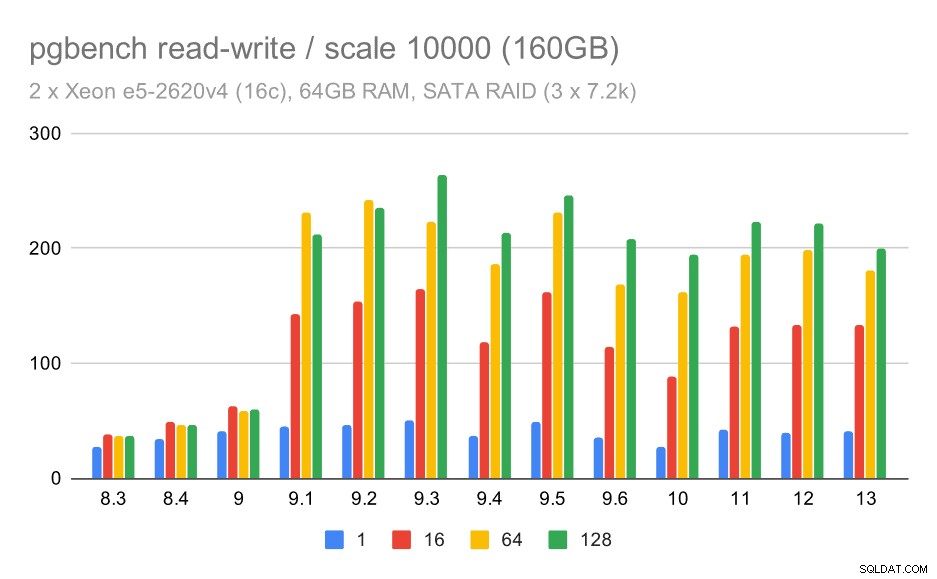
pgbench-resultater på SATA RAID / læse-skrive på stort datasæt (skala 10000, dvs. 160 GB)
Oversigt og fremtid
For at opsummere dette, for NVMe-opsætningen ser konklusionerne ud til at være ret positive. For skrivebeskyttet arbejdsbyrde er der en moderat hastighedsstigning i 9.2 og betydelig hastighed i 9.5, takket være skalerbarhedsoptimeringer, mens ydelsen for læse-skrive-arbejdsbelastningen blev forbedret med ca. 2x over tid, i flere versioner/trin.
Med SATA RAID-opsætningen er konklusionerne dog noget blandede. I tilfælde af skrivebeskyttet arbejdsbyrde er der megen variabilitet/støj og mulig regression i 9.6. For læse-skrive-arbejdsbyrden er der en massiv fremskyndelse i 9.1, hvor gennemløbet pludselig steg fra 100 tps til omkring 600 tps.
Hvad med forbedringer i fremtidige PostgreSQL-versioner? Jeg har ikke en meget klar idé om, hvad den næste store forbedring vil være - jeg er dog sikker på, at andre PostgreSQL-hackere vil komme med geniale ideer, der gør tingene mere effektive eller tillader at udnytte tilgængelige hardwareressourcer. Patchen til at forbedre skalerbarheden med mange forbindelser eller patchen til at tilføje understøttelse af ikke-flygtige WAL-buffere er eksempler på sådanne forbedringer. Vi vil muligvis se nogle radikale forbedringer af PostgreSQL-lagring (mere effektivt format på disken, brug af direkte I/O osv.), indeksering osv.